







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

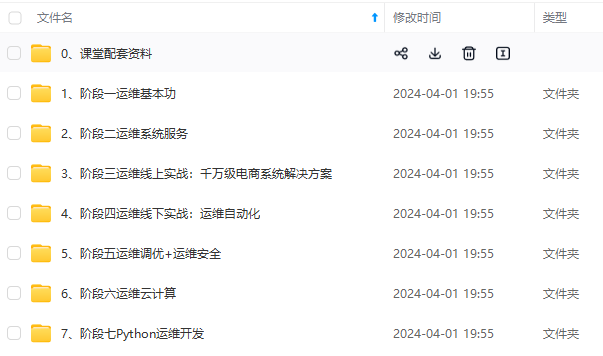
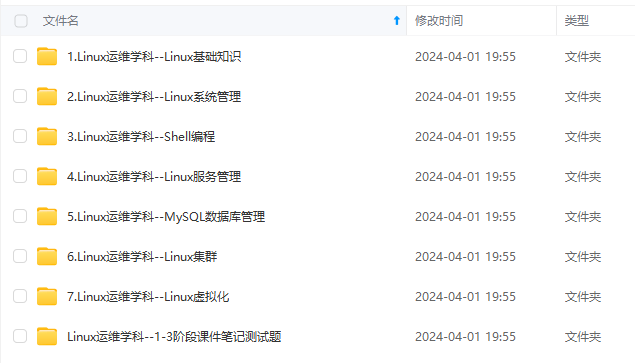
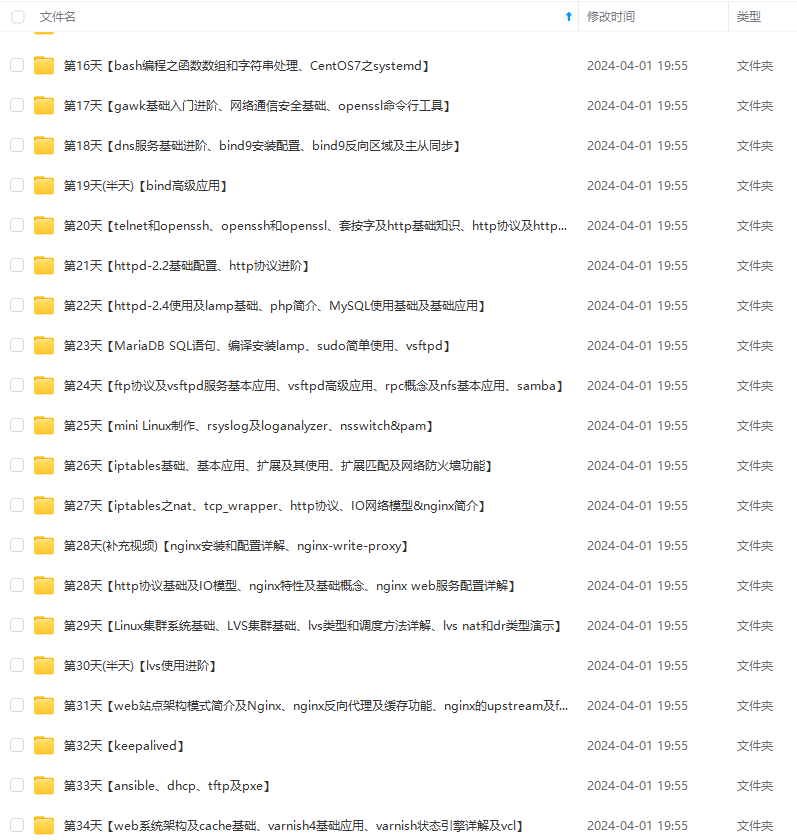
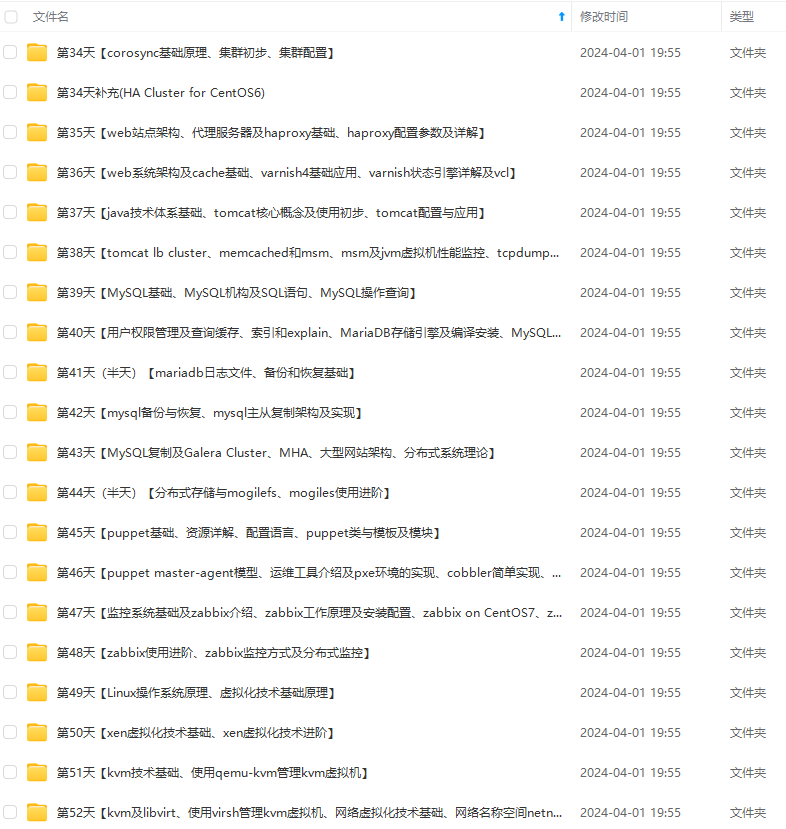
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
1.1.3 树形结构:数据元素之间存在一种一对多多层次关系;
1.1.4 图形结构:数据元素是多对多多关系;
1.2 物理结构:数据的逻辑结构在计算机中的存储形势
1.2.1 顺序存储结构:把数据元素存放在地址连续的存储单元里,其逻辑关系和物理关系一致(数组);
1.2.2 链式存储结构:数据元素存放在任意的存储单元里,这组存储单元可以联系也可不连续;
1.3 抽象数据类型
数据类型:一组性质相同的值的集合及定义在此集合上的一些操作的总称
类型就是用来说明变量或表达式的取值范围和所能进行的操作
抽象:取出事物具有普遍性的本质;
1.3.1 抽象数据类型:指一个数学模型及定义在该模型上的一组操作;
2 算法
是解决特定问题求解步骤等描述,在计算机中表现为指令等有限序列,并且每条指令表示一个或多个操作;
特性:输入输出,
有穷性:执行有限步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成;
确定性:算法的每一步骤具有确定的含义,不会出现二意性;
可行性:算法的每一步都必须可行,每一步都能够通过执行有限次数完成;
正确性,可读性, 健壮性:对不合法的输入做出相关处理;
时间效率高,存储量低;
2.7 算法效率的度量方法
事前分析估算方法:在计算机程序编制前,依据统计方法对算法进行估算;
函数的渐进增长:给定两个函数f(n)和g(n),如果存在一个整数N,使得对于n>N,f(n)和总比g(n)大,那么,我们说f(n)的增长渐进快于g(n)
2.8 算法时间复杂度
:语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n变化的情况并确定T(n)的数量级。算法的时间亮度,记作:T(n)=O(f(n))。它表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度。集中f(n)是问题规模n的某个函数。
O(1) < O(lgn) < O(n) < O(nlgn) < O(n2)< O(n3)<O(2n) < O(n!) < O(nn)
2.12 算法的空间复杂度
S(n)=O(f(n)):n为问题规模,f(n)为语句关于n所占存储空间的函数;
3 线性表
线性表元素个数定义为线性表长度,n=0,为空表;
线性表的顺序存储结构:用一段地址连续的存储单元依次存储线性表的数据元素(一维数组)
3.4.3 数组长度:存储空间的长度; 线性表的长度:线性表中数据元素的个数;
存储器中的每个单元都有自己的编号,称为地址;
Loc(ai)=Loc(a1) +(i-1)*c 时间复杂度:存取时间性能O(1) ---随机存储结构
3.5.4 优点:无须为逻辑关系增加额外存储空间,可以快速存取表中任意位置;
缺点:插入删除需移动大量元素,线性表长度变化难以确定存储空间,存储空间“碎片”
3.6 线性表的链式存储结构
一个节点:数据(数据域)+指针(指针域)
单链表:每个结点只包含一个指针域
头指针:链表中第一个结点的存储位置; 线性链表的最后一个结点指针为空(NULL)
头结点:单链表的第一个结点前设的一个结点;数据域一般无意义(可存储链表长度)
头指针不为空;头结点不一定是链表必须要素
3.8.1 单链表的插入,将s插入到p后: s->next=p->next, p->next=s(赋值顺序不能调换,否则出错)
3.9 单链表整表创建:r->next=p(将新建p结点放在r后面),r=p(p为最后结点赋给r),p->=NULL
3.11 单链表结构优点:插入删除时间O(1),不需要预分配;
确定:查找O(n)
3.12 静态链表:用数组描述的链表;
优点:插入删除只需修改游标;
缺点:表长依然难以确定,失去顺序存储结构的随机性;
3.13 循环链表:将单链表中终端结点的指针端由空指针改为头指针;
3.14 双向链表:在单链表的每个节点中,再设置一个指向其前驱结点的指针域;(空间换时间)
插入时需要保证p->next的赋值在四个操作中最后进行
4 栈
限定仅在表尾进行插入和删除操作的线性表;
后进先出,操作在栈顶进行,后进先出(LIFO结构);
进栈,压栈:插入操作
出栈:删除操作
4.6.1 栈的链式存储结构,链栈;
链栈:空间大小可不确定 ; 顺序栈:空间大小确定
栈的作用:有效解决递归问题
递归:直接调用自己或通过一系列的语句间接调用自己的函数;
迭代:循环结构; 递归:选择结构;
后缀表达式:逆波兰;
中缀表达式:标准四则运算表达式;
4.9.3 中缀转后缀:从左到右遍历中缀表达式每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;若是符号,则判断其与栈顶符号的优先级,是右括号或优先级低于栈顶符号则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止;
4.10 队列:允许在一段进行插入操作,在另一端进行删除操作的线性表;
first in first out(FIFO)
队尾:允许插入; 队头:允许删除;
队列顺序存储不足,删除队头,需要移动这个数组O(n);
front指向队头元素,rear指向队尾元素;
front = rear 空队列
循环队列:头尾相接;设置flag,以区别front = rear时为空还是满;
4.13 队列等链式存储结构
就是线性表的单链表,但只能尾进头出,链队列;
空队列:front和rear指向头结点;
5 串
是由零个或多个组成的有限序列,字符串;
空格串:只包含空格的串; 空串:零个字符串;
模式匹配算法,克努特-莫里斯-普拉斯算法(KMP模式)(没看懂)
http://blog.csdn.net/joylnwang/article/details/6778316
6 树
n(n≥0)个结点的有限集。n=0时称为空树。在任意一颗非空树中:有且仅有一个特定的称为根(Root)的结点;当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2…Tn,其中每一个集合本身又是一颗树,并且称为根的子树(SubTree)。
结点拥有的子树的数称为结点的度(Degree)。度为0度结点称为叶结点(Leaf)或终端结点;度不为0的结点称为非终端结点或分支结点,也称为内部结点。树的度是树内各结点的度的最大值。
结点子树的根称为该结点的孩子(Child),该结点称为孩子的双亲(Parent)。同一个双亲的孩子之间互称兄弟(Sibling)。结点的祖先是从根到该结点所经分支上的所有结点。
结点的层次从根开始定义,根为第一层,根的孩子为第二层。树中结点的最大层次称为树的深度(Deoth)或高度。
如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。森林是棵互不相交的树的集合。
6.5 二叉树(Binary Tree):n(n≥0)个结点的有限集合,该集合或者为空集,或者由一个根结点和两棵互不相交的,分别为根结点的左子树和右子树的二叉树组成。
特点:每个节结点最多两棵子树,即度不大于2,左右子树次序一定;
五种基本形态:空二叉树,只有一个根结点,根结点只有左子树,根结点只有右子树,根结点既有左子树又有右子树;
6.5.2 斜树:所有结点都只有左子树为左斜树,只有右子树为右斜树,这两种统称斜树;
满二叉树:所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上;
完全二叉树:一个有n个结点的二叉树按层序编号,如果编号为i的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树;
满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树;
完全二叉树特点:叶子结点只能出现在最下两层;最下层的叶子一定集中在左部连续;倒数二层若有叶子结点,一定都在右部连续位置;当结点度为1,则该结点只有左孩子;同样结点树的二叉树,完全二叉树的深度最小;
二叉树性质
1:在二叉树的第i层上至多有2^(i-1)个结点(i≧1);
2:深度为k的二叉树至多有(2^k)-1个结点(k≧1);
3:任意一棵二叉树T,如果终端结点数为n0,度为2的结点数为n2,则n0=n2+1;
4:具有n个结点的完全二叉树深度为「㏒2(n) 」+1(「x」表示不大于x的最大整数)
5:如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到第「㏒2(n) 」+1层),对任意一结点有:
如果i=1,则结点i是二叉树的根,无双亲;i≧1,则其双亲是结点「i/2」;
如果2*>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2*i;
如果2i>n,则结点i无右孩子;否则其右孩子是结点2i+1;
6.7 二叉树的存储结构
二叉链表:链表中结点设计一个数据域和两个指针域(表示两个孩子)
6.8 二叉树都遍历:
从根结点出发,按照某种次序依次访问二叉树中所有结点,使得每个节点被访问一次且仅被访问一次;
前序遍历:若二叉树为空,则空操作返回,否则先访问根结点,然后前序遍历左子树,再前序遍历右子树;
中序遍历:若树为空,则空操作返回,否则从根结点开始(并不是先访问根结点),中序遍历根结点左子树,然后访问根结点,最后中序遍历右子树;
后序遍历:若树为空,则空操作返回,否则从左到右先叶子后结点到方式遍历访问左右子树,最后访问根结点;
层序遍历:若树为空,则空操作返回,否则从树第一层,也就是根结点开始访问,从上而下逐层遍历,同一层从左到右顺序访问;
6.8.6 二叉树遍历性质
已知前序遍历序列和中序遍历序列可以唯一确定一棵二叉树;
已知后序遍历序列和中序遍历序列可以唯一确定一棵二叉树;
6.9 二叉树的建立
扩展二叉树:将二叉树的每个结点的空指针引出一个虚结点,其值为一特定值;
6.10 线索二叉树
指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树;
线索化:对二叉树以某种次序遍历使其变为线索二叉树的过程;
6.12 赫夫曼编码
带权路径长度WPL最小的二叉树称作赫夫曼树;
7 图
由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合;
图中数据元素称为顶点;
图结构中不允许没有顶点;
任意两点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以为空;
7.2.1 各种图定义
无向边:顶点V1和Vi之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(Vi Vj)来表示;
如果图中任意两个顶点之间的边都是无向边,则称该图为无向图;
有向边:若顶点从V1到Vi的边有方向,则称这条边有方向,也称为弧(Arc),用有序偶
表示,Vi称为弧尾(Tail),Vj为弧头(Head);
若图中任意两个顶点之间的边都是有向边,则称该图为有向图;如:顶点A到D的有向边,A是弧尾,D是弧头,<A,D>表示弧;
简单图:若不存在顶点到其自身的边且同一条边不重复出现;
无向完全图:在无向图中任意两个顶点都存在边;含有n个顶点的完全图有n*(n-1)/2条边;
有向完全图:有向图中任意两个顶点之间都存在方向互为相反的两天弧,有n*(n-1)条边;
有很少条边或弧度图称为稀疏图,反之称为稠密图;
图的边或弧相关的树叫做权(Weight),带权的图称为网(Network);
假设图G=(V,{E}),图G’=(V’,{E’}),如果V’⊆V且E’⊆E,则称G’为G的子图(Subgraph);
对于无向图G=(V,{E}),如果边(v,v’)∈E,则称顶点v和v’互为邻接点,即v和v’相领接边(v,v’)依附于顶点v和v’,顶点v的度是和v相关联的边的数目,记为TD(v);
边数就是各顶点度数和道一半:e= 0.5* ∑TD(vi) (i=1,2,3…n)
对于有向图G=(V,{E}),以顶点v为头的弧度数目称为v的入度,记为ID(v),以v为尾的弧的数目称为v的出度,记为OD(v);顶点v的度为TD(v)=ID(v)+OD(v);
无向图中从顶点v到顶点v’的路径是一个顶点序列;有向图的路径也是有向的;
路径的长度是路径上的边或弧度数目;
第一个顶点到最后一个顶点相同的路径称为换或回路,序列中不重复出现的路径称为简单路径;
7.2.3 连通图
无向图中,从顶点v到v‘有路径则称为v和v’是连通的;如果对于图中任意两点都是连通的,则称图是连通图;
无向图中的极大连通子图称为连通分量;
连通分量条件:子图/子图连通/连通子图含有极大顶点树/具有极大顶点数的连通子图包含依附于这些顶点的所有边;
在有向图G中,如果每一对v,v‘∈V,v≠v’,从v到v‘和从v’到v都存在路径,则称G是强连通图;有向图中的极大强连通子图称作有向图的强连通分量;
一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边;
如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一棵有向树;
一个有向图的生成森林由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧;
7.4 图的存储结构
7.4.1 邻接矩阵:一个一维数组存储图中顶点信息,一个二维数组存储图中的边或弧度信息;
二维数组就是矩阵形式存储,v[i][j]表示顶点i到j的边或弧;
n个顶点和e条边的无向网图创建时间复杂度O(n*n+n+e);
7.4.2 邻接表:数组与链表相结合的存储方式
顶点右一位数组存储,每个数据元素存储指向第一个领接点的指针,每个顶点的所有领接点构成一个线性表;
有向图的逆邻接表:对每个顶点vi建立一个链接为vi为弧头的表;
7.4.3 十字链表
将邻接表和你邻接表结合起来;
结点存储数据/入边表头指针/出边表头指针;
7.4.4 邻接多重表
7.4.5 边集数组
由两个一维数组构成,一个是存储顶点的信息;另一个存储边的信息,这个边数组每个数据元素由一条边的起点下表,终点下表和权组成;
7.5 图的遍历
从图中某一顶点出发遍历图中其余顶点,且每个顶点仅被访问一次,称为图的遍历;
深度优先遍历:从某顶点v出发,访问该顶点,然后从v的未被访问邻接点出发深度优先遍历图,直到图中所有和v有路径相同的顶点都被访问;
7.5.2 广度优先遍历
与深度优先遍历时间复杂度相同;(类似树的层序遍历)
7.6 最小生成树
构造连通网的最小代价生成树称为最小生成树;
7.6.1 普里姆(Prim)算法
时间复杂度:O(n*n);
7.6.2 克鲁斯卡尔(Kruskal)算法
时间复杂度O(e*log e)
7.7 最短路径
迪杰斯特拉算法:时间复杂度O(n*n);
弗洛伊德算法:时间复杂度O(nnn);
7.8 拓扑排序
AOV网:在一个表示工程的有向图中,用顶点表示活动,用弧表示活动间的优先关系;
拓扑序列:有向图G,满足从顶点vi到vj有一条路径,则在顶点序列中顶点vi必在vj之前;
拓扑排序:对一个有向图构造拓扑序列对过程;
时间复杂度:O(n+e)
AOE网:在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,
7.9 关键路径:
从源点到汇点具有最大路径;
8 查找
根据给定某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录);
查找表:由同一类型的数据元素构成的集合;
关键字:数据元素中某个数据项的值,又称键值;
主关键字:此关键字可以唯一表示一条记录;
数据项对应数据码;
查找:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录);
静态查找表:只做查找操作的查找表;
动态查找表:在查找过程中同时插入不存在的数据元素,或者从查找表中删除已经存在的某个数据元素
8.3 顺序表查找
顺序查找/线性查找:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若相等则查找成功,直到最后一个(或第一个)记录,不等则查找不成功;
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-IDxqwgby-1713610595648)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









