







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

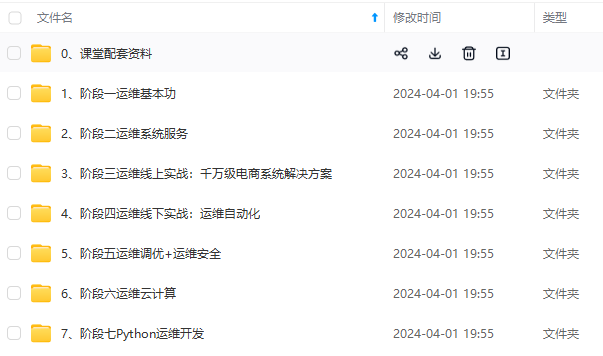
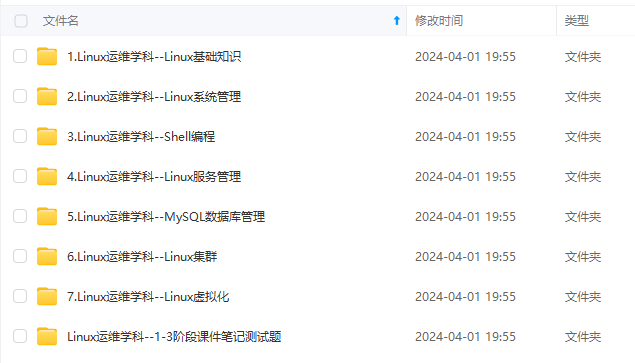
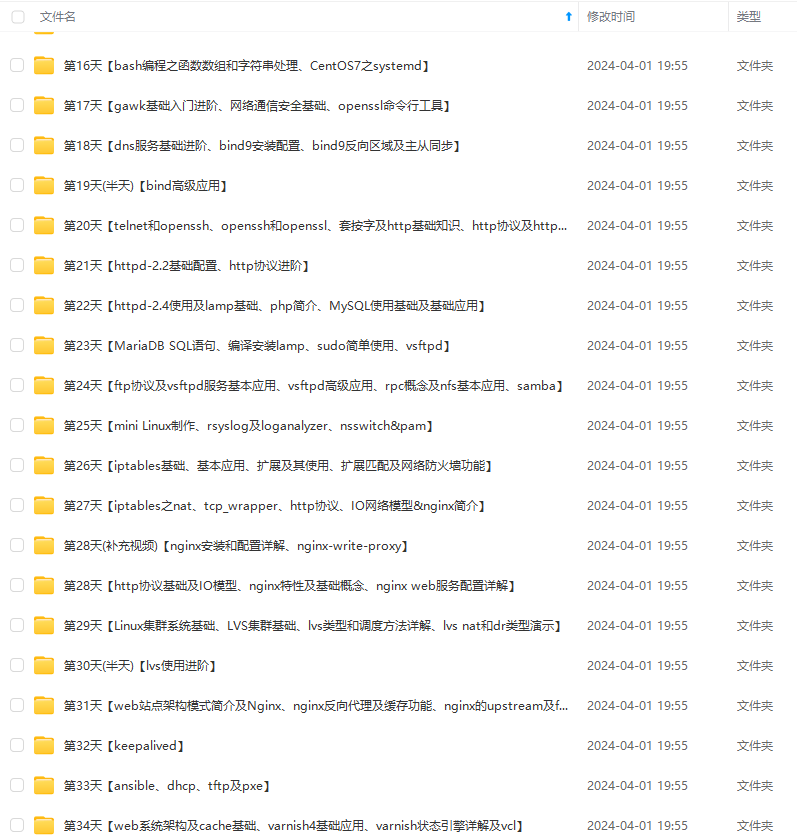
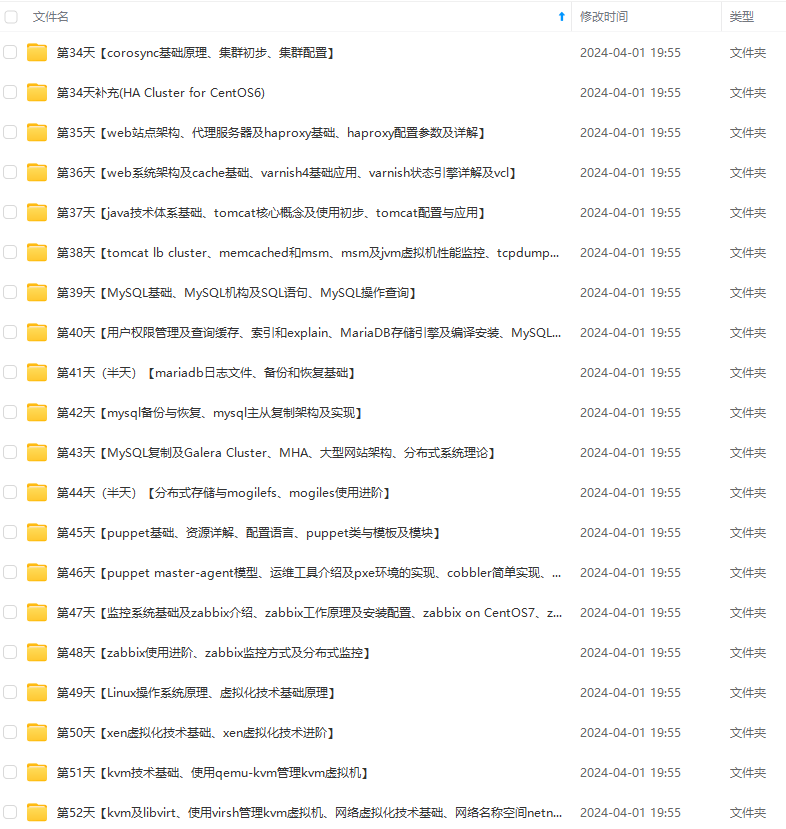
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
一、ResNet
1、ResNet介绍
ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。
通过堆叠卷积层和池化层来增加网络的深度,这样的网络性能是否就能相对浅层网络更优秀?在《Deep Residual Learning for Image Recognition》这篇论文中给出了答案。
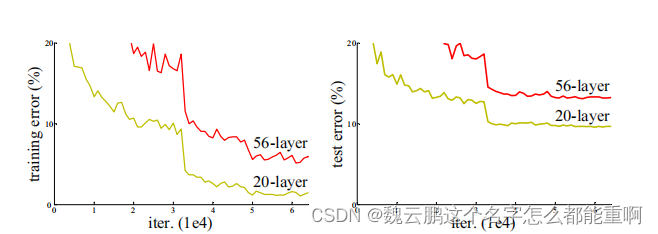
上图截取自原论文,可以看到。56层的网络不管是训练误差还是测试误差都要高于20层的网络 。论文作者给出了两种解释:一是梯度消失或梯度爆炸。随着网络层数的加深,假设层与层之间的误差梯度小于(大于)1,那在反向传播的过程中,梯度会越来越小(大),这就导致了梯度消失(爆炸)从而降低了网络的性能。可以通过数据标准化处理、权重初始化、batch normalization解决。batch normalization将一批数据(一个batch)的每一个通道标准化为均值为0,方差为一的分布。详见博文。二是退化问题,在解决了第一个问题后,仍然无法完全解决上述问题,作者便提出了一个残差结构来解决递归问题。下图是两种残差结构,其中左边的残差结构主要用于层数较浅的网络,而右边的残差结构则主要用于层数较深的网络。
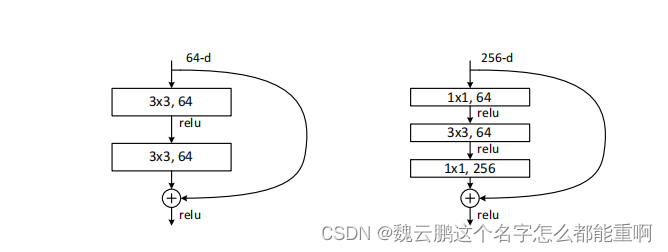
可以看到残差结构将输入与输出进行了相加,这就要求输入与输出具有相同的shape。经计算可得右边的残差结构的参数小于左边。 这也使得它可以应用到更深的网络中。
论文共给出了18层、34层、50层、101层、152层五个层数网络的结构
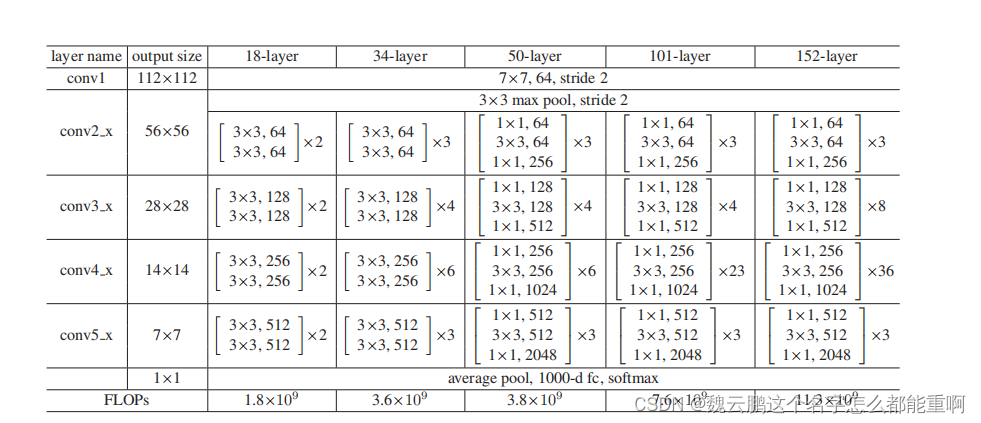
34层网络的详细结构如下。

标注实线的残差结构的输入与输出的shape完全一样可以直接相加。而标注虚线的残差结构输入与输出shape不同。需要通过卷积核的个数进行特征降维或升维、设置特定卷积核的大小、步长来改变特征图的高和宽。
2、用Pytorch搭建Resnet
1.2.1两种残差块:
在18层和34层的网络中,每个残差块的输入通道数与输出通道数相同,而在剩下三个层数的网络中,每个残差块的输出通道数是输入通道数的四倍。两种残差块的定义如下,通过expansion调整输出通道数。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=outchannel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=outchannel, out_channels=outchannel
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(outchannel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=outchannel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
1.2.2搭建网络
原始图像的通道数为3,经过卷积,batch normalization,relu、最大值池化后作为Conv2.x的输入。layer1、layer2、layer3、layer4分别对应Conv2.x,Conv3.x,Conv4.x,Conv5.x._make_layer函数中,第一个参数是上面两个block中的一个,在18层和34层的网络中为basicblock,而在其余三个网络中则为Bottleneck。第二个参数是Conv2.x,Conv3.x,Conv4.x,Conv5.x第一个残差块第一个卷积层中卷积核的个数,第三个参数是Conv2.x,Conv3.x,Conv4.x,Conv5.x残差块的个数,分别为3,4,6,3。以50层网络为例,在搭建layer1即(Conv2.x)时,由于expansion=4,故执行if语句下的命令,定义了一个downsample函数,它实现了将输入的通道数增加为与输出通道数相同,从而可以进行矩阵相加操作,这是layer1的三个残差组中的第一个,将它压入layers列表中,之后将剩余两个残差组压入列表,它们不再需要改变通道数。然后搭建layer2(即Conv3.x),layer3和layer4。他们中的某些组或许需要改变特征图的高宽和通道数。
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
1.2.3使用迁移学习训练网络
迁移学习是在别人已经训练好的模型基础上训练自己的模型,实验表明,它可以更快地达到一个理想的效果。常见的迁移学习方式有以下几种:1、载入权重后训练所有参数。2、载入权重后只训练最后几层参数。3、载入权重后在原网络的基础上再添加一层全连接层,仅训练最后一个全连接层。
在Resnet网络的训练中,可以在官网下载预训练好的模型,由于它的训练数据集是ImageNet,共有1000个类,如果要迁移到自己的实际任务当中,可以修改全连接层的参数数目,在训练最后一层全连接层即可。需要注意在测试时,要对数据进行与训练时相同的预处理。
修改全连接层参数代码如下,假设分类任务共有五类。下述代码重新定义了34层Resnet网络中的全连接层。
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 5)
net.to(device)
二、ResNext网络
1、ResNext改进之处
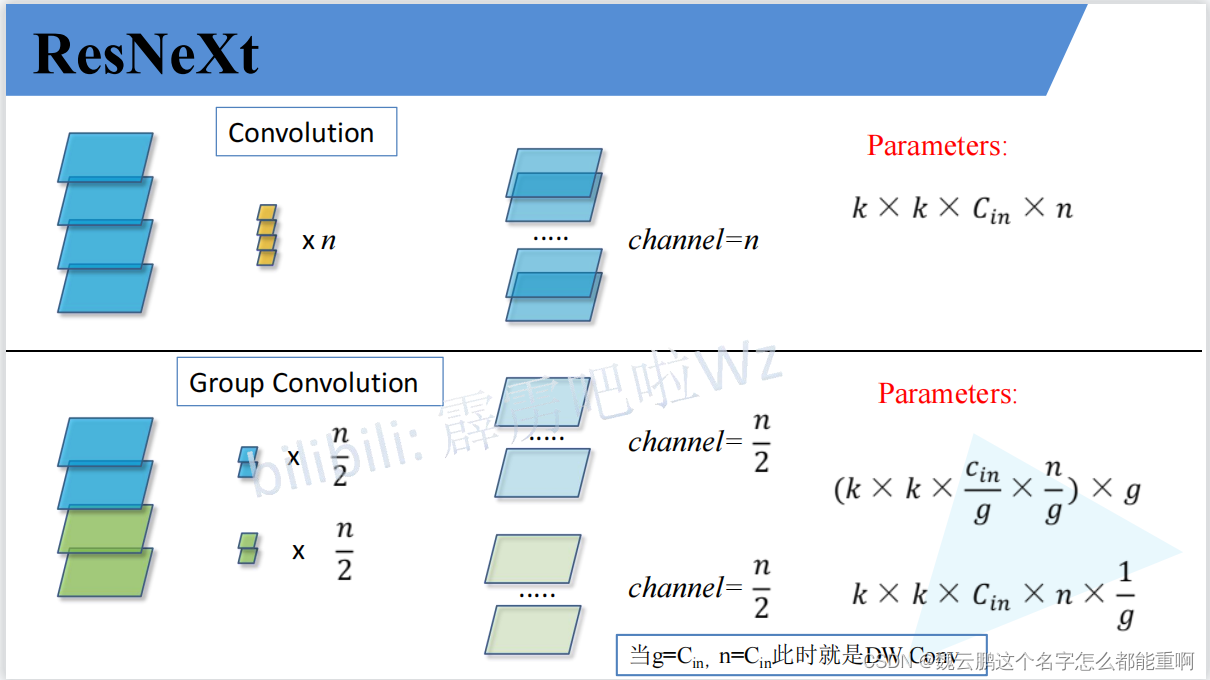
论文将ResNet网络中第二种残差块通过分组卷积的方法进行了改进。分组卷积将输入特征图的通道分为多个group,对每一个group进行卷积,再对结果进行拼接。新的残差块将通道分为32个group。提高了模型准确率。
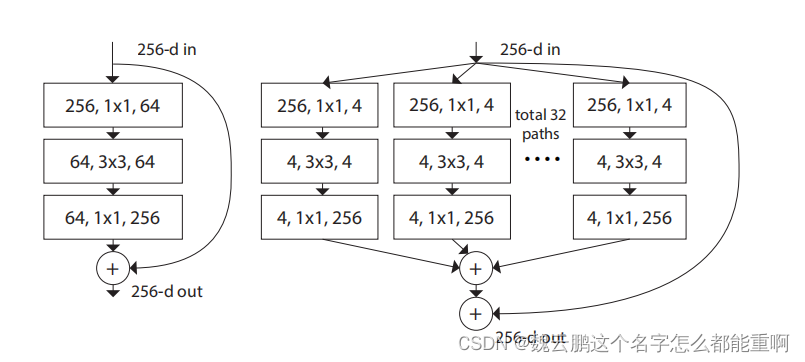
下图是分组卷积的计算量,g表示group的个数。分组卷积有效减少了计算量。
三、基于Lenet网络结构的猫狗图像分类
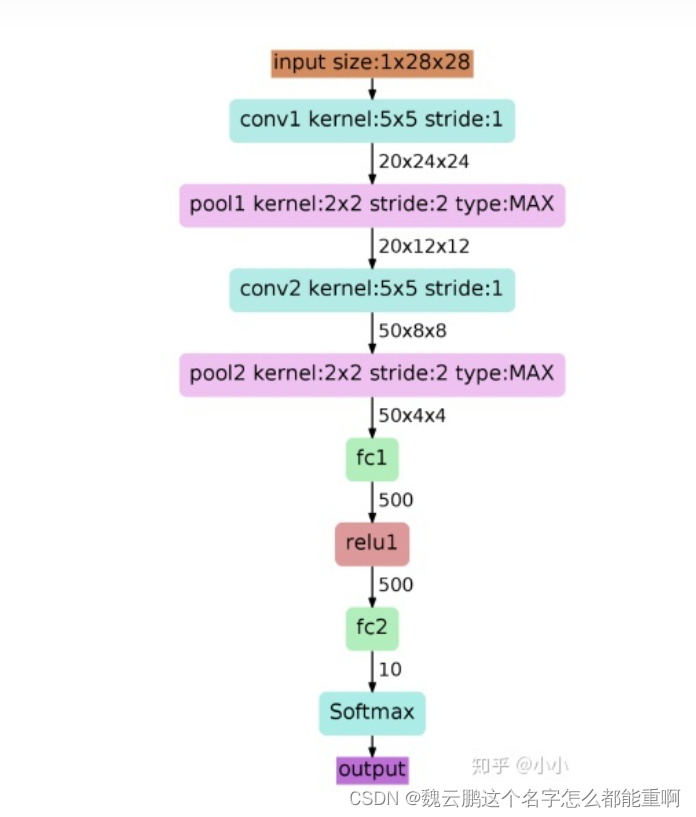
1、Lenet网络结构
Lenet网络结构如下:转自https://zhuanlan.zhihu.com/p/116181964
2、pytorch代码实现
3.2.1数据集加载
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import torch.nn.functional as F
from PIL import Image
import torch.optim as optim
import os
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
train_path = './train/'
test_path = './test/'
def get_data(file_path):
file_lst = os.listdir(file_path) #获得所有文件名称 xxxx.jpg
data_lst = []
for i in range(len(file_lst)):
clas = file_lst[i][:3] #cat和dog在文件名的开头
img_path = os.path.join(file_path,file_lst[i])#将文件名与路径合并得到完整路径,以备读取
if clas == 'cat':
data_lst.append((img_path, 0))
else:
data_lst.append((img_path, 1))
return data_lst
class catdog_set(torch.utils.data.Dataset):
def __init__(self, path, transform):
super(catdog_set).__init__()
self.data_lst = get_data(path)#调用刚才的函数获得数据列表
self.trans = torchvision.transforms.Compose(transform)
def __len__(self):
return len(self.data_lst)
def __getitem__(self,index):
(img,cls) = self.data_lst[index]
image = self.trans(Image.open(img))
label = torch.tensor(cls,dtype=torch.float32)
return image,label
# 将输入图像缩放为 128*128,每一个 batch 中图像数量为128
# 训练时,每一个 epoch 随机打乱图像的顺序,以实现样本多样化
train_loader = torch.utils.data.DataLoader(
catdog_set(train_path, [transforms.Resize((128,128)),transforms.ToTensor()]),
batch_size=128, shuffle=True)
训练集20000张图片(猫10000张,狗10000张)测试集2000张图片数据集下载地址与代码放在同一目录下。get_data函数返回一个列表,是参数文件夹下每一张图片的路径和标签。[(‘./train/cat_0.jpg’, 0), (‘./train/cat_1.jpg’, 0),…(‘./train/dog_9999.jpg’, 1)]
3.2.2网络结构
Lenet的pytorch实现如下,
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.Conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(kernel_size=2)
self.Conv2 = nn.Conv2d(6, 16, 5)
self.pool = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(16*29*29,32)
self.fc2 = nn.Linear(32,2)
def forward(self, x):
x = self.Conv1(x)
print(x.shape)
x = self.pool(x)
print(x.shape)
x = self.pool(self.Conv2(x))
print(x.shape)
x = torch.flatten(x, 1)
print(x.shape)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
随机产生一个指定大小的张量
x = torch.randn(1, 3, 128, 128)
print(x.shape)
net = Net()
y = net(x)
print(y.shape)
输出如下:torch.Size([1, 3, 128, 128])
torch.Size([1, 6, 124, 124])
torch.Size([1, 6, 62, 62])
torch.Size([1, 16, 29, 29])
torch.Size([1, 13456])
torch.Size([1, 2])
说明网络接通,网络的输出是1×2的。
3.2.3网络训练
nn.CrossEntropyLoss()是交叉熵损失函数,用于解决多分类或二分类问题。它的输入是网络最后一层的输出,我们在forward函数中没有写softmax操作,原因在于该损失函数中对输入进行了softmax操作。交叉熵函数
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(30): # 重复多轮训练
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels.long())
loss.backward()
optimizer.step()
print('Epoch: %d loss: %.6f' %(epoch + 1, loss.item()))
print('Finished Training')
训练结果如下:
Epoch: 1 loss: 0.698980
Epoch: 2 loss: 0.482175
Epoch: 3 loss: 0.496106
Epoch: 4 loss: 0.491504
Epoch: 5 loss: 0.340280
Epoch: 6 loss: 0.421208
Epoch: 7 loss: 0.494740
Epoch: 8 loss: 0.276336
Epoch: 9 loss: 0.195770
Epoch: 10 loss: 0.157310
Epoch: 11 loss: 0.052218
Epoch: 12 loss: 0.055619
Epoch: 13 loss: 0.014557
Epoch: 14 loss: 0.010108
Epoch: 15 loss: 0.004856
Epoch: 16 loss: 0.007189
Epoch: 17 loss: 0.005779
Epoch: 18 loss: 0.108815
Epoch: 19 loss: 0.038461
Epoch: 20 loss: 0.057754
Epoch: 21 loss: 0.010165
Epoch: 22 loss: 0.001001
Epoch: 23 loss: 0.003251
Epoch: 24 loss: 0.000153
Epoch: 25 loss: 0.001171
Epoch: 26 loss: 0.000920
Epoch: 27 loss: 0.001027
Epoch: 28 loss: 0.000189
Epoch: 29 loss: 0.000538
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-3AGdcHFv-1713620144293)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2659
2659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









