







为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
“version”:1
}
1 . 准备好JSON文件,然后使用分区重新分配工具生成候选分配,命令如下:
bin/kafka-reassign-partitions.sh --zookeeper dn1:2181 --topics-to-move-json-file topics-to-move.json --broker-list “1,2” --generate
执行完成命令之后,控制台出现如下信息:
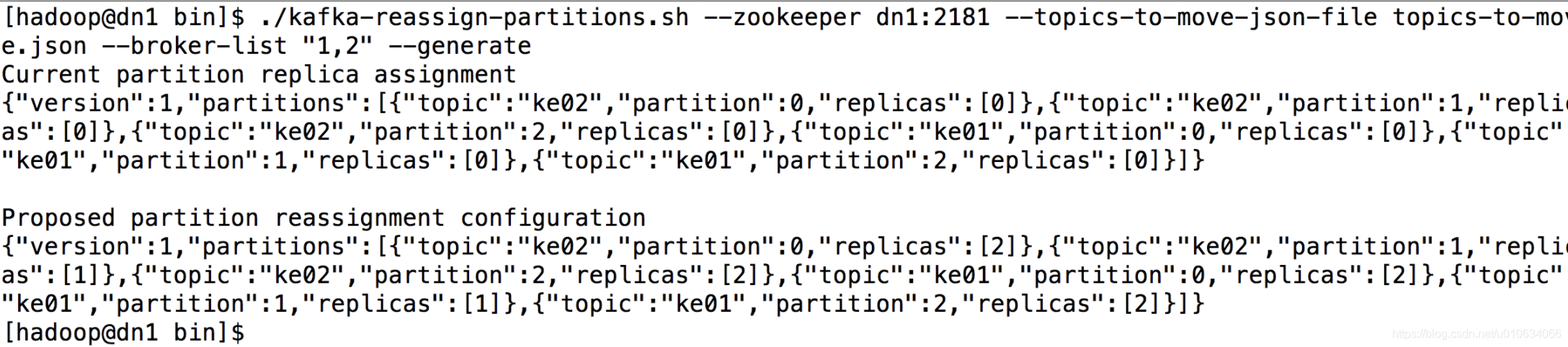
该工具生成一个候选分配,将所有分区从Topic ke01,ke02移动到Broker1和Broker2。需求注意的是,此时分区移动尚未开始,它只是告诉你当前的分配和建议。保存当前分配,以防你想要回滚它。新的赋值应保存在JSON文件(例如expand-cluster-reassignment.json)中,以使用–execute选项执行。JSON文件如下:
{“version”:1,“partitions”:[{“topic”:“ke02”,“partition”:0,“replicas”:[2]},{“topic”:“ke02”,“partition”:1,“replicas”:[1]},{“topic”:“ke02”,“partition”:2,“replicas”:[2]},{“topic”:“ke01”,“partition”:0,“replicas”:[2]},{“topic”:“ke01”,“partition”:1,“replicas”:[1]},{“topic”:“ke01”,“partition”:2,“replicas”:[2]}]}
2. 执行命令如下所示:
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
3. 最后,–verify选项可与该工具一起使用,以检查分区重新分配的状态。需要注意的是,相同的expand-cluster-reassignment.json(与–execute选项一起使用)应与–verify选项一起使用,执行命令如下:
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
执行结果如下图所示:

数据迁移的几个注意点
减少迁移的数据量: 如果要迁移的Topic 有大量数据(Topic 默认保留7天的数据),可以在迁移之前临时动态地调整retention.ms 来减少数据量,比如下面命令改成1小时; Kafka 会主动purge 掉1小时之前的数据;
bin/kafka-topics --zookeeper localhost:2181 --alter --topic sdk_counters --config retention.ms=3600000
不要要注意迁移完成后,恢复原先的设置
迁移过程注意流量陡增对集群的影响
Kafka提供一个broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限,当重新平衡集群,引导新broker,添加或移除broker时候,这是很有用的。因为它限制了这些密集型的数据操作从而保障了对用户的影响、
例如我们上面的迁移操作
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
在后面加上一个—throttle 50000000 参数, 那么执行移动分区的时候,会被限制流量在50000000 B/s
加上参数后你可以看到
The throttle limit was set to 50000000 B/s
Successfully started reassignment of partitions.
迁移过程限流不能过小,导致迁移失败
-throttle 是broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限; 但是你应该了解到正常情况下,副本直接也是有副本同步的流量的; 如果限制的低于正常副本同步的流量值,那么会导致副本同步异常,跟不上Leader的速率很快就被踢出ISR了;
迁移完成,注意要移除流量的限制:
如果我们加上了迁移这个操作, 需要使用参数--verify 来验证执行状态,同时流量限制也会被移除掉; 否则可能会导致定期复制操作的流量也受到限制。
./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
详情请参考
Logi-KafkaManager 实现数据迁移
了解完了手动迁移的流程后,那我们再来了解一下KM的迁移动作,那么你会爱上这个操作;因为极大的简化了迁移操作;
下图中是创建一个 迁移任务的操作; 解释一下里面的几个参数;
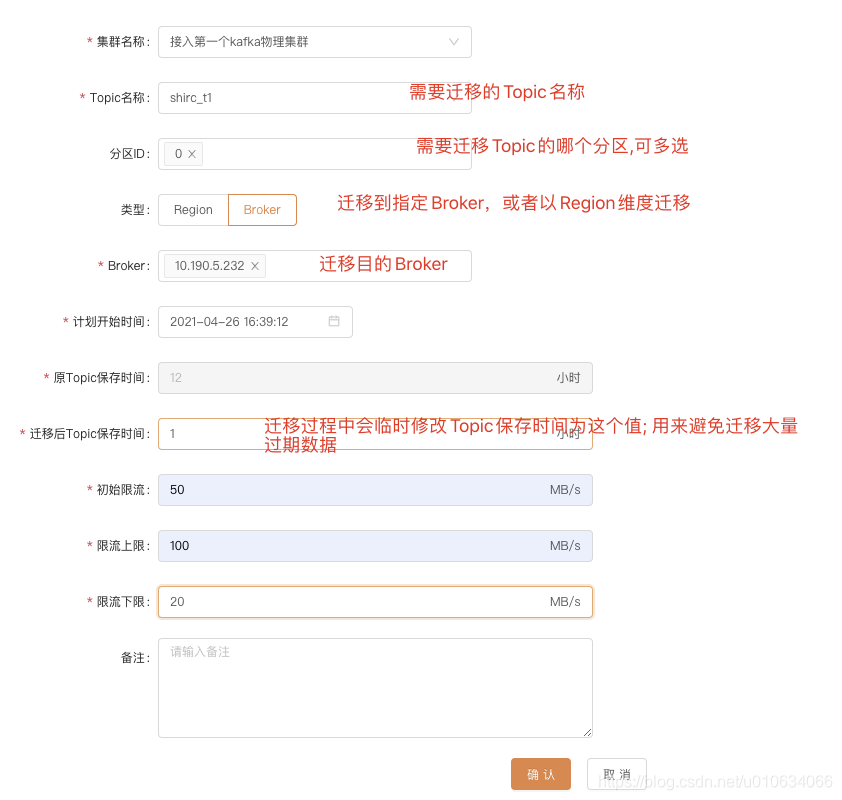
上面我主要讲解几个参数
迁移后Topic的保存时间:
我们上面讲解迁移注意事项的时候有讲解到,需要 减少迁移的数据量 ; 假如你默认保存了7天的数据量, 那么这个迁移的数据量可能非常的大,并且很多都是已经消费过得过期数据; 所以我们需要在先把这么多过期数据给清理掉之后再开始迁移; 这个参数填的就是保存最近多久的数据;删掉过期的数据; 并且迁移结束之后会把时间改回成原来的时间;
初始限流:
限流上线:
限流下线:
可能你看到这几个参数会很奇怪, 限流不就是一个确定的值么,填一个限流值就行了,搞这么多是要干啥;
其实是 KM想做成的是动态调整限流, 根据不同时间和集群状态去动态调整, 比如空闲时候我最大可以允许你流量达到100M/s(限流上线); 但是如果你在迁移的时候可能压力比较大,我不想让你一开始就用这个100M/s限流; 迁移开始时候使用初始限流,但是限流不能过小,因为要考虑正常情况下副本同步时候的流量,所以有了限流下线 ;
然后KM每隔一段时间(1分钟)就会去检查迁移状态,然后动态调整限流值;
当然,现在KM中其实用的还是初始限流这个值来作为限流; 并没有动态的来调整流速; 这个是将来需要改造的点;
创建完迁移任务之后,KM定时器检测到达到开始时间之后,就会开始正式迁移;
执行的过程跟我们上面讲到的迁移流程一样,只是程序自动帮我们去实现了;
如果数据量大,迁移任务建议放在空闲时间段
集群任务
这个模块是用于自动化kafka集群升级用的,但是需要配合夜莺系统来使用(主要是在KM上将升级包发送到服务器上);
这个功能对应大集群来说非常好用,自动在线升级; 不需要手动去操作;
简单看一下使用图


如何对接夜莺系统, 等我有空再补充 对接夜莺系统,TODO
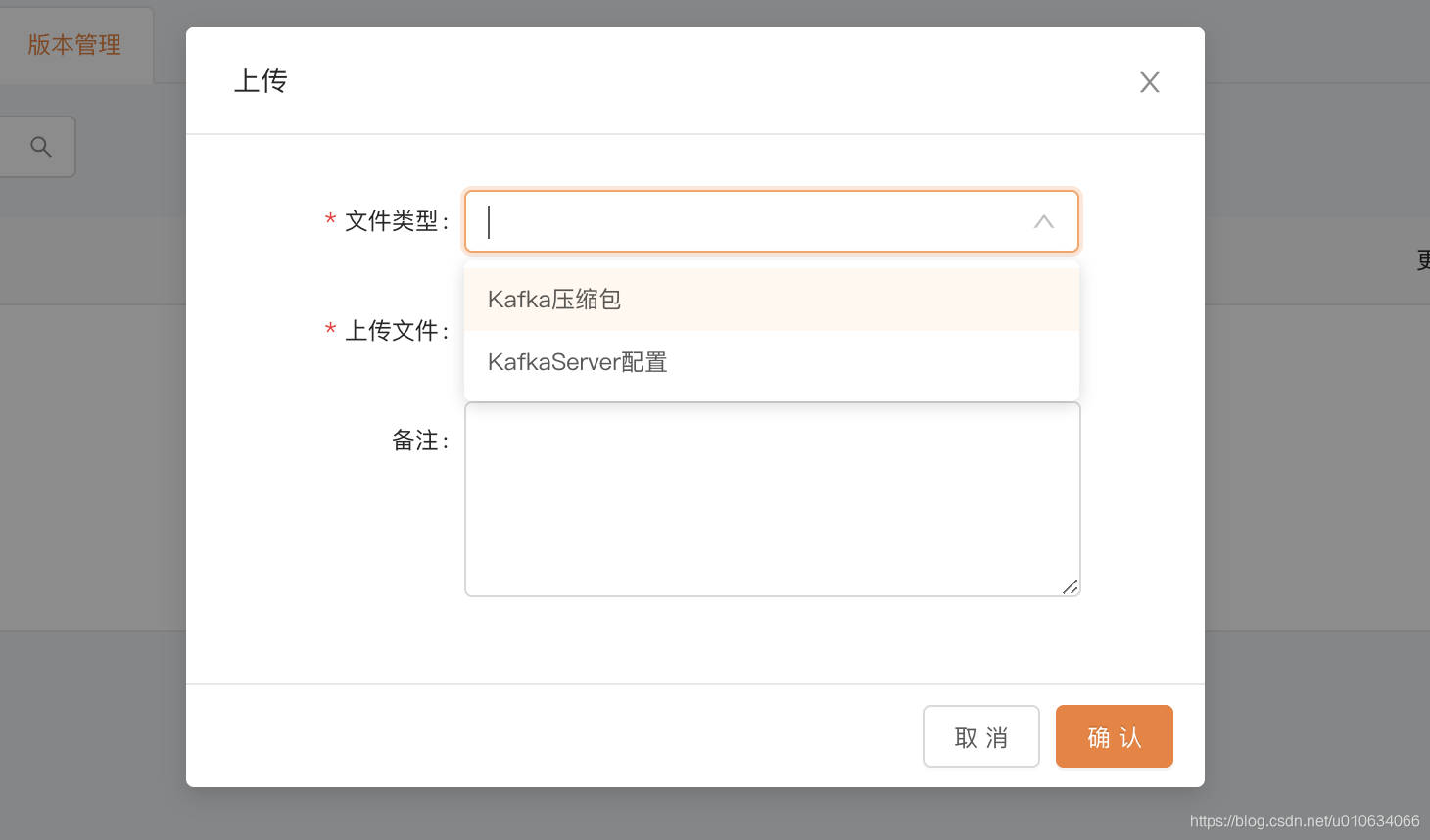
版本管理
创建集群任务的时候, 需要上传 kafka升级包,和配置文件集
Kafka的灵魂伴侣Logi-KafkaManger(5)之运维管控–平台管理(用户管理和平台配置)
======================================================================
Kafka的灵魂伴侣Logi-KafkaManger一之集群的接入及相关概念讲解
Kafka的灵魂伴侣Logi-KafkaManger二之kafka针对Topic粒度的配额管理(限流)
Kafka的灵魂伴侣Logi-KafkaManger三之运维管控–集群列表
欢迎 Star和 共建由 滴滴开源的kafka的管理平台,非常优秀非常好用的一款kafka管理平台
满足所有开发运维日常需求
滴滴开源Logi-KafkaManager 一站式Kafka监控与管控平台
欢迎加个人微信拉你进开发技术交流群,群内专人解答技术疑问
(请备注:技术) wx: jjdlmn_ 或 wx: mike_zhangliang


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
rocess=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTA2MzQwNjY=,size_16,color_FFFFFF,t_70#pic_center)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









