







示例3: 更换backbone为EfficientNetB0
方法也是和前面介绍的是一样的,完整代码如下:
backbone=torchvision.models.efficientnet_b0(pretrained=False)
#print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"features.5":"0"})
out=backbone(torch.rand(1,3,224,224))
print(out["0"].shape)
backbone.out_channels=112
这里的return_nodes={"features.5":"0"}),对应的key为features.5
参考博客:EfficientNet网络详解
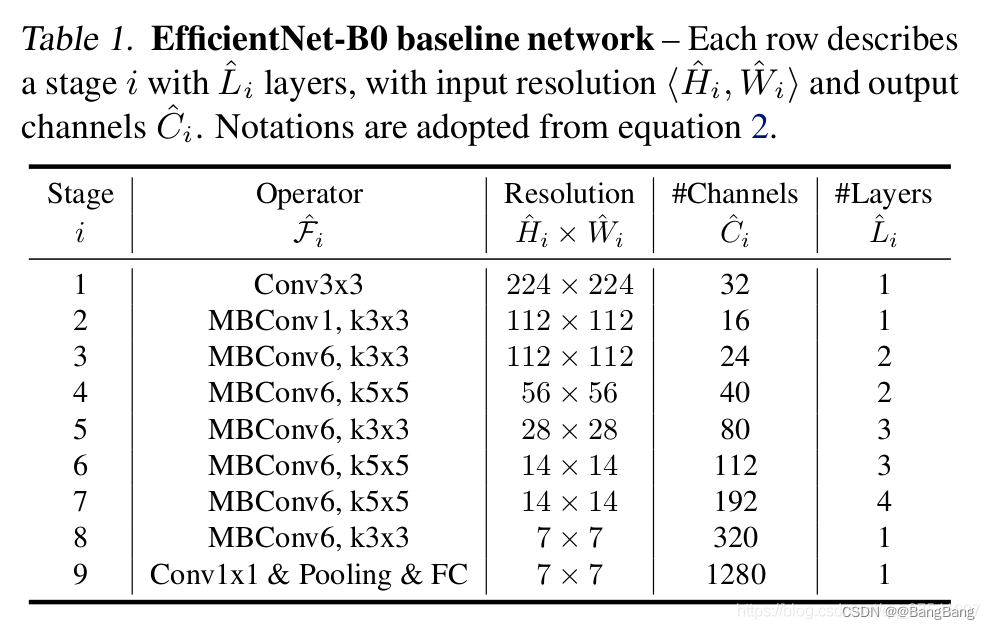
可以看到stage 6输出的特征为14x14,对于stage 7 输入为14x14 ,但是 对应的stride为2输出7x7 下采样32倍.
通过print(backbone)打印网络结构图.
EfficientNet(
(features): Sequential(
(0): ConvNormActivation(
(0): Conv2d(3, 32, kernel\_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(32, 32, kernel\_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(32, 8, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(8, 32, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(2): ConvNormActivation(
(0): Conv2d(32, 16, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0, mode=row)
)
)
(2): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(16, 96, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(96, 96, kernel\_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 4, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(4, 96, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(96, 24, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0125, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(24, 144, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(144, 144, kernel\_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(144, 24, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.025, mode=row)
)
)
(3): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(24, 144, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(144, 144, kernel\_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(144, 40, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.037500000000000006, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(40, 240, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(240, 240, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(240, 40, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.05, mode=row)
)
)
(4): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(40, 240, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(240, 240, kernel\_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(240, 80, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0625, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel\_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 80, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.07500000000000001, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel\_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 80, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.08750000000000001, mode=row)
)
)
(5): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(80, 480, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(480, 480, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(480, 112, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 112, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1125, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 112, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.125, mode=row)
)
)
(6): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(112, 672, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(672, 672, kernel\_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(672, 192, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1375, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.15000000000000002, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1625, mode=row)
)
(3): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel\_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 192, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.17500000000000002, mode=row)
)
)
(7): Sequential(
(0): MBConv(
(block): Sequential(
(0): ConvNormActivation(
(0): Conv2d(192, 1152, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(1): ConvNormActivation(
(0): Conv2d(1152, 1152, kernel\_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel\_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel\_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): ConvNormActivation(
(0): Conv2d(1152, 320, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1875, mode=row)
)
)
(8): ConvNormActivation(
(0): Conv2d(320, 1280, kernel\_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track\_running\_stats=True)
(2): SiLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): Dropout(p=0.2, inplace=True)
(1): Linear(in_features=1280, out\_features=1000, bias=True)
)
)
网络结构stage 6,对于与features模块下,索引为5的子模块,所以对应的节点为"features.5"
构建 Faster RCNN代码讲解
构建backbone
创建好backbone后,接下来讲解如何构建Faster RCNN模型,这里介绍的是不带FPN结构的,也就是说只有一个预测特征层.
实例化AnchorGenerator 和 roi_pooler
实例化AnchorGenerator
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
传入两个参数,一个是sizes,一个是aspect_ratios. size 和aspect_ratios都是元祖类型,并且都是一个元素,因为我们是构建不带FPN的结构,只有一个预测特征层,对应sizes和aspect_ratios元祖都只有一个元素
如果我们这里不去定义AnchorGenerator,在Faster RCNN内部它会自动去构建针对具有FPN结构的AnchorGenerator 以及roi_pooler,因此需要我们事先去构建 AnchorGenerator和roi_pooler
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
这里用的MutiScaleRoIAlign ,这个相对Faster RCNN论文所讲的RoiPooler而言会更加精确一些. 由于这里只有一个key为0的预测特征层,所以在MultiScaleRoIAlign中传入featmap_names=['0']
模型构建
构建模型:
model = FasterRCNN(backbone=backbone,
num\_classes=num_classes,
rpn\_anchor\_generator=anchor_generator,
box\_roi\_pool=roi_pooler)
完整代码如下:
def create\_model(num_classes, load_pretrain_weights=True):
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
# vgg16
backbone=torchvision.models.vgg16_bn(pretrained=False)
print(backbone)
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
#out=backbone(torch.rand(1,3,224,224))
#print(out["0"].shape)
backbone.out_channels=512
# resnet50 backbone
# backbone=torchvision.models.resnet50(pretrained=False)
# #print(backbone)
# backbone=create\_feature\_extractor(backbone,return\_nodes={"layer3":"0"})
# out=backbone(torch.rand(1,3,224,224))
# print(out["0"].shape)
# backbone.out\_channels=1024
# efficientnet\_b0 backbone
# backbone=torchvision.models.efficientnet\_b0(pretrained=False)
# print(backbone)
# backbone=create\_feature\_extractor(backbone,return\_nodes={"features.5":"0"})
# out=backbone(torch.rand(1,3,224,224))
# print(out["0"].shape)
# backbone.out\_channels=112
anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行RoIAlign pooling
output_size=[7, 7], # RoIAlign pooling输出特征矩阵尺寸
sampling_ratio=2) # 采样率
model = FasterRCNN(backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
return model
带FPN结构更换backbone
对应的代码在change_backbone_with_fpn.py文件中,同样我们来看下 create_model这部分代码.
首先在create_model函数中导入两个包
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
我们使用的pytorch版本必须是1.10或以上,torchvision也要按照和pytorch对应的版本
更换backbone
以 mobienet_v3_large backbone 为例
# --- mobilenet\_v3\_large fpn backbone --- #
backbone = torchvision.models.mobilenet_v3_large(pretrained=True)
设置pretrained=True,在创建模型的过程会自动下载在ImageNet预训练好的权重.
构建带fpn结构的backbone,参考目标检测FPN结构的使用,
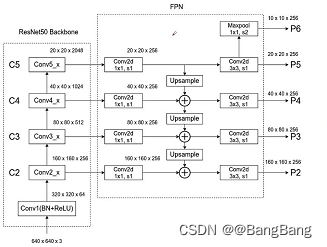
主要难点是要知道我们要获取哪些特征层,并且这些特征层对应的是哪一个模块的输出.
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
创建了一个return_layers字典,字典中每一对键值对对应的就是某一个特征层,和不带FPN的backbone比较类似,只是带FPN结构的backbone需要抽取多个特正层.
- key对应的是抽取特征层,在网络中的节点位置
- value, 默认设置从"0"开始递增
![[MobileNetV3-Large结构图]](https://img-blog.csdnimg.cn/cd50654317834a2db1081eaa2bb27641.png)
这个图是原论文为给MobileNetV3-Large网络的一个结构,假设我这边想获取图中用蓝色框框出来的这3个模块所对应的输出,可以看到对于第一个模块我们下采样了8倍,第二个模块下采样了16倍,第三个模块下采样了32倍. 当然也可以按自己的想法选择合适的模块抽取特征.
如何找到抽取的3个模块的名称呢?主要有两种方式:
- 第一种是通过源码查看
- 第二种通过
print(backbone)进行查看。
通过IDE查看构建MobileNetV3-Large的源代码,我们可以看到官方所实现的features
self.features = nn.Sequential(\*layers)
它所存储的就是上图中对应索引0-16的17个模块,在源码中我们可以知道每搭建一层就会增加一个模块,所以对应的索引就是该模块所在位置.图中抽取的模块,对应的是6,12,16 ,如果不清楚的话也可以打印下backbone进行查看.
设定好return_layers之后,我们还需要指定下我们抽取的这几个特征层,他们对应的channels,通过上图中的表格可以看出这个层对应的channels,分别是[40,112,960], 如果不清楚chanel的话,我随机创建一个tensor,输入backbone,然后通过简单的循环打印抽取特征层名称和shape.
backbone = torchvision.models.mobilenet_v3_large(pretrained=False)
print(backbone)
return_layers = {"features.6": "0", # stride 8
"features.12": "1", # stride 16
"features.16": "2"} # stride 32
# 提供给fpn的每个特征层channel
# in\_channels\_list = [40, 112, 960]
new_backbone = create_feature_extractor(backbone, return_layers)
img = torch.randn(1, 3, 224, 224)
outputs = new_backbone(img)
[print(f"{k} shape: {v.shape}") for k, v in outputs.items()]
打印的信息:
0 shape: torch.Size([1, 40, 28, 28])
1 shape: torch.Size([1, 112, 14, 14])
2 shape: torch.Size([1, 960, 7, 7])
这里的key 0,1,2是我们在retrun_layers中定义的value.其中通道可以看到分别是40,112,960,结合每个特征层输出的高和宽的数值,能够帮助我们分析我们抽取的特征层的下采样倍率是不是对的.
接下来,通过实例化backboneWithFPN来构建带fpn的backbone.
backbone_with_fpn = BackboneWithFPN(new_backbone,
return_layers=return_layers,
in_channels_list=in_channels_list,
out_channels=256,
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)**

为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

ql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-a1o7a3r1-1713074286487)]















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









