







前言:
想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。
一、磨刀不误砍柴工:环境准备(虚拟机与网络)
虚拟机克隆与基础配置 (以VMware为例)
第一步:准备一台基础Linux虚拟机:
你需要一台安装好Linux(推荐CentOS 7 或 Ubuntu 24.04.2/20.04)的虚拟机。确保它已安装常用工具,网络能通。
- centos 7的详细安装教程可以参考《安装篇–CentOS 7 虚拟机安装》
- Ubuntu 24.04.2的详细安装教程可以参考《安装篇–Ubuntu24.04.2详细安装教程》
第二步:克隆虚拟机:
1.启动克隆向导: 在VMware Workstation中,右键点击你准备好的虚拟机,选择 “管理” -> “克隆”。
接着会弹出“欢迎使用克隆虚拟机向导”界面,直接点击“下一步”。
2.选择克隆源: 默认选择“虚拟机中的当前状态”,直接点击“下一步”。
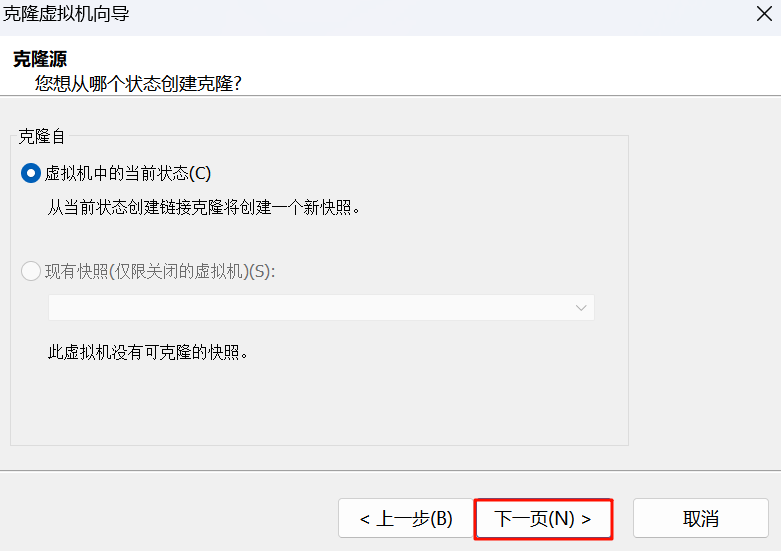
3.选择克隆类型: 选择“创建完整克隆”。完整克隆会复制整个虚拟硬盘,确保每台“小鸡”都是独立的,不会相互影响。链接克隆虽然省空间,但不适合我们做集群。点击“下一步”。
4.命名与存放位置:
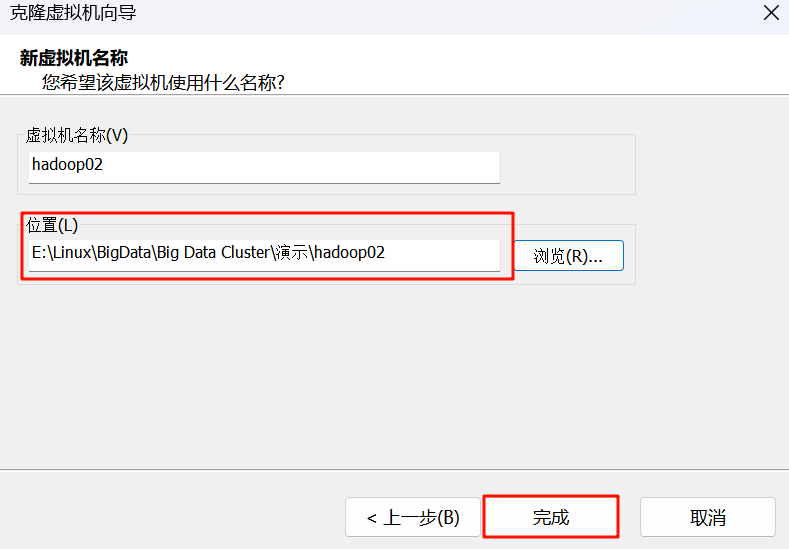
第三步:Windows宿主机VMnet8网卡IP配置
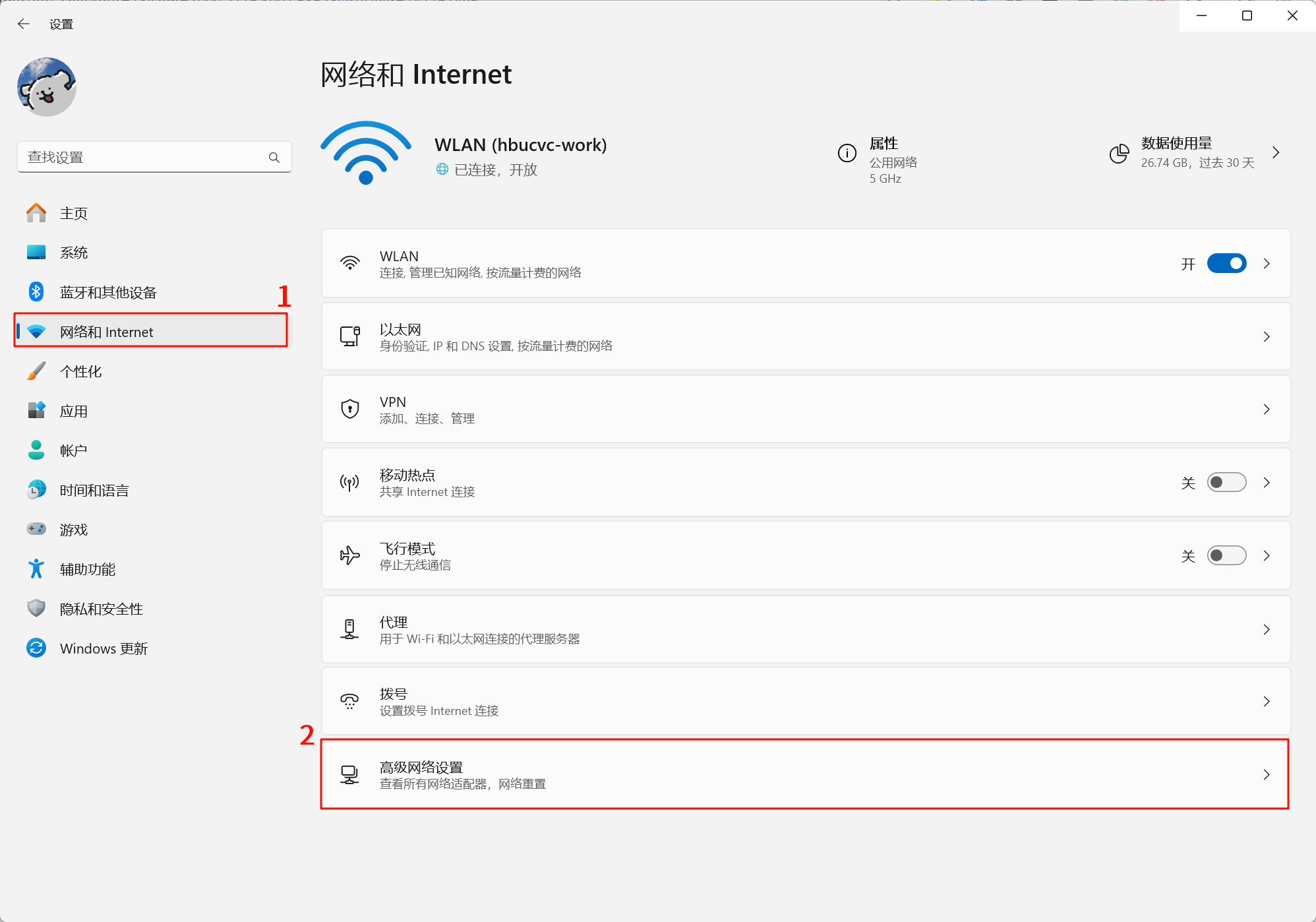
1.在Windows设置中,进入 “网络和 Internet”
2.点击 “高级网络设置”
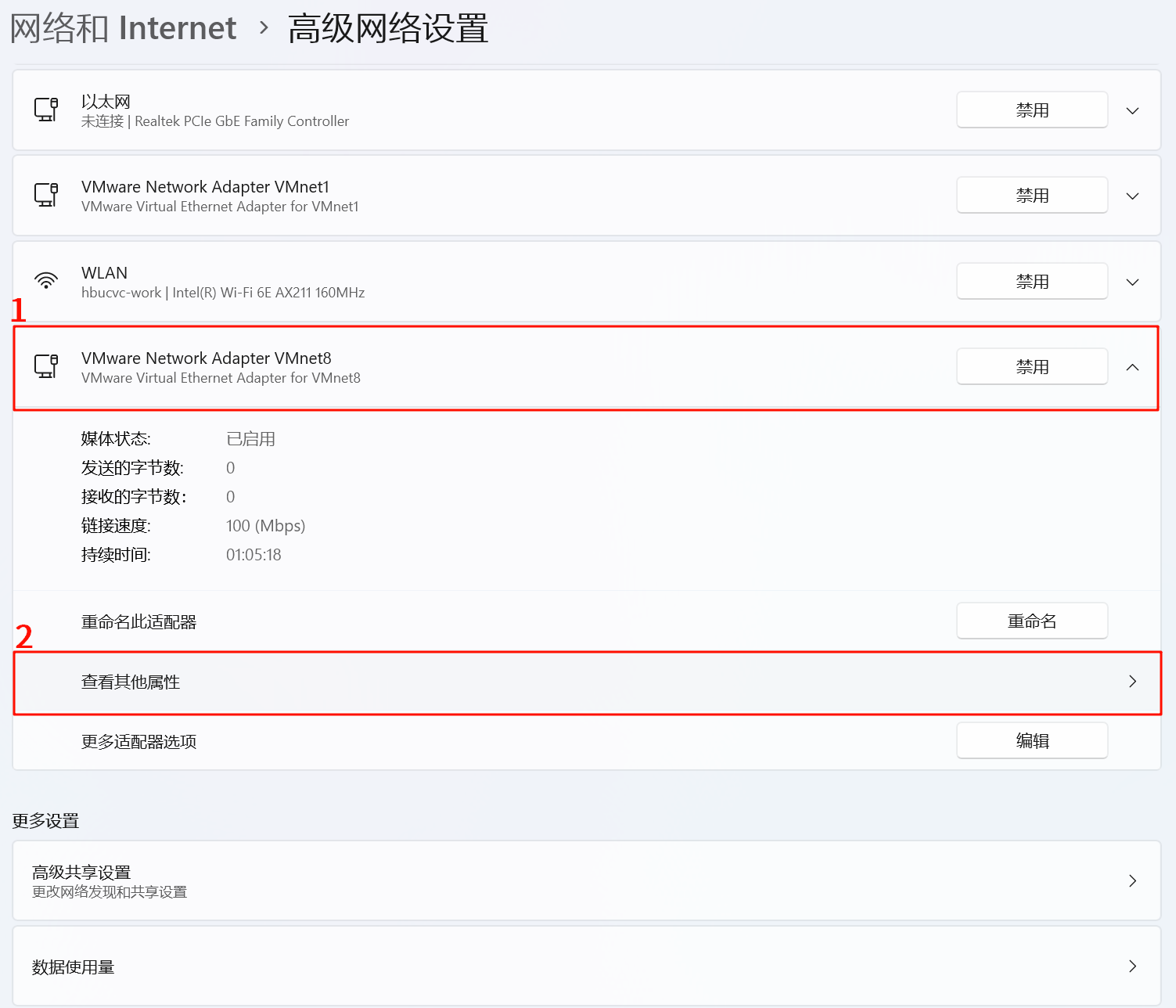
3.找到 “VMware Network Adapter VMnet8”,展开它,点击 “查看其他属性”
4.点击“IP 分配”旁边的“编辑”
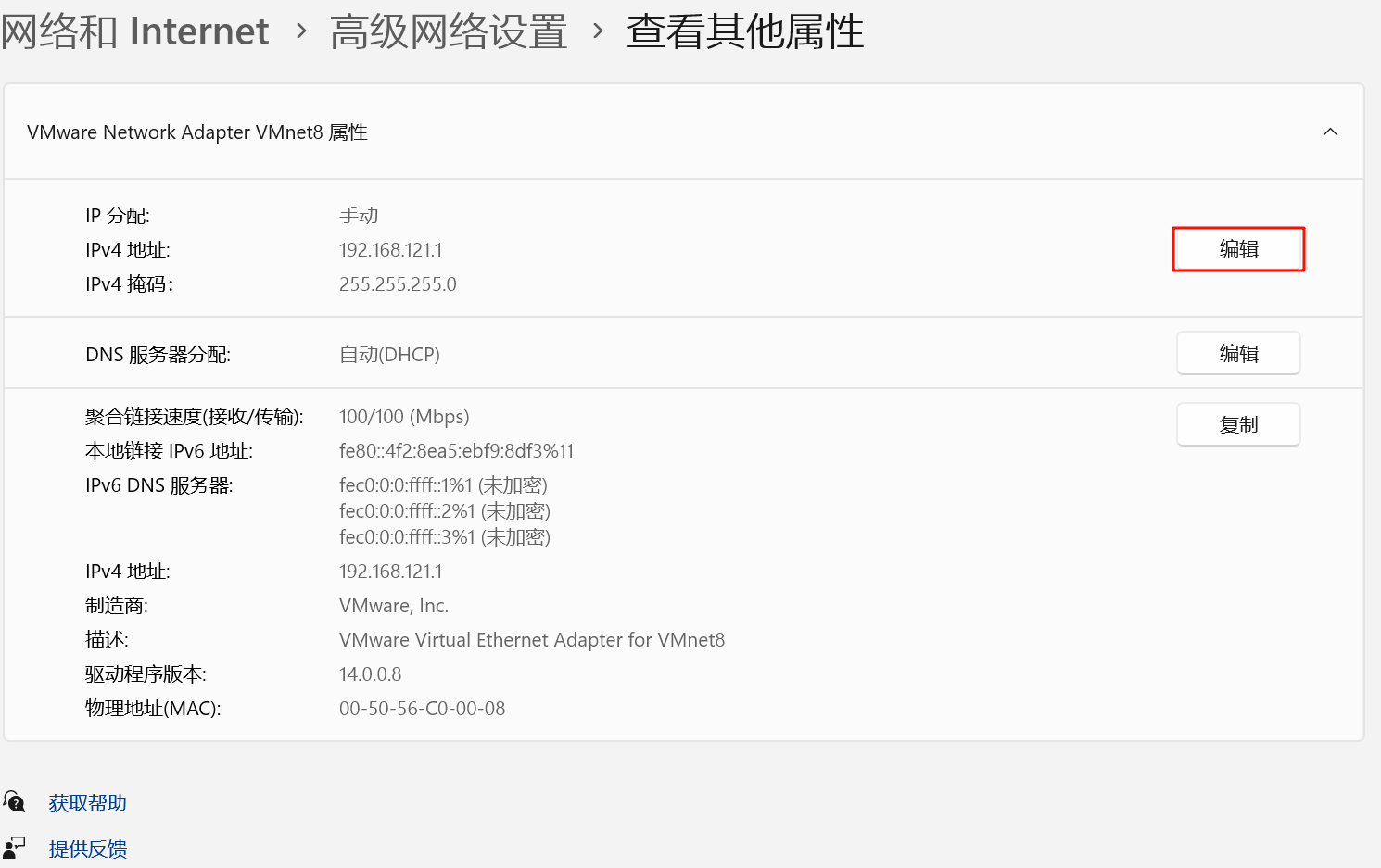
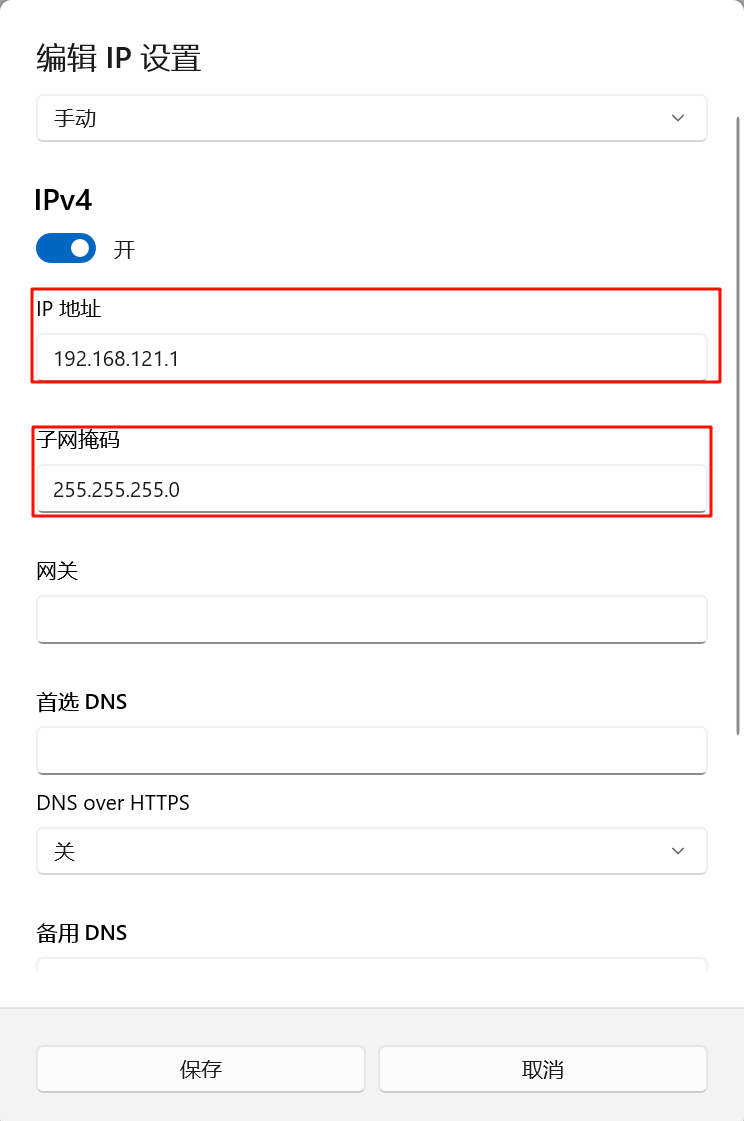
5.在“编辑 IP 设置”中,选择“手动”,打开IPv4,然后填写IP地址(如 192.168.121.1)和子网掩码(255.255.255.0)。网关和DNS对于这个宿主机的虚拟网卡通常不需要填写,或者可以填写VMnet8的网关(192.168.121.2)和你的常用DNS。
第四步:VMware虚拟网络配置 (关键步骤!)
1.在VMware Workstation主界面,点击菜单栏的 “编辑” -> “虚拟网络编辑器”
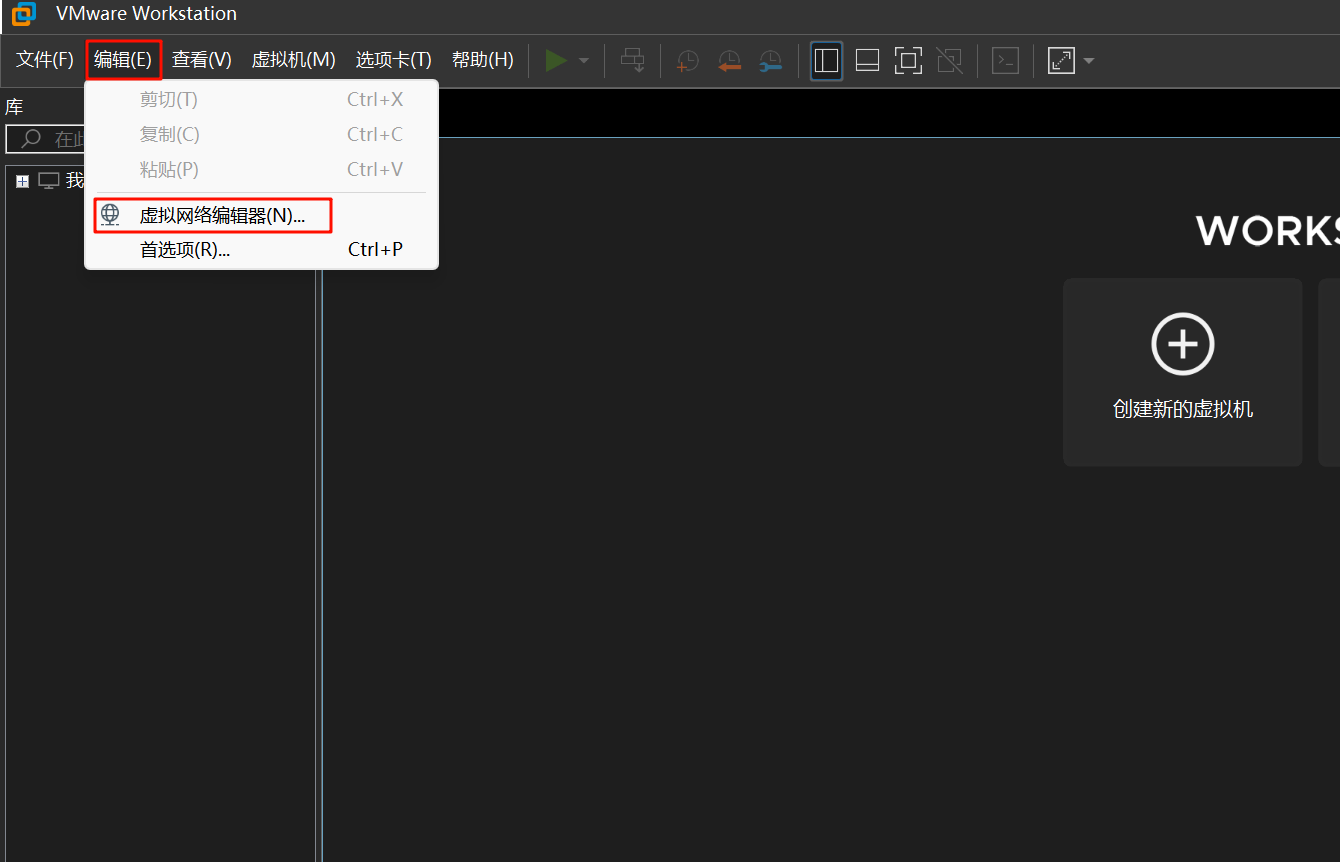
2.在“虚拟网络编辑器”中,你会看到一个网络列表,找到 VMnet8 (通常类型是NAT模式)
3.如果下方的配置选项是灰色的,你需要点击右下角的 “更改设置” 按钮,并可能需要提供管理员权限
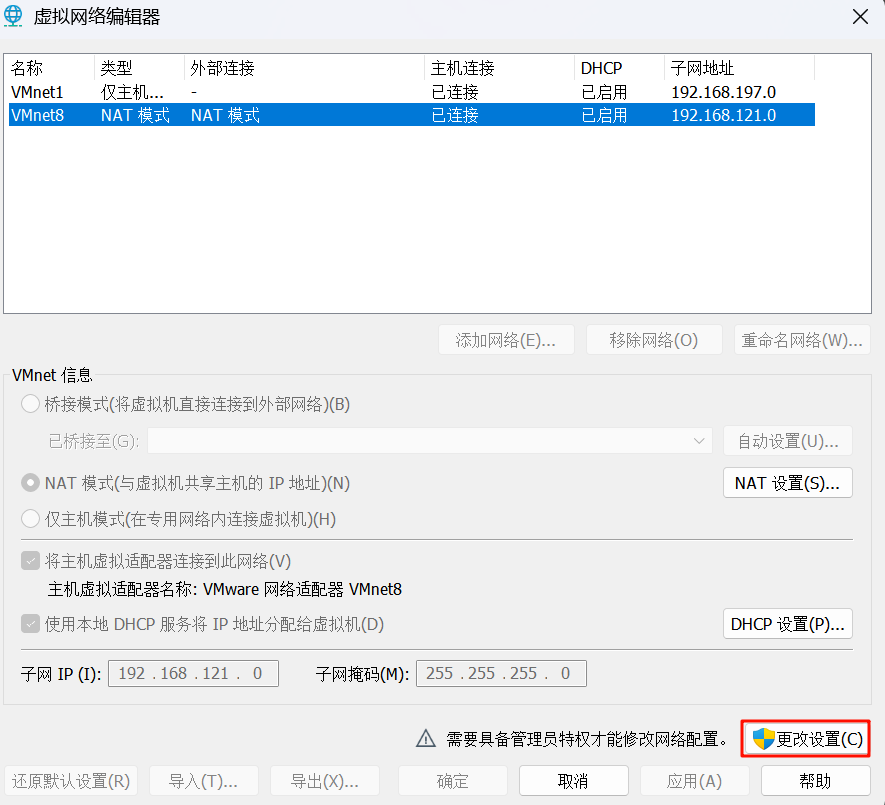
4.选中VMnet8,然后进行以下配置:
4.1.确保连接类型选择 “NAT模式(与虚拟机共享主机的IP地址)”。
4.2.取消勾选 “使用本地DHCP服务将IP地址分配给虚拟机”
子网IP: 输入 192.168.121.0
子网掩码: 输入 255.255.255.0
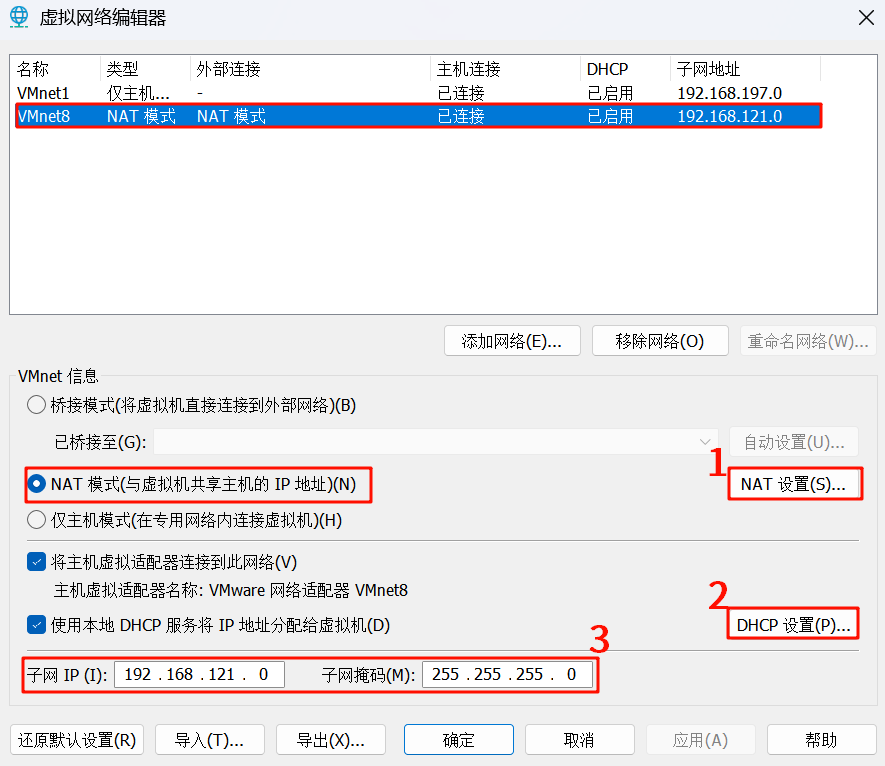
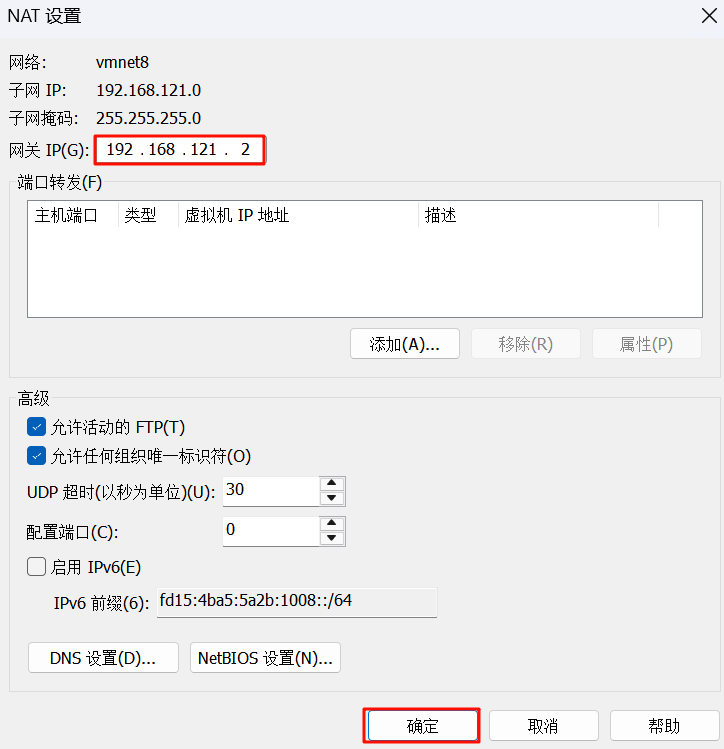
5.配置NAT设置 (网关):
将 “网关 IP(G):” 设置为 192.168.121.2
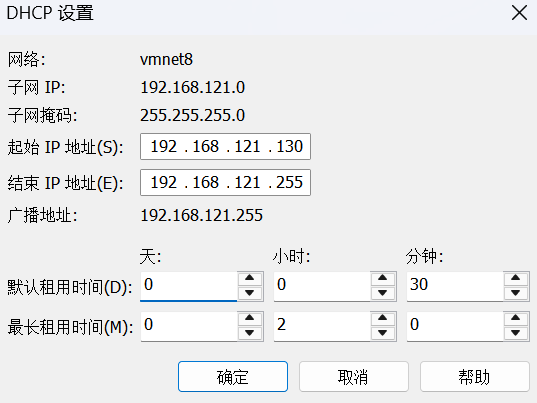
配置DHCP设置 (定义IP地址范围,可选但推荐检查):
起始 IP 地址(S): 192.168.121.130
结束 IP 地址(E): 192.168.121.255
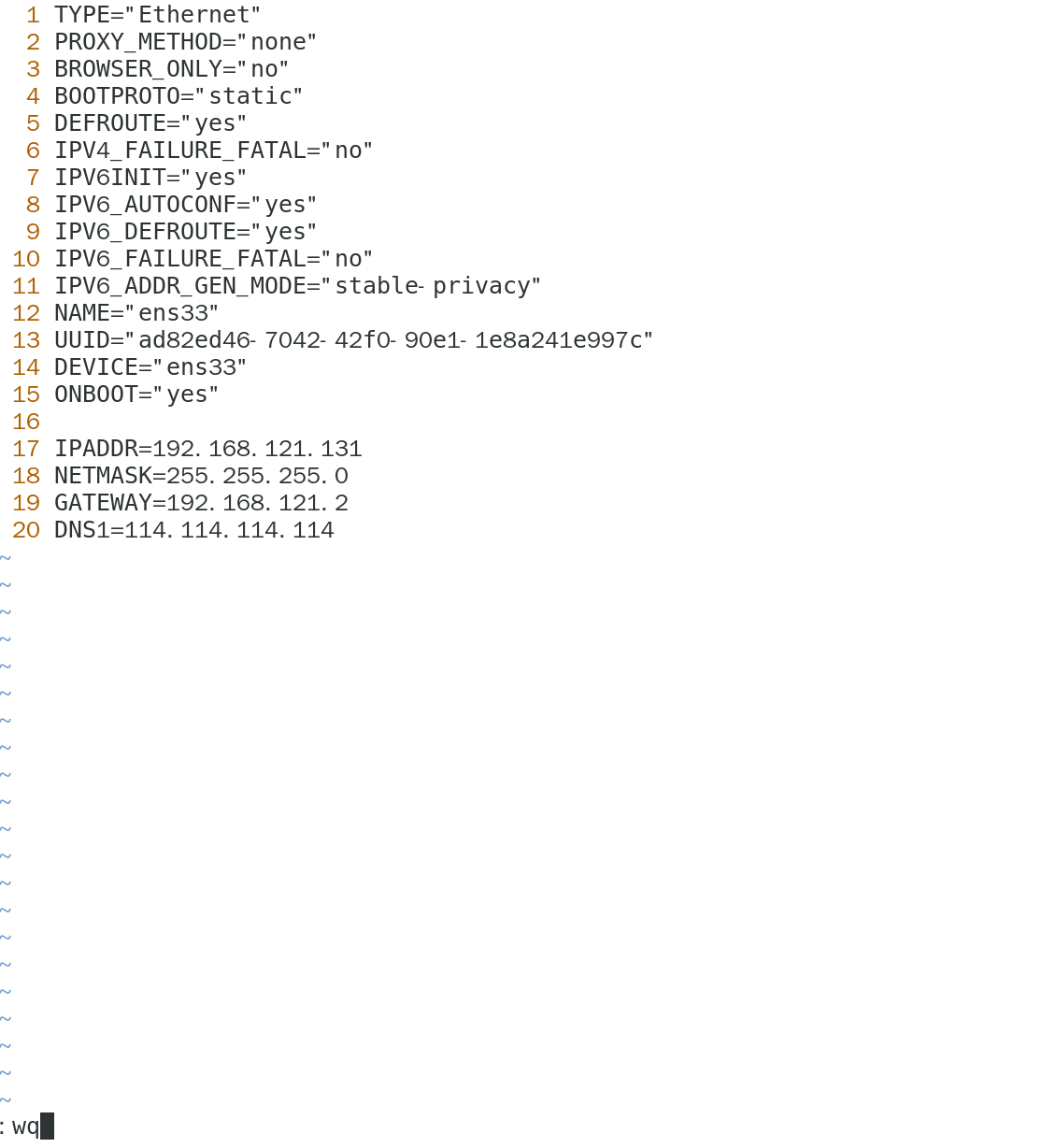
第五步:Linux虚拟机静态IP配置 (核心!以CentOS 7为例):
在每台Linux虚拟机上,编辑网络配置文件,例如 /etc/sysconfig/network-scripts/ifcfg-ens33 (你的网卡名可能不同)。
vim /etc/sysconfig/network-scripts/ifcfg-ens33
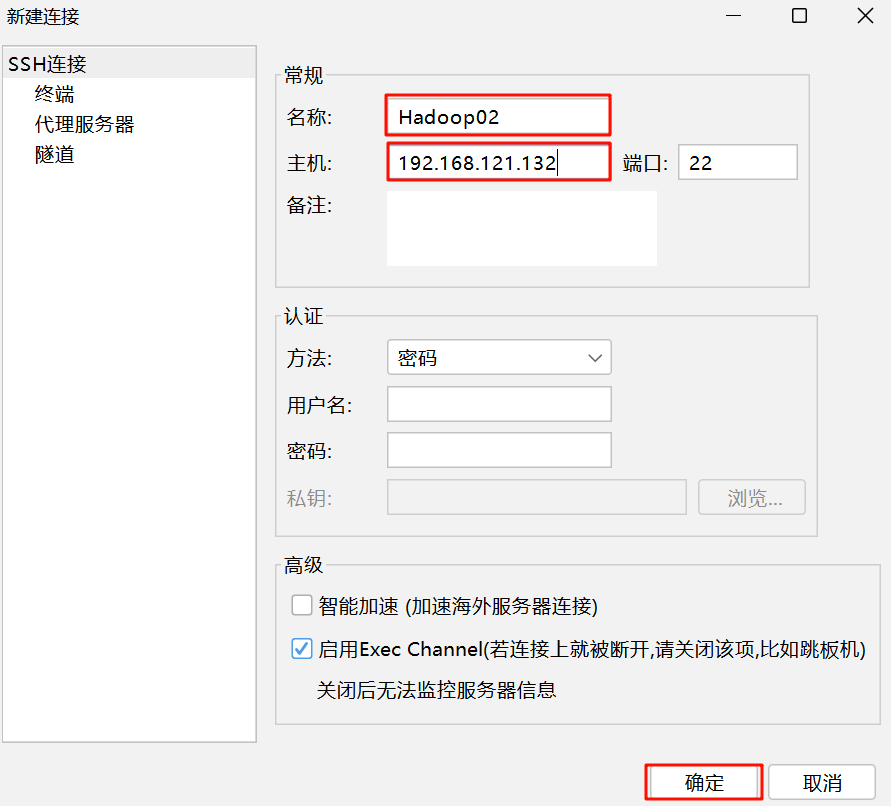
hadoop02 的配置:将 IPADDR 改为 192.168.121.132。
hadoop03 的配置:将 IPADDR 改为 192.168.121.133。
- 配置源码 (
ifcfg-ensXX):
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ensXX
DEVICE=ensXX
ONBOOT=yes
IPADDR=192.168.121.131
NETMASK=255.255.255.0
GATEWAY=192.168.121.2
DNS1=114.114.114.114
- 配置主机映射
- 在
hadoop01,hadoop02,hadoop03上都执行:
vim /etc/hosts
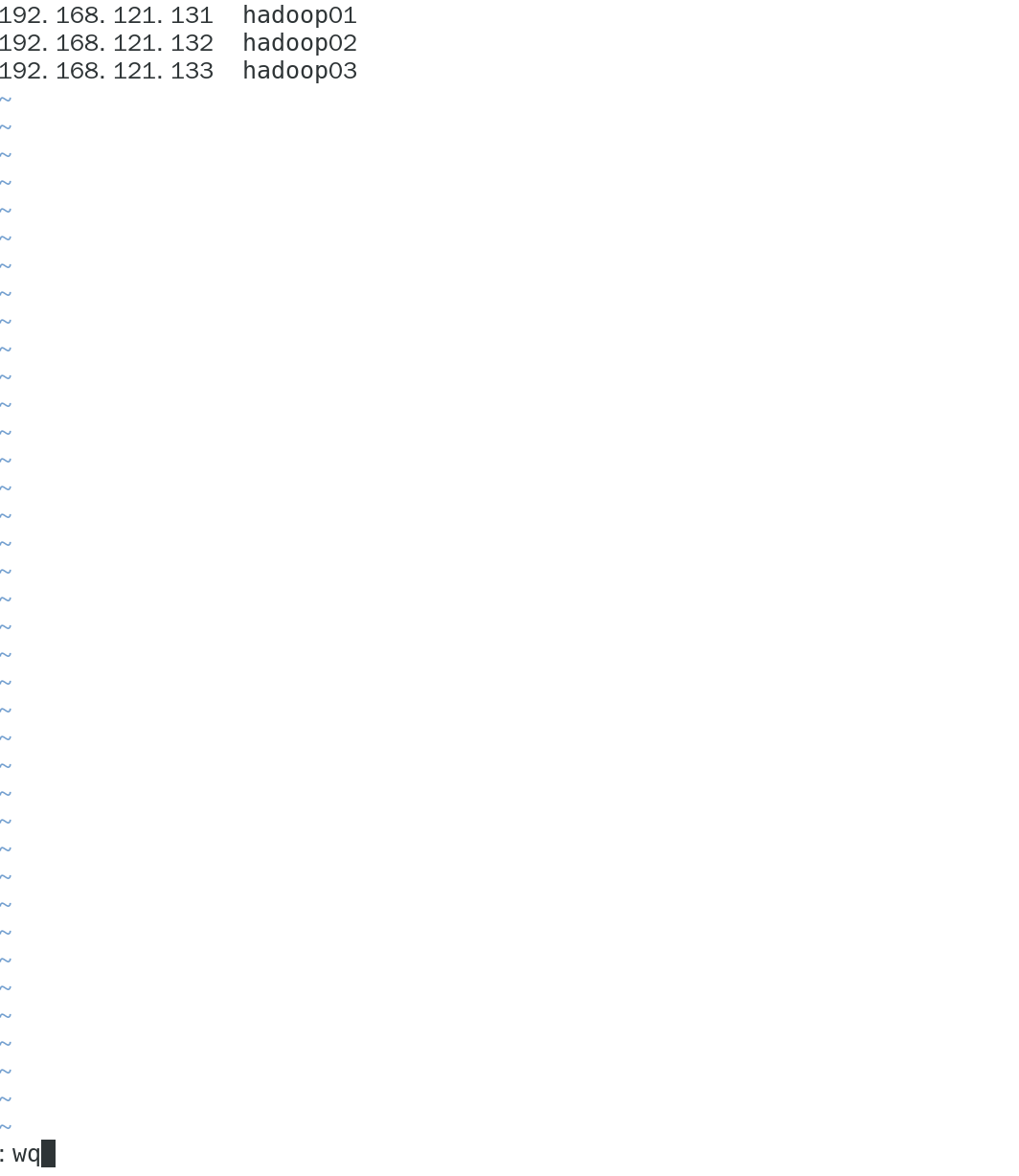
- 修改
hadoop01的主机名:
hostnamectl set-hostname hadoop01
- 重启主机
reboot
- 用
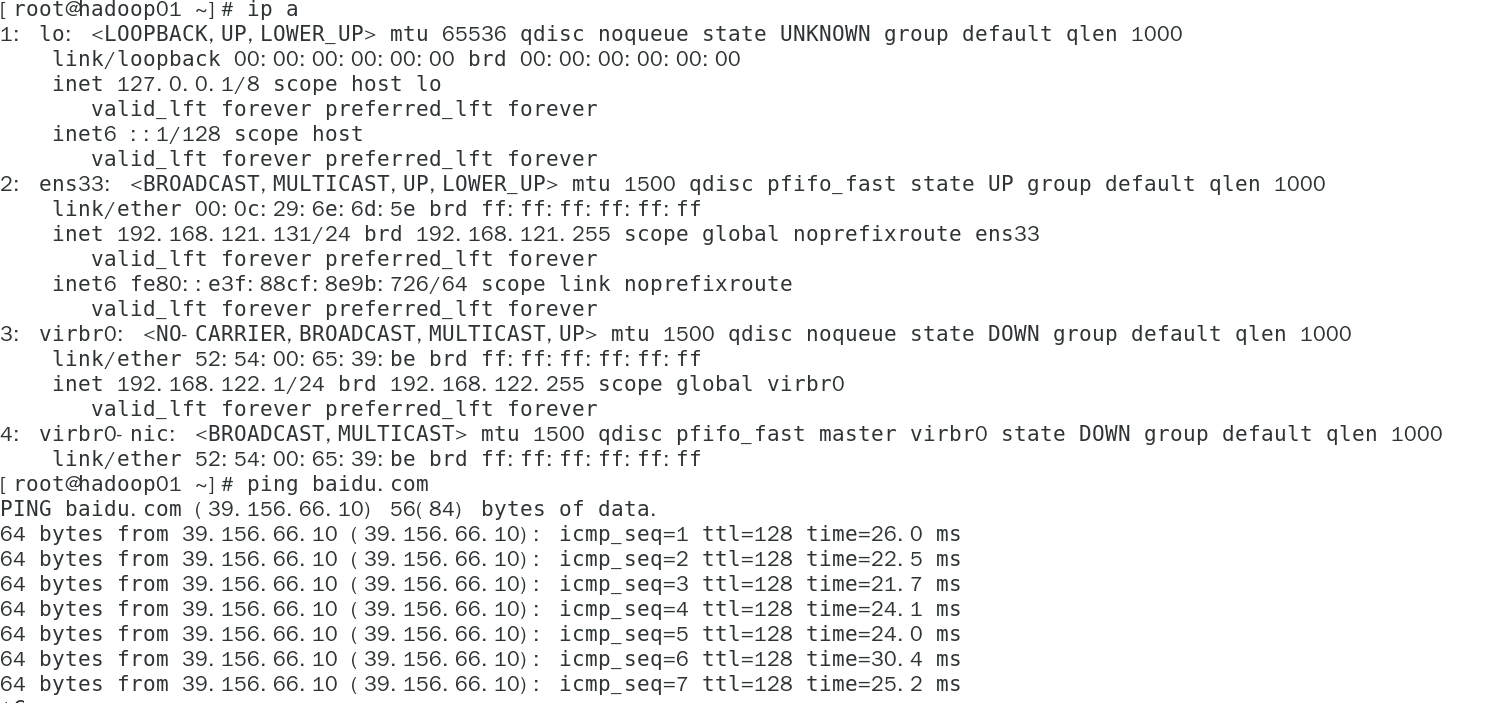
ip a验证ip是否改正 - 查看网络能否正常
ping通
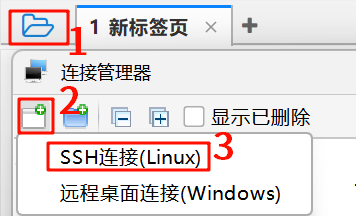
第六步:使用FinalShell连接虚拟机:
2. 关闭防火墙和selinux
- 关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
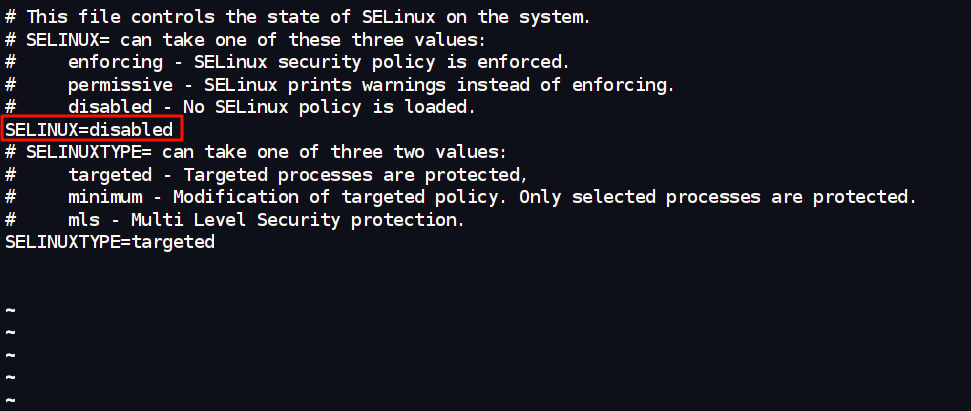
- 关闭SELinux:
vim /etc/selinux/config
# SELINUX=disabled
#需重启虚拟机
3.配置SSH免密登录 (核心):
在 hadoop01 中执行:
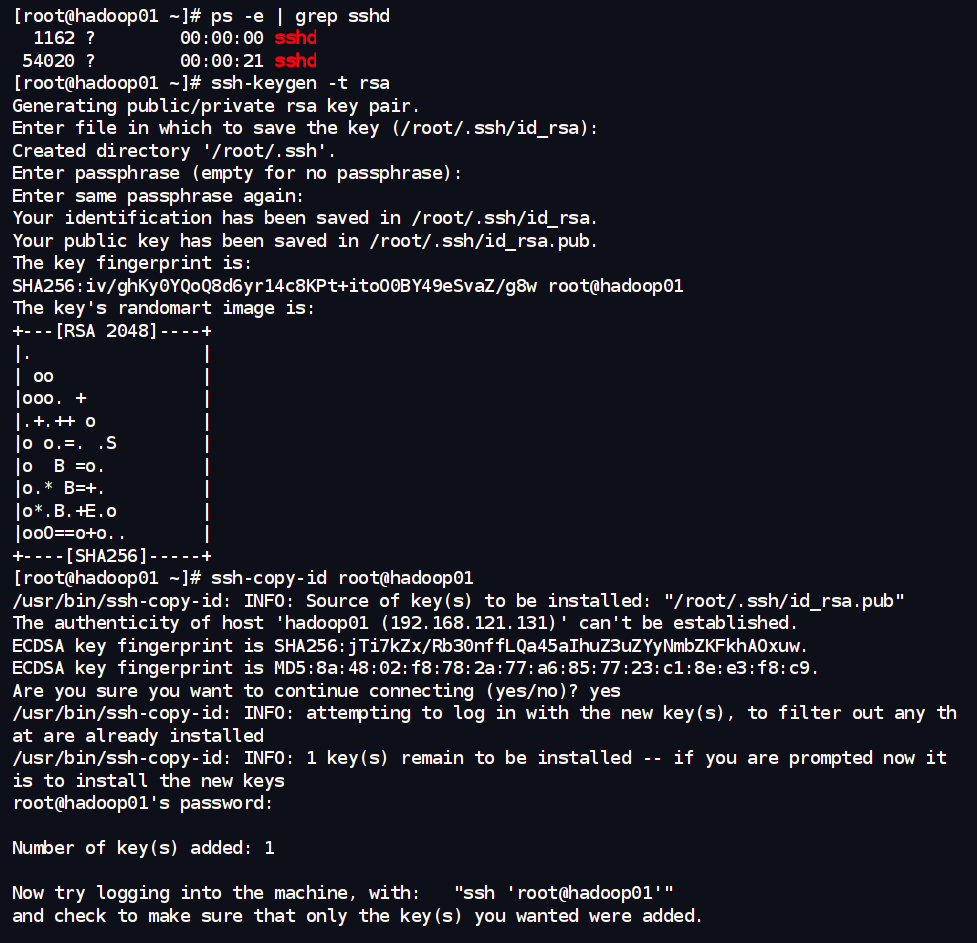
#验证ssh协议
ps -e | grep sshd
#生成钥匙
ssh-keygen -t rsa
#复制密码发送到其他设备
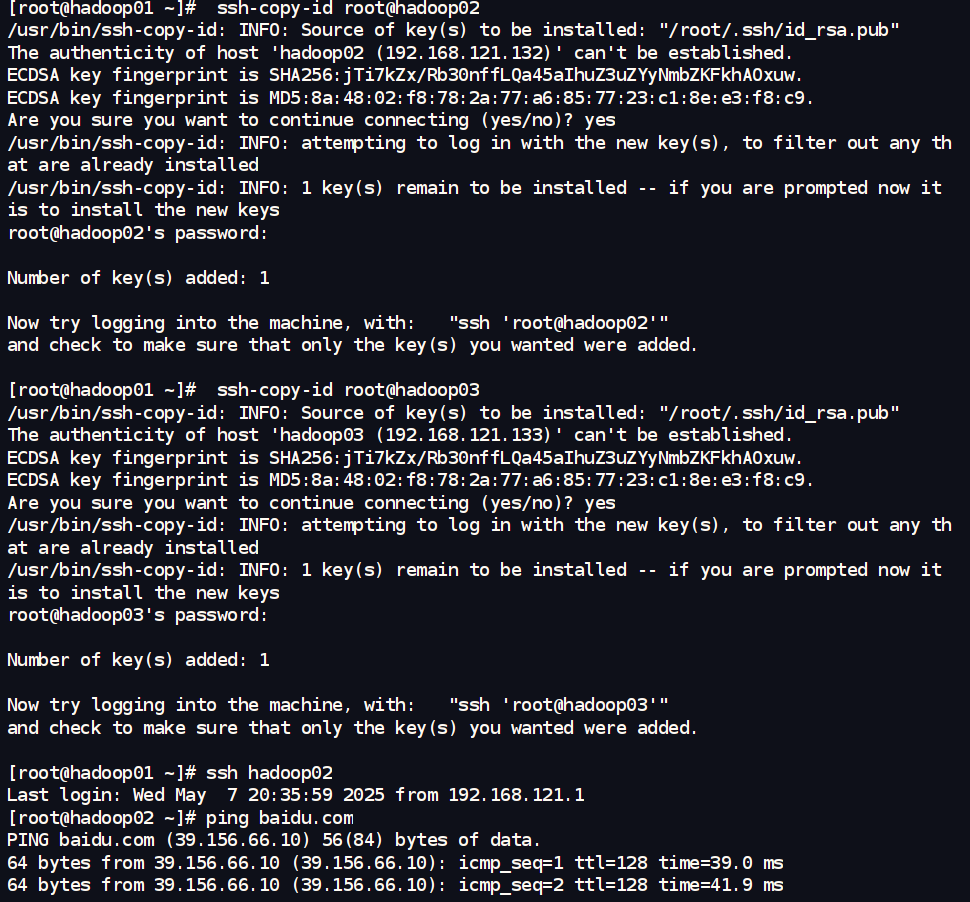
ssh-copy-id root@hadoop01
ssh-copy-id root@hadoop02
ssh-copy-id root@hadoop03
4.时间同步 (NTP):
yum install -y ntp
systemctl start ntpd
systemctl enable ntpd

5. 安装Java JDK
# 创建存放软件和安装包的目录
mkdir -p /export/server /export/softwares
5.1.上传并解压JDK安装包:
将你准备好的 jdk-8u361-linux-x64.tar.gz 文件,通过 FinalShell 的上传功能(或者其他sftp工具),上传到三台虚拟机的 /export/softwares/ 目录下。
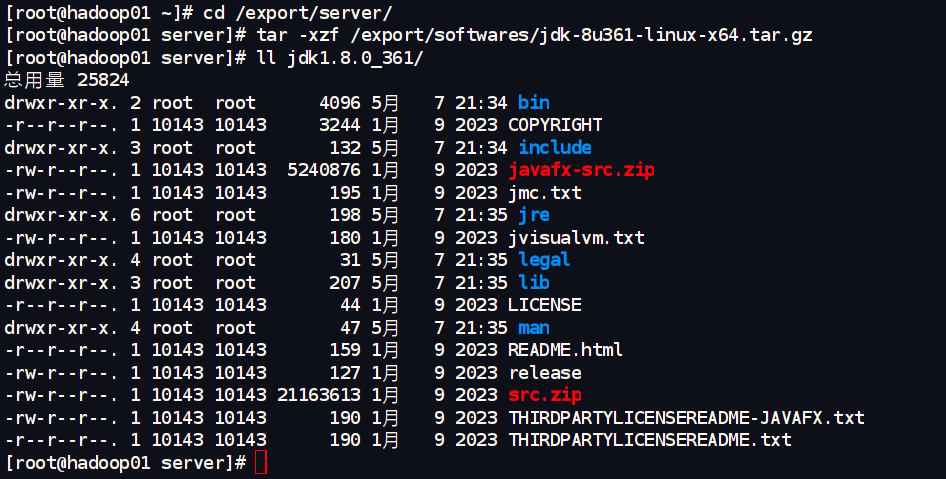
进入 /export/server/ 目录,并解压 JDK 安装包:
cd /export/server/ # 进入我们计划安装软件的目录
# 解压 JDK 安装包
tar -xzf /export/softwares/jdk-8u361-linux-x64.tar.gz
# 解压后通常会得到一个名为 jdk1.8.0_361 的目录,用ls确认一下
ls /export/server/
5.2.配置 JAVA_HOME 环境变量:
在每台机器上,编辑环境变量文件 ~/.bashrc:
vim ~/.bashrc
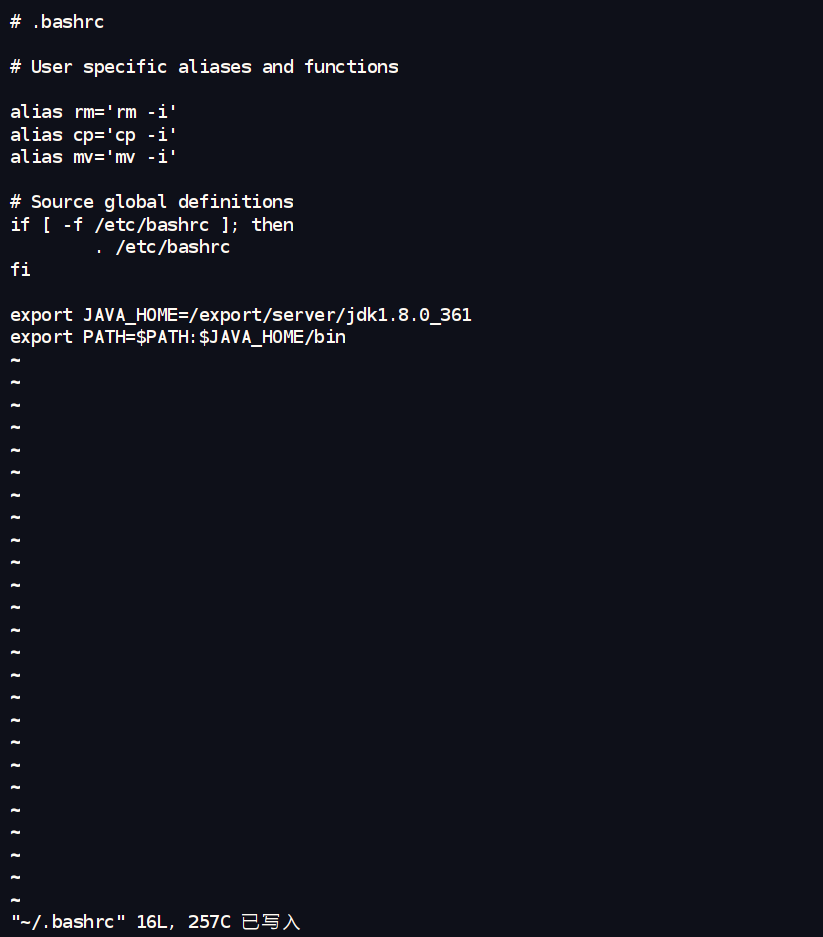
export JAVA_HOME=/export/server/jdk1.8.0_361 # 注意这里的路径和解压出来的目录名一致
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc

二、Hadoop 安装与配置
1. 解压Hadoop到指定目录 (/export/server/)
-
上传Hadoop安装包:将
hadoop-3.3.4.tar.gz安装包,通过 FinalShell 上传到三台虚拟机的/export/softwares/目录下。 -
解压Hadoop到
/export/server/并重命名:
# 解压 Hadoop 安装包
tar -xzf /export/softwares/hadoop-3.3.4.tar.gz
# 为了方便,我们把它重命名为简洁的 hadoop
mv hadoop-3.3.4 hadoop

2. 配置Hadoop环境变量
编辑~/.bashrc 文件,追加 Hadoop 相关的环境变量:
vim ~/.bashrc
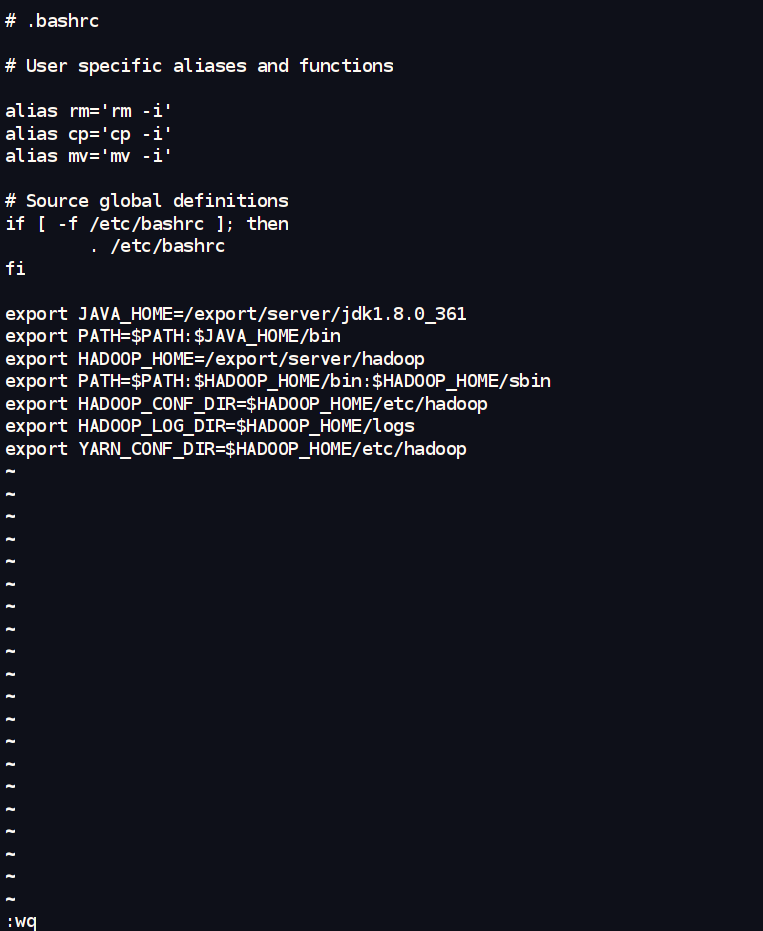
在文件末尾添加:
export HADOOP_HOME=/export/server/hadoop # 注意这里的路径是自定义安装路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 将 Hadoop 的命令加入到 PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # 指定 Hadoop 配置文件的位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs # 指定 Hadoop 日志文件的位置
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop # YARN 配置文件的位置
让环境变量生效:
source ~/.bashrc

3. 修改Hadoop核心配置文件 (重点)
主要在 hadoop01 上修改,然后分发给其他节点。
- (A)
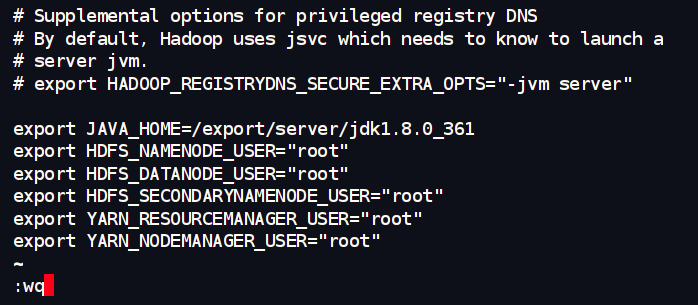
hadoop-env.sh(所有节点一致修改)- 这个文件主要配置 Hadoop 运行的环境,比如指定 Java。
cd /export/server/hadoop/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_361
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"

- (B)
core-site.xml(所有节点一致修改)- 这是 Hadoop 的核心配置文件,配置HDFS的地址、临时文件目录等。
vim /core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录,比如MapReduce的临时数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop</value> <!-- 修改为自定义路径下的临时数据目录 -->
</property>
<!-- (可选但推荐) 用于WebHDFS和HTTPFS的用户模拟配置,让指定用户(这里是hadoopuser)可以模拟其他用户 -->
<property>
<name>hadoop.proxyuser.hadoopuser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoopuser.groups</name>
<value>*</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
- ©
hdfs-site.xml(所有节点一致修改)- 这个文件配置 HDFS 的具体参数,比如副本数量、NameNode和DataNode数据存放位置等。
vim hdfs-site.xml
<configuration>
<!-- NameNode的Web UI访问地址 (Hadoop 3.x默认端口9870) -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- SecondaryNameNode的Web UI访问地址 (Hadoop 3.x默认端口9868) -->
<property>
<name>dfs.secondary.http-address</name>
<value>hadoop01:9868</value> <!-- 我们也让它在hadoop01上 -->
</property>
<!-- SecondaryNameNode所在的主机和端口,NameNode会向它发送元数据 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:9868</value>
</property>
<!-- HDFS副本数量,我们有3个节点,可以设置为2或3。这里先设为2,至少保证有两个DataNode时数据有冗余 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- NameNode元数据(fsimage和editlog)存放的本地磁盘路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/server/hadoop/dfs_data/name</value> <!-- 修改为自定义路径 -->
</property>
<!-- DataNode数据块存放的本地磁盘路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/server/hadoop/dfs_data/data</value> <!-- 修改为自定义路径 -->
</property>
<!-- 开启WebHDFS功能,可以通过HTTP访问HDFS文件 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
- (D)
yarn-site.xml(所有节点一致修改)- 这是 YARN (资源管理器) 的配置文件。
vim yarn-site.xml
<configuration>
<!-- 指定YARN的ResourceManager(RM)的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager上运行的附属服务,MapReduce Shuffle是必须的 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager的Web UI访问地址 (默认端口8088) -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
<!-- (可选) 开启日志聚集功能,方便在Web UI上查看已完成任务的日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- MapReduce JobHistory Server 的日志服务地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value> <!-- 指向JobHistoryServer的Web UI -->
</property>
<!-- (可选) 日志保留时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value> <!-- 日志保留7天 (604800秒) -->
</property>
</configuration>
- (E)
mapred-site.xml(所有节点一致修改)- 这个文件配置 MapReduce 的运行时框架和 JobHistory Server。
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce作业运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce JobHistory Server 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MapReduce JobHistory Server Web UI 地址 (默认端口19888) -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!-- (Hadoop 3.x需要) 使YARN能够正确找到和分发MapReduce相关的JAR包 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- (F)
workers文件 (仅在hadoop01上修改,然后分发)- 这个文件告诉
start-dfs.sh和start-yarn.sh脚本,需要在哪些机器上启动 DataNode 和 NodeManager 进程。
- 这个文件告诉
vim workers
hadoop01
hadoop02
hadoop03
4. 分发配置文件 (在 hadoop01 上执行)
好了,配置文件修改完了。把 hadoop01 上的配置文件同步到 hadoop02 和 hadoop03 去。
- 确保你在
hadoopuser用户下,且在$HADOOP_HOME/etc/目录下(也就是/export/server/hadoop/etc/)。
cd /export/server
scp ~/.bashrc hadoop02:~/.bashrc
scp ~/.bashrc hadoop03:~/.bashrc
#传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令,来刷新配置文件
scp -r hadoop hadoop02:$PWD
scp -r jdk1.8.0_361 hadoop02:$PWD
scp -r hadoop hadoop03:$PWD
scp -r jdk1.8.0_361 hadoop03:$PWD
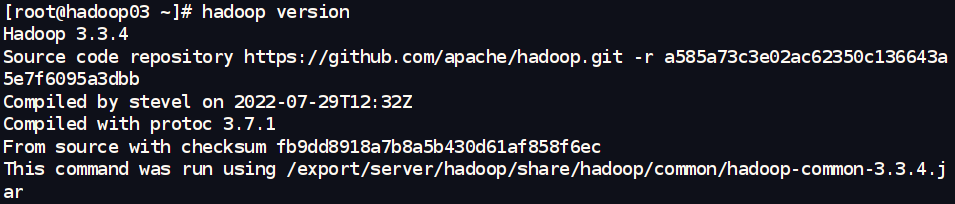
5.验证是否成功

















 3625
3625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









