







1、深度学习基础 - 神经网络模型
(1)神经网络模型****基本原理
神经网络模型的思想来源于模仿人类大脑思考的方式。神经元是神经系统最基本的结构和功能单位,分为突起和细胞体两部分。突起作用是接受冲动并传递给细胞体,细胞体整合输入的信息并传出。人类大脑在思考时,神经元会接受外部的刺激,当传入的冲动使神经元的电位超过阈值时,神经元就会从抑制转向兴奋,并将信号向下一个神经元传导。神经网络的思想是通过构造人造神经元的方式模拟这一过程。
1、单层神经网络模型
如下图所示,在一个简单的神经网络模型中有两组神经元,一组接收信号,一组输出信号。接受信号的一组通过线性变换和非线性的激活函数转换来修改信号,并传递给下一组。
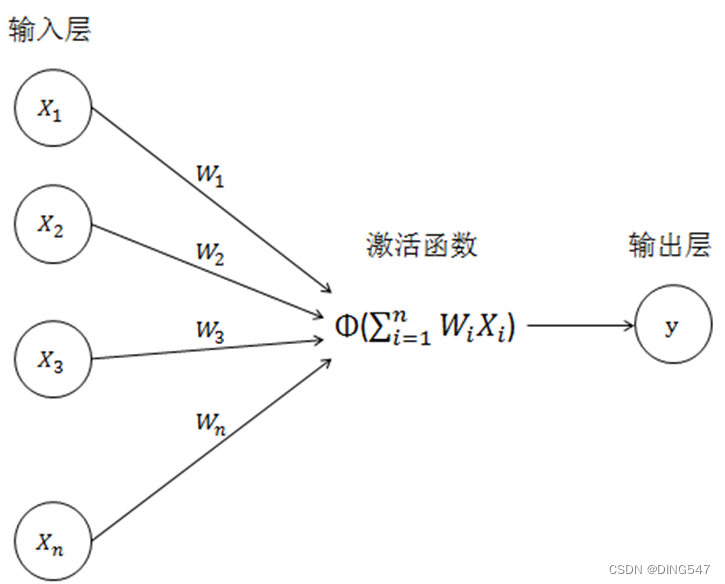
输出层信号的计算分为两步:
第一步:对输入的信号进行加权平均:
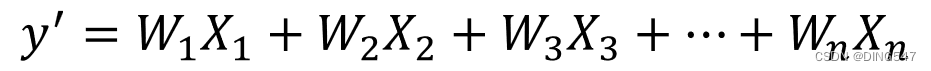
此时如果不再进行下面的操作,那么到这里,它就和第三章讲的线性回归模型是一样的了。其实神经网络模型的确和之前学到的一些基础模型有着紧密的联系。
输出层信号的计算分为两步:
第二步:对加权平均后的结果使用激活函数(Activation Function) ϕ(x)进行非线性的转化,计算出输出值:
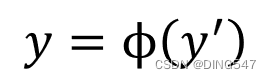
在神经网络模型中,常用来做非线性转换的激活函数有Sigmoid函数、Tanh函数、Relu函数。
Sigmoid函数:如右图所示,该函数是将取值为*(−∞,∞)*(-∞,∞)的数转换到(0,1)之间,可以用来做二分类。其导数 f′(x) 从0开始,很快就又趋近于0,所以在梯度下降时会出现梯度消失;而且sigmoid函数的均值是0.5而非0,不利于下一层的输出。
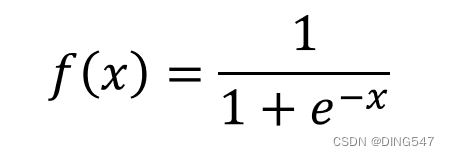
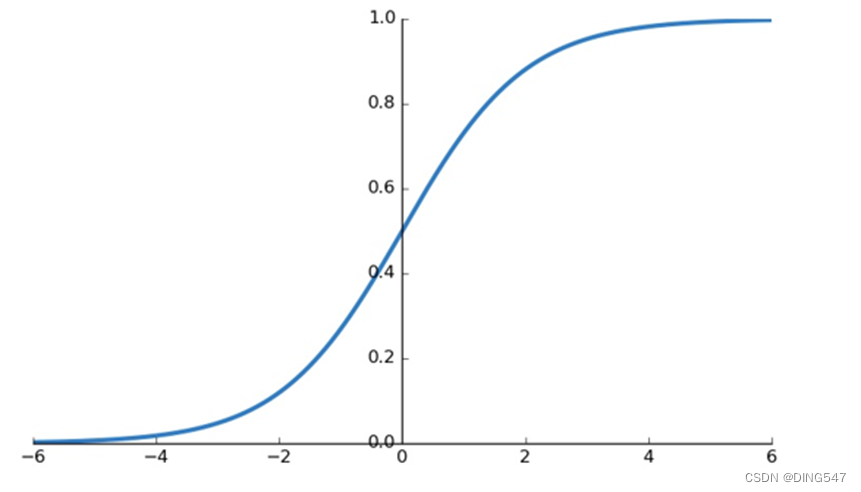
Tanh函数:如右图所示, Tanh函数将取值为*(−∞,∞)*(-∞,∞)的数转换到(-1,1)之间。当x很大或者很小的时候,导数 f′(x)也会很接近0,和sigmoid函数有同样的梯度消失的问题。但是tanh函数的均值为0,在这点上弥补了sigmoid函数均值为0.5的缺点。
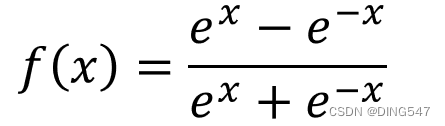
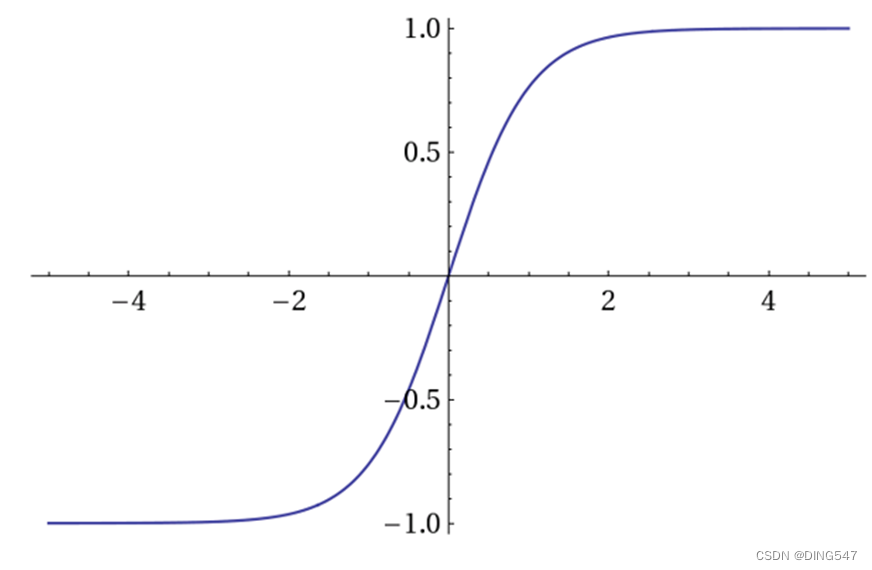
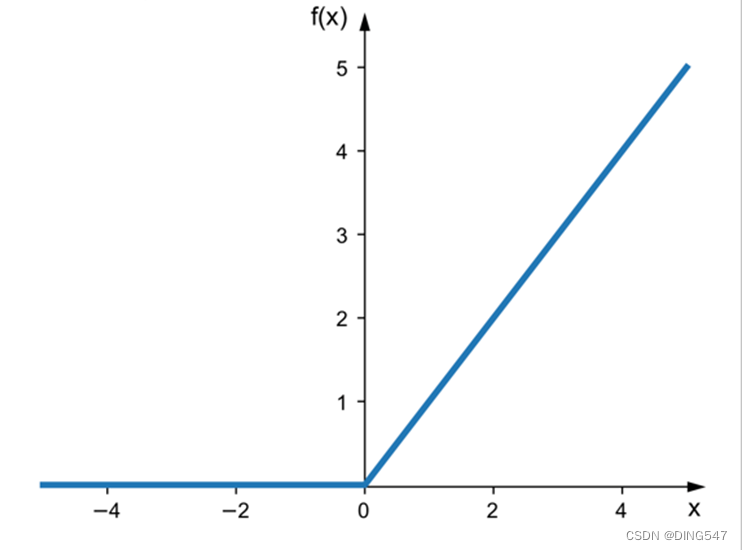
Relu函数:如右图所示, Relu函数是一种分段线性函数,它在输入为正数时弥补了Sigmoid函数以及Tanh函数的梯度消失问题,但是输入为负数时仍然有梯度消失的问题。此外Relu函数的计算速度相对于Sigmoid函数和Tanh函数也较快一些,在实战应用中,Relu函数在神经网络模型中用的相对较广一些。
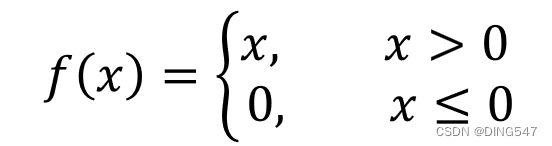
2、多层神经网络模型
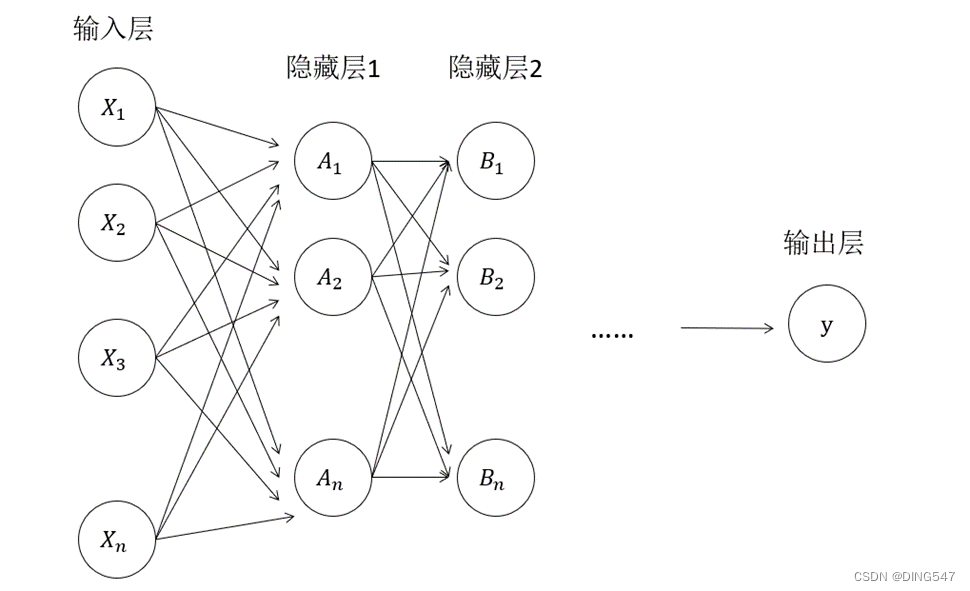
实际应用中,常常采用如下图所示的多层神经网络,在多层神经网络模型中,输入层和输出层间可以有多层隐藏层,层与层之间互相连接,信号通过线性变换和激活函数的复杂映射,不断地进行传递。
(2)神经网络模型简单代码****实现
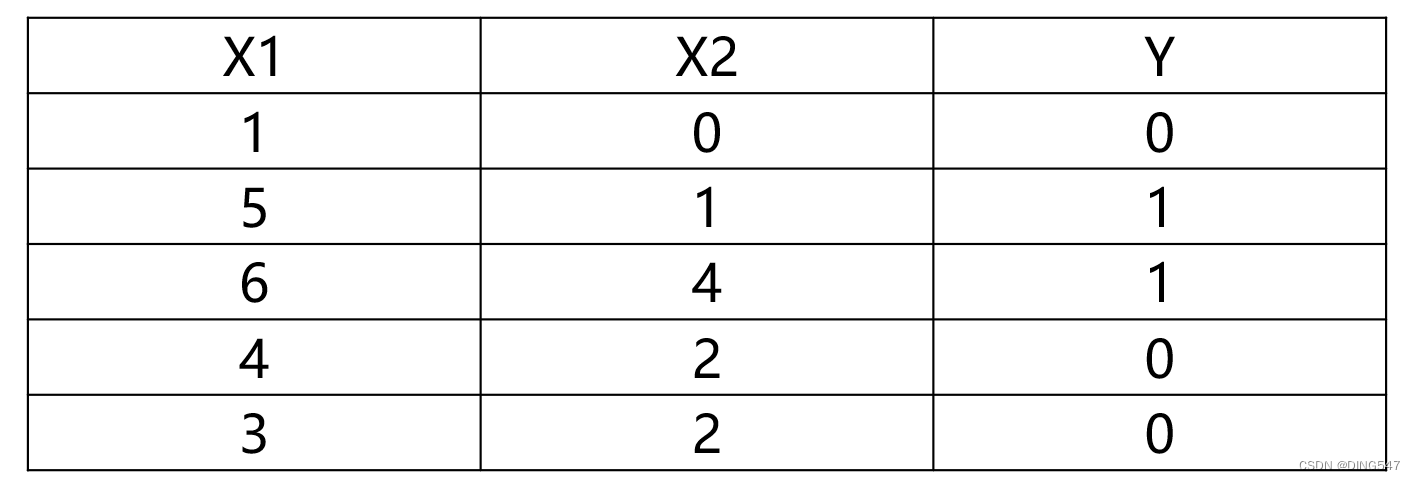
下面我们使用Scikit-Learn库中的MLP多层神经网络模型解决一个简单的二分类问题。数据如下,其中二维向量X是自变量,一维向量Y是因变量,其中Y的取值范围为0或1,代表两个不同的分类:
将数据通过神经网络模型进行拟合:
X = [[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]]
y = [0, 1, 1, 0, 0]
mlp =MLPClassifier()
mlp.fit(X, y)
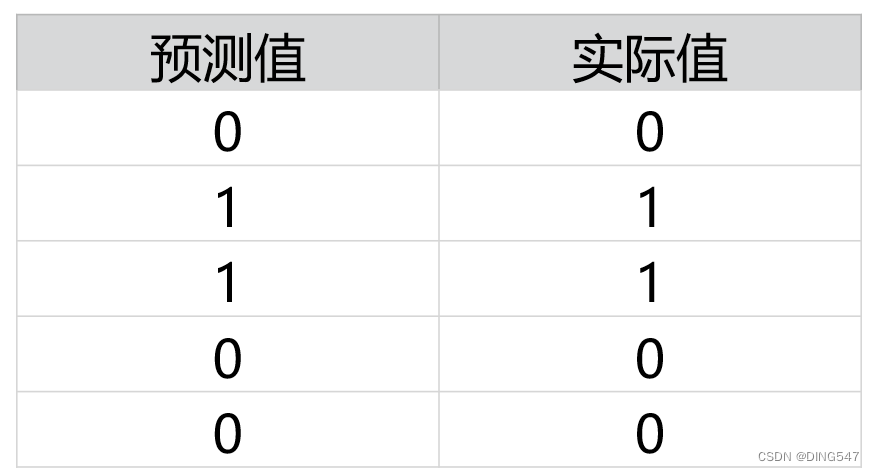
我们将这5个数据的预测值和实际值进行对比:
import pandas as pd
a = pd.DataFrame()
a['预测值'] = list(y_pred)
a['实际值'] = list(y)
此时生成的对比表格如下所示,对该简单二分类问题的预测准确度达到了100%:
除了可以搭建神经网络分类模型外,神经网络模型还可以用于回归分析,神经网络回归模型简单代码演示如下所示:
from sklearn.neural_network import MLPRegressor
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [1, 2, 3, 4, 5]
model = MLPRegressor(random_state=123)
model.fit(X, y)
print(model.predict([[5, 5]]))
2、案例**-** 用户评论情感分析
(1)背景
用户对电商产品的评价及评分中包含着用户的偏好信息,利用情感分析模型可以获取用户的情感以及对产品属性的偏好。在获取用户偏好的基础上,我们可以利用智能推荐系统向用户推荐更多他们喜欢的产品以增加用户的粘性,挖掘潜在利润。
(2)数据读取、中文分词、文本****向量化
我们可以用下面的代码读入数据并对单词进行分段:
import pandas as pd
df = pd.read_excel('产品评价.xlsx')
df.head()
import jieba
word = jieba.cut('我爱北京天安门')
for i in word:
print(i)
这里我们通过print(words[0:3])来查看前3条评论的分词结果,如下图所示:

使用CountVectorizer()函数将分词后的结果文本向量化后,我们就可以把之前所有评论分词后的分词结果进行文本向量化了,其代码如下:
from sklearn.feature_extraction.text import CountVectorizer
test = ['手机 外观 漂亮', '手机 图片 清晰']
vect = CountVectorizer()
X = vect.fit_transform(test)
X = X.toarray()
此时的X如下图所示:

我们可以用如下代码查看其文本向量化后的词袋:
words_bag = vect.vocabulary_
print(words_bag)
结果如下图所示:

通过如下代码可以转换X成DataFrame格式,其中添加pd.set_option(‘display.max_columns’, None)这行代码可以显示所有列,如果将None改成500,则表示可最多显示500列;pd.set_option(‘display.max_rows’, None)可以设置显示所有行,如果将None改成500,则表示最多可显示500行。
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.DataFrame(X).head()
(3)神经网络模型搭建与****使用
1、划分训练集和测试集
通过train_test_split()函数划分训练集和测试集,代码如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
2、搭建神经网络模型
通过如下代码即可搭建简单的神经网络模型:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
















 3134
3134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









