






public interface CLibrary extends Library {
void str_print(String text); // 方法名和动态库接口一致,参数类型需要用Java里的类型表示,执行时会做类型映射,原理介绍章节会有详细解释
}
加载动态链接库,并实现接口方法。
JnaDemo.java
package com.jna.demo;
import com.sun.jna.Library;
import com.sun.jna.Native;
public class JnaDemo {
private CLibrary cLibrary;
public interface CLibrary extends Library {
void str_print(String text);
}
public JnaDemo() {
cLibrary = Native.load("str_print", CLibrary.class);
}
public void str_print(String text)
{
cLibrary.str_print(text);
}
}
对比可以发现,相比于JNI,JNA不再需要指定native关键字,不再需要生成JNI部分C代码,也不再需要显示的做参数类型转化,极大地提高了调用动态库的效率。
### []( )3.2 打包发布
为了做到开箱即用,我们将动态库与对应语言代码打包在一起,并自动准备好对应依赖环境。这样使用方只需要安装对应的库,并引入到工程中,就可以直接开始调用。这里需要解释的是,我们没有将so发布到运行机器上,而是将其和接口代码一并发布至代码仓库,原因是我们所开发的工具代码可能被不同业务、不同背景(非C++)团队使用,不能保证各个业务方团队都使用统一的、标准化的运行环境,无法做到so的统一发布、更新。
#### []( )3.2.1 Python 包发布
Python可以通过setuptools将工具库打包,发布至pypi公共仓库中。具体操作方法如下:
创建目录。
.
├── MANIFEST.in #指定静态依赖
├── setup.py # 发布配置的代码
└── strprint # 工具库的源码目录
├── __init__.py # 工具包的入口
└── libstr_print.so # 依赖的c_wrapper 动态库
编写**init**.py, 将上文代码封装成方法。
-- coding: utf-8 --
import ctypes
import os
import sys
dirname, _ = os.path.split(os.path.abspath(file))
lib = ctypes.cdll.LoadLibrary(dirname + “/libstr_print.so”)
lib.str_print.argtypes = [ctypes.c_char_p]
lib.str_print.restype = None
def str_print(text):
lib.str_print(text)
编写setup.py。
from setuptools import setup, find_packages
setup(
name="strprint",
version="1.0.0",
packages=find_packages(),
include_package_data=True,
description='str print',
author='xxx',
package_data={
'strprint': ['*.so']
},
)
编写MANIFEST.in。
include strprint/libstr_print.so
打包发布。
python setup.py sdist upload
#### []( )3.2.2 Java接口
对于Java接口,将其打包成JAR包,并发布至Maven仓库中。
编写封装接口代码`JnaDemo.java`。
package com.jna.demo;
import com.sun.jna.Library;
import com.sun.jna.Native;
import com.sun.jna.Pointer;
public class JnaDemo {
private CLibrary cLibrary;
public interface CLibrary extends Library {
Pointer create();
void str_print(String text);
}
public static JnaDemo create() {
JnaDemo jnademo = new JnaDemo();
jnademo.cLibrary = Native.load("str_print", CLibrary.class);
//System.out.println("test");
return jnademo;
}
public void print(String text)
{
cLibrary.str_print(text);
}
}
创建resources目录,并将依赖的动态库放到该目录。
通过打包插件,将依赖的库一并打包到JAR包中。
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
### []( )3.3 业务使用
#### []( )3.3.1 Python使用
安装strprint包。
pip install strprint==1.0.0
使用示例:
-- coding: utf-8 --
import sys
from strprint import *
str_print(‘Hello py’)
#### []( )3.3.2 Java使用
pom引入JAR包。
<groupId>com.jna.demo</groupId>
<artifactId>jnademo</artifactId>
<version>1.0</version>
使用示例:
JnaDemo jnademo = new JnaDemo();
jnademo.str_print(“hello jna”);
### []( )3.4 易用性优化
#### []( )3.4.1 Python版本兼容
Python2与Python3版本的问题,是Python开发用户一直诟病的槽点。因为工具面向不同的业务团队,我们没有办法强制要求使用统一的Python版本,但是我们可以通过对工具库做一下简单处理,实现两个版本的兼容。Python版本兼容里,需要注意两方面的问题:
* 语法兼容
* 数据编码
Python代码的封装里,基本不牵扯语法兼容问题,我们的工作主要集中在数据编码问题上。由于Python 3的str类型使用的是unicode编码,而在C中,我们需要的char\* 是utf8编码,因此需要对于传入的字符串做utf8编码处理,对于C语言返回的字符串,做utf8转换成unicode的解码处理。于是对于上例子,我们做了如下改造:
-- coding: utf-8 --
import ctypes
import os
import sys
dirname, _ = os.path.split(os.path.abspath(file))
lib = ctypes.cdll.LoadLibrary(dirname + “/libstr_print.so”)
lib.str_print.argtypes = [ctypes.c_char_p]
lib.str_print.restype = None
def is_python3():
return sys.version_info[0] == 3
def encode_str(input):
if is_python3() and type(input) is str:
return bytes(input, encoding='utf8')
return input
def decode_str(input):
if is_python3() and type(input) is bytes:
return input.decode('utf8')
return input
def str_print(text):
lib.str_print(encode_str(text))
#### []( )3.4.2 依赖管理
在很多情况下,我们调用的动态库,会依赖其它动态库,比如当我们依赖的gcc/g++版本与运行环境上的不一致时,时常会遇到`glibc_X.XX not found`的问题,这时需要我们提供指定版本的`libstdc.so`与`libstdc++.so.6`。
为了实现开箱即用的目标,在依赖并不复杂的情况下,我们会将这些依赖也一并打包到发布包里,随工具包一起提供。对于这些间接依赖,在封装的代码里,并不需要显式的load,因为Python与Java的实现里,加载动态库,最终调用的都是系统函数dlopen。这个函数在加载目标动态库时,会自动的加载它的间接依赖。所以我们所需要做的,就只是将这些依赖放置到dlopen能够查找到路径下。
dlopen查找依赖的顺序如下:
1. 从dlopen调用方ELF(Executable and Linkable Format)的DT\_RPATH所指定的目录下寻找,ELF是so的文件格式,这里的DT\_RPATH是写在动态库文件的,常规手段下,我们无法修改这个部分。
2. 从环境变量LD\_LIBRARY\_PATH所指定的目录下寻找,这是最常用的指定动态库路径的方式。
3. 从dlopen调用方ELF的DT\_RUNPATH所指定的目录下寻找,同样是在so文件中指定的路径。
4. 从/etc/ld.so.cache寻找,需要修改/etc/ld.so.conf文件构建的目标缓存,因为需要root权限,所以在实际生产中,一般很少修改。
5. 从/lib寻找, 系统目录,一般存放系统依赖的动态库。
6. 从/usr/lib寻找,通过root安装的动态库,同样因为需要root权限,生产中,很少使用。
从上述查找顺序中可以看出,对于依赖管理的最好方式,是通过指定`LD_LIBRARY_PATH`变量的方式,使其包含我们的工具包中的动态库资源所在的路径。另外,对于Java程序而言,我们也可以通过指定`java.library.path`运行参数的方式来指定动态库的位置。Java程序会将`java.library.path`与动态库文件名拼接到一起作为绝对路径传递给dlopen,其加载顺序排在上述顺序之前。
最后,在Java中还有一个细节需要注意,我们发布的工具包是以JAR包形式提供,JAR包本质上是一个压缩包,在Java程序中,我们能够直接通过`Native.load()`方法,直接加载位于项目resources目录里的so,这些资源文件打包后,会被放到JAR包中的根目录。
但是dlopen无法加载这个目录。对于这一问题,最好的方案可以参考【2.1.3 生成动态库】一节中的打包方法,将依赖的动态库合成一个so,这样无须做任何环境配置,开箱即用。但是对于诸如`libstdc++.so.6`等无法打包在一个so的中系统库,更为通用的做法是,在服务初始化时将so文件从JAR包中拷贝至本地某个目录,并指定`LD_LIBRARY_PATH`包含该目录。
[]( )4\. 原理介绍
--------------------------------------------------------------------
### []( )4.1 为什么需要一个c\_wrapper
实现方案一节中提到Python/Java不能直接调用C++接口,要先对C++中对外提供的接口用C语言的形式进行封装。这里根本原因在于使用动态库中的接口前,需要根据函数名查找接口在内存中的地址,动态库中函数的寻址通过系统函数dlsym实现,dlsym是严格按照传入的函数名寻址。
在C语言中,函数签名即为代码函数的名称,而在C++语言中,因为需要支持函数重载,可能会有多个同名函数。为了保证签名唯一,C++通过name mangling机制为相同名字不同实现的函数生成不同的签名,生成的签名会是一个像\_\_Z4funcPN4printE这样的字符串,无法被dlsym识别(注:Linux系统下可执行程序或者动态库多是以ELF格式组织二进制数据,其中所有的非静态函数(non-static)以“符号(symbol)”作为唯一标识,用于在链接过程和执行过程中区分不同的函数,并在执行时映射到具体的指令地址,这个“符号”我们通常称之为函数签名)。
为了解决这个问题,我们需要通过extern “C” 指定函数使用C的签名方式进行编译。因此当依赖的动态库是C++库时,需要通过一个c\_wrapper模块作为桥接。而对于依赖库是C语言编译的动态库时,则不需要这个模块,可以直接调用。
### []( )4.2 跨语言调用如何实现参数传递
C/C++函数调用的标准过程如下:
1. 在内存的栈空间中为被调函数分配一个栈帧,用来存放被调函数的形参、局部变量和返回地址。
2. 将实参的值复制给相应的形参变量(可以是指针、引用、值拷贝)。
3. 控制流转移到被调函数的起始位置,并执行。
4. 控制流返回到函数调用点,并将返回值给到调用方,同时栈帧释放。
由以上过程可知,函数调用涉及内存的申请释放、实参到形参的拷贝等,Python/Java这种基于虚拟机运行的程序,在其虚拟机内部也同样遵守上述过程,但涉及到调用非原生语言实现的动态库程序时,调用过程是怎样的呢?
由于Python/Java的调用过程基本一致,我们以Java的调用过程为例来进行解释,对于Python的调用过程不再赘述。
#### []( )4.2.1 内存管理
在Java的世界里,内存由JVM统一进行管理,JVM的内存由栈区、堆区、方法区构成,在较为详细的资料中,还会提到native heap与native stack,其实这个问题,我们不从JVM的角度去看,而是从操作系统层面出发来理解会更为简单直观。以Linux系统下为例,首先JVM名义上是一个虚拟机,但是其本质就是跑在操作系统上的一个进程,因此这个进程的内存会存在如下左图所示划分。而JVM的内存管理实质上是在进程的堆上进行重新划分,自己又“虚拟”出Java世界里的堆栈。如右图所示,native的栈区就是JVM进程的栈区,进程的堆区一部分用于JVM进行管理,剩余的则可以给native方法进行分配使用。
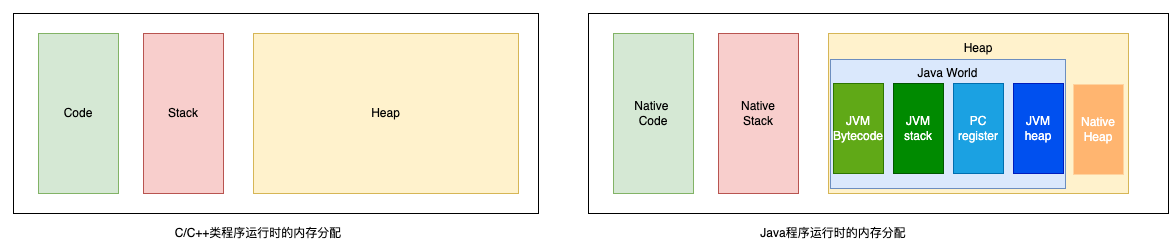
图 3
#### []( )4.2.2 调用过程
前文提到,native方法调用前,需要将其所在的动态库加载到内存中,这个过程是利用Linux的dlopen实现的,JVM会把动态库中的代码片段放到Native Code区域,同时会在JVM Bytecode区域保存一份native方法名与其所在Native Code里的内存地址映射。
一次native方法的调用步骤,大致分为四步:
1. 从JVM Bytecode获取native方法的地址。
2. 准备方法所需的参数。
3. 切换到native栈中,执行native方法。
4. native方法出栈后,切换回JVM方法,JVM将结果拷贝至JVM的栈或堆中。

图 4
由上述步骤可以看出,native方法的调用同样涉及参数的拷贝,并且其拷贝是建立在JVM堆栈和原生堆栈之间。
对于原生数据类型,参数是通过值拷贝方式与native方法地址一起入栈。而对于复杂数据类型,则需要一套协议,将Java中的object映射到C/C++中能识别的数据字节。原因是JVM与C语言中的内存排布差异较大,不能直接内存拷贝,这些差异主要包括:
* 类型长度不同,比如char在Java里为16比特,在C里面却是8个比特。
* JVM与操作系统的字节顺序(Big Endian还是Little Endian)可能不一致。
* JVM的对象中,会包含一些meta信息,而C里的struct则只是基础类型的并列排布,同样Java中没有指针,也需要进行封装和映射。
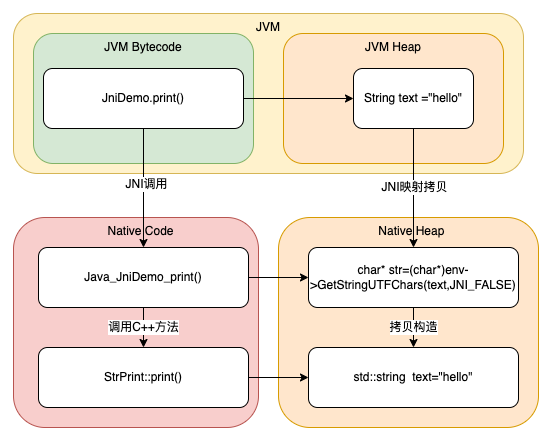
图 5
上图展示了native方法调用过程中参数传递的过程,其中映射拷贝在JNI中是由C/C++链接部分的胶水代码实现,类型的映射定义在jni.h中。
Java基本类型与C基本类型的映射(通过值传递。将Java对象在JVM内存里的值拷贝至栈帧的形参位置):
typedef unsigned char jboolean;
typedef unsigned short jchar;
typedef short jshort;
typedef float jfloat;
typedef double jdouble;
typedef jint jsize;
Java复杂类型与C复杂类型的映射(通过指针传递。首先根据基本类型一一映射,将组装好的新对象的地址拷贝至栈帧的形参位置):
typedef _jobject *jobject;
typedef _jclass *jclass;
typedef _jthrowable *jthrowable;
typedef _jstring *jstring;
typedef _jarray *jarray;
**注**:在Java中,非原生类型均是Object的派生类,多个object的数组本身也是一个object,每个object的类型是一个class,同时class本身也是一个object。
class _jobject {};
class _jclass : public _jobject {};
class _jthrowable : public _jobject {};
class _jarray : public _jobject {};
class _jcharArray : public _jarray {};
class _jobjectArray : public _jarray {};
jni.h 中配套提供了内存拷贝和读取的工具类,比如前面例子中的`GetStringUTFChars`能够将JVM中的字符串中的文本内容,按照utf8编码的格式,拷贝到native heap中,并将char\*指针传递给native方法使用。
整个调用过程,产生的内存拷贝,Java中的对象由JVM的GC进行清理,Native Heap中的对象如果是由 JNI框架分配生成的,如上文JNI示例中的参数,均由框架进行统一释放。而在C/C++中新分配的对象,则需要用户代码在C/C++中手动释放。简而言之,Native Heap中与普通的C/C++进程一致,没有GC机制的存在,并且遵循着谁分配谁释放的内存治理原则。
### []( )4.3 扩展阅读(JNA直接映射)
相比于JNI,JNA使用了其函数调用的基础框架,其中的内存映射部分,由JNA工具库中的工具类自动化的完成类型映射和内存拷贝的大部分工作,从而避免大量胶水代码的编写,使用上更为友好,但相应的这部分工作则产生了一些性能上的损耗。
JNA还额外提供了一种“直接映射”(DirectMapping)的调用方式来弥补这一不足。但是直接映射对于参数有着较为严格的限制,只能传递原生类型、对应数组以及Native引用类型,并且不支持不定参数,方法返回类型只能是原生类型。
直接映射的Java代码中需要增加native关键字,这与JNI的写法一致。
`DirectMapping`示例
import com.sun.jna.*;
public class JnaDemo {
public static native double cos(DoubleByReference x);
static {
Native.register(Platform.C_LIBRARY_NAME);
}
public static void main(String[] args) {
System.out.println(cos(new DoubleByReference(1.0)));
}
}
DoubleByReference即是双精度浮点数的Native引用类型的实现,它的JNA源码定义如下(仅截取相关代码):
//DoubleByReference
public class DoubleByReference extends ByReference {
public DoubleByReference(double value) {
super(8);
setValue(value);
}
}
// ByReference
public abstract class ByReference extends PointerType {
protected ByReference(int dataSize) {
setPointer(new Memory(dataSize));
}
}
Memory类型是Java版的shared\_ptr实现,它通过引用引数的方式,封装了内存分配、引用、释放的相关细节。这种类型的数据内存实际上是分配在native的堆中,Java代码中,只能拿到指向该内存的引用。JNA在构造Memory对象的时候通过调用malloc在堆中分配新内存,并记录指向该内存的指针。
在ByReference的对象释放时,调用free,释放该内存。JNA的源码中ByReference基类的finalize 方法会在GC时调用,此时会去释放对应申请的内存。因此在JNA的实现中,动态库中的分配的内存由动态库的代码管理,JNA框架分配的内存由JNA中的代码显示释放,但是其触发时机,则是靠JVM中的GC机制释放JNA对象时来触发运行。这与前文提到的Native Heap中不存在GC机制,遵循谁分配谁释放的原则是一致的。
@Override
protected void finalize() {
dispose();
}
/** Free the native memory and set peer to zero */
protected synchronized void dispose() {
if (peer == 0) {
// someone called dispose before, the finalizer will call dispose again
return;
}
try {
free(peer);
} finally {
peer = 0;
// no null check here, tracking is only null for SharedMemory
// SharedMemory is overriding the dispose method
reference.unlink();
}
}
### []( )4.4 性能分析
提高运算效率是Native调用中的一个重要目的,但是经过上述分析也不难发现,在一次跨语言本地化的调用过程中,仍然有大量的跨语言工作需要完成,这些过程也需要支出对应的算力。因此并不是所有Native调用,都能提高运算效率。为此我们需要理解语言间的性能差异在哪儿,以及跨语言调用需要耗费多大的算力支出。
语言间的性能差异主要体现在三个方面:
* Python与Java语言都是解释执行类语言,在运行时期,需要先把脚本或字节码翻译成二进制机器指令,再交给CPU进行执行。而C/C++编译执行类语言,则是直接编译为机器指令执行。尽管有JIT等运行时优化机制,但也只能一定程度上缩小这一差距。
* 上层语言有较多操作,本身就是通过跨语言调用的方式由操作系统底层实现,这一部分显然不如直接调用的效率高。
* Python与Java语言的内存管理机制引入了垃圾回收机制,用于简化内存管理,GC工作在运行时,会占用一定的系统开销。这一部分效率差异,通常以运行时毛刺的形态出现,即对平均运行时长影响不明显,但是对个别时刻的运行效率造成较大影响。
而跨语言调用的开销,主要包括三部分:
* 对于JNA这种由动态代理实现的跨语言调用,在调用过程中存在堆栈切换、代理路由等工作。
* 寻址与构造本地方法栈,即将Java中native方法对应到动态库中的函数地址,并构造调用现场的工作。
* 内存映射,尤其存在大量数据从JVM Heap向Native Heap 进行拷贝时,这部分的开销是跨语言调用的主要耗时所在。
我们通过如下实验简单做了一下性能对比,我们分别用C语言、Java、JNI、JNA以及JNA直接映射五种方式,分别进行100万次到1000万次的余弦计算,得到耗时对比。在6核16G机器,我们得到如下结果:
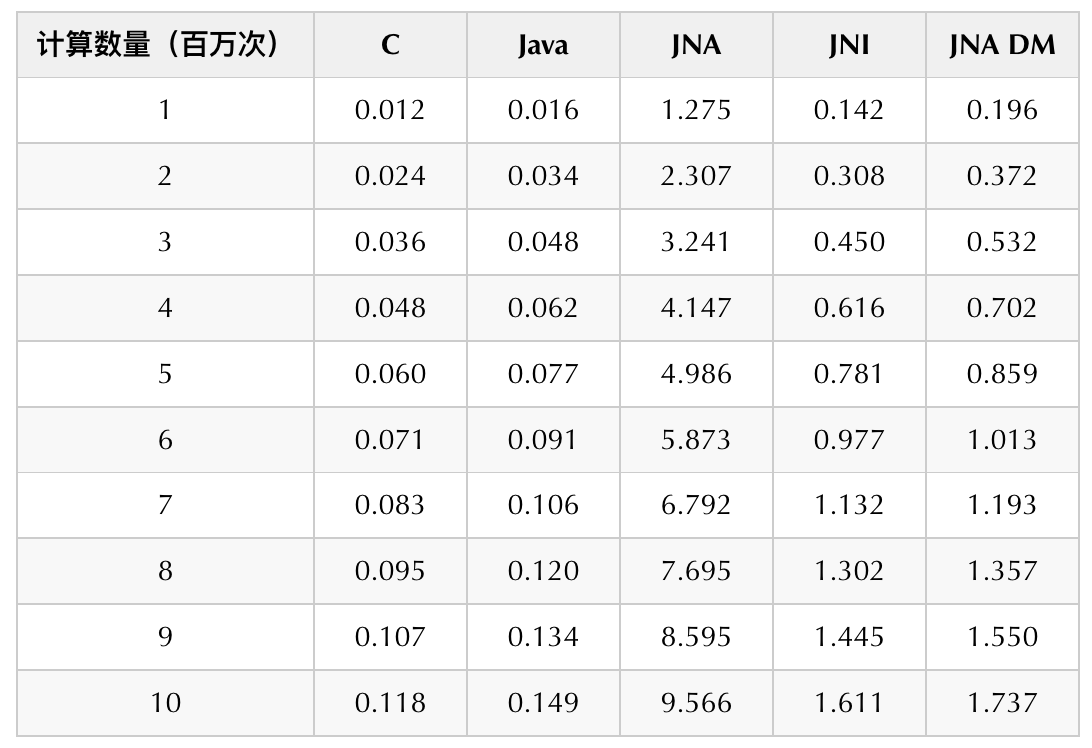
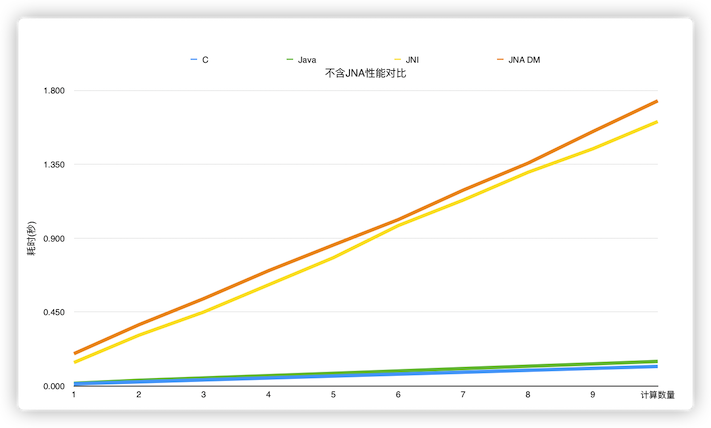
图 6
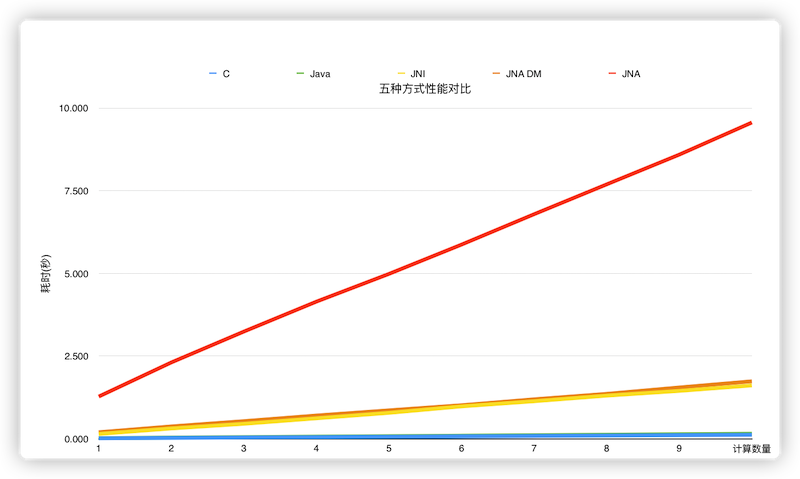
图 7
由实验数据可知,运行效率依次是 `C > Java > JNI > JNA DirectMapping > JNA`。 C语言高于Java的效率,但两者非常接近。JNI与JNA DirectMapping的方式性能基本一致,但是会比原生语言的实现要慢很多。普通模式下的JNA的速度最慢,会比JNI慢5到6倍。
综上所述,跨语言本地化调用,并不总是能够提升计算性能,需要综合计算任务的复杂度和跨语言调用的耗时进行综合权衡。我们目前总结到的适合跨语言调用的场景有:
* **离线数据分析**:离线任务可能会涉及到多种语言开发,且对耗时不敏感,核心点在于多语言下的效果打平,跨语言调用可以节省多语言版本的开发成本。
* **跨语言RPC调用转换为跨语言本地化调用**:对于计算耗时是微秒级以及更小的量级的计算请求,如果通过RPC调用来获得结果,用于网络传输的时间至少是毫秒级,远大于计算开销。在依赖简单的情况下,转化为本地化调用,将大幅缩减单请求的处理时间。
* 对于一些复杂的模型计算,Python/Java跨语言调用C++可以提升计算效率。

最全的Linux教程,Linux从入门到精通
======================
1. **linux从入门到精通(第2版)**
2. **Linux系统移植**
3. **Linux驱动开发入门与实战**
4. **LINUX 系统移植 第2版**
5. **Linux开源网络全栈详解 从DPDK到OpenFlow**

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

**本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。**
> 需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618542503)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









