







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
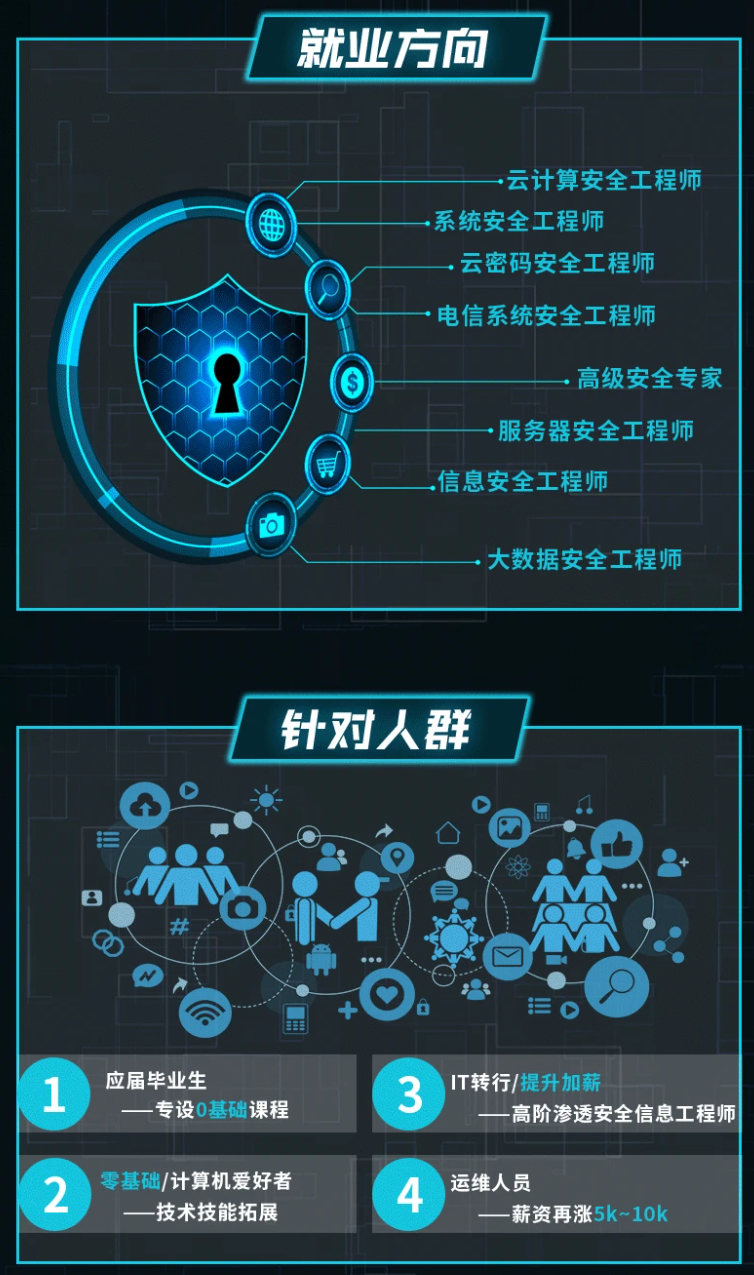
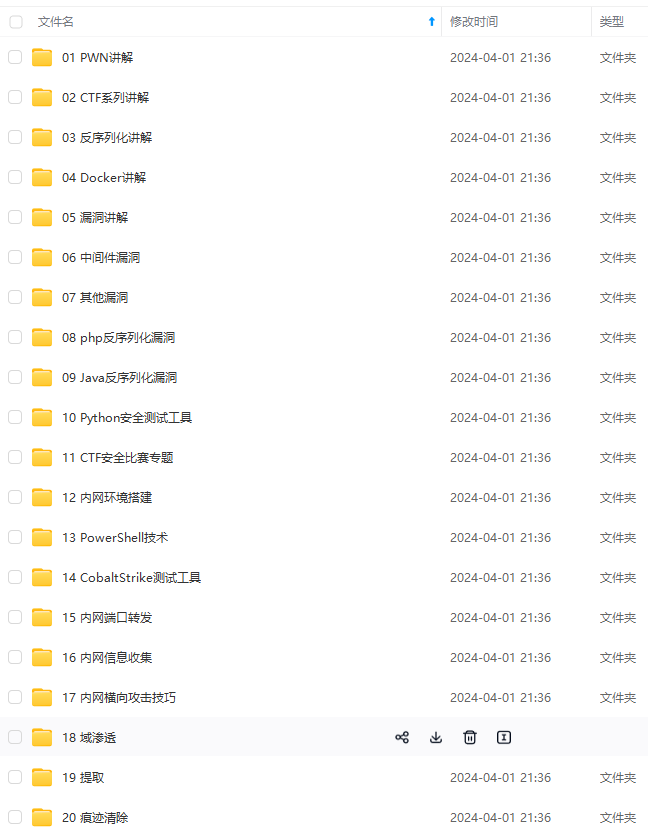
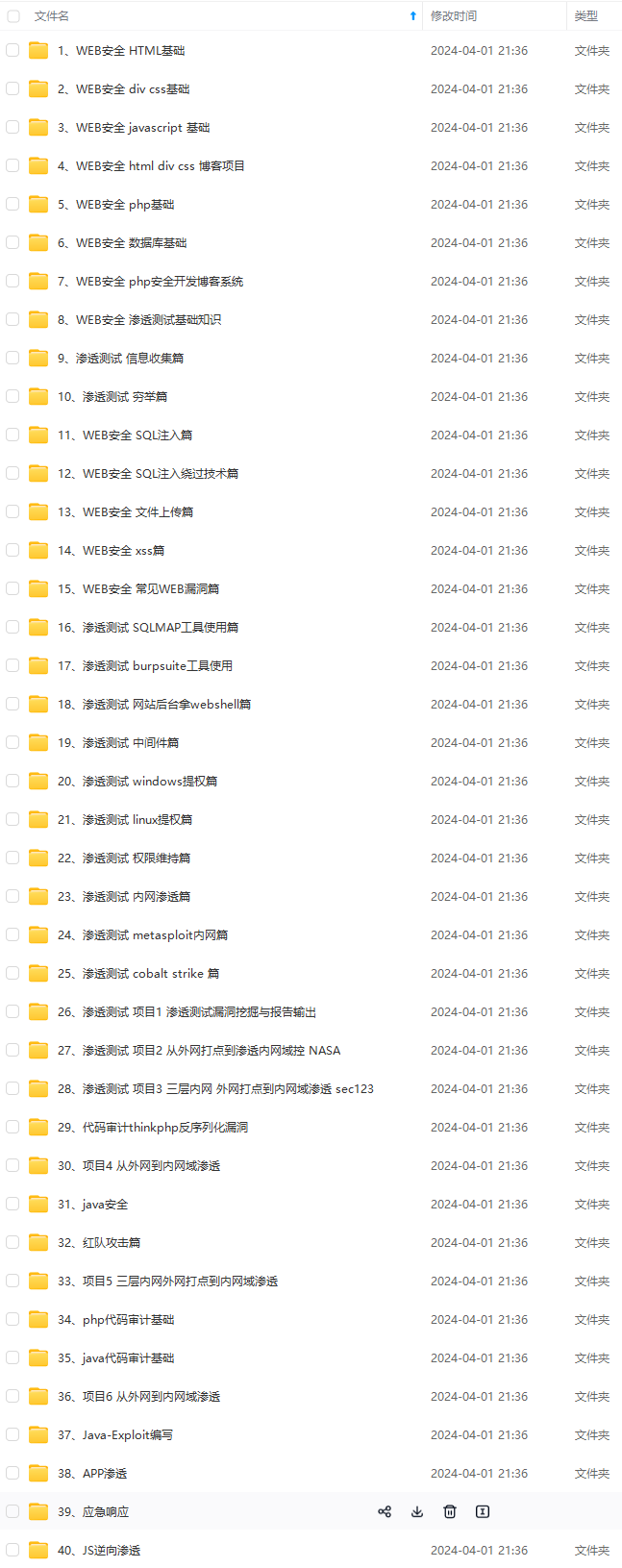
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
C
(
x
ε
)
=
t
C(x+\varepsilon)=t
C(x+ε)=t是高度非线性的,因此现有的算法都难以直接求解,上面的式子,所以需要选择一种更适合优化的表达方式。即定义一个目标函数
f
f
f,当且仅当
f
(
x
ε
)
≤
0
f(x+\varepsilon)\le0
f(x+ε)≤0时,
C
(
x
ε
)
=
t
C(x+\varepsilon)=t
C(x+ε)=t。我们可以用如下的一个式子来当做
f
f
f。
f
(
x
′
)
=
(
m
a
x
i
≠
t
(
F
(
x
′
)
i
)
−
F
(
x
′
)
t
)
f(x’) = (max_{i\ne t}(F(x’)_i)-F(x’)_t)^+
f(x′)=(maxi=t(F(x′)i)−F(x′)t)+
式中,
t
t
t表示定向攻击标签,
(
∗
)
(*)^+
(∗)+表示
m
a
x
(
∗
,
0
)
;
max(*,0);
max(∗,0);,
F
(
x
′
)
i
F(x’)_i
F(x′)i表示当神经网络输入为
x
′
x’
x′时,产生类别是
i
i
i的概率;
Z
(
x
′
)
Z(x’)
Z(x′)表示softmax层前的输出,即
F
(
x
)
=
s
o
f
t
m
a
x
(
Z
(
x
)
)
F(x)=softmax(Z(x))
F(x)=softmax(Z(x));
l
o
s
s
F
,
t
(
x
′
)
loss_{F,t}(x’)
lossF,t(x′)为交叉熵。
上面给出的
f
(
x
)
f(x)
f(x),
m
a
x
i
≠
t
(
F
(
x
′
)
i
)
max_{i\ne t}(F(x’)_i)
maxi=t(F(x′)i)表示除了目标类别
t
t
t外,模型当前输入认为最有可能属于类别
i
i
i,输入类别
i
i
i的概率依旧小于类别
t
t
t的概率,认为此时攻击成功。换言之,就是当识别为类别
t
t
t的概率最大时,认为攻击成功。
所以可以对公式进行重新改写。
minimize
D
(
x
,
x
ε
)
s.t.
f
(
x
ϵ
)
≤
0
x
ε
∈
[
0
,
1
]
n
\begin{aligned} & \text{minimize} \quad D(x, x + \varepsilon) \ & \text{s.t.} \quad f(x + \epsilon) \le 0\ & \quad x + \varepsilon \in [0, 1]^n \end{aligned}
minimizeD(x,x+ε)s.t.f(x+ϵ)≤0x+ε∈[0,1]n
这个地方应该还是
x
ϵ
∈
[
0
,
1
]
n
x + \epsilon \in [0, 1]^n
x+ϵ∈[0,1]n好一点,原书的公式不带上标n,不清楚为什么。
将上述的约束条件转换为目标函数,令距离度量函数
D
D
D为
L
p
L_p
Lp范数,得到以下约束:
m
i
n
∣
∣
δ
∣
∣
p
c
f
(
x
ε
)
s
.
t
.
x
ε
∈
[
0
,
1
]
n
min\quad||\delta||_p+cf(x+\varepsilon)\ s.t. \quad x+\varepsilon \in [0,1]^n
min∣∣δ∣∣p+cf(x+ε)s.t.x+ε∈[0,1]n
其中的
∣
∣
δ
∣
∣
p
||\delta||_p
∣∣δ∣∣p项即上面式子中的
D
(
x
,
x
ε
)
D(x, x + \varepsilon)
D(x,x+ε),这一项代表着对抗样本和原始样本的
L
2
L_2
L2范数距离,也就是扰动,回顾对抗样本生成的目标:“生成样本与原始干净样本尽量的相似”,使这一项最小化,就保证了生成的对抗样本与原始样本尽可能地相似;
c
f
(
x
ε
)
cf(x+\varepsilon)
cf(x+ε)表示分类结果越符合目标结果越好,上面给出的
f
(
x
)
f(x)
f(x)中,如果
F
(
x
′
)
t
F(x’)_t
F(x′)t越大(即分类为目标类的概率越大),那么
c
f
(
x
ε
)
cf(x+\varepsilon)
cf(x+ε)的值越小,也就为了满足生成对抗样本的第二个要求:生成样本确实能成功攻击模型。
由于对抗样本增加、减去剃度之后很容易超出
[
0
,
1
]
[0,1]
[0,1]的范围,为了生成有效的图片,需要对其进行约束,使得
0
≤
x
i
δ
i
≤
1
0\le x_i+\delta_i \le 1
0≤xi+δi≤1。对生成样本进行clip截断就可以将其约束在[0,1]的范围内,我们可以现在只需不断的进行迭代,找到最小值就可以生成对抗样本了。
然而,使用截断的思想,但会使攻击性能下降,CW算法提出的思想,将其映射到tanh空间,为此,CW算法作者引入了新的变量
w
w
w。
x
δ
=
1
2
(
t
a
n
h
(
w
)
1
)
δ
=
1
2
(
t
a
n
h
(
w
)
1
)
−
x
x+\delta = \frac{1}{2}(tanh(w)+1)\ \delta = \frac{1}{2}(tanh(w)+1)-x
x+δ=21(tanh(w)+1)δ=21(tanh(w)+1)−x
因为tanh函数的值域为
[
−
1
,
1
]
[-1,1]
[−1,1],所以
x
δ
x+\delta
x+δ的取值范围是
[
0
,
1
]
[0,1]
[0,1],这样就满足了约束条件。
下面给出已CW算法的
L
2
L_2
L2范数攻击定义式
m
i
n
i
m
i
z
e
∣
∣
1
2
(
t
a
n
h
(
w
)
1
)
−
x
∣
∣
2
2
c
f
(
1
2
(
t
a
n
h
(
w
)
1
)
)
f
(
x
′
)
=
m
a
x
(
m
a
x
{
Z
(
x
′
)
i
:
i
≠
t
}
−
Z
(
x
′
)
t
,
−
K
)
minimize \quad ||\frac{1}{2}(tanh(w)+1)-x||_2^2+cf(\frac{1}{2}(tanh(w)+1))\ f(x’)=max(max{ Z(x’)_i:i\ne t }-Z(x’)_t, -K)
minimize∣∣21(tanh(w)+1)−x∣∣22+cf(21(tanh(w)+1))f(x′)=max(max{Z(x′)i:i=t}−Z(x′)t,−K)
f
f
f在式中添加了参数
K
K
K,改参数能够控制误分类发生的置信度。保证找到的对抗样本
x
′
x’
x′能够以较好的置信度被误分为类别
t
t
t。最初我自己看的时候不好理解,下面给出两个式子大家理解一下。
2.1 对于K的理解
先看第一种:
假设现在有
K
=
0.2
K=0.2
K=0.2,且假设此时
m
a
x
{
Z
(
x
′
)
i
:
i
≠
t
}
−
Z
(
x
′
)
t
≤
−
K
max{ Z(x’)_i:i\ne t }-Z(x’)_t \le -K
max{Z(x′)i:i=t}−Z(x′)t≤−K,即
f
(
x
′
)
=
m
a
x
(
m
a
x
{
Z
(
x
′
)
i
:
i
≠
t
}
−
Z
(
x
′
)
t
,
−
K
)
=
−
K
f(x’)=max(max{ Z(x’)_i:i\ne t }-Z(x’)_t, -K)=-K
f(x′)=max(max{Z(x′)i:i=t}−Z(x′)t,−K)=−K,那么式可以变成
m
i
n
i
m
i
z
e
∣
∣
1
2
(
t
a
n
h
(
w
)
1
)
−
x
∣
∣
2
2
c
∗
(
−
0.2
)
f
(
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
minimize∣∣21(tanh(w)+1)−x∣∣22+cf(21(tanh(w)+1))f(x′)=max(max{Z(x′)i:i=t}−Z(x′)t,−K)
f
f
f在式中添加了参数
K
K
K,改参数能够控制误分类发生的置信度。保证找到的对抗样本
x
′
x’
x′能够以较好的置信度被误分为类别
t
t
t。最初我自己看的时候不好理解,下面给出两个式子大家理解一下。
2.1 对于K的理解
先看第一种:
假设现在有
K
=
0.2
K=0.2
K=0.2,且假设此时
m
a
x
{
Z
(
x
′
)
i
:
i
≠
t
}
−
Z
(
x
′
)
t
≤
−
K
max{ Z(x’)_i:i\ne t }-Z(x’)_t \le -K
max{Z(x′)i:i=t}−Z(x′)t≤−K,即
f
(
x
′
)
=
m
a
x
(
m
a
x
{
Z
(
x
′
)
i
:
i
≠
t
}
−
Z
(
x
′
)
t
,
−
K
)
=
−
K
f(x’)=max(max{ Z(x’)_i:i\ne t }-Z(x’)_t, -K)=-K
f(x′)=max(max{Z(x′)i:i=t}−Z(x′)t,−K)=−K,那么式可以变成
m
i
n
i
m
i
z
e
∣
∣
1
2
(
t
a
n
h
(
w
)
1
)
−
x
∣
∣
2
2
c
∗
(
−
0.2
)
f
(
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)
[外链图片转存中…(img-z1qQLFtL-1713313513335)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









