







当对象分配失败,会进入到Evac失败过程,在GC日志详情中会打印相关信息。发生失败一般意味着不能继续分配,此时需要做两件事:
- 处理失败。
- 再次尝试分配,仍不成功,进行Full GC(FGC)。
本章主要介绍:Evac失败后的处理过程,Java 10之前的串行FGC以及Java 10引入的并行FGC。
Evac失败
失败处理主要是在G1CollectedHeap::handle_evacuation_failure_par中把对象放入Evac失败栈,同时会对栈对象进行处理,处理过程是串行的。
src\share\vm\gc_implementation\g1\g1CollectedHeap.cpp
oop G1CollectedHeap::handle_evacuation_failure_par(
G1ParScanThreadState* _par_scan_state, oop old) {
assert(obj_in_cs(old),
err_msg("obj: " PTR_FORMAT " should still be in the CSet",
p2i(old)));
markOop m = old->mark();
oop forward_ptr = old->forward_to_atomic(old);
if (forward_ptr == NULL) {
// Forward-to-self succeeded.
assert(_par_scan_state != NULL, "par scan state");
OopsInHeapRegionClosure* cl = _par_scan_state->evac_failure_closure();
uint queue_num = _par_scan_state->queue_num();
_evacuation_failed = true;
_evacuation_failed_info_array[queue_num].register_copy_failure(old->size());
if (_evac_failure_closure != cl) {
MutexLockerEx x(EvacFailureStack_lock, Mutex::_no_safepoint_check_flag);
assert(!_drain_in_progress,
"Should only be true while someone holds the lock.");
// Set the global evac-failure closure to the current thread's.
assert(_evac_failure_closure == NULL, "Or locking has failed.");
set_evac_failure_closure(cl);
// Now do the common part.
handle_evacuation_failure_common(old, m);
// Reset to NULL.
set_evac_failure_closure(NULL);
} else {
// The lock is already held, and this is recursive.
assert(_drain_in_progress, "This should only be the recursive case.");
handle_evacuation_failure_common(old, m);
}
return old;
} else {
// Forward-to-self failed. Either someone else managed to allocate
// space for this object (old != forward_ptr) or they beat us in
// self-forwarding it (old == forward_ptr).
assert(old == forward_ptr || !obj_in_cs(forward_ptr),
err_msg("obj: " PTR_FORMAT " forwarded to: " PTR_FORMAT " "
"should not be in the CSet",
p2i(old), p2i(forward_ptr)));
return forward_ptr;
}
}
void G1CollectedHeap::handle_evacuation_failure_common(oop old, markOop m) {
preserve_mark_if_necessary(old, m);
HeapRegion* r = heap_region_containing(old);
if (!r->evacuation_failed()) {
r->set_evacuation_failed(true);
_hr_printer.evac_failure(r);
}
push_on_evac_failure_scan_stack(old);
if (!_drain_in_progress) {
// prevent recursion in copy_to_survivor_space()
_drain_in_progress = true;
drain_evac_failure_scan_stack();
_drain_in_progress = false;
}
}
void G1CollectedHeap::preserve_mark_if_necessary(oop obj, markOop m) {
assert(evacuation_failed(), "Oversaving!");
// We want to call the "for_promotion_failure" version only in the
// case of a promotion failure.
if (m->must_be_preserved_for_promotion_failure(obj)) {
_objs_with_preserved_marks.push(obj);
_preserved_marks_of_objs.push(m);
}
}
void G1CollectedHeap::push_on_evac_failure_scan_stack(oop obj) {
_evac_failure_scan_stack->push(obj);
}
void G1CollectedHeap::drain_evac_failure_scan_stack() {
assert(_evac_failure_scan_stack != NULL, "precondition");
while (_evac_failure_scan_stack->length() > 0) {
oop obj = _evac_failure_scan_stack->pop();
_evac_failure_closure->set_region(heap_region_containing(obj));
obj->oop_iterate_backwards(_evac_failure_closure);
}
}处理过程发生在G1ParCopyColsure中,思路也非常简单,就是把对象加入到dirty card队列中处理。这么做的目的是如果对象复制发生了一部分,该如何处理?最好的办法就是直接更新对象的RSet,不需要对已经复制的对象做额外回收之类的处理。
我们在JVM G1源码分析——新生代回收对象复制中提到,如果失败,则把对象的指针指向自己。所以整个JVM中如果发现指针指向自己则认为发生了复制失败。所以在处理Evac失败的时候(在YGC的时候已经提到,Evac失败处理是发生在YGC的并行阶段之后,具体可以回顾JVM G1源码分析——新生代回收的内容),需要检查是否有指向自己的指针。如果有的话,则需要删除指针,恢复对象头。删除指针处理的入口在remove_self_forwarding_pointers中,代码如下所示:
src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
void G1CollectedHeap::remove_self_forwarding_pointers() {
G1ParRemoveSelfForwardPtrsTask rsfp_task(this);
if (G1CollectedHeap::use_parallel_gc_threads()) {
set_par_threads();
workers()->run_task(&rsfp_task);
set_par_threads(0);
} else {
rsfp_task.work(0);
}
// CSet中所有分区重置状态
reset_cset_heap_region_claim_values();
while (!_objs_with_preserved_marks.is_empty()) {
oop obj = _objs_with_preserved_marks.pop();
markOop m = _preserved_marks_of_objs.pop();
obj->set_mark(m);
}
_objs_with_preserved_marks.clear(true);
_preserved_marks_of_objs.clear(true);
}并行任务G1ParRemoveSelfForwardPtrsTask的处理主要是通过Closure遍历分区。我们直接看Closure的代码,如下所示:
src/share/vm/gc_implementation/g1/g1EvacFailure.hpp
bool RemoveSelfForwardPtrHRClosure::doHeapRegion(HeapRegion *hr) {
bool during_initial_mark = _g1h->g1_policy()->during_initial_mark_pause();
bool during_conc_mark = _g1h->mark_in_progress();
if (hr->claimHeapRegion(HeapRegion::ParEvacFailureClaimValue)) {
if (hr->evacuation_failed()) {
RemoveSelfForwardPtrObjClosure rspc(_g1h, _cm, hr, &_update_rset_cl,
during_initial_mark,
during_conc_mark,
_worker_id);
hr->note_self_forwarding_removal_start(during_initial_mark, during_
conc_mark);
_g1h->check_bitmaps("Self-Forwarding Ptr Removal", hr);
hr->rem_set()->reset_for_par_iteration();
hr->reset_bot();
_update_rset_cl.set_region(hr);
// 对分区处理,调用closure
hr->object_iterate(&rspc);
hr->rem_set()->clean_strong_code_roots(hr);
hr->note_self_forwarding_removal_end(during_initial_mark,
during_conc_mark,
rspc.marked_bytes());
}
}
return false;
}
};继续看对象指针辅助函数RemoveSelfForwardPtrObjClosure,其主要工作在do_object中,代码如下所示:
src/share/vm/gc_implementation/g1/g1EvacFailure.hpp
void RemoveSelfForwardPtrObjClosure::do_object(oop obj) {
HeapWord* obj_addr = (HeapWord*) obj;
size_t obj_size = obj->size();
HeapWord* obj_end = obj_addr + obj_size;
if (_end_of_last_gap != obj_addr) {
_last_gap_threshold = _hr->cross_threshold(_end_of_last_gap, obj_addr);
}
// 恢复对象头信息
if (obj->is_forwarded() && obj->forwardee() == obj) {
if (!_cm->isPrevMarked(obj)) {
_cm->markPrev(obj);
}
if (_during_initial_mark) {
_cm->grayRoot(obj, obj_size, _worker_id, _hr);
}
_marked_bytes += (obj_size * HeapWordSize);
obj->set_mark(markOopDesc::prototype());
// 设置卡表信息,把卡表设置为deferred
obj->oop_iterate(_update_rset_cl);
} else {
// 对象已经成功转移或者已经无效了,所以设置dummy对象进行填充
MemRegion mr(obj_addr, obj_size);
CollectedHeap::fill_with_object(mr);
// 把这些不活跃对象的标记位清除,在回收时可以回收这些对象
_cm->clearRangePrevBitmap(MemRegion(_end_of_last_gap, obj_end));
}
_end_of_last_gap = obj_end;
_last_obj_threshold = _hr->cross_threshold(obj_addr, obj_end);
}
};其中把卡表设置为deferred的代码如下:
src/share/vm/gc_implementation/g1/g1EvacFailure.hpp
template <class T> void UpdateRSetDeferred::do_oop_work(T* p) {
assert(_from->is_in_reserved(p), "paranoia");
if (!_from->is_in_reserved(oopDesc::load_decode_heap_oop(p)) &&
!_from->is_survivor()) {
size_t card_index = _ct_bs->index_for(p);
if (_ct_bs->mark_card_deferred(card_index)) {
_dcq->enqueue((jbyte*)_ct_bs->byte_for_index(card_index));
}
}
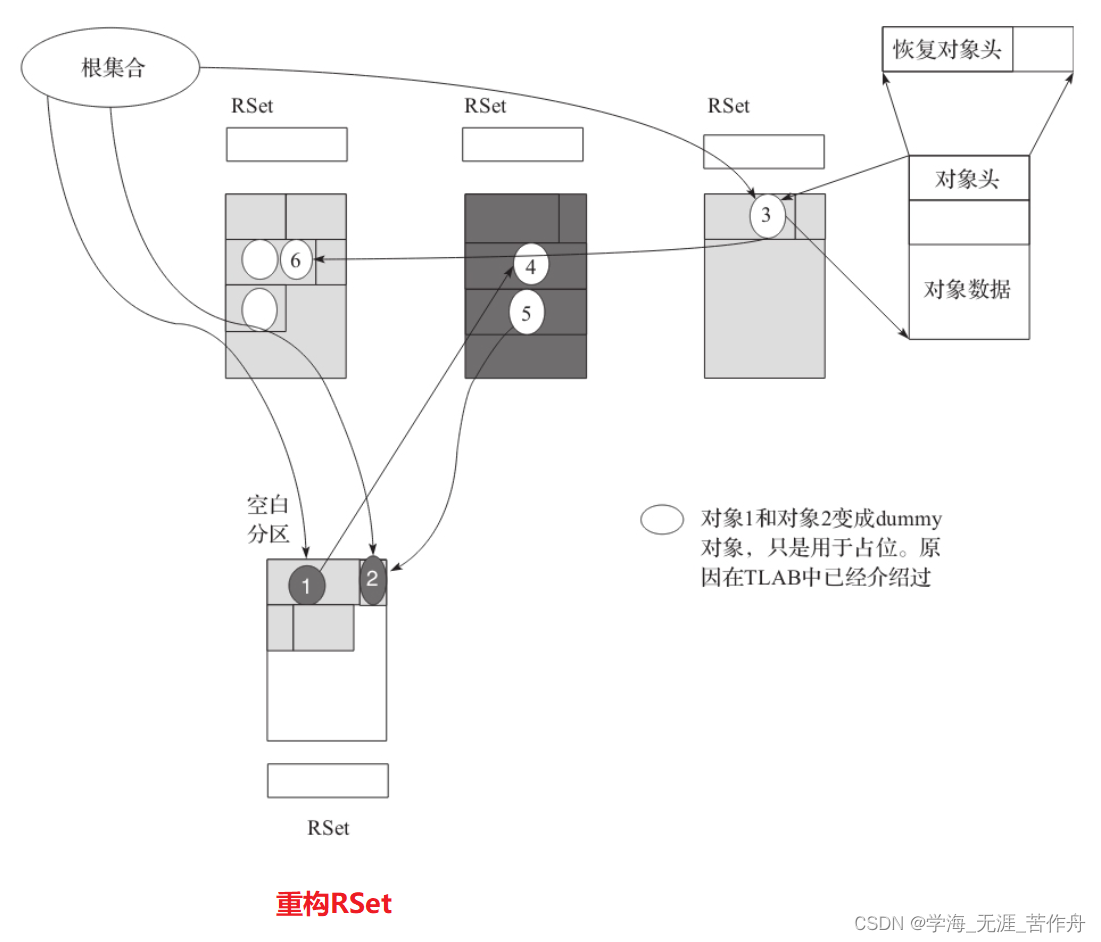
}设置为deferred的目的就是为了重构RSet。
Evac失败演示示意图
这里重用YGC中的演示示意图,如下图所示:

假设在根处理时对象3复制发生失败,不能复制。则把对象3里面的Pointer标记指向自己,形成自引用。然后继续向下处理,注意这里的处理类似于跳过失败的对象,然后进行正常路径的处理。只不过需要一个额外的动作,即把对象放入到一个特殊的dirty card队列中。
继续向下即处理RSet,处理RSet时发现对象2已经成功复制,所以正常更新指针,即用对象2的新地址更新对象5的field。假设之后对象都不能成功复制,最终的内存布局如下图所示:
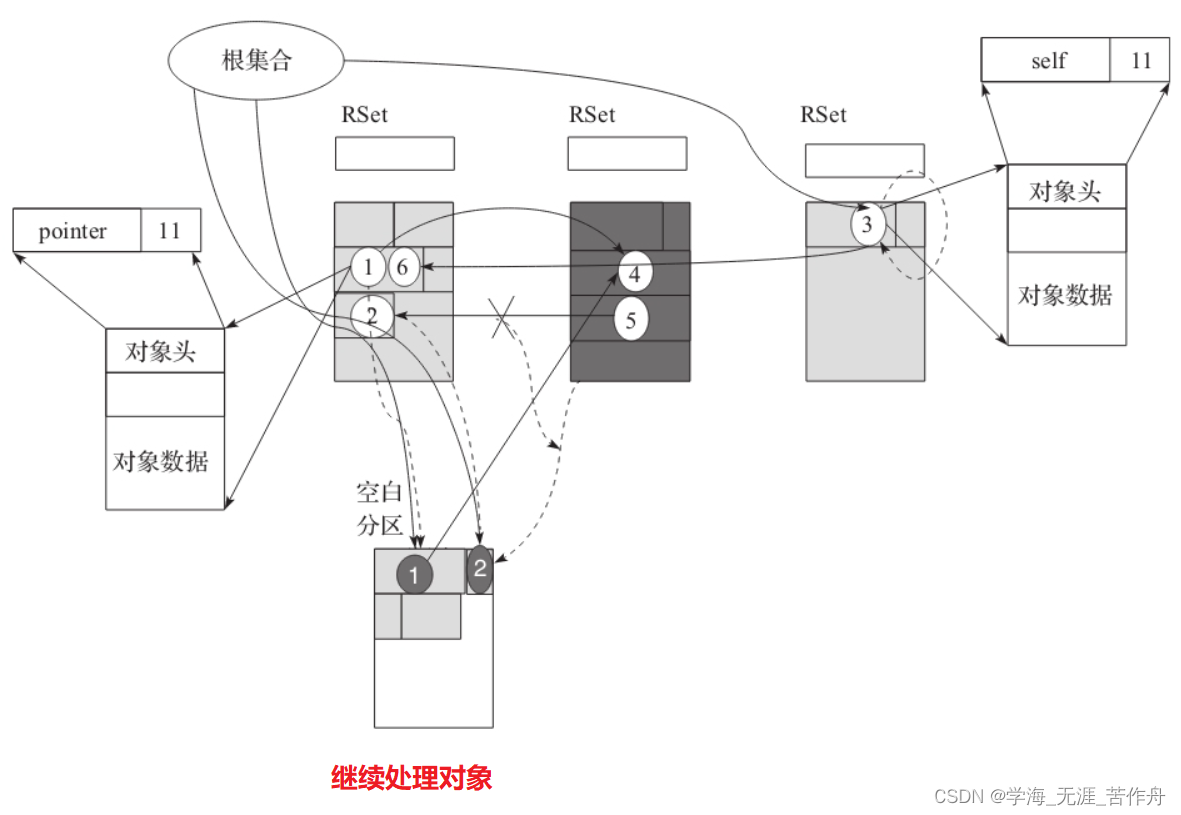
接下来就是Evac特有的步骤,删除自引用。自引用对象都应该是活跃对象。同时对于已经被复制的对象需要把他们变成dummy对象,因为这个时候他们已经可以被回收了,如下图所示。
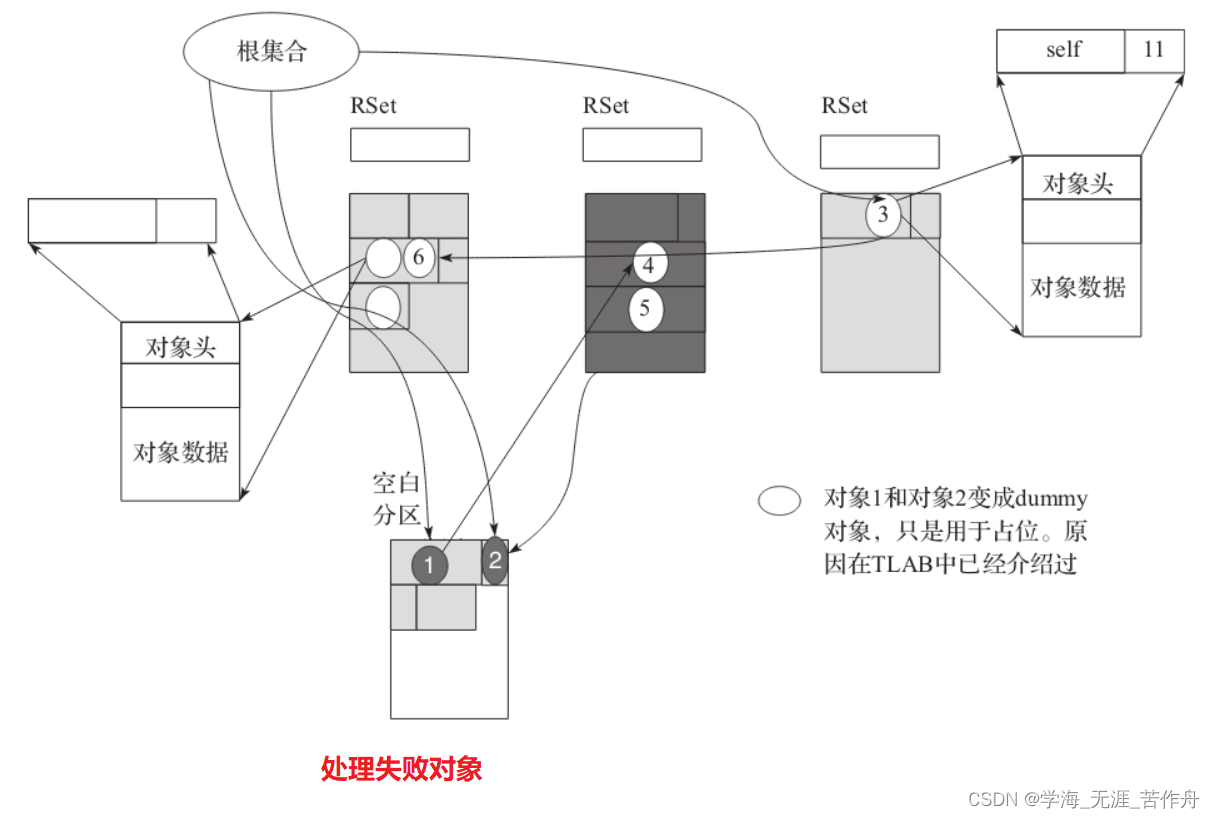
最后一步也是执行Redirty重构整个RSet,如下图所示,确保引用的正确性。
串行FGC
Evac失败后会进入到FGC,在JDK 10之前FGC都是串行回收。在串行回收之前需要做一些预处理,主要有停止并发标记、停止增量回收等动作。这些不再赘述,FGC在G1CollectedHeap::do_collection中调用G1MarkSweep::invoke_at_safepoint。串行回收采用的标记清除算法,主要分为4步:
- 标记活跃对象。
- 计算新对象的地址。
- 把所有的引用都更新到新的地址上。
- 移动对象。
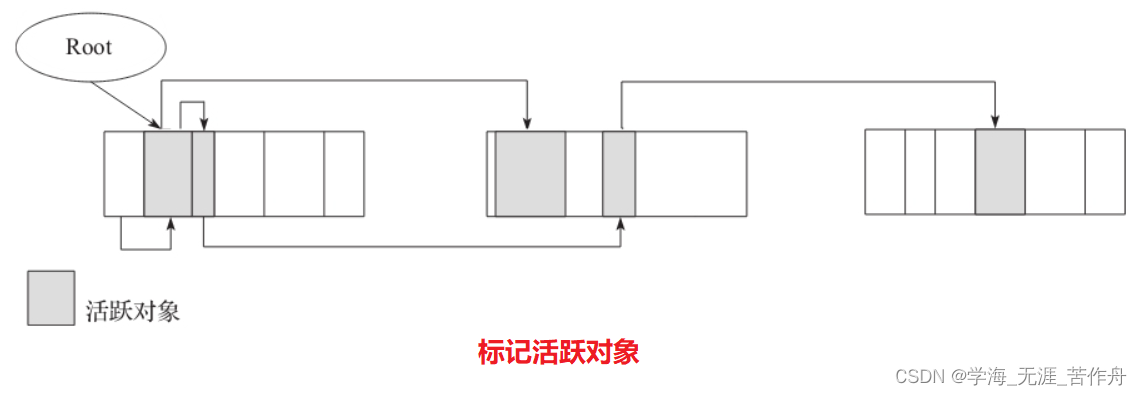
标记活跃对象
标记活跃对象代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1MarkSweep.cpp
void G1MarkSweep::mark_sweep_phase1(bool& marked_for_unloading,
bool clear_all_softrefs) {
……
// 标记处理和前面YGC提到的标记处理是类似的。不同之处在于用到的Closure以及要额外
// 处理代码对象;另外标记是串行执行的。
MarkingCodeBlobClosure follow_code_closure(&GenMarkSweep::follow_root_
closure, !CodeBlobToOopClosure::FixRelocations);
{
G1RootProcessor root_processor(g1h);
root_processor.process_strong_roots(&GenMarkSweep::follow_root_closure,
&GenMarkSweep::follow_cld_closure,
&follow_code_closure);
}
/*针对所有的根处理,通过FollowRootClosure触发标记,主要工作从follow_root开始。也是两件事情:1)标记根对象;2)标记对象的每一个字段然后入栈(在follow_contents中处理,调用了MarkSweep::mark_and_push)。*/
template <class T> inline void MarkSweep::follow_root(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
if (!obj->mark()->is_marked()) {
mark_object(obj);
obj->follow_contents();
}
}
follow_stack();
}
// follow_stack则是对栈的对象一个一个遍历处理(标记每一个字段)
void MarkSweep::follow_stack() {
do {
while (!_marking_stack.is_empty()) {
oop obj = _marking_stack.pop();
assert (obj->is_gc_marked(), "p must be marked");
obj->follow_contents();
}
// 在处理对象数组时,需要一个元素一个元素地处理,如果直接处理整个数组对象可能
// 导致标记溢出
if (!_objarray_stack.is_empty()) {
ObjArrayTask task = _objarray_stack.pop();
ObjArrayKlass* k = (ObjArrayKlass*)task.obj()->klass();
k->oop_follow_contents(task.obj(), task.index());
}
} while (!_marking_stack.is_empty() || !_objarray_stack.is_empty());
}
// 需要注意的是,第一所有的根要顺序处理,第二在处理对象的时候会把对象对应的klass
// 对象也标记处理。对引用对象标记处理,前面已经介绍过了。
ReferenceProcessor* rp = GenMarkSweep::ref_processor();
rp->setup_policy(clear_all_softrefs);
const ReferenceProcessorStats& stats =
rp->process_discovered_references(&GenMarkSweep::is_alive,
&GenMarkSweep::keep_alive,
&GenMarkSweep::follow_stack_closure,
NULL,
gc_timer(),
gc_tracer()->gc_id());
// 对系统字典、符号表标记、编译代码、klass做卸载处理,这里的卸载就是把无用对象从这些
// 全局对象中删去,但是对象的内存并没有释放。
bool purged_class = SystemDictionary::do_unloading(&GenMarkSweep::is_alive);
CodeCache::do_unloading(&GenMarkSweep::is_alive, purged_class);
Klass::clean_weak_klass_links(&GenMarkSweep::is_alive);
G1CollectedHeap::heap()->unlink_string_and_symbol_table(&GenMarkSweep::is_
alive);
}假设系统堆的初始情况如下图所示(假设有3个分区,FGC并不关心是新生代分区还是老生代分区)。

第一步操作之后,会对活跃对象标记,如下图所示。
计算对象的新地址
第二步最主要的工作就是找到每个对象应该在什么位置。从分区的底部开始扫描,同时设置compact top也为底部,当对象被标记,即活跃时,把对象的oop指针设置为compact top,这个值就是对象应该所处的位置。主要工作在heapRegion::prepare_for_compaction中。代码如下所示:
src/share/vm/gc_implementation/g1/g1MarkSweep.cpp
void G1MarkSweep::mark_sweep_phase2() {
prepare_compaction();
}
void ContiguousSpace::prepare_for_compaction(CompactPoint* cp) {
SCAN_AND_FORWARD(cp, top, block_is_always_obj, obj_size);
}SCAN_AND_FORWARD()函数定义在src/share/vm/memory/space.hpp中。这一部分代码是用宏实现的,主要的工作就是计算每个对象对应新位置的指针,这个指针表示如果移除垃圾对象之后,它应该在的位置。具体可参见源码。第二步结束后,我们可以得到下图,图中用虚线的指针表示对象的新位置。
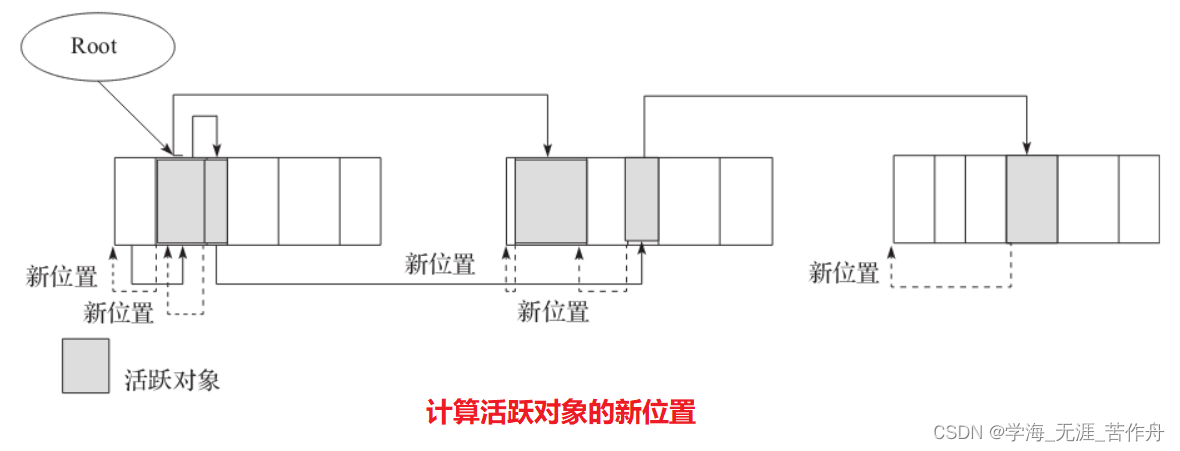
更新引用对象的地址
在上一步中,我们找到了对象的新位置,然后通过对象头里面的指针指向新位置。这一步最主要的工作就是遍历活跃对象,然后把活跃对象和活跃对象中的引用更新到新位置。代码如下:
src/share/vm/gc_implementation/g1/g1MarkSweep.cpp
void G1MarkSweep::mark_sweep_phase3() {
// 状态复位
ClassLoaderDataGraph::clear_claimed_marks();
// 更新根对象的引用
CodeBlobToOopClosure adjust_code_closure(&GenMarkSweep::adjust_pointer_
closure, CodeBlobToOopClosure::FixRelocations);
{
G1RootProcessor root_processor(g1h);
root_processor.process_all_roots(&GenMarkSweep::adjust_pointer_closure,
&GenMarkSweep::adjust_cld_closure,
&adjust_code_closure);
}
g1h->ref_processor_stw()->weak_oops_do(&GenMarkSweep::adjust_pointer_closure);
// 处理引用,不活跃对象的引用会被清除
JNIHandles::weak_oops_do(&always_true, &GenMarkSweep::adjust_pointer_
closure);
if (G1StringDedup::is_enabled()) {
G1StringDedup::oops_do(&GenMarkSweep::adjust_pointer_closure);
}
// 在第一步的时候,有些对象如果有特殊的对象头,会被入栈保存起来,这里会调整这些保存的对象头
GenMarkSweep::adjust_marks();
G1AdjustPointersClosure blk;
g1h->heap_region_iterate(&blk);
}G1AdjustPointersClosure对每一个分区都要处理,处理的方式是针对每一个活跃对象遍历它的每一个字段,更新字段的引用。代码位于:
src/share/vm/oops/instanceKlass.cpp
int InstanceKlass::oop_adjust_pointers(oop obj) {
int size = size_helper();
InstanceKlass_OOP_MAP_ITERATE( \
obj, \
MarkSweep::adjust_pointer(p), \
assert_is_in)
return size;
}其中宏定义MarkSweep::adjust_pointer的代码如下所示:
src/share/vm/gc_implementation/shared/markSweep.inline.hpp
template <class T> inline void MarkSweep::adjust_pointer(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
oop new_obj = oop(obj->mark()->decode_pointer());
if (new_obj != NULL) {
// 更新指针位置
oopDesc::encode_store_heap_oop_not_null(p, new_obj);
}
}
}如下图所示,虚线指针表示对象的新位置,点划线指针表示对象引用所在的新位置,要注意的是,对象的指针都指向对象的首地址。
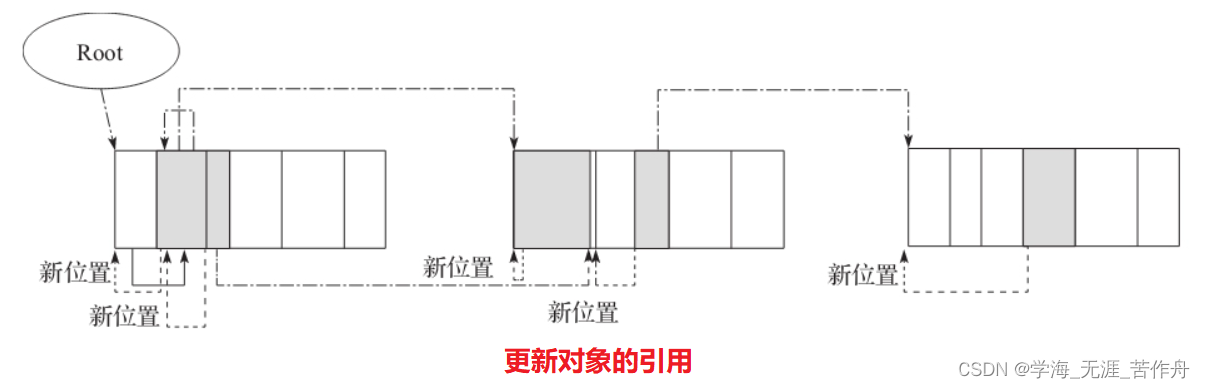
移动对象完成压缩
最后一步就是完成空间的压缩。遍历时必须从前向后依次开始,否则数据会被破坏。代码如下所示:
src/share/vm/gc_implementation/g1/g1MarkSweep.cpp
void G1MarkSweep::mark_sweep_phase4() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
G1SpaceCompactClosure blk;
g1h->heap_region_iterate(&blk);
}具体的处理在该文件的G1SpaceCompactClosure类中,代码如下所示:
class G1SpaceCompactClosure: public HeapRegionClosure {
public:
G1SpaceCompactClosure() {}
bool doHeapRegion(HeapRegion* hr) {
if (hr->isHumongous()) {
if (hr->startsHumongous()) {
oop obj = oop(hr->bottom());
if (obj->is_gc_marked()) {
obj->init_mark();
} else {
assert(hr->is_empty(), "Should have been cleared in phase 2.");
}
hr->reset_during_compaction();
}
} else {
hr->compact();
}
return false;
}
};其中compact()位于hotspot/src/share/vm/memory/space.cpp中。代码如下所示:
void CompactibleSpace::compact() {
SCAN_AND_COMPACT(obj_size);
}这里的宏SCAN_AND_COMPACT(obj_size)位于hotspot/src/share/vm/memory/space.inline.hpp。这个宏逻辑不算复杂,这里就不再列出全部代码。这个宏的主要工作就是:把对象复制到新的地址,然后重新设置对象头,这就是压缩工作。代码如下所示:
Copy::aligned_conjoint_words(q, compaction_top, size); \
oop(compaction_top)->init_mark(); \下图是示意图,把对象进行复制。
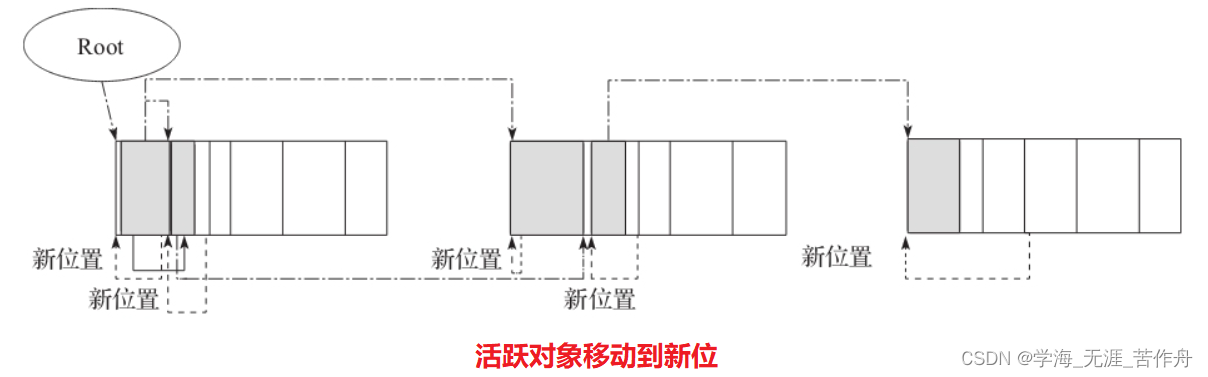
复制之后,通过双点划指针还是可以有效地访问对象,而虚线指针变成无用的。
后处理
在第四步压缩结束以后,实际上我们看到分区并没有发生调整,仅仅是把已经死亡的对象回收,而活跃的对象仍然保留在本分区内。所以在G1CollectedHeap::do_collection中还需要进行后处理,我们把几个主要的步骤拿出来:
1)尝试调整整个堆空间的大小,主要工作在G1CollectHeap::resize_if_necessary_after_full_collection中,这里会用到两个参数MinHeapFreeRatio(默认值为40)和MaxHeapFreeRatio(默认值为70)。代码如下所示:
src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
resize_if_necessary_after_full_collection(size_t word_size) {
const size_t used_after_gc = used();
const size_t capacity_after_gc = capacity();
const size_t free_after_gc = capacity_after_gc - used_after_gc;
const double minimum_free_percentage = (double) MinHeapFreeRatio / 100.0;
const double maximum_used_percentage = 1.0 - minimum_free_percentage;
const double maximum_free_percentage = (double) MaxHeapFreeRatio / 100.0;
const double minimum_used_percentage = 1.0 - maximum_free_percentage;
const size_t min_heap_size = collector_policy()->min_heap_byte_size();
const size_t max_heap_size = collector_policy()->max_heap_byte_size();
double used_after_gc_d = (double) used_after_gc;
double minimum_desired_capacity_d = used_after_gc_d / maximum_used_percentage;
double maximum_desired_capacity_d = used_after_gc_d / minimum_used_percentage;
double desired_capacity_upper_bound = (double) max_heap_size;
minimum_desired_capacity_d = MIN2(minimum_desired_capacity_d,
desired_capacity_upper_bound);
maximum_desired_capacity_d = MIN2(maximum_desired_capacity_d,
desired_capacity_upper_bound);
size_t minimum_desired_capacity = (size_t) minimum_desired_capacity_d;
size_t maximum_desired_capacity = (size_t) maximum_desired_capacity_d;
minimum_desired_capacity = MIN2(minimum_desired_capacity, max_heap_size);
maximum_desired_capacity = MAX2(maximum_desired_capacity, min_heap_size);
if (capacity_after_gc < minimum_desired_capacity) {
size_t expand_bytes = minimum_desired_capacity - capacity_after_gc;
expand(expand_bytes);
} else if (capacity_after_gc > maximum_desired_capacity) {
size_t shrink_bytes = capacity_after_gc - maximum_desired_capacity;
shrink(shrink_bytes);
}
}根据GC发生后已经使用的内存除以期望的占比得到期望的空间大小,然后利用期望值和实际值的比较来判断是否需要扩展或者收缩堆空间。扩展堆空间我们在前面已经介绍,这里稍微提一下收缩空间,收缩主要发生的动作就是把空闲分区标记为uncommit,用于后续分配。
2)遍历堆,重构RSet。因为所有的分区里面的对象位置都发生了变化,我们在第三步的时候也把对象位置变化的指针都更新了,但是这里还有一个重要的事情,就是重构RSet,否则下一次发生GC就会丢失根集合,导致回收错误。重构Rset主要通过ParRebuildRSTask完成,对每一个分区根据对象的引用关系重构RSet。
3)清除dirty Card队列,并把所有的分区都认为是old分区。
4)最后记录各种信息,同时会调整YGC的大小,在G1CollectHeap::record_full_collection_end会调用update_young_list_target_length重建Eden,用于下一次回收。
并行FGC
FGC是Java程序员努力要避免的,但是由于JVM的不可控,在长时间运行的应用中FGC基本上不可避免。所以如何调优避免FGC是广大程序员奋斗的目标之一。在FGC发生之后,通常都是串行执行回收。G1的FGC基本上和其他的垃圾回收器是一样的,重用了以前的代码,只是稍做适配。另一个解决思路就是当FGC发生时,让FGC并行化,减少FGC的时间。实际上G1因为分区的引入,可以实现一套并行的FGC。有一个新的项目JEP 307正是这个目的,该项目已经发布到JDK 10的代码[插图]中,为了便于大家获取JDK 10的代码,我也将代码下载并上传到GitHub[插图]。同时串行的FGC也从G1中移除。并行调用可以分为:
·收集前处理:prepare_collection这一步是保存一些信息,如对象头、偏向锁等;相关内容比较简单不再赘述。
·收集:collect是真正的并行回收,并行FGC的步骤和串行FGC的步骤类似,也分为4步,代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullCollector.cpp
void G1FullCollector::collect() {
// 并行标记,从Root Set出发,这里还会对引用处理
phase1_mark_live_objects();
// 这是针对C2的优化,记录对象的派生关系,开始GC之前先暂停更新
deactivate_derived_pointers();
// 并行准备压缩,找到对象的新的位置
phase2_prepare_compaction();
// 并行调整指针
phase3_adjust_pointers();
// 并行压缩
phase4_do_compaction();
}·后处理:complete_collection,恢复对象头等信息。
下面我们看一下并行回收的每一步都做了什么工作。
并行标记活跃对象
FGC的并行标记类似于并发标记。但比并发标记简单,因为它不涉及SATB处理。代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullCollector.cpp
void G1FullCollector::phase1_mark_live_objects() {
// 从根出发,做并行标记。因为这里是并行处理,使用一个额外的数据结构标记栈,处理标记对象
G1FullGCMarkTask marking_task(this);
run_task(&marking_task);
// 处理引用
G1FullGCReferenceProcessingExecutor reference_processing(this);
reference_processing.execute(scope()->timer(), scope()->tracer());
// 弱引用对象清理
{
// 在FGC中可以直接处理弱引用
WeakProcessor::weak_oops_do(&_is_alive, &do_nothing_cl);
}
// 类元数据卸载
if (ClassUnloading) {
// 卸载元数据和符号表
bool purged_class = SystemDictionary::do_unloading(&_is_alive, scope()-
>timer());
_heap->complete_cleaning(&_is_alive, purged_class);
} else {
// 卸载符号表和字符串表,在第9章和第10章会看到这两个表的具体结构
_heap->partial_cleaning(&_is_alive, true, true, G1StringDedup::is_enabled());
}
}并行标记任务主要在G1FullGCMarkTask完成,多个GC线程从不同的根出发,完成标记,当线程任务完成后可以尝试窃取别的线程尚未处理完的对象进行标记。代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullGCMarkTask.cpp
void G1FullGCMarkTask::work(uint worker_id) {
Ticks start = Ticks::now();
ResourceMark rm;
G1FullGCMarker* marker = collector()->marker(worker_id);
MarkingCodeBlobClosure code_closure(marker->mark_closure(), !CodeBlobTo
OopClosure::FixRelocations);
// 这个root_processor我们在前面已经看到。就是从根集合出发进行处理,这里传入的
// Closure是标记动作
if (ClassUnloading) {
_root_processor.process_strong_roots(
marker->mark_closure(),
marker->cld_closure(),
&code_closure);
} else {
_root_processor.process_all_roots_no_string_table(
marker->mark_closure(),
marker->cld_closure(),
&code_closure);
}
// 遍历标记栈里面的所有对象
marker->complete_marking(collector()->oop_queue_set(), collector()->array_
queue_set(), &_terminator);
}处理引用也可以并行处理,处理过程见后文。
计算对象的新地址
并行处理是针对每一个分区,计算对象的新地址。与串行FGC不一样的地方就是,串行处理中,每一个分区的有效对象都会移动到该分区的头部。而并行处理的时候,一个并发线程通常要处理多个分区,所以在计算对象的新地址时可以把这一批分区里面的对象进行压缩,这样就可能出现完全空闲的分区。代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullCollector.cpp
void G1FullCollector::prepare_compaction_common() {
G1FullGCPrepareTask task(this);
// 并行处理
run_task(&task);
/*这一步的处理是因为并行处理之后,发现所有的线程处理完之后不存在一个完全空闲的分区,此时的状态就是每个线程除了最后一个分区,处理的其他分区都是满的,为了降低内存碎片,可以把所有线程处理的最后的一个分区合并,这个合并是串行处理的。这完全是为了优化,防止OOM */
if (!task.has_freed_regions()) {
task.prepare_serial_compaction();
}
}主要的并行工作在G1FullGCPrepareTask中,代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullGCPrepareTask.cpp
void G1FullGCPrepareTask::work(uint worker_id) {
G1FullGCCompactionPoint* compaction_point = collector()->compaction_point
(worker_id);
// 这里其实就是根据标记的情况,并行地计算对象的新位置
G1CalculatePointersClosure closure(collector()->mark_bitmap(), compaction_
point);
G1CollectedHeap::heap()->heap_region_par_iterate_from_start(&closure, &_
hrclaimer);
// 如果发现有大对象分区,且分区里面的对象都已经死亡,可以直接释放分区
closure.update_sets();
compaction_point->update();
// 根据上面的分析,因为并行计算对象会压缩对象,所以可以判断是否有需要释放的分区,
// 如果没有要释放的分区,说明原来有几个分区,这个线程处理之后还有几个分区。
if (closure.freed_regions()) {
set_freed_regions();
}
}由于并行处理可能需要跨多个分区,所以引入了G1FullGCCompactionPoint,就是为了记录单个GC线程在计算对象位置时所用的分区情况。这里需要提示的是,除了大对象,对象是不能垮分区存放。例如前面一个分区剩下1KB,新的对象需要2KB,此时这个分区就不能存放这个对象,分区里面的起始地址都是对象的起始地址,对象不能垮分区存放,否则在对分区进行遍历的时候问题就大了。与串行处理一样,该步完成之后,每个对象头存储的都是新地址。
更新引用对象的地址
在上一步中,我们找到了所有对象的新位置,并通过对象头里面的指针指向新的位置。这一步最主要的工作就是从根集合出发遍历活跃对象,然后把活跃对象和活跃对象中的引用都更新到新的位置。其主要工作在G1FullGCAdjustTask中,代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullGCAdjustTask.cpp
void G1FullGCAdjustTask::work(uint worker_id) {
ResourceMark rm;
G1FullGCMarker* marker = collector()->marker(worker_id);
marker->preserved_stack()->adjust_during_full_gc();
// 处理根对象,根对象仅仅需要更新指针位置
CLDToOopClosure adjust_cld(&_adjust);
CodeBlobToOopClosure adjust_code(&_adjust, CodeBlobToOopClosure::FixRel
ocations);
_root_processor.process_full_gc_weak_roots(&_adjust);
// 最后process_all_roots会调用all_tasks_completed,直到所有任务完成
_root_processor.process_all_roots(
&_adjust,
&adjust_cld,
&adjust_code);
// 处理字符串去重
if (G1StringDedup::is_enabled()) {
G1StringDedup::parallel_unlink(&_adjust_string_dedup, worker_id);
}
// 处理每一个分区,对每一个活跃对象更新指针,并且要更新对象的引用关系RSet。与串行回收
// 中提到的一样,这里对象并没有移动,它们的指针指向对象将要在的新位置。
G1AdjustRegionClosure blk(collector()->mark_bitmap(), worker_id);
G1CollectedHeap::heap()->heap_region_par_iterate_from_worker_offset(&blk, &_hrclaimer, worker_id);
}移动对象完成压缩
最后一步就是完成空间的压缩。代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullCollector.cpp
void G1FullCollector::phase4_do_compaction() {
/*并行压缩,第二步中每个线程处理一部分分区,都已经计算好了对象的位置,所以这一步可以把对象复制到新的位置。这个压缩任务比较简单不再介绍。*/
G1FullGCCompactTask task(this);
run_task(&task);
// 这一步也是根据第二步中的结果,如果进行了串行压缩,则队尾分区进行一次串行处理。
if (serial_compaction_point()->has_regions()) {
task.serial_compaction();
}
}后处理
这一步主要就是恢复对象头,更新各种信息等。代码如下所示:
jdk10u/src/Hotspot/share/gc/g1/g1FullCollector.cpp
void G1FullCollector::complete_collection() {
/*在进行并行标记的时候,会把对象的对象头存放起来,此时把它们都恢复。注意这个地方存储对象头信息的数据结构实际上是一个map,就是对象和对象头的信息。当经过上述压缩过程,这个对象的地址当然也就更新了,所以可以直接恢复。*/
restore_marks();
// 这是为了C2的优化,因为对象的位置发生了变化,所以必须更新对象派生关系的地址
update_derived_pointers();
// 恢复偏向锁的信息
BiasedLocking::restore_marks();
// 做各种后处理,更新新生代的长度等
CodeCache::gc_epilogue();
JvmtiExport::gc_epilogue();
_heap->prepare_heap_for_mutators();
_heap->g1_policy()->record_full_collection_end();
}日志解读
发生FGC时,通常在日志中可以看到Full GC这样的信息,下面是程序发生FGC后的日志片段:
[Full GC (Allocation Failure) 123M->76M(128M), 0.2036229 secs]
[Eden: 0.0B(6144.0K)->0.0B(19.0M) Survivors: 0.0B->0.0B Heap: 123.7M(128.0M)-
>76.9M(128.0M)], [Metaspace: 4393K->4393K(1056768K)]
[Times: user=0.34 sys=0.00, real=0.20 secs]以上日志信息是完成第五步之后的信息。比如上述信息表明在FGC后Eden从6M变成19M,总体空间从123.7M变成76.9M。
参数介绍和调优
FGC是我们一般要避免的操作,但是如果非常不幸FGC发生之后,如何能够尽快完成并且避免以后再发生FGC,这是需要程序员进行调优的,这里稍微介绍几个参数:
·参数MinHeapFreeRatio,这个值用于判断是否可以扩展堆空间,增大该值扩展概率变小,减小该值扩展几率变大。
·参数MaxHeapFreeRatio,这个值用于判断是否可以收缩堆空间,增大该值收缩概率变小,减小该值收缩概率变大。
·参数MarkSweepAlwaysCompactCount,默认值为4,这个值表示经过一定次数的GC之后,允许当前区域空间中一定比例的空间用来将死亡对象当作存活对象处理,这里姑且将这些对象称为弥留对象,把这片空间称为弥留。这个比例由MarkSweepDeadRatio控制,默认值为5,该参数的作用是加快FGC的处理速度。















 6511
6511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









