






 本文探讨了G1垃圾收集器中的FullGC过程,包括其串行和并行实现算法,重点介绍了引用集重构的差异以及如何处理内存紧张情况。G1的目标是减少全代GC,通过自适应调整内存和停顿时间来避免全GC的发生。
本文探讨了G1垃圾收集器中的FullGC过程,包括其串行和并行实现算法,重点介绍了引用集重构的差异以及如何处理内存紧张情况。G1的目标是减少全代GC,通过自适应调整内存和停顿时间来避免全GC的发生。
Full GC
G1的设计目标是避免Full GC的发生,用户设置合理的内存、期望停顿时间,由JVM自适应地调整新生代空间大小。
但是当应用的分配速率过大时,会触发并发标记、混合回收。
但当混合回收仍然无法满足应用的分区请求时,就会触发Full GC。
若内存或者停顿时间设置得不合理,Full GC就无可避免地被触发。
本节简单讨论一下G1中的Full GC及其演化。
串行实现算法
G1中串行回收实现和前面介绍的标记压缩回收完全相同,仅仅在两个地方做了微调:
1)不会跳过任何死亡对象,是一个严格的标记压缩算法。
在前面介绍标记压缩算法实现时提到,为了提高压缩的性能,会跳过部分死亡对象。在G1中并没有支持这个功能,笔者的理解是,G1执行Full GC后全部分区都被标记为老生代,在标记压缩的过程中由于分区之间的顺序并不固定,比较难确定哪些分区生命周期更长,哪些更短。对生命周期长的分区跳过部分死亡对象符合“强分代理论”,对生命周期短的分区跳到死亡对象则不够合理,所以G1并没有提供该特性。
2)引用集重构不同。在分代连续内存管理中,如果Full GC发生后所有对象都在老生代空间,卡表则直接清除;如果Full GC发生后老生代不能存储所有的对象,卡表将全部置位。
这样设计的目的是使大多数情况下老生代都能存储所有的对象,卡表清空后,下一次执行Minor GC效率比较高。而在G1中引用集的存储方式不是采用卡表的形式,Full GC后所有的分区都是老生代,但是在混合回收时需要知道老生代分区之间的引用关系,所以在Full GC结束时必须重构引用集。
在G1中引用集的重构在早期版本中采用的是并行的处理方式,而在JDK 11中引用集重构采用并发处理方式。
并行实现算法
在JDK 10以前,G1的Full GC只有串行回收实现,在JDK 10中有一个JEP307将串行回收优化为并行回收。串行回收修改为并行回收的思路非常简单。在串行回收中只有一个GC工作线程进行回收,如图6-23所示。

图6-23 串行回收示意图
在并行回收中将多个分区划分给多个并行的GC工作线程执行,每个线程都执行标记压缩算法,如图6-24所示。

图6-24 并行回收示意图
另外,图中是一种理想的状态,n个线程负载都很均衡。但实际上,n个线程之间的任务可能并不均衡。在当前的实现中,当多个线程出现任务不均衡时,没有一种自动均衡机制。有兴趣的读者可以尝试对此进行优化。
除了并行化进行标记压缩实现之外,并行实现中还有两个值得注意的地方:
1)并发重构引用集。在串行回收中,对引用集进行并行重构,目的是保证后续发生的混合回收能正确处理引用关系。而JDK 11将并行工作优化为并发工作,进一步减少Full GC的停顿时间。这个优化的思路是,当Full GC发生后暂时不重构引用集,只保证在混合回收发生前引用集重构完成。所以重构工作可以通过并发标记来触发(原因是并发标记是在混合回收之前执行的),并保证在并发标记结束之前完成引用集重构即可。
2)处理极限内存不足的情况。在内存非常紧张且GC工作线程比较多的情况下,很有可能出现下面的情况:多个GC工作线程只有最后一个分区是不完全满的,其他分区都已经压缩满了,如图6-25所示。
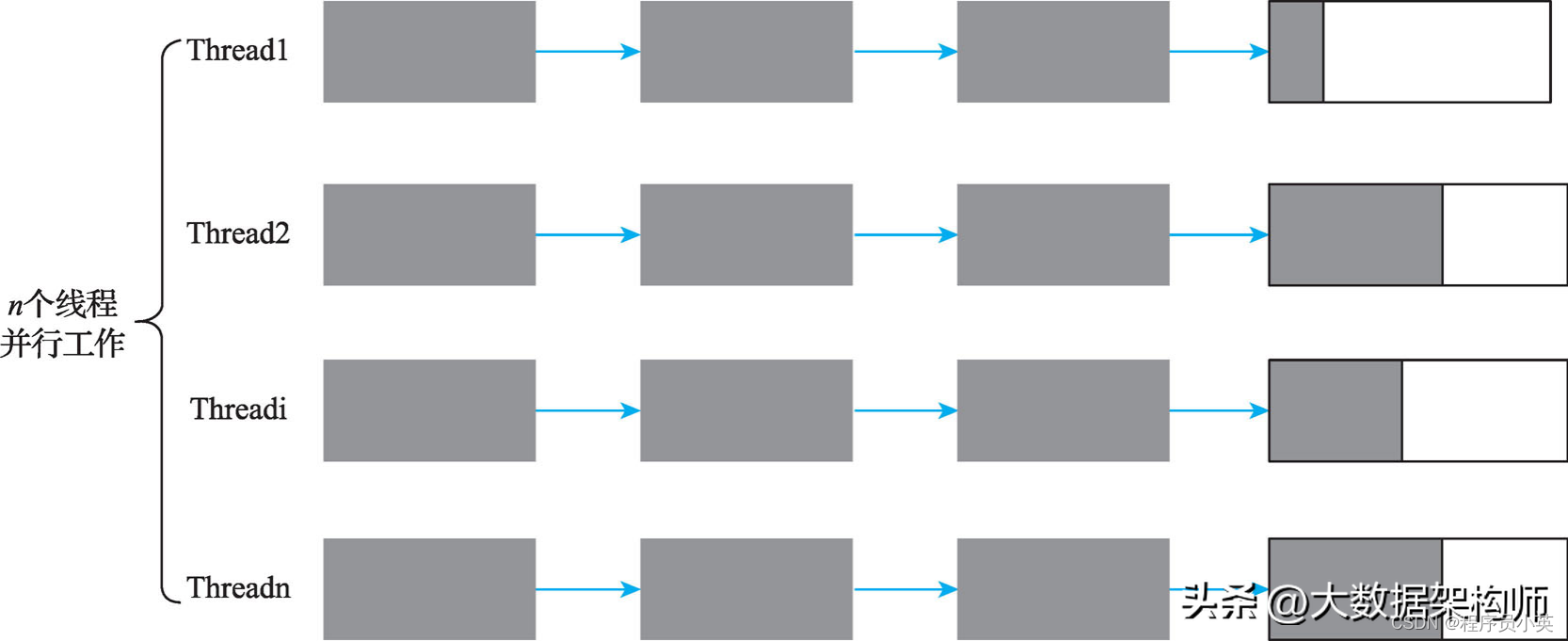
图6-25 只有最后一个分区不满的场景
对于这种情况,当Full GC执行完成后,实际上没有任何一个完整的空闲分区,也就是说无法产生新生代空间,从而也无法响应应用的对象分配请求。
对这种情况又进行了一次优化处理,将多个线程中每个线程尾部的最后一个分区拿出来重新进行一次串行压缩,从而释放出完整的自由分区。
注意,由于对象头总是与分区头对齐的,因此对所有线程尾部的分区重新进行压缩,完全不影响已经压缩满的分区。

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









