







操作环境:
MATLAB 2022a
1、算法描述
Q-learning是一种无模型的强化学习算法,适用于有限的马尔可夫决策过程(MDP)。它的核心是学习一个动作价值函数(action-value function),即Q函数,这个函数用于估计在某状态下采取特定动作能带来的期望回报。
详细步骤如下:
初始化Q表:首先,我们需要初始化一个Q表,这个表格包含了所有可能状态和在这些状态下可以采取的动作的组合。每个状态-动作对应的值(Q值)初始通常设为0。
探索与利用:在每个时间步骤,智能体(agent)需要决定是探索新动作还是利用已知的信息。这通常通过ε-greedy策略实现,即以ε的概率进行随机探索,以1-ε的概率选择当前已知最优动作。
动作执行和环境反馈:智能体根据选定的策略执行动作,然后环境会根据智能体的动作提供下一个状态和奖励。
Q值更新:智能体根据获得的奖励和预期未来回报更新Q表。
重复过程:重复上述过程,直到满足某些停止准则,例如达到最大迭代次数或Q表收敛。
2、仿真结果演示
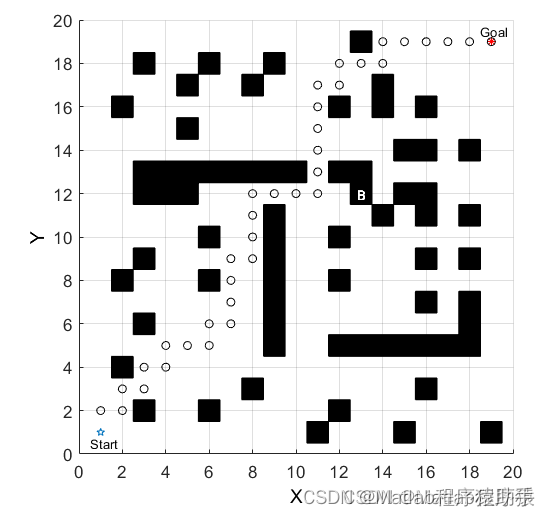
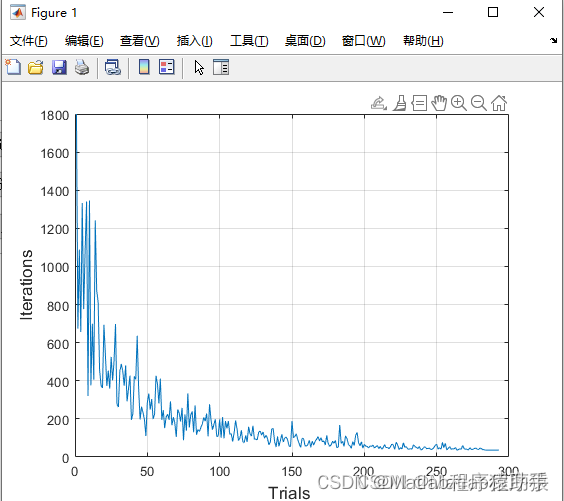
3、关键代码展示
略
4、MATLAB 源码获取
点击下方原文链接获取














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









