







Apache Hive 作为大数据领域主流的数据仓库解决方案,其查询语言 HQL (Hive Query Language) 是数据分析师和工程师日常工作的核心。除了基础的 SELECT-FROM-WHERE,HQL 还提供了强大的排序、数据合并以及组织复杂查询的机制。本文将深入探讨 HQL 中的排序操作 (SORT BY, ORDER BY, CLUSTER BY, DISTRIBUTE BY)、联合查询 (UNION, UNION ALL) 以及公用表表达式 (CTE),并通过代码示例和丰富的练习题助您全面掌握这些高级查询技巧。
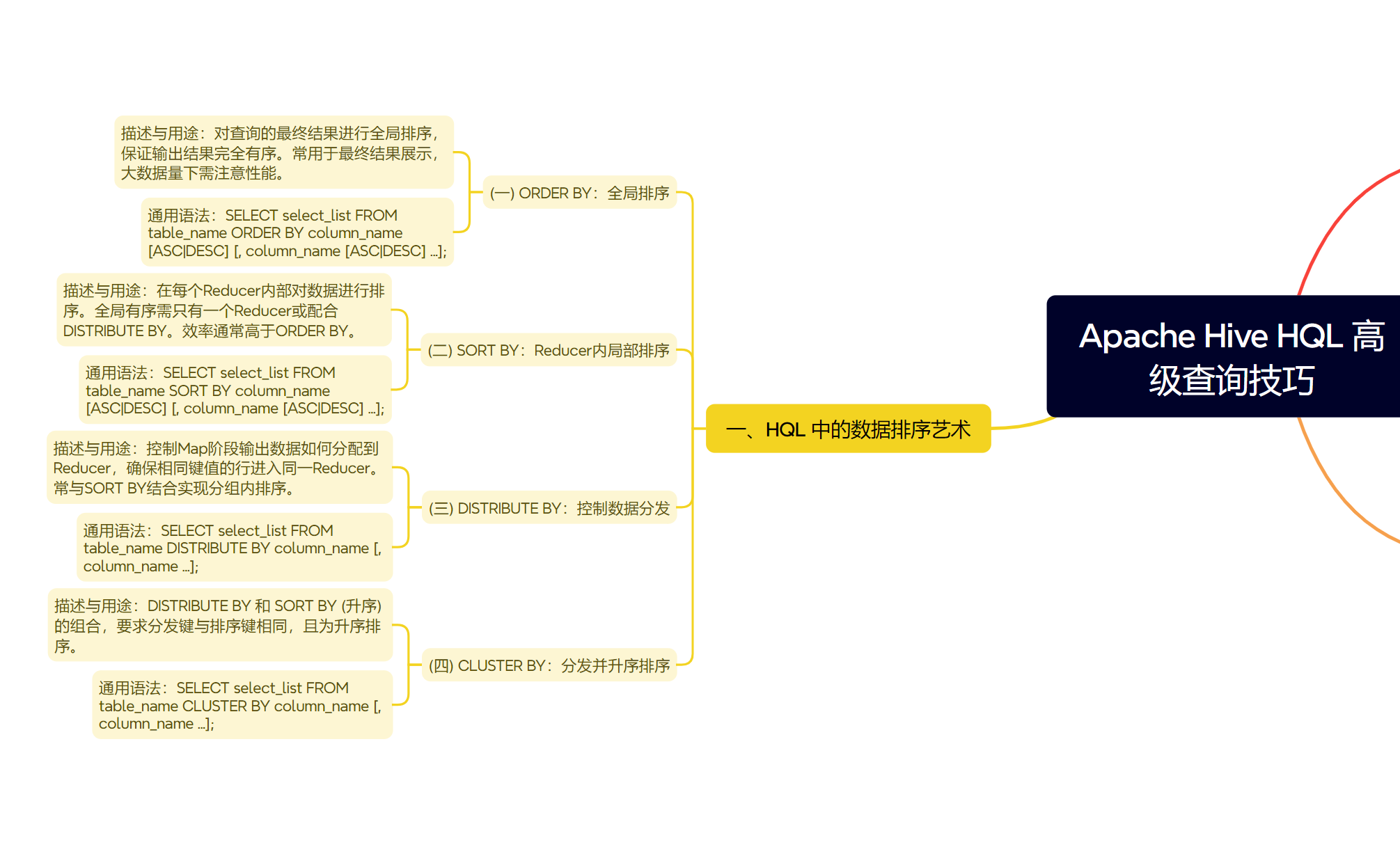
一、HQL 中的数据排序艺术
排序是数据分析中最常见的需求之一。HQL 提供了多种排序子句,它们在执行方式和适用场景上有所区别。
(一) ORDER BY:全局排序的标杆
ORDER BY 会对查询的最终结果进行全局排序。这意味着所有数据都会被发送到一个 Reducer 任务中进行统一排序。因此,对于非常大的数据集,ORDER BY 可能会非常耗时且消耗资源,甚至导致Reducer 内存溢出。
-
使用场景:当需要确保最终输出结果是完全有序时使用,通常用于结果集较小或最终展示的场景。
-
语法:
SELECT col1, col2 FROM table_name ORDER BY col1 [ASC|DESC] [, col2 [ASC|DESC] ...]; -
示例:查询员工信息,并按薪水降序排列。
假设我们有表employees(id INT, name STRING, salary DECIMAL)。
SELECT id, name, salary
FROM employees
ORDER BY salary DESC;
(二) SORT BY:Reducer 内的局部排序
SORT BY 则执行局部排序。数据在进入 Reducer 之前,会先在各自的 Reducer 内部进行排序。如果只有一个 Reducer,SORT BY 的效果等同于 ORDER BY。如果有多个 Reducer,则每个 Reducer 输出的数据是有序的,但全局来看,数据可能不是完全有序的。
-
使用场景:通常与
DISTRIBUTE BY结合使用,或者当后续处理步骤(如聚合)需要局部有序数据时。比ORDER BY效率更高。 -
语法:
SELECT col1, col2 FROM table_name SORT BY col1 [ASC|DESC] [, col2 [ASC|DESC] ...]; -
示例:按部门ID分区,然后按薪水在每个部门内排序(假设已有机制或后续操作使数据按部门进入不同 Reducer)。
SELECT id, name, department_id, salary
FROM employees
SORT BY salary DESC;
-- 注意:如果 Reduce 个数 > 1,全局可能无序。
(三) DISTRIBUTE BY:控制数据流向
DISTRIBUTE BY 用于控制 Map 阶段的输出如何分配到不同的 Reducer 任务。它确保具有相同 DISTRIBUTE BY 列值的行会被发送到同一个 Reducer 进行处理。
-
使用场景:常与
SORT BY结合,实现分组后组内排序。例如,先按用户ID分发,再在每个用户内部按时间排序。 -
语法:
SELECT col1, col2 FROM table_name DISTRIBUTE BY col1 [, col2 ...]; -
示例:将员工数据按部门ID分发到不同的 Reducer,然后每个 Reducer 内按薪水降序排序。
SELECT id, name, department_id, salary
FROM employees
DISTRIBUTE BY department_id
SORT BY salary DESC;
上述查询会保证同一个部门的员工数据进入同一个 Reducer,并且在该 Reducer 内按薪水降序排列。
(四) CLUSTER BY:分发与排序的便捷组合
CLUSTER BY 是 DISTRIBUTE BY 和 SORT BY 功能的一个便捷组合,但前提是分发键和排序键是相同的,并且排序顺序只能是升序 (ASC)。
-
使用场景:当需要按某些列进行数据分区,并且在每个分区内也按这些相同的列进行升序排序时。
-
语法:
SELECT col1, col2 FROM table_name CLUSTER BY col1 [, col2 ...];
它等价于:
SELECT col1, col2 FROM table_name DISTRIBUTE BY col1 [, col2 ...] SORT BY col1 ASC [, col2 ASC ...]; -
示例:将员工数据按部门ID分发,并在每个部门内按部门ID升序排序(虽然按部门ID排序意义不大,但演示了语法)。
SELECT id, name, department_id, salary
FROM employees
CLUSTER BY department_id;
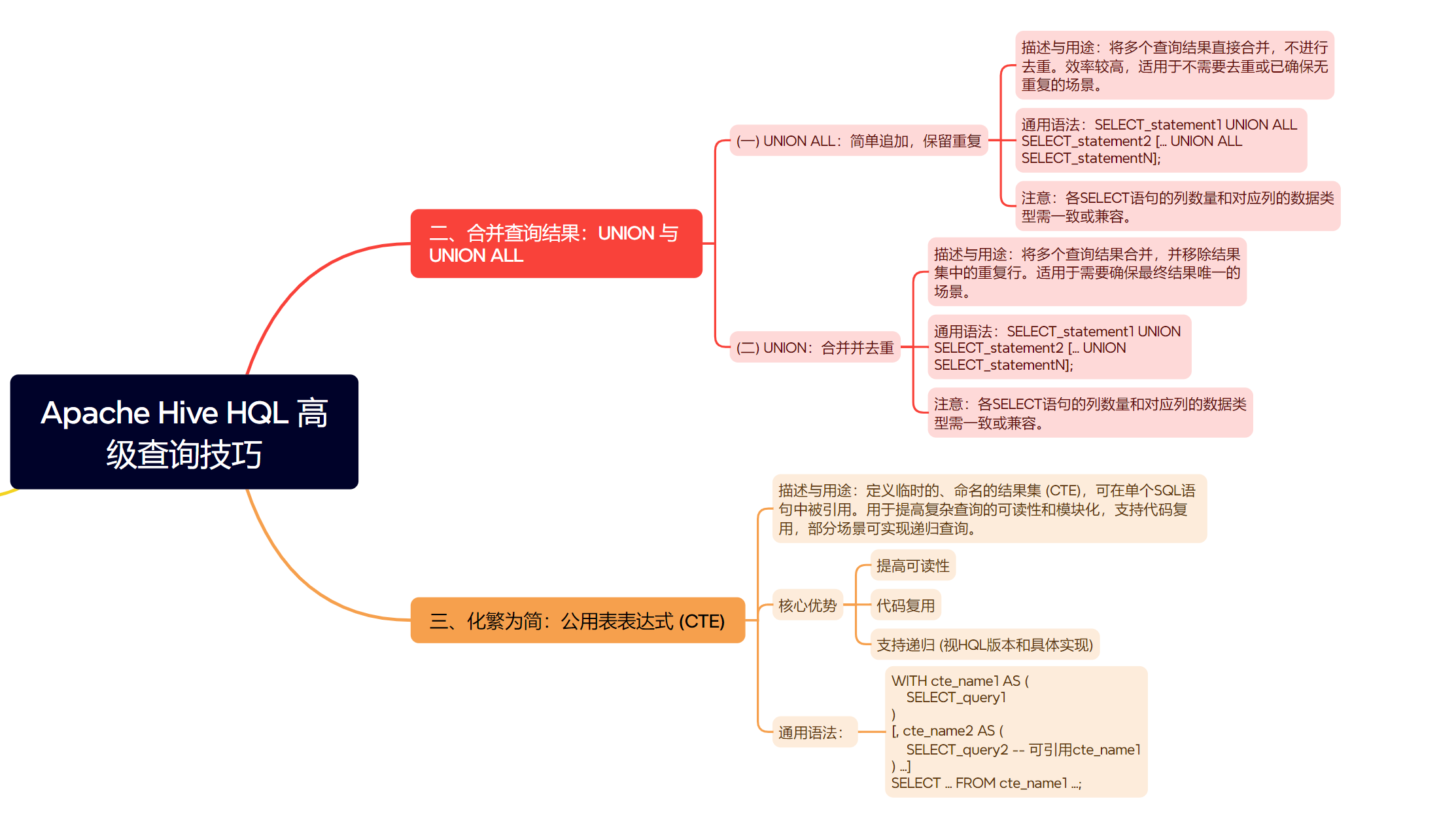
二、合并查询结果:UNION 与 UNION ALL
有时,我们需要将多个 SELECT 语句的结果集合并成一个结果集。HQL 提供了 UNION 和 UNION ALL 来实现这一目的。
(一) UNION ALL:简单追加,保留重复
UNION ALL 会简单地将所有查询的结果行追加在一起,不会进行任何去重操作。
-
使用场景:当确定合并的结果集之间没有重复,或者需要保留所有重复行时。效率比
UNION高。 -
语法:
SELECT_statement1 UNION ALL SELECT_statement2 [UNION ALL SELECT_statement3 ...];
注意:所有SELECT语句选择的列数、列的数据类型必须一致或兼容。 -
示例:合并两个部门(假设为
dept_A和dept_B表)的员工列表。
SELECT id, name, 'DepartmentA' AS department_source FROM dept_A
UNION ALL
SELECT emp_id, emp_name, 'DepartmentB' AS department_source FROM dept_B;
(二) UNION:合并并去重
UNION 操作符首先合并所有查询结果,然后移除结果集中的重复行。
-
使用场景:当需要确保最终结果集中没有重复记录时。
-
语法:
SELECT_statement1 UNION SELECT_statement2 [UNION SELECT_statement3 ...]; -
示例:合并两个产品列表(
products_store1,products_store2),并确保没有重复的产品。
SELECT product_id, product_name FROM products_store1
UNION
SELECT item_id, item_name FROM products_store2;
三、化繁为简:公用表表达式 (CTE)
公用表表达式 (Common Table Expression, CTE) 是一种强大的 SQL 特性,它允许你在单个 SQL 语句的执行范围内定义一个或多个 临时的、命名的结果集。这些命名的结果集可以在后续的查询部分(如主 SELECT 语句或其他 CTE)中被引用。
-
核心优势:
- 提高可读性:将复杂查询分解为多个逻辑清晰的小步骤。
- 代码复用:一个 CTE 可以在同一查询中被多次引用。
- 支持递归查询(虽然 HQL 对递归 CTE 的支持可能有限或有特定语法)。
-
语法:
WITH cte_name1 AS ( SELECT_statement1 ), cte_name2 AS ( SELECT_statement2 -- 可以引用 cte_name1 ) SELECT ... FROM cte_name1 JOIN cte_name2 ON ... WHERE ...; -
示例:计算每个部门的平均工资,然后找出工资高于其所在部门平均工资的员工。
假设employees表有id, name, department_id, salary列。
WITH department_avg_salary AS (
SELECT
department_id,
AVG(salary) AS avg_sal
FROM employees
GROUP BY department_id
)
SELECT
e.id,
e.name,
e.department_id,
e.salary,
das.avg_sal AS department_average_salary
FROM employees e
JOIN department_avg_salary das ON e.department_id = das.department_id
WHERE e.salary > das.avg_sal;
四、练习与巩固
为了更好地掌握以上知识点,请尝试完成以下练习。假设我们有以下几张表:
students表:student_id INT, student_name STRING, class_id INT, score DECIMAL, gender STRING, birth_date DATEclass_info表:class_id INT, class_name STRING, teacher_name STRINGemployees_asia表:emp_id INT, emp_name STRING, region STRING, salary DECIMALemployees_europe表:emp_id INT, emp_name STRING, region STRING, salary DECIMALorders表:order_id INT, customer_id INT, order_date DATE, total_amount DECIMAL
练习题1:
查询所有学生的信息,要求最终结果首先按 class_id 升序排列,然后在每个班级内部按 score 降序排列。
练习题2:
合并亚洲区员工表 employees_asia 和欧洲区员工表 employees_europe 的所有员工信息,并确保结果中没有重复的员工 (基于 emp_id)。
练习题3 (使用 CTE):
查询每个班级的最高分,并列出获得该班级最高分的学生姓名、分数以及班级名称。
练习题4:
将学生数据按性别 (gender) 分发到不同的 Reducer,然后在每个性别分组内部按 birth_date 升序排列,输出学生姓名和出生日期。
练习题5:
找出所有订单总金额 (total_amount) 高于 1000 的订单,并按订单日期 (order_date) 降序排列显示其 order_id 和 total_amount。
练习题6 (使用 UNION ALL):
假设有两个课程表 courses_fall (course_id, course_name) 和 courses_spring (course_id, course_name) 分别记录秋季和春季开设的课程。请列出所有开设过的课程(允许重复,如果一个课程在两学期都开设)。
练习题7:
使用 CLUSTER BY 按 class_id 对 students 表进行分区和排序(升序),查询 student_id 和 class_id。
练习题8 (CTE 与聚合):
找出每个客户 (customer_id) 的订单总数和总订单金额。
练习题9 (多重排序):
查询 employees_asia 表,先按 region 升序,再按 salary 降序,最后按 emp_name 升序排列。
练习题10 (CTE 嵌套或多步):
首先找出每个班级的平均分。然后,基于此结果,找出所有成绩高于其所在班级平均分的学生姓名、班级ID和他们的分数。
五、练习题答案
答案1:
SELECT student_id, student_name, class_id, score
FROM students
ORDER BY class_id ASC, score DESC;
答案2:
SELECT emp_id, emp_name, region, salary FROM employees_asia
UNION
SELECT emp_id, emp_name, region, salary FROM employees_europe;
答案3:
WITH class_max_score AS (
SELECT
class_id,
MAX(score) AS max_score
FROM students
GROUP BY class_id
)
SELECT
s.student_name,
s.score,
cms.class_id,
ci.class_name
FROM students s
JOIN class_max_score cms ON s.class_id = cms.class_id AND s.score = cms.max_score
JOIN class_info ci ON s.class_id = ci.class_id;
答案4:
SELECT student_name, birth_date
FROM students
DISTRIBUTE BY gender
SORT BY birth_date ASC;
答案5:
SELECT order_id, total_amount
FROM orders
WHERE total_amount > 1000
ORDER BY order_date DESC;
答案6:
SELECT course_id, course_name FROM courses_fall
UNION ALL
SELECT course_id, course_name FROM courses_spring;
答案7:
SELECT student_id, class_id
FROM students
CLUSTER BY class_id;
答案8:
WITH customer_order_summary AS (
SELECT
customer_id,
COUNT(order_id) AS order_count,
SUM(total_amount) AS total_spent
FROM orders
GROUP BY customer_id
)
SELECT customer_id, order_count, total_spent
FROM customer_order_summary;
或者直接查询:
SELECT
customer_id,
COUNT(order_id) AS order_count,
SUM(total_amount) AS total_spent
FROM orders
GROUP BY customer_id;
答案9:
SELECT emp_id, emp_name, region, salary
FROM employees_asia
ORDER BY region ASC, salary DESC, emp_name ASC;
答案10:
WITH class_avg_scores AS (
SELECT
class_id,
AVG(score) AS avg_class_score
FROM students
GROUP BY class_id
),
students_above_avg AS (
SELECT
s.student_name,
s.class_id,
s.score,
cas.avg_class_score
FROM students s
JOIN class_avg_scores cas ON s.class_id = cas.class_id
WHERE s.score > cas.avg_class_score
)
SELECT student_name, class_id, score
FROM students_above_avg;
结语
掌握 HQL 中的排序机制、联合查询以及公用表表达式 (CTE),能够显著提升你处理和分析大数据的能力和效率。ORDER BY 提供了全局有序的保证,而 SORT BY、DISTRIBUTE BY 和 CLUSTER BY 则为更细致的性能调优和分布式处理逻辑提供了灵活的控制。UNION 和 UNION ALL 使得数据整合变得简单直接。CTE 更是组织复杂查询、提升代码可读性的利器。通过不断练习,你会越来越熟练地运用这些高级特性来解决实际的数据问题!

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









