







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

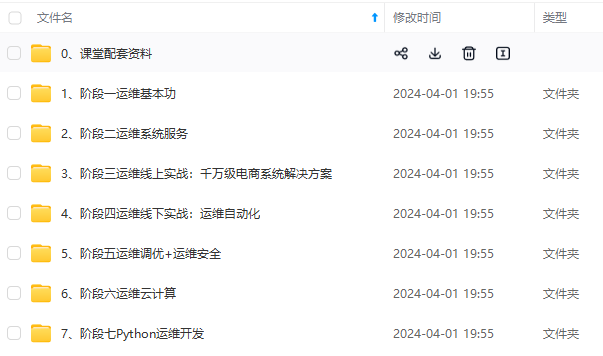
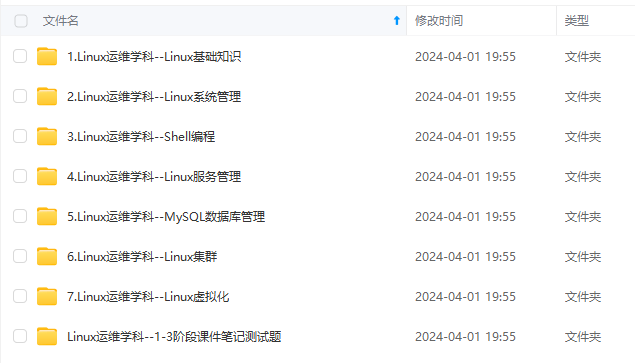
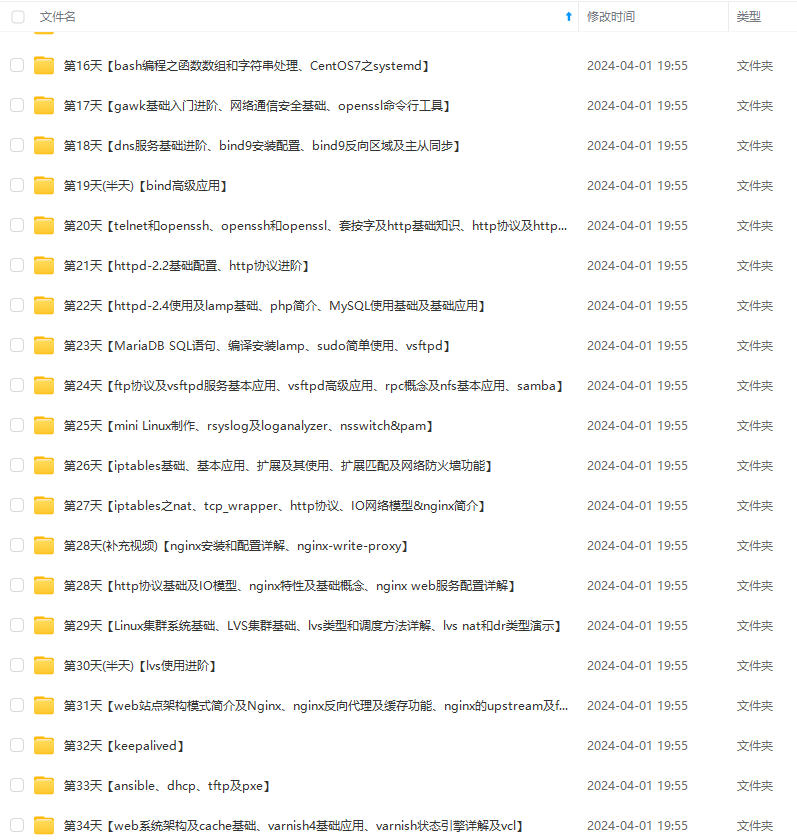
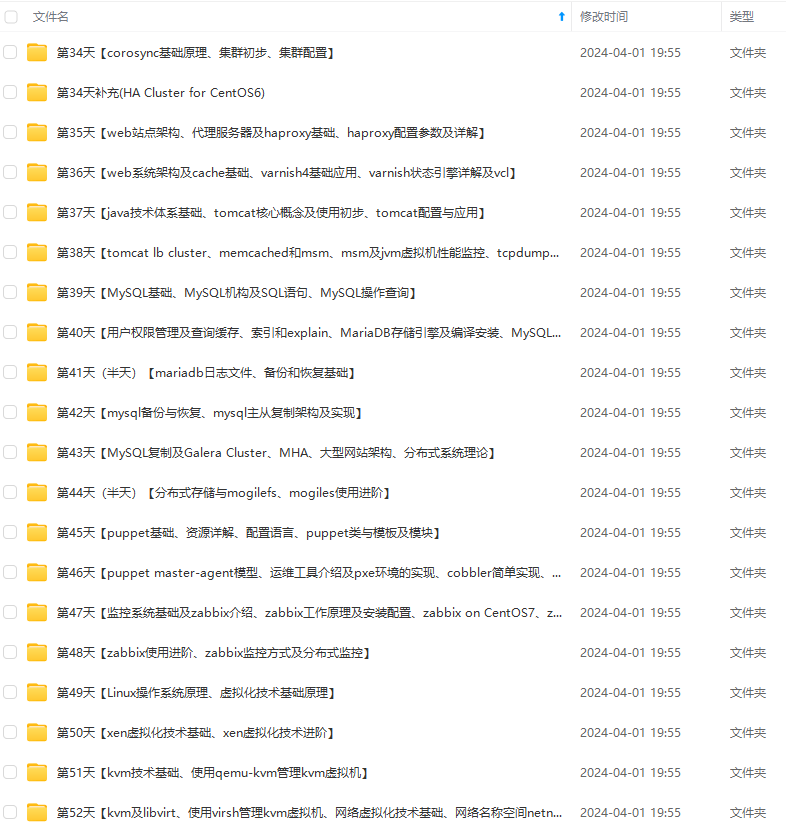
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
else
for i in seq 1 $#
do
a=$i
echo “ls ${!a}”
ls -l ${!a} |grep ‘^d’
done
fi
标注:
你可能会对${!a}有疑问,这里是一个特殊用法,在shell中,$1为第一个参数,$2为第二个参数,以此类推,那么这里的数字要是一个变量如何表示呢?比如n=3,我想取第三个参数,能否写成 $ n ? s h e l l 中是不支持的,那怎么办?就用脚本中的这种方法: a = n? shell中是不支持的,那怎么办? 就用脚本中的这种方法: a= n?shell中是不支持的,那怎么办?就用脚本中的这种方法:a=n, echo ${!a}
---
#### 【脚本43】下载文件
创建一个函数,能接受两个参数:
1. 第一个参数为URL,即可下载的文件;第二个参数为目录,即下载后保存的位置;
2. 如果用户给的目录不存在,则提示用户是否创建;如果创建就继续执行,否则,函数返回一个51的错误值给调用脚本;
3. 如果给的目录存在,则下载文件;下载命令执行结束后测试文件下载成功与否;如果成功,则>返回0给调用脚本,否则,返回52给调用脚本;
提示,在函数中返回错误值给调用脚本,使用return
参考代码:
#!/bin/bash
if [ ! -d $2 ]
then
echo “please make directory”
exit 51
fi
cd $2
wget $1
n=echo $?
if [ $n -eq 0 ];then
exit 0
else
exit 52
fi
---
#### 【脚本44】猜数字
写一个猜数字脚本,当用户输入的数字和预设数字(随机生成一个小于100的数字)一样时,直接退出,否则让用户一直输入,并且提示用户的数字比预设数字大或者小。
参考代码:
#!/bin/bash
m=echo $RANDOM
n1=
[
[
[m%100]
while :
do
read -p "Please input a number: " n
if [ $n == $n1 ]
then
break
elif [ $n -gt $n1 ]
then
echo “bigger”
continue
else
echo “smaller”
continue
fi
done
echo “You are right.”
---
#### 【脚本45】抽签脚本
1、写一个脚本执行后,输入名字,产生随机数01-99之间的数字。
2、如果相同的名字重复输入,抓到的数字还是第一次抓取的结果,
3、前面已经抓到的数字,下次不能在出现相同数字。
4、第一个输入名字后,屏幕输出信息,并将名字和数字记录到文件里,程序不能退出
继续等待别的学生输入。
参考代码:
while :
do
read -p “Please input a name:” name
if [ -f /work/test/1.log ];then
bb=cat /work/test/1.log | awk -F: '{print $1}' | grep "$name"
if [ "$bb" != "$name" ];then #名字不重复情况下
aa=`echo $RANDOM | awk -F "" '{print $2 $3}'`
while :
do
dd=`cat /work/test/1.log | awk -F: '{print $2}' | grep "$aa"`
if [ "$aa" == "$dd" ];then #数字已经存在情况下
echo "数字已存在."
aa=`echo $RANDOM | awk -F "" '{print $2 $3}'`
else
break
fi
done
echo "$name:$aa" | tee -a /work/test/1.log
else
aa=`cat /work/test/1.log | grep "$name" | awk -F: '{print $2}'` #名字重复
echo $aa
echo "重复名字."
fi
else
aa=echo $RANDOM | awk -F "" '{print $2 $3}'
echo “
n
a
m
e
:
name:
name:aa” | tee -a /work/test/1.log
fi
done
---
#### 【脚本46】打印只有一个数字的行
如题,把一个文本文档中只有一个数字的行给打印出来。
参考代码:
#!/bin/bash
f=/etc/passwd
line=wc -l $f|awk '{print $1}'
for l in seq 1 $line; do
n=sed -n "$l"p $f|grep -o '[0-9]'|wc -l;
if [
n
−
e
q
1
]
;
t
h
e
n
s
e
d
−
n
"
n -eq 1 ]; then sed -n "
n−eq1];thensed−n"l"p $f
fi
done
---
#### 【脚本47】日志归档
类似于日志切割,系统有个logrotate程序,可以完成归档。但现在我们要自己写一个shell脚本实现归档。
举例: 假如服务的输出日志是1.log,我要求每天归档一个,1.log第二天就变成1.log.1,第三天1.log.2, 第四天 1.log.3 一直到1.log.5
参考答案:
#!/bin/bash
function e_df()
{
[ -f $1 ] && rm -f $1
}
for i in seq 5 -1 2
do
i2=
[
[
[i-1]
e_df /data/1.log.
i
i
f
[
−
f
/
d
a
t
a
/
1.
l
o
g
.
i if [ -f /data/1.log.
iif[−f/data/1.log.i2 ]
then
mv /data/1.log.
i
2
/
d
a
t
a
/
1.
l
o
g
.
i2 /data/1.log.
i2/data/1.log.i
fi
done
e_df /data/1.log.1
mv /data/1.log /data/1.log.1
---
#### 【脚本48】找出活动ip
写一个shell脚本,把192.168.0.0/24网段在线的ip列出来。
思路: for循环, 0.1 — 0.254 依次去ping,能通说明在线。
参考代码:
#!/bin/bash
ips=“192.168.1.”
for i in seq 1 254
do
ping -c 2
i
p
s
ips
ipsi >/dev/null 2>/dev/null
if [ $? == 0 ]
then
echo “echo
i
p
s
ips
ipsi is online”
else
echo “echo
i
p
s
ips
ipsi is not online”
fi
done
---
#### 【脚本49】检查错误
写一个shell脚本,检查指定的shell脚本是否有语法错误,若有错误,首先显示错误信息,然后提示用户输入q或者Q退出脚本,输入其他内容则直接用vim打开该shell脚本。
提醒: 检查shell脚本有没有语法错误的命令是 sh -n xxx.sh
参考代码:
#!/bin/bash
sh -n $1 2>/tmp/err
if [ $? -eq “0” ]
then
echo “The script is OK.”
else
cat /tmp/err
read -p "Please inpupt Q/q to exit, or others to edit it by vim. " n
if [ -z $n ]
then
vim $1
exit
fi
if [ $n == “q” -o $n == “Q” ]
then
exit
else
vim $1
exit
fi
fi
---
#### 【脚本50】格式化输出
输入一串随机数字,然后按千分位输出。
比如输入数字串为“123456789”,输出为123,456,789
代码参考:
#!/bin/bash
read -p “输入一串数字:” num
v=echo $num|sed 's/[0-9]//g'
if [ -n "
v
"
]
t
h
e
n
e
c
h
o
"
请输入纯数字
.
"
e
x
i
t
f
i
l
e
n
g
t
h
=
v" ] then echo "请输入纯数字." exit fi length=
v"]thenecho"请输入纯数字."exitfilength={#num}
len=0
sum=‘’
for i in $(seq 1
l
e
n
g
t
h
)
d
o
l
e
n
=
length) do len=
length)dolen=[$len+1]
if [[
l
e
n
=
=
3
]
]
t
h
e
n
s
u
m
=
′
,
′
len == 3 ]] then sum=','
len==3]]thensum=′,′{num:
[
0
−
[0-
[0−i]:1}
s
u
m
l
e
n
=
0
e
l
s
e
s
u
m
=
sum len=0 else sum=
sumlen=0elsesum={num:
[
0
−
[0-
[0−i]:1}$sum
fi
done
if [[ -n $(echo $sum | grep ‘^,’ ) ]]
then
echo ${sum:1}
else
echo $sum
fi
上面这个实现比较复杂,下面再来一个sed的:
#!/bin/bash
read -p “输入一串数字:” num
v=echo $num|sed 's/[0-9]//g'
if [ -n “$v” ]
then
echo “请输入纯数字.”
exit
fi
echo $num|sed -r ‘{:number;s/([0-9]+)([0-9]{3})/\1,\2/;t number}’
---
#### 【脚本51】
1 编写一个名为iffile程序,它执行时判断/bin目录下date文件是否存在?
参考代码:
#!/bin/bash
if [ -f /bin/date ]
then
echo “/bin/date file exist.”
else
echo “/bin/date not exist.”
fi
2 编写一个名为greet的问候程序,它执行时能根据系统当前的时间向用户输出问候信息。设从半夜到中午为早晨,中午到下午六点为下午,下午六点到半夜为晚上。
参考代码:
#!/bin/bash
h=date +%H
if [ $h -ge 0 ] && [ $h -lt 12 ]
then
echo “Good morning.”
elif [ $h -ge 12 ] && [ $h -lt 18 ]
then
echo “Good afternoon.”
else
echo “Good evening.”
fi
---
#### 【脚本52】判断用户登录
1 编写一个名为ifuser的程序,它执行时带用户名作为命令行参数,判断该用户是否已经在系统中登录,并给出相关信息。
参考代码:
#!/bin/bash
read -p "Please input the username: " user
if who | grep -qw $user
then
echo $user is online.
else
echo $user not online.
fi
2 编写一个名为menu的程序,实现简单的弹出式菜单功能,用户能根据显示的菜单项从键盘选择执行对应的命令。
参考代码:
#!/bin/bash
function message()
{
echo “0. w”
echo “1. ls”
echo “2.quit”
read -p "Please input parameter: " Par
}
message
while [ $Par -ne ‘2’ ] ; do
case $Par in
0)
w
;;
1)
ls
;;
2)
exit
;;
*)
echo “Unkown command”
;;
esac
message
done
---
#### 【脚本53】更改后缀名
1 编写一个名为chname的程序,将当前目录下所有的.txt文件更名为.doc文件。
参考代码:
#!/bin/bash
find . -type f -name “*.txt” > /tmp/txt.list
for f in cat /tmp/txt.list
do
n=echo $f|sed -r 's/(.*)\.txt/\1/'
echo “mv $f $n.doc”
done
2 编写一个名为chuser的程序,执行中每隔5分钟检查指定的用户是否登录系统,用户名从命令行输入;如果指定的用户已经登录,则显示相关信息。
参考代码:
#!/bin/bash
read -p "Please input the username: " user
while :
do
if who | grep -qw $user
then
echo $user login.
else
echo $user not login.
fi
sleep 300
done
---
#### 【脚本54】判断pid是否一致
先普及一小段知识,我们用ps aux可以查看到进程的PID,而每个PID都会在/proc内产生。如果查看到的pid而proc内是没有的,则是进程被人修改了,这就代表你的系统很有可能已经被\*\*\*过了。
请大家用上面知识编写一个shell,定期检查下自己的系统是否被人\*\*\*过。
参考代码:
#!/bin/bash
ps aux|awk '/[0-9]/ {print KaTeX parse error: Expected 'EOF', got '}' at position 2: 2}̲'|while read pi…pid"`
if [ -z
r
e
s
u
l
t
]
;
t
h
e
n
e
c
h
o
"
result ]; then echo "
result];thenecho"pid abnormal!"
fi
done
---
#### 【脚本55】一列变三行
比如1.txt内容:
1
2
3
4
5
6
7
处理后应该是:
1 2 3
4 5 6
7
可使用sed命令完成:
sed ‘N;N;s/\n/ /g’ 1.txt
---
#### 【脚本56】shell的getops
写一个getinterface.sh 脚本可以接受选项[i,I],完成下面任务:
1. 使用一下形式:getinterface.sh [-i interface | -I ip]
2. 当用户使用-i选项时,显示指定网卡的IP地址;当用户使用-I选项时,显示其指定ip所属的网卡。
* 例:sh getinterface.sh -i eth0
* sh getinterface.sh -I 192.168.0.1
3. 当用户使用除[-i | -I]选项时,显示[-i interface | -I ip]此信息。
4. 当用户指定信息不符合时,显示错误。(比如指定的eth0没有,而是eth1时)
参考代码:
#!/bin/bash
ip add |awk -F “:” ‘$1 ~ /1/ {print $2}’|sed ‘s/ //g’ > /tmp/eths.txt
[ -f /tmp/eth_ip.log ] && rm -f /tmp/eth_ip.log
for eth in cat /tmp/eths.txt
do
ip=ip add |grep -A2 ": $eth" |grep inet |awk '{print $2}' |cut -d '/' -f 1
echo “
e
t
h
:
eth:
eth:ip” >> /tmp/eth_ip.log
done
useage()
{
echo “Please useage: $0 -i 网卡名字 or $0 -I ip地址”
}
wrong_eth()
{
if ! awk -F ‘:’ ‘{print $1}’ /tmp/eth_ip.log | grep -qw “^
1
1
1”
then
echo “请指定正确的网卡名字”
exit
fi
}
wrong_ip()
{
if ! awk -F ‘:’ ‘{print $2}’ /tmp/eth_ip.log | grep -qw “^
1
1
1”
then
echo “请指定正确的ip地址”
exit
fi
}
if [ $# -ne 2 ]
then
useage
exit
fi
case $1 in
-i)
wrong_eth $2
grep -w $2 /tmp/eth_ip.log |awk -F ‘:’ ‘{print $2}’
;;
-I)
wrong_ip $2
grep -w $2 /tmp/eth_ip.log |awk -F ':' '{print $1}'
;;
*)
useage
exit
esac
---
#### 【脚本57】3位随机数字
写一个脚本产生随机3位的数字,并且可以根据用户的输入参数来判断输出几组。 比如,脚本名字为 number3.sh。
执行方法:
bash number3.sh
直接产生一组3位数字。
bash number3.sh 10
插上10组3位数字。
思路: 可以使用echo $RANDOM获取一个随机数字,然后再除以10,取余获取0-9随机数字,三次运算获得一组。
参考代码:
#!/bin/bash
get_a_num() {
n=
[
[
[RANDOM%10]
echo $n
}
get_numbers() {
for i in 1 2 3; do
a[$i]=get_a_num
done
echo ${a[@]}
}
if [ -n “$1” ]; then
m=echo $1|sed 's/[0-9]//g'
if [ -n “$m” ]; then
echo “Useage bash $0 n, n is a number, example: bash $0 5”
exit
else
for i in seq 1 $1
do
get_numbers
done
fi
else
get_numbers
fi
---
#### 【脚本58】检查服务
先判断是否安装http和mysql,没有安装进行安装,安装了检查是否启动服务,若没有启动则需要启动服务。
说明:操作系统为centos6,httpd和mysql全部为rpm包安装。
参考代码:
#!/bin/bash
if_install()
{
n=rpm -qa|grep -cw "$1"
if [ $n -eq 0 ]
then
echo “$1 not install.”
yum install -y $1
else
echo “$1 installed.”
fi
}
if_install httpd
if_install mysql-server
chk_ser()
{
p_n=ps -C "$1" --no-heading |wc -l
if [ $p_n -eq 0 ]
then
echo “$1 not start.”
/etc/init.d/$1 start
else
echo “$1 started.”
fi
}
chk_httpd
chk_mysqld
---
#### 【脚本59】判断日期是否合法
用shell脚本判断输入的日期是否合法。就是判断日期是都是真实的日期,比如20170110就是合法日期,20171332就不合法
参考代码:
#!/bin/bash
#check date
if [ $# -ne 1 ] || [ ${#1} -ne 8 ]
then
echo “Usage: bash $0 yyyymmdd”
exit 1
fi
datem=
1
y
e
a
r
=
1 year=
1year={datem:0:4}
month=
d
a
t
e
m
:
4
:
2
d
a
y
=
{datem:4:2} day=
datem:4:2day={datem:6:2}
if echo $day|grep -q ‘^0’
then
day=echo $day |sed 's/^0//'
fi
if cal $month $year >/dev/null 2>/dev/null
then
daym=cal $month $year|egrep -v "$year|Su"|grep -w "$day"
if [ “$daym” != “” ]
then
echo ok
else
echo “Error: Please input a wright date.”
exit 1
fi
else
echo “Error: Please input a wright date.”
exit 1
fi
---
#### 【脚本60】监控网卡
1.每10分钟检测一次指定网卡的流量
2.如果流量为0,则重启网卡
参考代码:
#!/bin/bash
LANG=en
n1=sar -n DEV 1 60 |grep eth0 |grep -i average|awk '{print $5}'|sed 's/\.//g'
n2=sar -n DEV 1 60 |grep eth0 |grep -i average|awk '{print $6}'|sed 's/\.//g'
if [ $n1 == “000” ] && [ $n2 == “000” ]
then
ifdown eth0
ifup eth0
fi
然后写个cron,10分钟执行一次
---
#### 【脚本61】监控web可用性
写一个shell脚本,通过curl -I 返回的状态码来判定所访问的网站是否正常。比如,当状态码为200时,才算正常。
参考代码:
#/bin/bash
url=“http://www.apelearn.com/index.php”
sta=curl -I $url 2>/dev/null |head -1 |awk '{print $2}'
if [
s
t
a
!
=
"
200
"
]
t
h
e
n
p
y
t
h
o
n
/
u
s
r
/
l
o
c
a
l
/
s
b
i
n
/
m
a
i
l
.
p
y
x
x
x
@
q
q
.
c
o
m
"
sta != "200" ] then python /usr/local/sbin/mail.py xxx@qq.com "
sta!="200"]thenpython/usr/local/sbin/mail.pyxxx@qq.com"url down." “$url down”
fi
---
#### 【脚本62】文件打包
需求:将用户家目录(考虑到执行脚本的用户可能是普通用户也可能是root)下面小于5KB的文件打包成tar.gz的压缩包,并以当前日期为文件名前缀,例如今天打包的文件为2017-09-15.tar.gz。
参考代码:
#!/bin/bash
t=date +%F
cd $HOME
tar czf $t.tar.gz find . -type f -size -5k
---
#### 【脚本63】端口解封
一个小伙伴提到一个问题,他不小心用iptables规则把sshd端口22给封掉了,结果不能远程登陆,要想解决这问题,还要去机房,登陆真机去删除这规则。 问题来了,要写个监控脚本,监控iptables规则是否封掉了22端口,如果封掉了,给打开。 写好脚本,放到任务计划里,每分钟执行一次。
参考代码:
#!/bin/bash
check sshd port drop
/sbin/iptables -nvL --line-number|grep “dpt:22”|awk -F ’ ’ ‘{print $4}’ > /tmp/drop.txt
i=cat /tmp/drop.txt|head -n 1|egrep -iE "DROP|REJECT"|wc -l
if [ $i -gt 0 ]
then
/sbin/iptables -I INPUT 1 -p tcp --dport 22 -j ACCEPT
fi
---
#### 【脚本64】统计分析日志
已知nginx访问的日志文件在/usr/local/nginx/logs/access.log内
请统计下早上10点到12点 来访ip最多的是哪个?
日志样例:
111.199.186.68 – [15/Sep/2017:09:58:37 +0800] “//plugin.php?id=security:job” 200 “POST //plugin.php?id=security:job HTTP/1.1″”http://a.lishiming.net/forum.php?mod=viewthread&tid=11338&extra=page%3D1%26filter%3Dauthor%26orderby%3Ddateline” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.7 Safari/537.36” “0.516”
203.208.60.208 – [15/Sep/2017:09:58:46 +0800] “/misc.php?mod=patch&action=ipnotice&_r=0.05560809863330207&inajax=1&ajaxtarget=ip_notice” 200 “GET /misc.php?mod=patch&action=ipnotice&_r=0.05560809863330207&inajax=1&ajaxtarget=ip_notice HTTP/1.1″”http://a.lishiming.net/forum.php?mod=forumdisplay&fid=65&filter=author&orderby=dateline” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.7 Safari/537.36” “0.065”
实现这个需求使用如下命令即可:
grep ‘15/Sep/2017:1[0-2]:[0-5][0-9]:’ /usr/local/nginx/logs/access.log|awk ‘{print $1}’|sort -n|uniq -c |sort -n|tail -n1
---
#### 【脚本65】打印数字
写一个shell脚本。提示你输入一个暂停的数字,然后从1打印到该数字。然后询问是否继续。继续的话在输入个在数字 接着打印。不继续退出。
例:如果输入的是5,打印1 2 3 4 5 然后继续 输入15 然后打印 6 7 …14 15 依此类推。
参考代码:
#!/bin/bash
read -p “请输入您想要暂停的数字:” number_1
for i in seq 1 $number_1;
do
echo $i
done
read -p “是否继续输入数字?” a
if [
a
=
=
"
y
e
s
"
]
;
t
h
e
n
r
e
a
d
−
p
"
请继续输入您想要暂停的数字:
"
n
u
m
b
e
r
2
n
u
m
b
e
r
3
=
a == "yes" ];then read -p "请继续输入您想要暂停的数字:" number_2 number_3=
a=="yes"];thenread−p"请继续输入您想要暂停的数字:"number2number3=[$number_1+1]
if [ $number_2 -gt $number_1 ];then
for h in seq $number_3 $number_2;
do
echo $h
done
else
echo “输入数字错误,请输入大于的数字!”
fi
else
exit
fi
---
#### 【脚本66】给文档增加内容
在文本文档1.txt第5行(假设文件行数大于5)后面增加如下内容:
This is a test file.
Test insert line into this file.
参考命令:
sed -i “5a # This is a test file.\n# Test insert line into this file.” 1.txt
---
#### 【脚本67】备份etc下面文件
设计一个shell程序,在每月第一天备份并压缩/etc目录的所有内容,存放在/root/bak目录里,且文件名为如下形式”yymmdd\_etc.tar.gz”,yy为年,mm为月,dd为日。
参考代码:
#!/bin/sh
if [ ! -d /root/bak ]
then
mkdir /root/bak
fi
prefix=date +%y%m%d
d=date +%d
if [
d
=
=
"
01
"
]
t
h
e
n
c
d
/
e
t
c
/
t
a
r
c
z
f
/
r
o
o
t
/
b
a
k
/
d == "01" ] then cd /etc/ tar czf /root/bak/
d=="01"]thencd/etc/tarczf/root/bak/prefix_etc.tar.gz ./
fi
---
#### 【脚本68】计算单词重复次数
将文件内所有的单词的重复次数计算出来,只需要列出重复次数最多的10个单词。
假设文档名字叫做a.txt,使用如下命令即可:
sed ‘s/[^a-zA-Z]/ /g’ a.txt|xargs -n1 |sort |uniq -c |sort -nr |head
---
#### 【脚本69】成员分组
需求是,把所有的成员平均得分成若干个小组。这里,我会提供一个人员列表,比如成员有50人,需要分成7个小组,要求随机性,每次和每次分组的结构应该不一致。
假设成员列表文件为members.txt
参考代码:
#!/bin/bash
f=members.txt
n=wc -l $f|awk '{print $1}'
get_n()
{
l=echo $1|wc -c
n1=
R
A
N
D
O
M
n
2
=
RANDOM n2=
RANDOMn2=[
n
1
+
n1+
n1+l]
g_id=
[
[
[n1%7]
if [ $g_id -eq 0 ]
then
g_id=7
fi
echo $g_id
}
for i in seq 1 7
do
[ -f n_KaTeX parse error: Expected 'EOF', got '&' at position 9: i.txt ] &̲& rm -f n_i.txt
done
for i in seq 1 $n
do
name=sed -n "$i"p $f
g=get_n $name
echo KaTeX parse error: Expected group after '_' at position 10: name >> n_̲g.txt
done
nu(){
wc -l $1|awk ‘{print $1}’
}
max(){
ma=0
for i in seq 1 7
do
n=nu n_$i.txt
if [ $n -gt
m
a
]
t
h
e
n
m
a
=
ma ] then ma=
ma]thenma=n
fi
done
echo $ma
}
min(){
mi=50
for i in seq 1 7
do
n=nu n_$i.txt
if [ $n -lt
m
i
]
t
h
e
n
m
i
=
mi ] then mi=
mi]thenmi=n
fi
done
echo $mi
}
ini_min=1
while [ KaTeX parse error: Expected group after '_' at position 106: … n=`nu n_̲i.txt`
if [ $n -eq KaTeX parse error: Expected group after '_' at position 34: … f1=n_̲i.txt
elif [ $n -eq KaTeX parse error: Expected group after '_' at position 33: … f2=n_̲i.txt
fi
done
name=`tail -n1 $f1`
echo $name >>
f
2
s
e
d
−
i
"
/
f2 sed -i "/
f2sed−i"/name/d"
f
1
i
n
i
m
i
n
=
f1 ini_min=
f1inimin=[$ini_min+1]
done
for i in seq 1 7
do
echo "KaTeX parse error: Expected group after '_' at position 19: …成员有:" cat n_̲i.txt
echo
done
---
#### 【脚本70】shell中的小数
有一组式子如下:
a=0.5
b=3
c=a*b
求c的值,参考代码:
#!/bin/bash
a=0.5
b=3
c=echo "scale=1;$a*$b"|bc
echo $c
---
#### 【脚本71】a.txt有b.txt没有
有两个文件a.txt和b.txt,需求是,把a.txt中有的并且b.txt中没有的行找出来,并写入到c.txt,然后计算c.txt文件的行数。
参考代码:
#!/bin/bash
n=wc -l a.txt|awk '{print $1}'
[ -f c.txt ] && rm -f c.txt
for i in seq 1 $n
do
l=sed -n "$i"p a.txt
if ! grep -q “^
l
l
l” b.txt
then
echo $l >>c.txt
fi
done
wc -l c.txt
或者用grep实现
grep -vwf b.txt a.txt > c.txt; wc -l c.txt
---
#### 【脚本72】杀死进程
把当前用户下所有进程名字中含有”java”的进程关闭。
参考答案:
ps -u U S E R ∣ a w k ′ USER |awk ' USER∣awk′NF ~ /java/ {print $1}'|xargs kill
---
#### 【脚本73】备份数据表
用shell实现,以并发进程的形式将mysql数据库所有的表备份到当前目录,并把所有的表压缩到一个压缩包文件里。
假设数据库名字为mydb,用户名为zero,密码为passwd。
提示: 在shell中加上&可以将命令丢到后台,从而可以同时执行多条命令达到并发的效果。
参考代码:
#!/bin/bash
pre=date +%F
for d in mysql -uaming -ppasswd mydb -e "show tables"|grep -v 'Tables_in_'
do
mysqldump -uaming -ppasswd mydb $d > $d.sql &
done
tar czf $pre.tar.gz *.sql
rm -f *.sql
---
#### 【脚本74】监控节点
一个网站,使用了cdn,全国各地有几十个节点。需要你写一个shell脚本来监控各个节点是否正常。
假如:
1. 监控的url为www.xxx.com/index.php
2. 源站ip为88.88.88.88
参考代码:
#!/bin/bash
url=“www.xxx.com/index.php”
s_ip=“88.88.88.88”
curl -x $s_ip:80 $url > /tmp/source.html 2>/dev/null
for ip in cat /tmp/ip.txt
do
curl -x $ip:80
u
r
l
2
>
/
d
e
v
/
n
u
l
l
>
/
t
m
p
/
url 2>/dev/null >/tmp/
url2>/dev/null>/tmp/ip.html
[ -f /tmp/KaTeX parse error: Expected 'EOF', got '&' at position 11: ip.diff ] &̲& rm -f /tmp/ip.diff
touch /tmp/
i
p
.
d
i
f
f
d
i
f
f
/
t
m
p
/
s
o
u
r
c
e
.
h
t
m
l
/
t
m
p
/
ip.diff diff /tmp/source.html /tmp/
ip.diffdiff/tmp/source.html/tmp/ip.html > /tmp/
i
p
.
d
i
f
f
2
>
/
d
e
v
/
n
u
l
l
n
=
‘
w
c
−
l
/
t
m
p
/
ip.diff 2>/dev/null n=`wc -l /tmp/
ip.diff2>/dev/nulln=‘wc−l/tmp/ip.diff|awk ‘{print $1}’`
if [ $n -lt 0 ]
then
echo “node $ip sth wrong.”
fi
done
---
#### 【脚本75】破解字符串
已知下面的字符串是通过RANDOM随机数变量md5sum|cut-c 1-8截取后的结果,请破解这些字符串对应的md5sum前的RANDOM对应数字?
21029299
00205d1c
a3da1677
1f6d12dd
890684ba
解题思路:通过每次传递一个参数的方式,来实现依次破解,$RANDOM的范围为0-32767。
参考代码:
#!/bin/bash
for n in {0…32767}
do
MD5=echo $n | md5sum | cut -c 1-8
if [ “$MD5” == "
1
"
]
;
t
h
e
n
e
c
h
o
"
1" ];then echo "
1"];thenecho"n $1 "
break
fi
done
---
#### 【脚本76】判断cpu厂商
写一个脚本:
1. 判断当前主机的CPU生产商,其信息在/proc/cpuinfo文件中vendor id一行中。
2. 如果其生产商为AuthenticAMD,就显示其为AMD公司;
3. 如果其生产商为GenuineIntel,就显示其为Intel公司;
4. 否则,就说其为非主流公司。
参考代码:
#!/bin/bash
m=cat /proc/cpuinfo |grep vendor_id|awk -F":" '{print $2}'|tail -1
if [ $m == “GenuineIntel” ]
then
echo “cpu is 英特尔”
elif [ $m == “AuthenticAMD” ]
then
echo “cpu is AMD”
else
echo “cpu is 非主流”
fi
---
#### 【脚本77】监控cpu使用率
用shell写一个监控服务器cpu使用率的监控脚本。
思路:用top -bn1 命令,取当前空闲cpu百份比值(只取整数部分),然后用100去剑这个数值。
参考代码:
#!/bin/bash
while :
do
idle=top -bn1 |sed -n '3p' |awk '{print $5}'|cut -d . -f1
use=
[
100
−
[100-
[100−idle]
if [ $use -gt 90 ]
then
echo “cpu use percent too high.”
#发邮件省略
fi
sleep 10
done
---
#### 【脚本78】获取子进程
说明:本shell题目是一个网友在公众号中提问的,正好利用这个每日习题的机会拿出来让大家一起做一做。
给出一个进程PID,打印出该进程下面的子进程以及子进程下面的所有子进程。(只需要考虑子进程的子进程,再往深层次则不考虑)
参考代码:
#!/bin/bash
read -p "please input a pid number: " p
ps -elf > /tmp/ps.log
is_ppid(){
awk ‘{print $5}’ /tmp/ps.log > /tmp/ps1.log
if ! grep -qw “$1” /tmp/ps1.log
then
echo “PID $1 不是系统进程号,或者它不是父进程”
return 1
fi
}
is_ppid $p
if [ $? -eq “1” ]
then
exit
fi
print_cpid(){
p=
1
a
w
k
−
v
p
1
=
1 awk -v p1=
1awk−vp1=p ‘$5 == p1 {print $4}’ /tmp/ps.log |sort -n |uniq >/tmp/p1.log
n=wc -l /tmp/p1.log|awk '{print $1}'
if [ $n -ne 0 ]
then
echo “PID $p 子进程 pid 如下:”
cat /tmp/p1.log
else
echo “PID $p 没有子进程”
fi
}
print_cpid $p
for cp in cat /tmp/p1.log
do
print_cpid $cp
done
另外,一条命令查询的方法是:
pstree -p pid
---
#### 【脚本79】自动添加项目
需求背景:
服务器上,跑的lamp环境,上面有很多客户的项目,每个项目就是一个网站。 由于客户在不断增加,每次增加一个客户,就需要配置相应的mysql、ftp以及httpd. 这种工作是重复性非常强的,所以用脚本实现非常合适。
mysql增加的是对应客户项目的数据库、用户、密码,ftp增加的是对应项目的用户、密码(使用vsftpd,虚拟用户模式),httpd就是要增加虚拟主机配置段。
参考代码:
#!/bin/bash
webdir=/home/wwwroot
ftpudir=/etc/vsftpd/vuuser
mysqlc=“/usr/bin/mysql -uroot -xxxxxx”
httpd_config_f=“/usr/local/apache2/conf/extra/httpd-vhosts.conf”
add_mysql_user()
{
mysql_p=mkpasswd -s 0 -l 12
echo “$pro
m
y
s
q
l
p
"
>
/
t
m
p
/
mysql_p" >/tmp/
mysqlp">/tmp/pro.txt
$mysqlc <<EOF
grant all on
p
.
∗
t
o
"
p.* to "
p.∗to"pro”@‘127.0.0.1’ identified by “$mysql_p”;
EOF
}
add_ftp_user()
{
ftp_p=mkpasswd -s 0 -l 12
echo “
p
r
o
"
>
>
/
r
o
o
t
/
l
o
g
i
n
.
t
x
t
e
c
h
o
"
pro" >> /root/login.txt echo "
pro">>/root/login.txtecho"ftp_p” >> /root/login.txt
db_load -T -t hash -f /root/login.txt /etc/vsftpd/vsftpd_login.db
cd $ftpudir
cp aaa
p
r
o
/
/
这里的
a
a
a
是一个文件,是之前的一个项目,可以作为配置模板
s
e
d
−
i
"
s
/
a
a
a
/
pro //这里的aaa是一个文件,是之前的一个项目,可以作为配置模板 sed -i "s/aaa/
pro//这里的aaa是一个文件,是之前的一个项目,可以作为配置模板sed−i"s/aaa/pro/" $pro //把里面的aaa改为新的项目名字
/etc/init.d/vsftpd restart
}
config_httpd()
{
mkdir
w
e
b
d
i
r
/
webdir/
webdir/pro
chown vsftpd:vsftpd
w
e
b
d
i
r
/
webdir/
webdir/pro
echo -e "<VirtualHost *:80> \n DocumentRoot “/home/internet/www/$pro/” \n ServerName $dom \n #ServerAlias \n " >> $httpd_config_f
/usr/local/apache2/bin/apachectl graceful
}
read -p "input the project name: " pro
read -p "input the domain: " dom
add_mysql_user
add_ftp_user
config_httpd
---
#### 【脚本80】计算器
用shell写一个简易计算器,可以实现加、减、乘、除运算,假如脚本名字为1.sh,执行示例:./1.sh 1 + 2
参考代码:
#!/bin/bash
if [ $# -ne 3 ]
then
echo “参数个数不为3”
echo “当使用乘法时,需要加上脱义符号,例如 $0 1 * 2”
exit 1;
fi
num1=echo $1|sed 's/[0-9.]//g' ;
if [ -n “$num1” ]
then
echo “$1 不是数字” ;
exit 1
fi
num3=echo $3|sed 's/[0-9.]//g' ;
if [ -n “$num3” ]
then
echo “$3 不是数字” ;
exit 1
fi
case $2 in
+)
echo “scale=2;$1+$3” | bc
;;
-)
echo “scale=2;$1-$3” | bc
;;
*)
echo “scale=2;$1*$3” | bc
;;
/)
echo “scale=2;$1/$3” | bc
;;
*)
echo “$2 不是运算符”
;;
esac
---
#### 【脚本81】判断没有文件
判断所给目录内哪些二级目录下没有text.txt文件。
有text.txt文件的二级目录,根据文件计算选项中单词数最大的值(选项间以|分割,单词间以空格分隔)。
假如脚本名字为1.sh, 运行脚本的格式为 ./1.sh 123 root,其中123为目录名字,而root为要计算数量的单词。
说明: 这个shell脚本题目出的有点歧义。 原题给的描述不是很清楚,我另外又改了一下需求,依然不是很清晰。在这里我再做一个补充: 对于有test.txt的目录,计算出该test.txt文件里面所给出单词的次数。不用找最大。
参考代码:
#!/bin/bash
if [ $# -ne 2 ]
then
echo “useage $0 dir word”
exit 1
fi
if [ -d $1 ]
then
cd $1
else
echo “$1目录不存在”
exit 1
fi
for f in ls $1
do
if [ -d $f ]
then
if [ -f $f/test.txt ]
then
n=grep -cw "$2" $f/test.txt
echo “
1
/
1/
1/f/test.txt 里面有$n个$2”
else
echo “
1
/
1/
1/f 下面没有test.txt”
fi
fi
done
---
#### 【脚本82】打印正方形
交互式脚本,根据提示,需要用户输入一个数字作为参数,最终打印出一个正方形。
在这里我提供一个linux下面的特殊字符■,可以直接打印出来。
示例: 如果用户输入数字为5,则最终显示的效果为:
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
参考代码:
#!/bin/bash
read -p “please input a number:” sum
a=echo $sum |sed 's/[0-9]//g'
if [ -n “$a” ]
then
echo “请输入一个纯数字。”
exit 1
fi
for n in seq $sum
do
for m in seq $sum
do
if [ $m -lt $sum ]
then
echo -n "■ "
else
echo “■”
fi
done
done
---
#### 【脚本83】问候用户
写一个脚本,依次向/etc/passwd中的每个用户问好,并且说出对方的ID是什么:
Hello,root,your UID is 0.
参考命令:
awk -F ‘:’ ‘{print “Hello,”$1",your uid is "$3.}’ /etc/passwd
---
#### 【脚本84】按要求处理文本
linux系统 /home目录下有一个文件test.xml,内容如下:
请写出shell脚本删除文件中的注释部分内容,获取文件中所有artifactItem的内容,并用如下格式逐行输出 artifactItem:groupId:artifactId
分析:这个文件比较特殊,但是却很有规律。注释部分内容其实就是<!– –>中间的内容,所以我们想办法把这些内容删除掉就ok了。而artifactItem的内容,其实就是获取中间的内容。然后想办法用提到的格式输出即可。
参考代码:
#!/bin/bash
egrep -v '<!--|-->' 1.txt |tee 2.txt //这行就是删除掉注释的行
grep -n 'artifactItem>' 2.txt |awk '{print $1}' |sed 's/://' > /tmp/line_number.txt
n=`wc -l /tmp/line_number.txt|awk '{print $1}'`
get_value(){
sed -n "$1,$2"p 2.txt|awk -F '<' '{print $2}'|awk -F '>' '{print $1,$2}' > /tmp/value.txt
nu=`wc -l /tmp/value.txt|awk '{print $1}'`
for i in `seq 1 $nu`
do
x=`sed -n "$i"p /tmp/value.txt|awk '{print $1}'`
y=`sed -n "$i"p /tmp/value.txt|awk '{print $2}'`
echo artifactItem:$x:$y
done
}
n2=$[$n/2]
for j in `seq 1 $n2`
do
m1=$[$j*2-1]
m2=$[$j*2]
nu1=`sed -n "$m1"p /tmp/line_number.txt`
nu2=`sed -n "$m2"p /tmp/line_number.txt`
nu3=$[$nu1+1]
nu4=$[$nu2-1]
get_value $nu3 $nu4
done
【脚本85】判断函数
请使用条件函数if撰写一个shell函数 函数名为 f_judge,实现以下功能:
- 当/home/log 目录存在时 将/home目录下所有tmp开头的文件或目录移/home/log 目录。
- 当/home/log目录不存在时,创建该目录,然后退出。
参考代码:
#!/bin/bash
f_judge (){
if [ -d /home/log ]
then
mv /home/tmp* /home/log/
else
mkdir -p /home/log
exit
fi
}
【脚本86】批量杀进程
linux系统中,根目录/root/下有一个文件ip-pwd.ini,内容如下:
10.111.11.1,root,xyxyxy
10.111.11.1,root,xzxzxz
10.111.11.1,root,123456
10.111.11.1,root,xxxxxx
……
文件中每一行的格式都为linux服务器的ip,root用户名,root密码,请用一个shell批量将这些服务器中的所有tomcat进程kill掉。
讲解: 有了ip,用户名和密码,剩下的就是登录机器,然后执行命令了。批量登录机器,并执行命令,咱们课程当中有讲过一个expect脚本。所以本题就是需要这个东西来完成。
首先编辑expect脚本 kill_tomcat.expect:
#!/usr/bin/expect
set passwd [lindex $argv 0]
set host [lindex $argv 1]
spawn ssh root@$host
expect {
"yes/no" { send "yes\r"; exp_continue}
"password:" { send "$passwd\r" }
}
expect "]*"
send "killall java\r"
expect "]*"
send "exit\r"
编辑完后需要给这个文件执行权限:
chmod a+x kill_tomcat.expect
然后编辑shell脚本:
#!/bin/bash
n=`wc -l ip-pwd.ini`
for i in `seq 1 $n`
do
ip=`sed -n "$n"p ip-pwd.ini |awk -F ',' '{print $1}'`
pw=`sed -n "$n"p ip-pwd.ini |awk -F ',' '{print $3}'`
./kill_tomcat.expect $pw $ip
done
【脚本87】处理日志
写一个脚本查找/data/log目录下,最后创建时间是3天前,后缀是*.log的文件,打包后发送至192.168.1.2服务上的/data/log下,并删除原始.log文件,仅保留打包后的文件
参考代码:
#!/bin/bash
find /data/log -name “*.log” -mtime +3 > /tmp/file.list
cd /data/log
tar czvf log.tar.gz `cat /tmp/file.list|xargs`
rsync -a log.tar.gz 192.168.1.2:/data/log # 这一步需要提前做一个免密码登录
for f in `cat /tmp/file.list`
do
rm -f $f
done
【脚本88】处理文本
有如下文本,其中前5行内容为
1111111:13443253456
2222222:13211222122
1111111:13643543544
3333333:12341243123
2222222:12123123123
用shell脚本处理后,按下面格式输出:
[1111111]
13443253456
13643543544
[2222222]
13211222122
12123123123
[3333333]
12341243123
参考代码:
#! /bin/bash
sort -n filename |awk -F ':' '{print $1}'|uniq >id.txt
for id in `cat id.txt`; do
echo "[$id]"
awk -v id2=$id -F ':' '$1==id2 {print $2}' filename
#另外的方式为: awk -F ':' '$1=="'$id'" {print $2}' filename
done
【脚本89】清理日志
要求:两类机器一共300多台,写个脚本自动清理这两类机器里面的日志文件。在堡垒机批量发布,也要批量发布到crontab里面。
A类机器日志存放路径很统一,B类机器日志存放路径需要用匹配(因为这个目录里除了日志外,还有其他文件,不能删除。匹配的时候可用.log)
A类:/opt/cloud/log/ 删除7天前的
B类: /opt/cloud/instances/ 删除15天前的
要求写在一个脚本里面。不用考虑堡垒机上的操作,只需要写出shell脚本。
参考代码:
#!/bin/bash
dir1=/opt/cloud/instances/
dir2=/opt/cloud/log/
if [ -d $dir1 ];then
find $dir1 -type f -name "*.log" -mtime +15 |xargs rm -f
elif [ -d $dir2 ];then
find $dir2 -type f -mtime +7 |xargs rm -f
fi
【脚本90】
贷款有两种还款的方式:等额本金法和等额本息法
简单说明一下等额本息法与等额本金法的主要区别:
等额本息法的特点是:每月的还款额相同,在月供中“本金与利息”的分配比例中,前半段时期所还的利息比例大、本金比例小,还款期限过半后逐步转为本金比例大、利息比例小。所支出的总利息比等额本金法多,而且贷款期限越长,利息相差越大。
等额本金法的特点是:每月的还款额不同,它是将贷款额按还款的总月数均分(等额本金),再加上上期剩余本金的月利息,形成一个月还款额,所以等额本金法第一个月的还款额最多 ,尔后逐月减少,越还越少。所支出的总利息比等额本息法少。
两种还款方式的比较不是我们今天的讨论范围,我们的任务就是做一个贷款计算器。
其中:等额本息每月还款额的计算公式是:
[贷款本金×月利率×(1+月利率)还款月数]÷[(1+月利率)还款月数-1]
参考代码:
#!/bin/bash
read -p "请输入贷款总额(单位:万元):" dkzewy
read -p "请输入贷款年利率(如年利率为6.5%,直接输入6.5):" dknll
read -p "请输入贷款年限(单位:年):" dknx
echo "贷款计算方式:"
echo "1)等额本金计算法"
echo "2)等额本息计算法"
read -p "请选择贷款方式(1|2)" dkfs
dkze=`echo "scale=2;$dkzewy*10000 " | bc -l`
dkll=`echo "scale=6;$dknll/100 " | bc -l`
dkyll=`echo "scale=6;$dkll/12 " | bc -l`
dkqc=$[$dknx*12]
echo "期次 本月还款额 本月利息 未还款额"
debjjsf()
{
yhbj=`echo "scale=2;($dkze/$dkqc)/1 " | bc -l`
whbj=$dkze
for((i=1;i<=$dkqc;i++))
do
bylx=`echo "scale=2;($whbj*$dkyll)/1 " | bc -l`
bybx=`echo "scale=2;($yhbj+$bylx)/1 " | bc -l`
yhke=`echo "scale=2;($yhbj*$i)/1 " | bc -l`
whbj=`echo "$dkze-$yhke " | bc -l`
if [ $i -eq $dkqc ]
then
yhbj=`echo "scale=2;($yhbj+$whbj)/1 " | bc -l`
whbj="0.00"
bybx=`echo "scale=2;($yhbj+$bylx)/1 " | bc -l`
fi
echo "$i $bybx $bylx $whbj"
done
}
debxjsf()
{
bybx=`echo "scale=2;(($dkze*$dkyll*((1+$dkyll)^$dkqc))/(((1+$dkyll)^$dkqc)-1))/1 " | bc -l`
whbj=$dkze
for((i=1;i<=$dkqc;i++))
do
bylx=`echo "scale=2;($whbj*$dkyll)/1 " | bc -l`
yhbj=`echo "scale=2;($bybx-$bylx)/1 " | bc -l`
whbj=`echo "scale=2;($whbj-$yhbj)/1 " | bc -l`
if [ $i -eq $dkqc ]
then
bybx=`echo "scale=2;($yhbj+$whbj)/1 " | bc -l`
whbj="0.00"
fi
echo "$i $bybx $bylx $whbj"
done
}
case $dkfs in
1) debjjsf
;;
2) debxjsf
;;
*) exit 1
;;
esac
【脚本91】监控磁盘io
阿里云的机器,今天收到客服来的电话,说服务器的磁盘io很重。于是登录到服务器查看,并没有发现问题,所以怀疑是间歇性地。
正要考虑写个脚本的时候,幸运的抓到了一个线索,造成磁盘io很高的幕后黑手是mysql。此时去show processlist,但未发现队列。原来只是一瞬间。
只好继续来写脚本,思路是,每5s检测一次磁盘io,当发现问题去查询mysql的processlist。
提示:你可以用iostat -x 1 5 来判定磁盘的io,主要看%util
参考代码:
#!/bin/bash
while :
do
n=`iostat -x 1 5 |tail -n3|head -n1 |awk '{print $NF}'|cut -d. -f1`
if [ $n -gt 70 ]
then
echo "`date` util% is $n%" >>/tmp/mysql_processlist.log
mysql -uroot -pxxxxxx -e "show full processlist" >> /tmp/mysql_processlist.log
fi
sleep 5
done
【脚本92】截取tomcat日志
写一个截取tomcat catalina.out日志的脚本。
tomcat实例t1-t4:
[root@server ~]# tree -L 1 /opt/TOM/
/opt/TOM/
├── crontabs
├── t1
├── t2
├── t3
└── t4
5 directories, 0 files
catalina.out日志路径:
[root@server ~]# find /opt/TOM/ -name catalina.out
/opt/TOM/t1/logs/catalina.out
/opt/TOM/t3/logs/catalina.out
/opt/TOM/t4/logs/catalina.out
/opt/TOM/t2/logs/catalina.out
要求:
- 这个脚本可以取tomcat实例t1-t4的日志
- 这个脚本可以自定义取日志的起始点,比如取今天早上10点之后到现在的数据
- 这个脚本可以自定义取日志的起始点和终点,比如取今天早上9点到晚上8点的数据
catalina.out 日志片段:
Mar 29, 2016 1:52:24 PM org.apache.coyote.AbstractProtocol start
INFO: Starting ProtocolHandler [“http-bio-8080”]
Mar 29, 2016 1:52:24 PM org.apache.coyote.AbstractProtocol start
INFO: Starting ProtocolHandler [“ajp-bio-8009”]
Mar 29, 2016 1:52:24 PM org.apache.catalina.startup.Catalina start
INFO: Server startup in 2102 ms
参考代码:
#!/bin/bash
export LANG=en_US.UTF-8
export PATH=$PATH
IPADD=`/sbin/ifconfig | grep "inet addr" | head -1 | awk '{print $2}'| awk -F '.' '{print $NF}'`
LOGFILE="/opt/TOM/$1/logs/catalina.out"
YEAR=`date +%Y`
DATE=`date +%m%d_%H%M`
TOMCAT=$1
BEGIN_TIME=$YEAR$2
END_TIME=$YEAR$3
##judge is a.m.or p.m.
TIME_HOUR1=`echo ${BEGIN_TIME:9:2}`
cut_log() {
N_DATE1=`echo $1 | sed 's/_/ /g'`
D_DATE1=`echo $2 | sed 's/_/ /g'`
E_DATE1=`echo $3 | sed 's/_/ /g'`
[ $4 ] && N_DATE2=`echo $4 | sed 's/_/ /g'`
[ $5 ] && D_DATE2=`echo $5 | sed 's/_/ /g'`
[ $6 ] && E_DATE2=`echo $6 | sed 's/_/ /g'`
BEGIN=`grep -nE "${N_DATE1}|${D_DATE1}|${E_DATE1}" ${LOGFILE} | head -1 | cut -d : -f1`
[ "$N_DATE2" ] && END=`grep -nE "${N_DATE2}|${D_DATE2}|${E_DATE2}" ${LOGFILE} | tail -1 | cut -d : -f1`
[ ! -z "${TIME_HOUR1}" ] && if [ ${TIME_HOUR1} -gt 12 ] ; then
BEGIN1=`grep -nE "${N_DATE1}|${D_DATE1}|${E_DATE1}" ${LOGFILE} |grep " PM " |grep "${E_DATE1}" | head -1 | cut -d : -f1`
if [ ! -z "${BEGIN1}" ] ; then
[ "${BEGIN1}" -gt "${BEGIN}" ] ; BEGIN=${BEGIN1}
fi
fi
if [ "$BEGIN" ] && [ -z "$END" ] ; then
if [ "$N_DATE2" ]; then
echo "${END_TIME}时间点没有访问日志,请重新设置时间点."
else
sed -n "${BEGIN},[ DISCUZ_CODE_0 ]quot;p ${LOGFILE} > /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.log
fi
elif [ "$END" ];then
[ "$BEGIN" ] || BEGIN=1
sed -n "${BEGIN},${END}"p ${LOGFILE} > /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.log
else
[ "$END_TIME" != "$YEAR" ] && echo "该时段 ${BEGIN_TIME}~${END_TIME} 没有日志."
[ "$END_TIME" = "$YEAR" ] && echo "该时段 ${BEGIN_TIME}~now 没有日志."
fi
if [ -s /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.log ]; then
cd /home/gcweb && tar -zcf ${IPADD}_${TOMCAT}_${DATE}.tar.gz ${IPADD}_${TOMCAT}_${DATE}.log
rm -f /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.log
sz /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.tar.gz
echo "Success to get logs."
rm -f /home/gcweb/${IPADD}_${TOMCAT}_${DATE}.tar.gz
fi
}
get_time() {
case "$1" in
4)
N_DATE=`date -d "$2" +"%Y-%m-%d" 2>/dev/null`
D_DATE=`date -d "$2" +"%Y/%m/%d" 2>/dev/null`
E_DATE=`date -d "$2" +"%h %e,_%Y" 2>/dev/null|sed 's/ /_/g'`
echo $N_DATE $D_DATE $E_DATE
;;
7)
TIME=`echo $2 | awk -F'_' '{print $1,$2}'`
N_DATE=`date -d "$TIME" +"%Y-%m-%d_%H" 2>/dev/null`
D_DATE=`date -d "$TIME" +"%Y/%m/%d_%H" 2>/dev/null`
E_DATE=`date -d "$TIME" +"%h %e,_%Y %l" 2>/dev/null|sed 's/ /_/g'`
echo "$N_DATE" "$D_DATE" "$E_DATE"
;;
9)
TIME=`echo $2 | awk -F'_' '{print $1,$2}'`
N_DATE=`date -d "$TIME" +"%Y-%m-%d_%H:%M" 2>/dev/null`
D_DATE=`date -d "$TIME" +"%Y/%m/%d_%H:%M" 2>/dev/null`
E_DATE=`date -d "$TIME" +"%h %e,_%Y %l:%M" 2>/dev/null|sed 's/ /_/g'`
echo "$N_DATE" "$D_DATE" "$E_DATE"
;;
*)
echo 1
;;
esac
}
check_arguments () {
if [ "$1" == 1 ] || [ -z "$1" ] ;then
echo "你输入时间参数的格式无法识别, usage: 0108、0108_10、0108_1020"
exit 3
fi
}
check_tomcat () {
if [ ! -s "${LOGFILE}" ] ;then
echo "tomcat_name: ${TOMCAT} is not exist"
echo "you can choose:"
/bin/ls /home/gcweb/usr/local/
fi
if [ $1 -lt 2 ] || [ ! -s "${LOGFILE}" ];then
echo "usage: $0 tomcat_name {begin_time|begin_time end_time}"
exit 2
fi
}
case "$#" in
0)
echo "usage: $0 tomcat_name {begin_time|begin_time end_time}"
exit 1
;;
1)
check_tomcat $#
;;
2)
check_tomcat $#
len=`echo $2 | awk '{print length($0)}'`
A_DATE=$(get_time $len $BEGIN_TIME)
eval $( echo $A_DATE |awk '{print "N_DATE="$1,"D_DATE="$2,"E_DATE="$3}')
check_arguments "${N_DATE}"
cut_log "${N_DATE}" "${D_DATE}" "${E_DATE}"
;;
3)
check_tomcat $#
len1=`echo $2 | awk '{print length($0)}'`
len2=`echo $3 | awk '{print length($0)}'`
A_DATE=$(get_time ${len1} $BEGIN_TIME)
eval $( echo $A_DATE |awk '{print "N_DATE1="$1,"D_DATE1="$2,"E_DATE1="$3}')
check_arguments "${N_DATE1}"
A_DATE=$(get_time ${len2} $END_TIME)
eval $( echo $A_DATE |awk '{print "N_DATE="$1,"D_DATE="$2,"E_DATE="$3}')
check_arguments "${N_DATE}"
cut_log ${N_DATE1} ${D_DATE1} ${E_DATE1} "${N_DATE}" "${D_DATE}" "${E_DATE}"
;;
*)
echo "usage: $0 tomcat_name {begin_time|begin_time end_time};你使用的参数太多哦."
;;
esac
【脚本93】数组
写一个脚本让用户输入多个城市的名字(可以是中文),要求不少于5个,然后把这些城市存到一个数组里,最后用for循环把它们打印出来。
参考代码:
#!/bin/bash
read -p "请输入至少5个城市的名字,用空格分隔:" city
n=`echo $city|awk '{print NF}'`
if [ $n -lt 5 ]
then
echo "输入的城市个数至少为5"
exit
fi
name=($city)
for i in ${name[@]}
do
echo $i
done
【脚本94】批量同步代码
需求背景是:
一个业务,有3台服务器(A,B,C)做负载均衡,由于规模太小目前并未使用专业的自动化运维工具。有新的需求时,开发同事改完代码会把变更上传到其中一台服务器A上。但是其他2台服务器也需要做相同变更。
写一个shell脚本,把A服务器上的变更代码同步到B和C上。
其中,你需要考虑到不需要同步的目录(假如有tmp、upload、logs、caches)
参考代码:
#!/bin/bash
echo "该脚本将会把A机器上的/data/wwwroot/www.aaa.com目录同步到B,C机器上";
read -p "是否要继续?(y|n) "
rs() {
rsync -azP \
--exclude logs \
--exclude upload \
--exclude caches \
--exclude tmp \
www.aaa.com/ $1:/data/wwwroot/www.aaa.com/
}
if [ $REPLY == 'y' -o $REPLY == 'Y' ]
then
echo "即将同步……"
sleep 2
cd /data/wwwroot/
rs B机器ip
rs C机器ip
echo "同步完成。"
elif [ $REPLY == 'n' -o $REPLY == 'N' ]
then
exit 1
else
echo "请输入字母y或者n"
fi
【脚本95】统计并发量
需求背景:
- 需要统计网站的并发量,并绘图。
思路:
- 借助zabbix成图
- 通过统计访问日志每秒的日志条数来判定并发量
- zabbix获取数据间隔30s
说明: 只需要写出shell脚本即可,不用关心zabbix配置。
假设日志路径为:
/data/logs/www.aaa.com_access.log
日志格式如下:
112.107.15.12 - [07/Nov/2017:09:59:01 +0800] www.aaa.com "/api/live.php" 200"-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)"
参考代码:
#!/bin/bash
log=/data/logs/www.aaa.com_access.log
t=`date -d "-1 second" +%Y:%H:%M:%S`
#可以大概分析一下每分钟日志的量级,比如说不超过3000
n=tail -3000 $log |grep -c "$t"
echo $n
【脚本96】关闭服务
在centos6系统里,我们可以使用ntsysv关闭不需要开机启动的服务,当然也可以使用chkconfig工具来实现。
写一个shell脚本,用chkconfig工具把不常用的服务关闭。脚本需要写成交互式的,需要我们给它提供关闭的服务名字。
参考代码:
#!/bin/bash
LANG=en
c="1"
while [ ! $c == "q" ]
do
echo -e "\033[35mPlease chose a service to close from this list: \033[0m"
chkconfig --list |awk '/3:on/ {print $1}'
read -p "Which service to close: " s
chkconfig $s off
service $s stop
read -p "If you want's to quit this program, tab "q", or tab "Ctrl c": " c
done
【脚本97】重启tomcat服务
在生产环境中,经常遇到tomcat无法彻底关闭,也就是说用tomcat自带shutdown.sh脚本无法将java进程完全关掉。所以,需要借助shell脚本,将进程杀死,然后再启动。
写一个shell脚本,实现上述功能。彻底杀死一个进程的命令是 kill -9 pid.
参考代码:
#!/bin/bash
###功能: 重启 tomcat 进程
###要求:对于tomcat中的某些应用,使用shutdown.sh是无法完全停掉所有服务的 实际操作中都需要kill掉tomcat再重启
##
### root can not run this script.
##
if [ $USER = root ]
then
echo "root cann't run this script!please run with other user!"
exit 1
fi
##
### check the Parameter
##
if [[ $# -ne 1 ]]
then
echo "Usage:$0 tomcatname"
exit 1
fi
##
### only one process can run one time
##
TMP_FILE_U=/tmp/.tmp.ps.keyword.$USER.956327.txt
#echo $TMP_FILE_U
KEYWORD1="$0"
KEYWORD2="$1"
# 使用赋值会多fork出一个进程,所以要先重定向到一个文本,再统计.
ps ux |grep "$KEYWORD1"|grep "\<$KEYWORD2\>"|grep -v "grep" > $TMP_FILE_U
Pro_count=`cat $TMP_FILE_U |wc -l`
if [ $Pro_count -gt 1 ]
then
echo "An other process already running ,exit now!"
exit 1
fi
###################################################
# #
# begin of the script #
# #
###################################################
##
### set the Parameter
##
TOM=`echo $1|sed 's#/##g'`
TOMCAT_DIRECTORY=~/usr/local/$TOM
STARTUP_SCRIPT=$TOMCAT_DIRECTORY/bin/startup.sh
TOMCAT_LOG=$TOMCAT_DIRECTORY/logs/catalina.out
CONF_FILE=$TOMCAT_DIRECTORY/conf/server.xml
TEMPFILE=/tmp/.tmpfile.x.89342.c4r3.tmp
##
### check if the tomcat directory exist
##
if [ ! -d "$TOMCAT_DIRECTORY" ]
then
echo "the tomcat \"$TOM\" not exist.check again!"
exit 1
fi
##
### log roteta and delete log one week ago
##
rotate_log(){
TIME_FORMART=$(date +%Y%m%d%H%M%S)
LOG_DIR=$(dirname $TOMCAT_LOG)
mv $TOMCAT_LOG ${TOMCAT_LOG}_${TIME_FORMART}
find $LOG_DIR -type f -ctime +7 -exec rm -rf {} \;
}
##
### function start the tomcat
##
start_tomcat()
{
#echo start-tomcat-func
if [ -x "$STARTUP_SCRIPT" ]
then
rotate_log
$STARTUP_SCRIPT
sleep 1
tail -f $TOMCAT_LOG
else
if [ -e $STARTUP_SCRIPT ]
then
chmod +x $STARTUP_SCRIPT
# echo "permition added!"
if [ -x "$STARTUP_SCRIPT" ]
then
rotate_log
$STARTUP_SCRIPT
sleep 1
tail -f $TOMCAT_LOG
else
echo "The script not have excute permision,Couldn't add permision to Script!"
exit 1
fi
else
echo "error,the script \"startup.sh\" not exist!"
exit 1
fi
fi
}
##
### function stop the tomcat
##
stop_tomcat()
{
rm -rf $TEMPFILE
ps ux |grep /$TOM/ |grep -v "grep /$TOM/"|grep java > $TEMPFILE
Pro_Count=`cat $TEMPFILE|wc -l`
PIDS=`cat $TEMPFILE|awk '{print $2}'`
rm -rf $TEMPFILE
#echo $Pro_Count
if [ $Pro_Count -eq 0 ]
then
echo "The tomcat not running now!"
else
if [ $Pro_Count -ne 1 ]
then
echo "The have $Pro_Count process running,killed!"
kill -9 `echo $PIDS`
WC=`ps aux | grep "/$TOM/" | grep -v "grep /$TOM/" | grep java |wc -l`
[ $WC -ne 0 ] && (echo "kill process failed!";exit 1)
else
echo "Process killed!"
kill -9 `echo $PIDS`
WC=`ps aux | grep "/$TOM/" | grep -v "grep /$TOM/" | grep java |wc -l`
[ $WC -ne 0 ] && (echo "kill process failed!";exit 1)
fi
fi
}
###########################
#### ####
#### The main script ####
#### ####
###########################
echo -e "are you sure restart $TOM?(y or n)"
read ANS
if [ "$ANS"a != ya ]
then
echo -e "bye! \n"
exit 1
fi
stop_tomcat
echo "start tomcat ..."
sleep 2
start_tomcat
# end
【脚本98】取消后缀
至少用两种方法,批量把当前目录下面所有文件名后缀为.bak的后缀去掉,比如1.txt.bak去掉后为1.txt
假设取消的后缀为.bak
方法一:
#!/bin/bash
for i in `ls *.bak`
do
mv $i `echo $i|sed 's/\.bak//g'`
done
方法二:
#!/bin/bash
for i in `ls *.bak`
do
newname=`echo $i|awk -F '.bak' '{print $1}'`
mv $i $newname
done
【脚本99】域名到期提醒
写一个shell脚本,查询指定域名的过期时间,并在到期前一周,每天发一封提醒邮件。
思路: 大家可以在linux下使用命令“whois 域名”,如”whois xxx.com”,来获取该域名的一些信息。
提示: whois命令,需要安装jwhois包
参考代码:
#!/bin/bash
t1=`date +%s`
is_install_whois()
{
which whois >/dev/null 2>/dev/null
if [ $? -ne 0 ]
then
yum install -y jwhois
fi
}
notify()
{
e_d=`whois $1|grep 'Expiry Date'|awk '{print $4}'|cut -d 'T' -f 1`
e_t=`date -d "$e_d" +%s`
n=`echo "86400*7"|bc`
e_t1=$[$e_t-$n]
if [ $t1 -ge $e_t1 ] && [ $t1 -lt $e_t ]
then
/usr/local/sbin/mail.py aming_test@163.com "Domain $1 will be expire." "Domain $1 expire date is $e_d."
fi
}
is_install_whois
notify xxx.com
【脚本100】自动增加公钥
写一个shell脚本,当我们执行时,提示要输入对方的ip和root密码,然后可以自动把本机的公钥增加到对方机器上,从而实现密钥认证。
参考代码:
#!/bin/bash
read -p "Input IP: " ip
ping $ip -w 2 -c 2 >> /dev/null
## 查看ip是否可用
while [ $? -ne 0 ]
do
read -p "your ip may not useable, Please Input your IP: " ip
ping $ip -w 2 -c 2 >> /dev/null
done
read -p "Input root\'s password of this host: " password
## 检查命令子函数
check_ok() {
if [ $? != 0 ]
then
echo "Error!."
exit 1
fi
}
## yum需要用到的包
myyum() {
if ! rpm -qa |grep -q "$1"
then
yum install -y $1
check_ok
else
echo $1 already installed
fi
}
for p in openssh-clients openssh expect
do
myyum $p
done
## 在主机A上创建密钥对
if [ ! -f ~/.ssh/id_rsa ] || [ ! -f ~/.ssh/id_rsa.pub ]
then
if [ -d ~/.ssh ]
then
mv ~/.ssh/ ~/.ssh_old
fi
echo -e "\n" | ssh-keygen -t rsa -P ''
check_ok
fi
## 传私钥给主机B
if [ ! -d /usr/local/sbin/rsync_keys ]
then
mkdir /usr/local/sbin/rsync_keys
fi
cd /usr/local/sbin/rsync_keys
if [ -f rsync.expect ]
then
d=`date +%F-%T`
mv rsync.expect $d.expect
fi
#创建远程同步的expect文件
cat > rsync.expect <<EOF
#!/usr/bin/expect
set host [lindex \$argv 0]
#主机B的密码
set passwd [lindex \$argv 1]
spawn rsync -av /root/.ssh/id_rsa.pub root@\$host:/tmp/tmp.txt
expect {
"yes/no" { send "yes\r"; exp_continue}
"password:" { send "\$passwd\r" }
}
expect eof
spawn ssh root@\$host
expect {
"password:" { send "\$passwd\r" }
}
expect "]*"
send "\[ -f /root/.ssh/authorized_keys \] && cat /tmp/tmp.txt >>/root/.ssh/authorized_keys \r"
expect "]*"
send "\[ -f /root/.ssh/authorized_keys \] || mkdir -p /root/.ssh/ \r"
send "\[ -f /root/.ssh/authorized_keys \] || mv /tmp/tmp.txt /root/.ssh/authorized_keys\r"
expect "]*"
send "chmod 700 /root/.ssh; chmod 600 /root/.ssh/authorized_keys\r"
expect "]*"
send "exit\r"
EOF
check_ok
/usr/bin/expect /usr/local/sbin/rsync_keys/rsync.expect $ip $password
echo "OK,this script is successful. ssh $ip to test it"
【脚本101】自动封/解封ip
需求背景:
discuz论坛,每天有很多注册机注册的用户,然后发垃圾广告帖子。虽然使用了一些插件但没有效果。分析访问日志,发现有几个ip访问量特别大,所以想到可以写个shell脚本,通过分析访问日志,把访问量大的ip直接封掉。
但是这个脚本很有可能误伤,所以还需要考虑到自动解封这些ip。
思路:
- 可以每分钟分析1次访问日志,设定一个阈值,把访问量大的ip用iptables封掉80端口
- 每20分钟检测一次已经被封ip的请求数据包数量,设定阈值,把没有请求的或者请求量很小的解封
参考代码:
#! /bin/bash
## To block the ip of bad requesting.
## Writen by aming 2017-11-18.
log="/data/logs/www.xxx.com.log"
tmpdir="/tmp/badip"
#白名单ip,不应该被封
goodip="27.133.28.101"
[ -d $tmpdir ] || mkdir -p $tmpdir
t=`date -d "-1 min" +%Y:%H:%M`
#截取一分钟以前的日志
grep "$t:" $log > $tmpdir/last_min.log
#把一分钟内日志条数大于120的标记为不正常的请求
awk '{print $1}' $tmpdir/last_min.log |sort -n |uniq -c |sort -n |tail |awk '$1>120 {print $2}'|grep -v "$good_ip"> $tmpdir/bad.ip
d3=`date +%M`
#每隔20分钟解封一次ip
if [ $d3 -eq "20" ] || [ $d3 -eq "40" ] || [ $d3 -eq "00" ]
then
/sbin/iptables -nvL INPUT|grep 'DROP' |awk '$1<10 {print $8}'>$tmpdir/good.ip
if [ -s $tmpdir/good.ip ]
then
for ip in `cat $tmpdir/good.ip`
do
/sbin/iptables -D INPUT -p tcp --dport 80 -s $ip -j DROP
d4=`date +%Y%m%d-%H:%M`
echo "$d4 $ip unblock" >>$tmpdir/unblock.ip
done
fi
#解封后,再把iptables的计数器清零
/sbin/iptables -Z INPUT
fi
if [ -s $tmpdir/bad.ip ]
then
for ip in `cat $tmpdir/bad.ip`
do
/sbin/iptables -A INPUT -p tcp --dport 80 -s $ip -j DROP
d4=`date +%Y%m%d-%H:%M`
echo "$d4 $ip block" >>$tmpdir/block.ip
done
fi
【脚本102】单机部署SpringBoot项目
有一台测试服务器,经常需要部署SpringBoot项目,手动部署太麻烦,于是写了个部署脚本
脚本代码:
#!/bin/bash
# git仓库路径
GIT_REPOSITORY_HOME=/app/developer/git-repository
# jar包发布路径
PROD_HOME=/prod/java-back
# 应用列表
APPS=(app1 app2 app3)
if [ ! -n "$1" ]
then
为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
# 【脚本101】自动封/解封ip
需求背景:
discuz论坛,每天有很多注册机注册的用户,然后发垃圾广告帖子。虽然使用了一些插件但没有效果。分析访问日志,发现有几个ip访问量特别大,所以想到可以写个shell脚本,通过分析访问日志,把访问量大的ip直接封掉。
但是这个脚本很有可能误伤,所以还需要考虑到自动解封这些ip。
思路:
1. 可以每分钟分析1次访问日志,设定一个阈值,把访问量大的ip用iptables封掉80端口
2. 每20分钟检测一次已经被封ip的请求数据包数量,设定阈值,把没有请求的或者请求量很小的解封
参考代码:
#! /bin/bash
To block the ip of bad requesting.
Writen by aming 2017-11-18.
log=“/data/logs/www.xxx.com.log”
tmpdir=“/tmp/badip”
#白名单ip,不应该被封
goodip=“27.133.28.101”
[ -d $tmpdir ] || mkdir -p $tmpdir
t=date -d "-1 min" +%Y:%H:%M
#截取一分钟以前的日志
grep “$t:” $log > $tmpdir/last_min.log
#把一分钟内日志条数大于120的标记为不正常的请求
awk ‘{print $1}’ $tmpdir/last_min.log |sort -n |uniq -c |sort -n |tail |awk '$1>120 {print KaTeX parse error: Expected 'EOF', got '}' at position 2: 2}̲'|grep -v "good_ip"> $tmpdir/bad.ip
d3=date +%M
#每隔20分钟解封一次ip
if [ $d3 -eq “20” ] || [ $d3 -eq “40” ] || [ $d3 -eq “00” ]
then
/sbin/iptables -nvL INPUT|grep ‘DROP’ |awk '$1<10 {print KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲'>tmpdir/good.ip
if [ -s $tmpdir/good.ip ]
then
for ip in cat $tmpdir/good.ip
do
/sbin/iptables -D INPUT -p tcp --dport 80 -s
i
p
−
j
D
R
O
P
d
4
=
‘
d
a
t
e
+
e
c
h
o
"
ip -j DROP d4=`date +%Y%m%d-%H:%M` echo "
ip−jDROPd4=‘date+echo"d4
i
p
u
n
b
l
o
c
k
"
>
>
ip unblock" >>
ipunblock">>tmpdir/unblock.ip
done
fi
#解封后,再把iptables的计数器清零
/sbin/iptables -Z INPUT
fi
if [ -s $tmpdir/bad.ip ]
then
for ip in cat $tmpdir/bad.ip
do
/sbin/iptables -A INPUT -p tcp --dport 80 -s
i
p
−
j
D
R
O
P
d
4
=
‘
d
a
t
e
+
e
c
h
o
"
ip -j DROP d4=`date +%Y%m%d-%H:%M` echo "
ip−jDROPd4=‘date+echo"d4
i
p
b
l
o
c
k
"
>
>
ip block" >>
ipblock">>tmpdir/block.ip
done
fi
---
#### 【脚本102】单机部署SpringBoot项目
有一台测试服务器,经常需要部署SpringBoot项目,手动部署太麻烦,于是写了个部署脚本
脚本代码:
#!/bin/bash
git仓库路径
GIT_REPOSITORY_HOME=/app/developer/git-repository
jar包发布路径
PROD_HOME=/prod/java-back
应用列表
APPS=(app1 app2 app3)
if [ ! -n “$1” ]
then
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。
[外链图片转存中…(img-maC8Autu-1713285850991)]
本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-ELeVBbjZ-1713285850991)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
1-9 ↩︎














 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









