







val sum = deferred.sumOf { it.await().toLong() }
val useTime = System.currentTimeMillis() - start
println("end,useTime = ${useTime},sum = $sum")
}
}
输出结果如下:
start
end,useTime = 3923,sum = 500000500000
`GlobalScope.async { }`启动的协程必须等到调用了`await()`函数之后才会执行,所以这也是为什么上面的代码要使用`runBlocking { }`的原因,是为了阻塞主线程,等待100万个协程的执行结果。如果把`runBlocking { }`换成`GlobalScope.launch { }`将看不到打印结果,因为这个启动的协程还没开始运行,`main`线程就运行结束了,则所有的协程都没机会执行了。
接下来官方为了举例协程是并行运行的,原文描述如下:
> Let’s also make sure that our coroutines actually run in parallel.
`parallel`我自己翻译感觉就是并行的意思吧,不知道有没有理解错。官方为了说明协程是并行的,在协程中添加了1秒钟的延迟操作,如下:
val deferred = (1..1_000_000).map { n ->
GlobalScope.async {
delay(1000)
n
}
}
输出结果如下:
start
end,useTime = 7211,sum = 500000500000
如果不是并行而是按一个一个挨着执行的话,则每个协程延迟1秒钟则总共需要延迟100万秒,超过11.5天,而这里输出的结果为7秒钟左右,说明是并行的。
[]( )协程与线程的关系
=======================================================================
协程是运行在线程之上的,因为电脑CPU只有线程的说法,没有协程的说法,协程是由程序语言自己创建的,所以协程最终也是运行到线程上的,于是我想知道前面的代码中,开100万个协程,是跑在一个线程上还是多个线程上?实验代码如下:
fun main() {
val start = System.currentTimeMillis()
println("start")
val set = mutableSetOf<String>()
val deferred = (1..1_000_000).map { n ->
GlobalScope.async {
set.add(Thread.currentThread().name)
n
}
}
runBlocking {
val sum = deferred.sumOf { it.await().toLong() }
val useTime = System.currentTimeMillis() - start
println("end,useTime = ${useTime},sum = $sum,threadCount = ${set.size}")
set.forEach(System.out::println)
}
}
输出结果如下:
start
end,useTime = 4249,sum = 500000500000,threadCount = 4
DefaultDispatcher-worker-4
DefaultDispatcher-worker-3
DefaultDispatcher-worker-1
DefaultDispatcher-worker-2
这里我使用了Set集合来保存每个协程所属线程的线程名称,使用Set可以保证相同的线程名称只保存一次。从输出结果中可以看到,开100万个协程,这些协程是运行在4个线程之上的,为什么是4个呢?因为我的电脑是4核4线程的,有些电脑是4核8线程的,则执行相同的代码它就会输出8个线程,在Win10系统上可以打开任务管理器,切换到性能标签,查看“逻辑处理器”的个数,这个就是电脑实际上拥有的线程数,如下:
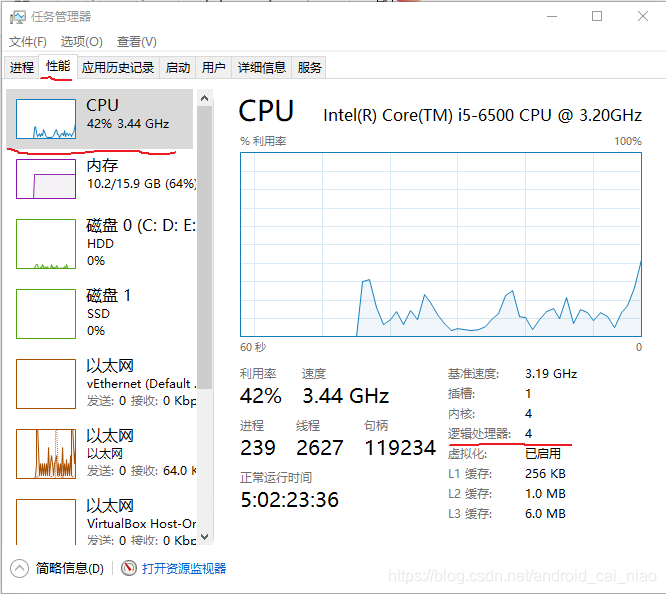
内核为4,逻辑处理器为4,说明一个内核在同一时刻只能处理一条线程。如果内核为4,逻辑处理器为8,则说明一个内核在同一时刻能处理两条线程。这里简单说一下我对CPU、内核、逻辑处理器的理解,普通人使用的电脑一般只安装一个CPU,很少有安装多个CPU的,一个CPU里面可以有多个核,这多个核就相当于把多个CPU集成到一个CPU一样,所以在早期的单核CPU时代,同一时间只能处理一个线程,而多核时代就可以同时处理多条线程。而且有的内核可以模拟成两个内核,比如内核为4,逻辑处理器为8,这就是把一个内核模拟成两个内核。所以如果你的电脑有8个逻辑处理器,就像你电脑插入了8个CPU一样,可以同一时刻处理8个线程。
这里有个疑问:为什么我们的程序可以创建100万个线程?这里用单核CPU说明,在单核CPU时代,CPU同一时刻只能处理一条线程,所以电脑里装的多个软件,就有多个线程,不管多少个线程,我们称之为软件的线程,这些软件的线程不可能同一时刻同时执行,CPU会给每个软件线程分配执行时间,比如CPU在一个软件线程上执行了几毫秒,然后就到另一个软件线程又执行几毫秒,然后又去别的软件线程执行几毫秒。。。当然了,每次执行时间可能比毫秒级还要小,也可能每次分配的时长不一样,总之我们知道CPU是轮流给线程分配执行的就OK了。
这段代码运行多次,你会发现输出的Set集合size有时为6,有时为7,有时为1,有时为3。。。,而且我发现Set的Size大于4时,集合中保存的线程名称肯定有重复的,因为只有4条线程,线程名称肯定就只有4个嘛,但是相同的名字竟然插入了多次,Set不是不允许插入重复的元素么??我就奇怪了,后来一想对了,这kotlin中的协程并不是跑在一个线程上的,是跑在多个线程上,而我对Set集合的操作又没有加入同步操作,所以就出现了问题,这充分说明了协程是并行运行的!我们修正后如下:
fun main() {
val start = System.currentTimeMillis()
println("start")
val set = mutableSetOf<String>()
val deferred = (1..1_000_000).map { n ->
GlobalScope.async {
synchronized(Any::class.java) {
set.add(Thread.currentThread().name)
}
delay(1000)
n
}
}
runBlocking {
val sum = deferred.sumOf { it.await().toLong() }
val useTime = System.currentTimeMillis() - start
println("end,useTime = ${useTime},sum = $sum,threadCount = ${set.size}")
set.forEach(System.out::println)
}
}
OK,加入同步处理之后,就每次都输出4个线程了。写到这里,我想起网上有的人说协程不需要做同步处理,我们不要被误导了,除非多个协程是跑在1个线程上就不需要做同步处理,这样的话,这多个协程其实并不是并发执行的,所以不需要做同步处理。
[]( )100万个协程可以当100万个线程用吗
==================================================================================
Kotlin官方给我们举例说明了使用100万个协程比使用100万个线程便宜多了,那协程能代替线程吗?之前官方的示例中使用delay()函数了模拟耗时操作,delay函数是一个可暂停的函数,它的功能是把协程暂停,这样该条协程对应的线程就空闲了,这条线程就可以去处理其它的协程了,delay(1000)为迟延1秒,那1秒后恢复时,如果之前的那条线程被别的协程使用,而且没使用完呢,这会怎样?很明显,协程暂停之后,恢复时不一定能在原来的线程上恢复,因为你需要恢复时可能线程已经被占用着了。Kotlin使用了线程池,所以它会从线程池中取一条空闲的线程来恢复被暂停的协程,而线程池的大小默认是跟电脑的逻辑处理器数量一样的。下面的示例代码演示了同一个协程,在不同线程上运行:
fun main() {
val start = System.currentTimeMillis()
var flag = 0
println("start")
val set = mutableSetOf<String>()
val deferred = (1..4).map { n ->
GlobalScope.async {
val coroutineFlag = ++flag
println("协程-${coroutineFlag}开始运行在线程-${Thread.currentThread().name}")
delay(1000)
println("协程-${coroutineFlag}后面运行在线程-${Thread.currentThread().name}")
synchronized(Any::class.java) {
set.add(Thread.currentThread().name)
}
n
}
}
runBlocking {
val sum = deferred.sumOf { it.await().toLong() }
val useTime = System.currentTimeMillis() - start
println("end,useTime = ${useTime},sum = $sum,threadCount = ${set.size}")
set.forEach(System.out::println)
}
}
输出结果如下:
start
协程-1开始运行在线程-DefaultDispatcher-worker-1
协程-2开始运行在线程-DefaultDispatcher-worker-2
协程-3开始运行在线程-DefaultDispatcher-worker-4
协程-4开始运行在线程-DefaultDispatcher-worker-3
协程-1后面运行在线程-DefaultDispatcher-worker-1
协程-2后面运行在线程-DefaultDispatcher-worker-3
协程-3后面运行在线程-DefaultDispatcher-worker-2
协程-4后面运行在线程-DefaultDispatcher-worker-4
end,useTime = 1142,sum = 10,threadCount = 4
DefaultDispatcher-worker-1
DefaultDispatcher-worker-3
DefaultDispatcher-worker-2
DefaultDispatcher-worker-4
这里,我们只启动了4个协程,注意看协程-2,它开始是运行在`worker-2`这个线程上的,暂停然后恢复的时候却运行在`worder-3`线程上了。
接下来,回到标题的问题上:100万个协程可以当100万个线程用吗?,这里我们简单一点问,协程可以完全替代线程来使用吗?需要做个实验来研究一下,之前我们了解到单核CPU会给多个软件线程分配执行时间,看起来电脑就像拥有多线程一样,那如果一个线程上的多个协程,该线程会给每个协程轮流分配执行时间吗(让多个协程看起来像多线程一样)?这里我们写一个readFile函数来读取一个大小为182M的文件,真实的耗时操作,我们不使用delay(1000)中虚的东西,示例代码如下:
fun main() {
val start = System.currentTimeMillis()
var flag = 0
println("程序总开始")
val deferred = (1..10).map { n ->
GlobalScope.async {
val coroutineFlag = ++flag
val useTime = readFile(coroutineFlag)
useTime
}
}
runBlocking {
val sum = deferred.sumOf { it.await() }
println("平均每个协程使用时间:${sum / 10}")
}
val useTime = System.currentTimeMillis() - start
println("程序总结束,总运行时间:$useTime")
}
private fun readFile(coroutineFlag: Int): Long {
val start = System.currentTimeMillis()
println("协程-${coroutineFlag}在${Thread.currentThread().name}开始读取文件")
val file = File("D:\\hello.mp4")
val readBytes = file.readBytes()
val fileSize = readBytes.size / 1024 / 1024
val useTime = System.currentTimeMillis() - start
println("协程-${coroutineFlag}在${Thread.currentThread().name}结束读取文件,文件大小为:${fileSize}M,使用时间为:$useTime")
return useTime
}
输出结果如下:
程序总开始
协程-1在DefaultDispatcher-worker-3开始读取文件
协程-3在DefaultDispatcher-worker-2开始读取文件
协程-2在DefaultDispatcher-worker-4开始读取文件
协程-1在DefaultDispatcher-worker-1开始读取文件
协程-1在DefaultDispatcher-worker-3结束读取文件,文件大小为:182M,使用时间为:368
协程-1在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:368
。。。
注意:这里,我们的`readFile`函数并没有声明为`suspend`,也没报错,所以在协程中做耗时操作的函数并不是一定要声明为`suspend`的,做耗时操作并不一定要挂起,所以如果你的函数里面没有挂起操作,是不需要声明为`suspend`的,如果我们在`readFile`函数上加上`suspend`,编译器会提示你这是多余的,因为你的函数内部就没有挂起操作啊,写了`suspend`等于没写。
这里,我只复制了最前面的几条记录,因为我发现输出有问题,为什么协程1开始读取出现了两次?仔细一想,还是多线程导致的问题啊,看来这个用于计数的flag也需要做多线程的同步处理啊,修改后如下:
val flag = AtomicInteger()
println("程序总开始")
val deferred = (1..10).map { n ->
GlobalScope.async {
val coroutineFlag = flag.incrementAndGet()
val useTime = readFile(coroutineFlag)
useTime
}
}
输出结果如下:
程序总开始
协程-1在DefaultDispatcher-worker-4开始读取文件
协程-4在DefaultDispatcher-worker-1开始读取文件
协程-3在DefaultDispatcher-worker-3开始读取文件
协程-2在DefaultDispatcher-worker-2开始读取文件
协程-1在DefaultDispatcher-worker-4结束读取文件,文件大小为:182M,使用时间为:413
协程-4在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:415
协程-6在DefaultDispatcher-worker-1开始读取文件
协程-5在DefaultDispatcher-worker-4开始读取文件
协程-2在DefaultDispatcher-worker-2结束读取文件,文件大小为:182M,使用时间为:421
协程-7在DefaultDispatcher-worker-2开始读取文件
协程-3在DefaultDispatcher-worker-3结束读取文件,文件大小为:182M,使用时间为:422
协程-8在DefaultDispatcher-worker-3开始读取文件
协程-5在DefaultDispatcher-worker-4结束读取文件,文件大小为:182M,使用时间为:420
协程-9在DefaultDispatcher-worker-4开始读取文件
协程-6在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:430
协程-10在DefaultDispatcher-worker-1开始读取文件
协程-7在DefaultDispatcher-worker-2结束读取文件,文件大小为:182M,使用时间为:434
协程-8在DefaultDispatcher-worker-3结束读取文件,文件大小为:182M,使用时间为:433
协程-9在DefaultDispatcher-worker-4结束读取文件,文件大小为:182M,使用时间为:312
协程-10在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:304
平均每个协程使用时间:400
程序总结束,总运行时间:1279
从结果中可以看到,并不是我们想象的那样:一个线程给多个协程轮流分配执行时间,也就是说我们希望是你执行一下,我执行一下,你执行一下,我执行一下。。。,结果并不是我们想象的那样,从结果可知,因为我们有4个逻辑处理器,所以Kotlin默认线程池创建了4个线程。我们创建了10个协程,而一开始只有4个协程分配到了线程,另外6个协程就只能等着了,等到其中一个协程读取文件结束了,才又开始了一个新的协程去执行读取文件的操作。Kotlin官方不是说协程是并行的吗,看来官方说法会让人有一些误解的,最前面在学官方开100万个协程的例子时,我们以为100万个协程是并行的呢,结果它是先并行执行4个,再并行执行4个,再并行执行4个。。。直到执行完100万个。如果我们要开一个多线程下载,比如8线程,如果使用协程简单的替换之前的多线程,明显是有问题的,因为它并不会8个协程同时下载,而是先4个协程下载,4个下载完了再来4个协程下载。
接下来我们使用传统的线程来验证一下,传统的线程是否是并行的:
fun main() {
val start = System.currentTimeMillis()
println("程序总开始")
val allThreadUseTime = AtomicLong()
val count = AtomicInteger()
(1..10).map {
thread {
val threadUseTime = readFile()
allThreadUseTime.addAndGet(threadUseTime)
if (count.incrementAndGet() == 10) {
val useTime = System.currentTimeMillis() - start
println("平均每个线程使用时间:${allThreadUseTime.get() / 10}")
println("程序总结束,总运行时间:$useTime")
}
}
}
}
private fun readFile(): Long {
val start = System.currentTimeMillis()
println("${Thread.currentThread().name}开始读取文件")
val file = File("D:\\hello.mp4")
val readBytes = file.readBytes()
val fileSize = readBytes.size / 1024 / 1024
val useTime = System.currentTimeMillis() - start
println("${Thread.currentThread().name}结束读取文件,文件大小为:${fileSize}M,使用时间为:$useTime")
return useTime
}
输出结果如下:
程序总开始
Thread-0开始读取文件
Thread-3开始读取文件
Thread-2开始读取文件
Thread-1开始读取文件
Thread-4开始读取文件
Thread-5开始读取文件
Thread-7开始读取文件
Thread-6开始读取文件
Thread-8开始读取文件
Thread-9开始读取文件
Thread-7结束读取文件,文件大小为:182M,使用时间为:941
Thread-9结束读取文件,文件大小为:182M,使用时间为:955
Thread-1结束读取文件,文件大小为:182M,使用时间为:956
Thread-5结束读取文件,文件大小为:182M,使用时间为:955
Thread-6结束读取文件,文件大小为:182M,使用时间为:958
Thread-0结束读取文件,文件大小为:182M,使用时间为:960
Thread-2结束读取文件,文件大小为:182M,使用时间为:972
Thread-3结束读取文件,文件大小为:182M,使用时间为:1022
Thread-4结束读取文件,文件大小为:182M,使用时间为:1023
Thread-8结束读取文件,文件大小为:182M,使用时间为:1024
平均每个线程使用时间:976
程序总结束,总运行时间:1059
从输出结果可以看到,10个线程是同时开始的,虽然说电脑只有4个逻辑处理器,同一时间只能处理4个线程,但是它会平均为我们的10个线程分配执行时间,这条线程执行一下,然后切换到另一条线程执行一下,再切换到另一条线程执行一下。。。,所以看起来就像10条线程同时执行一样,从平均每个线程的使用时间也可看出差别来,使用协程读取文件时,每个协程平均的使用时间为400毫秒,而线程的平均为976毫秒,这是因为在使用协程时,4核处理器,每个处理器只处理一个协程,所以单个协程使用的时间就少。而在使用线程时,每个处理器需要轮流处理2.5个线程(10 / 4 = 2.5),所以单个线程使用的时间就比较多。976 / 400 = 2.44,所以单个线程的下载时间也差不多是单个协程的2.5倍。
这里有一个疑问:我们发现使用线程的总运行时间竟然比使用协程的要少,理论上说使用协程时,每个处理器每次只需要处理一个协程,按道理是少了很多切换线程的操作的,理应使用时间更少才对,但是实现并非如此,我尝试运行了多次,每次都是使用线程时的总时间更少,很奇怪,不知道哪位大神告诉我一下原因。
[]( )总结
=================================================================
* 使用协程时并不能简单的替换线程
* 协程中线程池的线程数默认为逻辑处理器的数量,似乎听说也可以配置协程的线程池使用任意数量的线程
* 协程中线程切换很好用,比如你从UI线程切换到IO线程,再由IO线程切换到UI线程时,不需要写回调函数,就像写同步代表一样,很爽!So,Kotlin中的协程是用来切换线程用的??
* 协程调用的函数不一定都是suspend类型的,即使调用的函数很耗时,也不需要声明为suspend的,而是如果函数有挂起操作,或者它需要调用别的有挂起操作的函数时,才需要声明为suspend,如下面的函数的delay(1000)是一个suspend函数,我们的doWorld调用了此函数,所以doWorld也需要声明suspend:```
fun main() = runBlocking {
launch { doWorld() }
println("Hello,")
}
suspend fun doWorld() {
delay(1000L)
println("World!")
}
```
[]( )后续(2021年1月20日)
=============================================================================
今天又学到了Kotlin协程的另外的知识:[https://kotlinlang.org/docs/reference/coroutines/basics.html]( )
这篇教程中,有另一种创建协程的方式:`runBlocking { }`,它创建的是一个顶级协程,这样创建的协程是运行在`main`线程上的,而且我还了解到`GlobalScope`创建的也是顶级协程,它是运行在线程池上的。而且我们可以在一个协程上创建子协程,这样的子协程和顶级协程会使用同一个线程,示例如下:
fun main() = runBlocking {
println("runBlocking start,所在线程:${Thread.currentThread().name}")
(1..4).forEach { n ->
launch {
println("子协程-${n}所在线程:${Thread.currentThread().name}")
}
}
println("runBlocking end,所在线程:${Thread.currentThread().name}")
}
运行结果如下:
runBlocking start,所在线程:main
runBlocking end,所在线程:main
子协程-1所在线程:main
子协程-2所在线程:main
子协程-3所在线程:main
子协程-4所在线程:main
那我们再来试试`GlobalScope`的子协程,代码如下:
fun main() = runBlocking {
println("runBlocking start")
val job = GlobalScope.launch {
println("GlobalScope start,所在线程:${Thread.currentThread().name}")
launch {
(1..4).forEach { n ->
println("GlobalScope子协程-${n},所在线程:${Thread.currentThread().name}")
}
}
println("GlobalScope end,所在线程:${Thread.currentThread().name}")
}
job.join()
println("runBlocking end")
}
运行结果如下:
runBlocking start
GlobalScope start,所在线程:DefaultDispatcher-worker-1
GlobalScope end,所在线程:DefaultDispatcher-worker-1
GlobalScope子协程-1,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-2,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-3,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-4,所在线程:DefaultDispatcher-worker-2
runBlocking end
从输出结果可以看到,`GlobalScope.launch{ }`的协程和`runBlocking`的协程不太一样,`GlobalScope.launch{ }`的顶级协程和它的子协程并不使用同一个线程,但是它的子协程使用同一个线程。
那`GlobalScope.asyn { }`又如何呢,示例如下:
fun main() = runBlocking {
println("runBlocking start")
val deferred = GlobalScope.async {
println("GlobalScope start,所在线程:${Thread.currentThread().name}")
launch {
(1..4).forEach { n ->
println("GlobalScope子协程-${n},所在线程:${Thread.currentThread().name}")
}
}
println("GlobalScope end,所在线程:${Thread.currentThread().name}")
}
deferred.await()
println("runBlocking end")
}
运行结果如下:
runBlocking start
GlobalScope start,所在线程:DefaultDispatcher-worker-1
GlobalScope end,所在线程:DefaultDispatcher-worker-1
GlobalScope子协程-1,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-2,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-3,所在线程:DefaultDispatcher-worker-2
GlobalScope子协程-4,所在线程:DefaultDispatcher-worker-2
runBlocking end
跟`GlobalScope.launch { }`的执行效果一样。
接下来,我们使用子协程的方式重写前面读文件的例子,代码如下:
fun main() = runBlocking {
val start = System.currentTimeMillis()
val allCoroutineUseTime = AtomicLong()
val count = AtomicInteger()
println("runBlocking start,所在线程:${Thread.currentThread().name}")
(1..10).forEach { n ->
launch {
val useTime = readFile(n)
allCoroutineUseTime.addAndGet(useTime)
count.addAndGet(1)
if (count.get() == 10) {
println("平均每个协程使用时间:${allCoroutineUseTime.get() / 10}")
println("整个程序运行时间:${System.currentTimeMillis() - start}")
}
}
}
println("runBlocking end,所在线程:${Thread.currentThread().name}")
}
private fun readFile(coroutineFlag: Int): Long {
val start = System.currentTimeMillis()
println("协程-${coroutineFlag}在${Thread.currentThread().name}开始读取文件")
val file = File("D:\\hello.mp4")
val readBytes = file.readBytes()
val fileSize = readBytes.size / 1024 / 1024
val useTime = System.currentTimeMillis() - start
println("协程-${coroutineFlag}在${Thread.currentThread().name}结束读取文件,文件大小为:${fileSize}M,使用时间为:$useTime")
return useTime
}
执行结果如下:
runBlocking start,所在线程:main
runBlocking end,所在线程:main
协程-1在main开始读取文件
协程-1在main结束读取文件,文件大小为:182M,使用时间为:225
协程-2在main开始读取文件
协程-2在main结束读取文件,文件大小为:182M,使用时间为:215
协程-3在main开始读取文件
协程-3在main结束读取文件,文件大小为:182M,使用时间为:205
协程-4在main开始读取文件
协程-4在main结束读取文件,文件大小为:182M,使用时间为:215
协程-5在main开始读取文件
协程-5在main结束读取文件,文件大小为:182M,使用时间为:210
协程-6在main开始读取文件
协程-6在main结束读取文件,文件大小为:182M,使用时间为:210
协程-7在main开始读取文件
协程-7在main结束读取文件,文件大小为:182M,使用时间为:220
协程-8在main开始读取文件
协程-8在main结束读取文件,文件大小为:182M,使用时间为:210
协程-9在main开始读取文件
协程-9在main结束读取文件,文件大小为:182M,使用时间为:205
协程-10在main开始读取文件
协程-10在main结束读取文件,文件大小为:182M,使用时间为:205
平均每个协程使用时间:212
整个程序运行时间:2140
再一次证明协程并不是并行的,从输出结果可知,我们开了10个子协程来读取文件,但是它是一个一个执行的,协程-1读取完成了,协程-2才开始读取。
接下来,我们换成`GlobalScope.launch { }`,如下:
fun main() = runBlocking {
val start = System.currentTimeMillis()
val allCoroutineUseTime = AtomicLong()
val count = AtomicInteger()
println("runBlocking start,所在线程:${Thread.currentThread().name}")
val job = GlobalScope.launch {
println("GlobalScope start,所在线程:${Thread.currentThread().name}")
(1..10).forEach { n ->
launch {
val useTime = readFile(n)
allCoroutineUseTime.addAndGet(useTime)
count.addAndGet(1)
if (count.get() == 10) {
println("平均每个协程使用时间:${allCoroutineUseTime.get() / 10}")
println("整个程序运行时间:${System.currentTimeMillis() - start}")
}
}
}
println("GlobalScope end,所在线程:${Thread.currentThread().name}")
}
job.join()
println("runBlocking end,所在线程:${Thread.currentThread().name}")
}
private fun readFile(coroutineFlag: Int): Long {
val start = System.currentTimeMillis()
println("协程-${coroutineFlag}在${Thread.currentThread().name}开始读取文件")
val file = File("D:\\hello.mp4")
val readBytes = file.readBytes()
val fileSize = readBytes.size / 1024 / 1024
val useTime = System.currentTimeMillis() - start
println("协程-${coroutineFlag}在${Thread.currentThread().name}结束读取文件,文件大小为:${fileSize}M,使用时间为:$useTime")
return useTime
}
执行结果如下:
runBlocking start,所在线程:main
GlobalScope start,所在线程:DefaultDispatcher-worker-1
协程-1在DefaultDispatcher-worker-2开始读取文件
GlobalScope end,所在线程:DefaultDispatcher-worker-1
协程-10在DefaultDispatcher-worker-1开始读取文件
协程-2在DefaultDispatcher-worker-4开始读取文件
协程-3在DefaultDispatcher-worker-3开始读取文件
协程-2在DefaultDispatcher-worker-4结束读取文件,文件大小为:182M,使用时间为:420
协程-4在DefaultDispatcher-worker-4开始读取文件
协程-3在DefaultDispatcher-worker-3结束读取文件,文件大小为:182M,使用时间为:415
协程-5在DefaultDispatcher-worker-3开始读取文件
协程-10在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:420
协程-6在DefaultDispatcher-worker-1开始读取文件
协程-1在DefaultDispatcher-worker-2结束读取文件,文件大小为:182M,使用时间为:430
协程-7在DefaultDispatcher-worker-2开始读取文件
协程-7在DefaultDispatcher-worker-2结束读取文件,文件大小为:182M,使用时间为:379
协程-8在DefaultDispatcher-worker-2开始读取文件
协程-6在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:394
协程-9在DefaultDispatcher-worker-1开始读取文件
协程-5在DefaultDispatcher-worker-3结束读取文件,文件大小为:182M,使用时间为:394
协程-4在DefaultDispatcher-worker-4结束读取文件,文件大小为:182M,使用时间为:394
协程-8在DefaultDispatcher-worker-2结束读取文件,文件大小为:182M,使用时间为:291
协程-9在DefaultDispatcher-worker-1结束读取文件,文件大小为:182M,使用时间为:297
平均每个协程使用时间:383
整个程序运行时间:1141
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

总结
学习技术是一条慢长而艰苦的道路,不能靠一时激情,也不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!
最后如何才能让我们在面试中对答如流呢?
答案当然是平时在工作或者学习中多提升自身实力的啦,那如何才能正确的学习,有方向的学习呢?有没有免费资料可以借鉴?为此我整理了一份Android学习资料路线:

这里是一部分我工作以来以及参与过的大大小小的面试收集总结出来的一套BAT大厂面试资料专题包,主要还是希望大家在如今大环境不好的情况下面试能够顺利一点,希望可以帮助到大家。

好了,今天的分享就到这里,如果你对在面试中遇到的问题,或者刚毕业及工作几年迷茫不知道该如何准备面试并突破现状提升自己,对于自己的未来还不够了解不知道给如何规划。来看看同行们都是如何突破现状,怎么学习的,来吸收他们的面试以及工作经验完善自己的之后的面试计划及职业规划。
最后,祝愿即将跳槽和已经开始求职的大家都能找到一份好的工作!
这些只是整理出来的部分面试题,后续会持续更新,希望通过这些高级面试题能够降低面试Android岗位的门槛,让更多的Android工程师理解Android系统,掌握Android系统。喜欢的话麻烦点击一个喜欢再关注一下~
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
,基本涵盖了95%以上Android开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)
[外链图片转存中…(img-l9bsnrIn-1712198170386)]
总结
学习技术是一条慢长而艰苦的道路,不能靠一时激情,也不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!
最后如何才能让我们在面试中对答如流呢?
答案当然是平时在工作或者学习中多提升自身实力的啦,那如何才能正确的学习,有方向的学习呢?有没有免费资料可以借鉴?为此我整理了一份Android学习资料路线:
[外链图片转存中…(img-b26Dhk4a-1712198170386)]
这里是一部分我工作以来以及参与过的大大小小的面试收集总结出来的一套BAT大厂面试资料专题包,主要还是希望大家在如今大环境不好的情况下面试能够顺利一点,希望可以帮助到大家。
[外链图片转存中…(img-Mq58TaH2-1712198170387)]
好了,今天的分享就到这里,如果你对在面试中遇到的问题,或者刚毕业及工作几年迷茫不知道该如何准备面试并突破现状提升自己,对于自己的未来还不够了解不知道给如何规划。来看看同行们都是如何突破现状,怎么学习的,来吸收他们的面试以及工作经验完善自己的之后的面试计划及职业规划。
最后,祝愿即将跳槽和已经开始求职的大家都能找到一份好的工作!
这些只是整理出来的部分面试题,后续会持续更新,希望通过这些高级面试题能够降低面试Android岗位的门槛,让更多的Android工程师理解Android系统,掌握Android系统。喜欢的话麻烦点击一个喜欢再关注一下~
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算















 8744
8744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









