






SparkSQL 是 Apache Spark 的一个模块,用于处理结构化数据。它提供了一个高性能、分布式的 SQL 查询引擎,可以轻松处理各种数据源,包括结构化数据、半结构化数据和非结构化数据12。
SparkSQL 的特点
-
易整合:SparkSQL 无缝整合了 SQL 查询与 Spark 编程,可以随时用 SQL 或者 DataFrame 的 API 进行处理结构化数据,并且支持多语言(Java、Scala、Python、R)2。
-
统一的数据访问:使用相同的方式,连接不同的数据源或者不同文件格式中的数据,支持读写数据从不同的数据来源到不同的数据来源2。
-
兼容 Hive:在已有的数据仓库上直接运行 SQL 或者 HiveSQL,也可以使用 SparkSQL 直接处理数据并生成 Hive 数据表2。
-
标准的数据连接:支持标准化的 JDBC 或者 ODBC 连接,方便和各种数据库进行数据交换2。
SparkSQL 的发展历史
SparkSQL 的前身是 Shark,由伯克利实验室研发,基于 Hive 所开发的工具。由于对 Hive 过于依赖,制约了与 Spark 其他组件相互集合,所以提出了研发 SparkSQL 的项目2。2014 年 1.0 版本更新,Shark 和 SparkSQL 项目的负责人宣布停止 Shark 的开发,支持 Shark 发展到达终点,SparkSQL 的时代到来2。
SparkSQL 与 Hive 的区别
-
计算:Hive 依赖磁盘和内存,频繁 IO 流,而 SparkSQL 依赖内存迭代计算2。
-
源数据:两者都有源数据管理2。
-
底层运行:Hive 使用 MR,而 SparkSQL 使用 RDD2。
-
SQL 支持:两者都支持 SQL,但 SparkSQL 支持 SQL 混合其他编程语言代码2。
-
资源调度:两者都可以交给 Yarn 资源调度2。
SparkSQL 的基本用法
数据加载
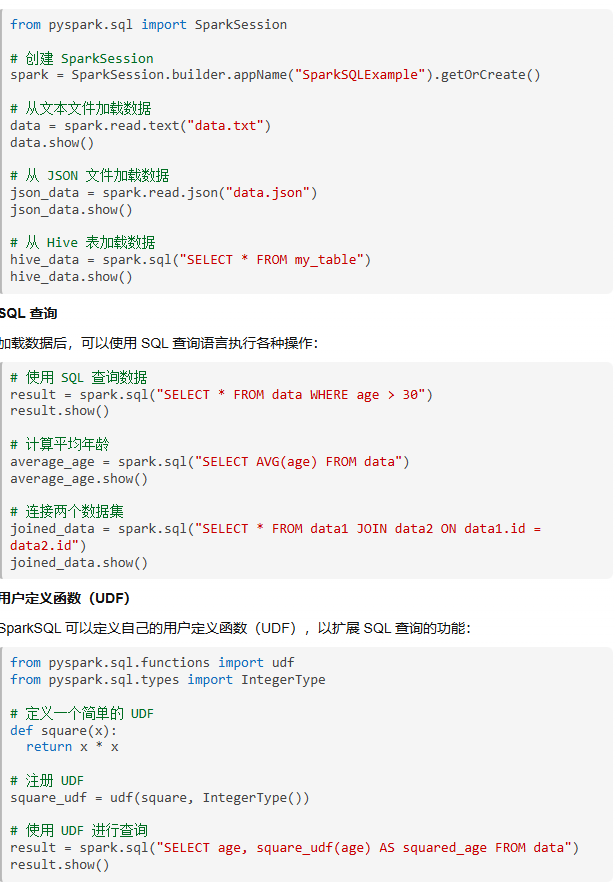
SparkSQL 支持多种数据源,包括文本文件、JSON 文件、Parquet 文件、Hive 表等。以下是一些常见的数据加载方法:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









