







 文章讲述了如何在深度学习中利用预训练权重,如MobileNetV2,通过调整全连接层节点数和冻结/微调特征层来优化模型性能。作者强调了迁移学习的优势,尤其是在加载预训练权重后快速收敛。同时提到了一份针对Linux运维的系统学习资源。
文章讲述了如何在深度学习中利用预训练权重,如MobileNetV2,通过调整全连接层节点数和冻结/微调特征层来优化模型性能。作者强调了迁移学习的优势,尤其是在加载预训练权重后快速收敛。同时提到了一份针对Linux运维的系统学习资源。
而第三种方法,在创建网络时候,更改最后的全连接层节点个数,直接net.load_state_dict()方法载入会报错的
net = MobileNetV2()
net.load_state_dict(torch.load(pre_trained_pth), strict=False)
//方法三:
in_channel = net.fc.in_feacture
net.fc = nn.Linear(in_channel, 5) //这里为什么是.fc,道理同下,下面具体讲解了
这里另外说一下为什么删除预训练权重中全连接层的参数,上方代码的判断语句中必须是“fc”???
其实不然,取决于你搭建网络时类变量名称的定义,可以通过来查看每个网络层的名称:
net = MobileNetV2(class_nums=5)
print(net)
//或者
for name in net.named_modules():
print(name)

例如:上面的红框中网络的全连接层名称是classifier,那么我们在删除全连接层的参数的时候就是if “classifier” not in k。
或者把网络结构中的classifier改成fc。这里全连接层的名称完全取决于我们自己。

2.载入预训练权重后两种情况
特征层的权重参数在反向传播过程中会求导,冻结特征层,可以缩短训练时间。
2.1冻结全部的特征提取层,微调全连接层
我们如果想要在短时间内将我们的模型达到一个相对理想的效果,可以将特征层全部冻结(全部使用别人预训练权重),然后只训练全连接层,根据我们自己的数据集类别进行fine-tuning。
for param in net.parameters(): //这里的就遍历每个特征层上的权重参数了
param.requires_grad = False
2.2冻结部分的特征层
在卷积神经网络中,特征提取层就是卷积层的部分,因为一开始卷积得到的特征图上的信息多为一些简单的信息:边缘、转角等,这类简单的特征对于大多数的对象都是通用的,所以我们可以冻结低层的权重,以减少训练时间。
for param in net.xx特征层名称.parameters(): //这里的xx特征层名称取决于搭建网络时的定义
param.requires_grad = False
2.3不冻结特征提取层
我认为这能够取得比较好的效果,在以别人的预训练权重参数为基础,继续寻找梯度最优,但可能比起上面冻结特征层,会增加时间上的负担。
3.直观上的结果对比
红色曲线是:载入别人预训练权重后,冻结特征层的loss和精确率;
蓝色曲线是:载入别人预训练权重后,没有冻结特征层,在此基础上继续梯度优化;
黑色曲线是:没有采用迁移学习,让搭建的网络模型随机初始化权重开始训练。
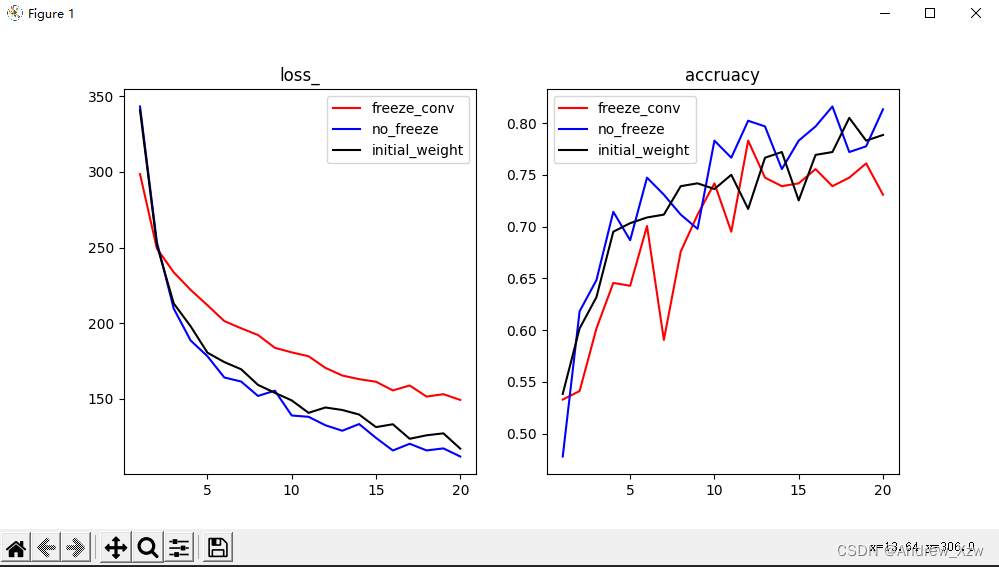
conclusion:
载入预训练权重,拿别人的参数作为一开始的初始化,更容易达到最优;而比起从头开始一点一点随机初始化,让模型胡乱地找梯度最优的方向。肯定迁移学习更好。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









