









YOLOv5 以其高效的目标检测能力和灵活的配置选项,成为处理自定义数据集的热门选择。本文将以 Kaggle 上的肺炎 X 光数据集为例,详细讲解如何配置和运行 YOLOv5 训练流程。
第一章 准备数据集
1.1 数据集来源与结构
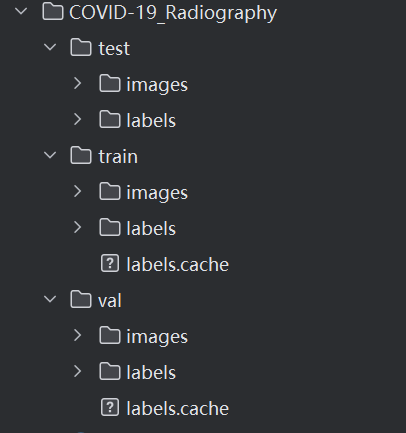
我们使用 Kaggle 平台的肺炎 X 光数据集(COVID-19 Radiography Dataset),需将其转换为 YOLOv5 支持的输入格式。核心结构如下:
数据集根目录/
├── train/
│ ├── images/ # 训练集图片(JPG/PNG等格式)
│ └── labels/ # 训练集标签(TXT格式,每个图片对应一个同名标签文件)
├── val/
│ ├── images/ # 验证集图片
│ └── labels/ # 验证集标签
└── test/
├── images/ # 测试集图片
└── labels/ # 测试集标签
1.2 标签文件格式要求
每个标签文件(如001.txt)内容需符合 YOLO 格式:每行代表一个目标,格式为 类别索引 x_center y_center width height,坐标和尺寸均为相对于图片宽高的归一化值(范围 0-1)。示例:0 0.521 0.634 0.213 0.345 表示类别 0(COVID),目标中心坐标 (52.1% 宽,63.4% 高),宽高占比 21.3% 和 34.5%。

第一个是分类标签,剩下四个是病灶的x,y,h,w的归一化后的坐标。
第二章 配置 YOLO 中的 YAML 文件
2.1 创建自定义数据集配置文件
在 YOLOv5 的data/目录下新建mydata.yaml(文件名可自定义),仿照 COCO 数据集格式定义路径和类别信息:
train: D:\VSCODE\YOLO\COVID-19_Radiography\train\images
val: D:\VSCODE\YOLO\COVID-19_Radiography\val\images
test: D:\VSCODE\YOLO\COVID-19_Radiography\test\images
nc: 4
names: ['COVID', 'Normal', 'Viral Pneumonia', 'Lung_Opacity']2.2 路径注意事项
- 路径格式:Windows 系统建议使用反斜杠\或双反斜杠\\,Linux/macOS 使用正斜杠/。
- 自动匹配标签:YOLOv5 会自动读取images/同级目录的labels/文件夹,无需在 YAML 中显式声明标签路径。
第三章 修改 YOLOv5 中的运行代码
在train.py的parse_opt函数中,通过命令行参数配置训练参数。以下是关键参数调整及意义说明(结合代码注释):
3.1 基础配置参数
parser.add_argument("--weights", type=str, default=ROOT / "yolov5m.pt", help="初始权重文件路径")
# 说明:选择预训练模型(如yolov5s.pt/yolov5m.pt),预训练权重可加速收敛,"yolov5m.pt"适合中等规模数据集
parser.add_argument("--cfg", type=str, default="", help="模型配置文件路径(如yolov5m.yaml)")
# 说明:留空时自动匹配权重文件对应的模型配置(如yolov5m.pt匹配yolov5m.yaml),一般无需修改
parser.add_argument("--data", type=str, default=ROOT / "data/mydata.yaml", help="数据集配置文件路径")
# 说明:指向第二章创建的mydata.yaml,确保YOLOv5读取自定义数据集路径和类别信息3.2 训练参数调整
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-med.yaml", help="超参数文件路径")
# 说明:针对医学图像选择中等强度数据增强(hyp.scratch-med.yaml),包含旋转、翻转、亮度调整等,提升模型泛化性
parser.add_argument("--epochs", type=int, default=30, help="总训练轮数")
# 说明:根据数据集大小调整,小数据集建议30-50轮,避免过拟合;大规模数据集可增至100+轮
parser.add_argument("--batch-size", type=int, default=32, help="总批量大小(所有GPU)")
# 说明:根据GPU显存调整(如3090显卡可设64,2060设16),-1表示自动适配最优批量大小
parser.add_argument("--imgsz", type=int, default=640, help="输入图片尺寸(像素)")
# 说明:常用640/416,尺寸越大检测精度越高但速度越慢,需平衡计算资源3.3 高级功能参数
parser.add_argument("--resume", nargs="?", const=True, default=True, help="继续上次训练")
# 说明:设为True时从最近的检查点(last.pt)恢复训练,中断后无需重新开始
parser.add_argument("--class-weights", type=float, nargs="+", default=[0.38, 0.13, 1.0, 0.22], help="类别权重")
# 说明:平衡类别不平衡问题,示例权重针对"Viral Pneumonia"(索引2)赋予最高权重1.0,其他类别按样本比例调整
parser.add_argument("--device", default="", help="训练设备(如'0'或'0,1'表示GPU,'cpu'表示CPU)")
# 说明:留空自动检测可用设备,建议指定GPU编号(如"0")避免多卡分配错误利用resume进行中断训练之后再训练时,是不会改变 epochs的,这个一开始是多少就会多少。
3.4 终端运行必要性
- 激活动态参数:含action="store_true"的参数(如--rect/--noval)需在终端显式声明才能生效,直接在 PyCharm 中运行会使用默认值。
- 命令示例:
python train.py --data data/mydata.yaml --weights yolov5m.pt --batch-size 32 --epochs 30其余的val.py和test.py均按照这个原理调配即可。
第四章 查看训练结果
4.1 结果保存路径
训练完成后,结果存储在runs/train/exp/目录(exp可通过--name参数自定义名称),核心文件包括:
- weights/:训练生成的权重文件(last.pt为最后一轮,best.pt为验证集精度最高的权重)。
- results.csv:训练过程j结果(损失值、mAP@0.5 等指标)。
- train_batch*.jpg:训练批次的可视化检测结果。
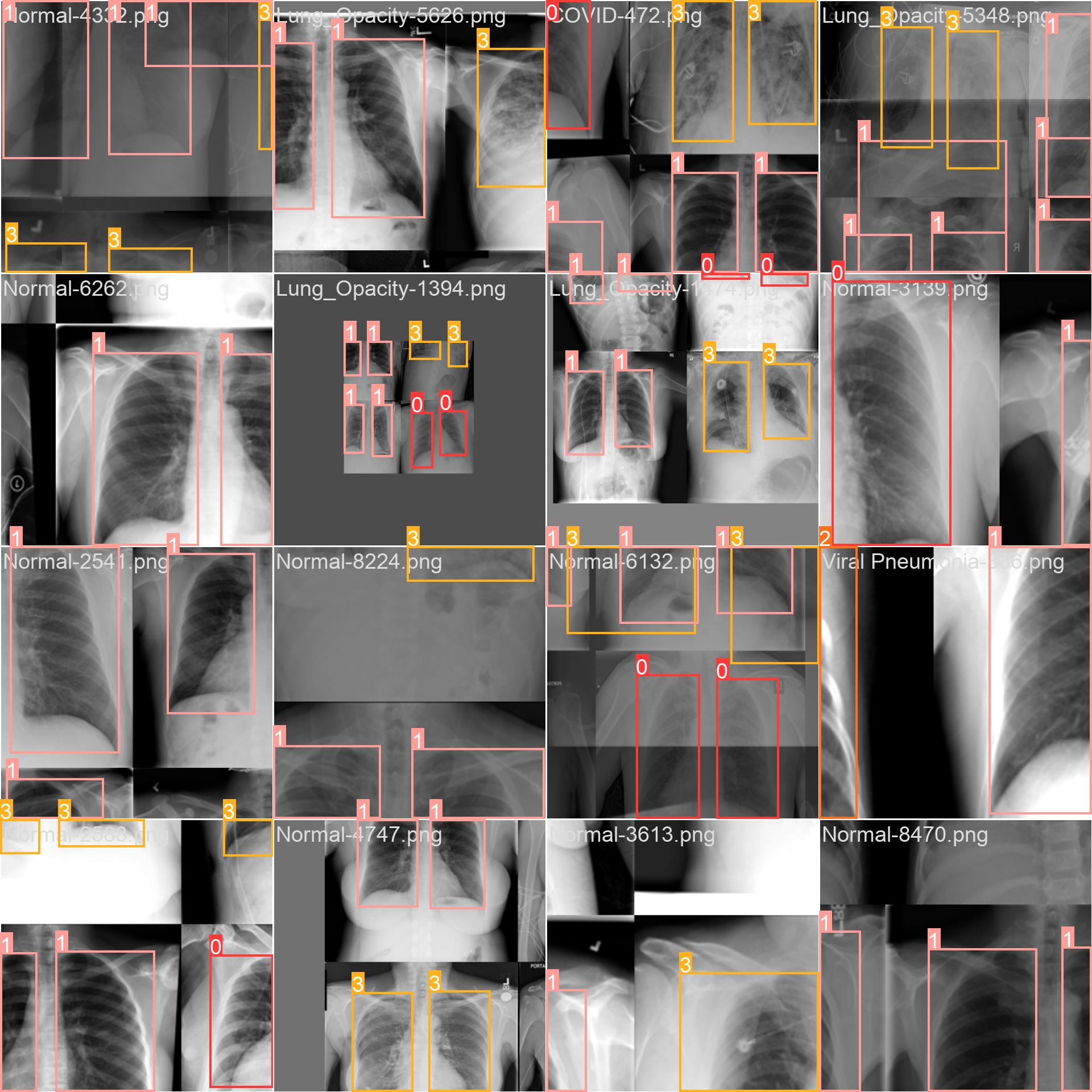
以及labels.jpg,则是生成相关的标签分布情况
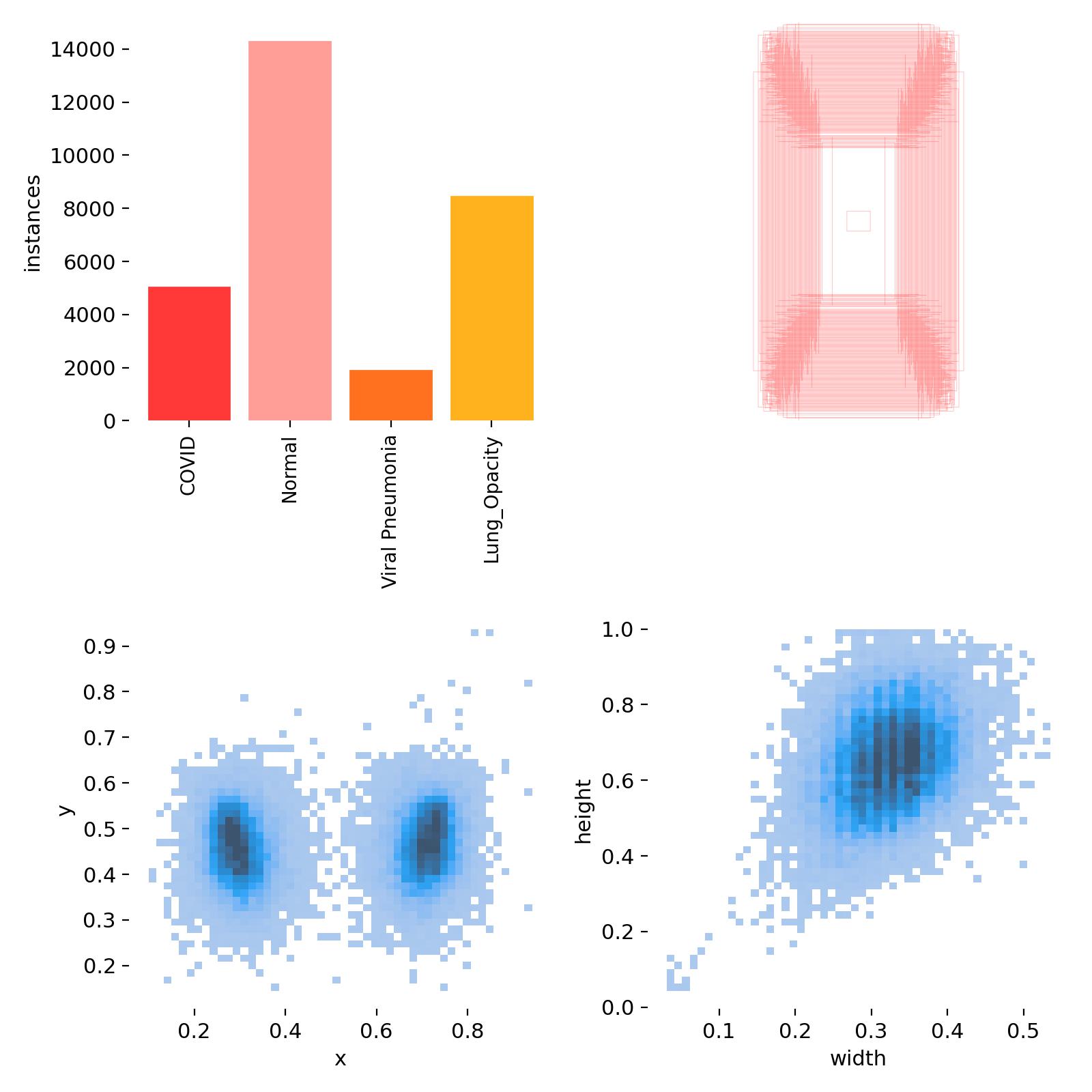

4.2 关键指标解读
- mAP@0.5:目标检测平均精度(IoU=0.5 时),值越高检测效果越好。
- loss:包含分类损失(class loss)和回归损失(box loss),稳定下降表示模型在收敛。
常见问题与优化建议
- 标签文件错误:确保标签文件名与图片名完全一致(仅扩展名不同),避免中文路径
- 显存不足:降低--batch-size或--imgsz,或使用混合精度训练(YOLOv5 默认开启)。
- 类别不平衡:通过--class-weights提升少数类权重,或使用数据增强增加少数类样本。
- 模型参数:初始的模型权重参数我们是要在YOLOv5的官网上下载的,根据硬件和需求下载合适的权重参数。比如,本人是为了参加统计建模大赛只是服务于论文,所以就不会用太精准的不然太耗时了。
通过以上步骤,即可快速在 YOLOv5 中运行自定义数据集。实际应用中可根据硬件条件和任务需求调整参数,进一步优化检测效果。
YOLOv5官网:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









