







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
bool flag = false;//标记每一趟是否有元素发生交换
for(int j = n - 1; j > i; j --){//从后往前依次枚举
if(a[j] < a[j - 1]){
swap(a[j], a[j - 1]);
flag = true;//发生交换
}
}
if(flag == false) return;//本趟未发生交换,即所有元素都已经有序
}
}
##### 1.9 优化历程
1.朴素写法
//升序排序
void bubble_sort(int a[], int len){//枚举趟, len为数组长度
for(int i = 0; i < len; i ++){//枚举比较元素
for(int j = 0; j < len - i - 1; j ++){
if(a[j] > a[j + 1]){//逆序,交换
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
}
2.一次优化
`设置一个标志位, 用来表示当前第 i 趟是否有交换, 如果有则要进行 i+1 趟, 如果没有, 则说明当前数组`
`已经完成排序, 一旦发现已经排好序, 立即跳出循环, 减少无谓的比较次数.`
//升序排序
void bubble_sort(int a[], int len){
for(int i = 0; i < len; i ++){
bool flag = true;//记录是否发生交换
for(int j = 0; j < len - i - 1; j ++){
if(a[j] > a[j + 1]){
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;//发生交换
}
}
if(flag) break;//某一趟已经完全排好序,直接退出.
}
}
3.二次优化
`利用一个标志位, 记录一下当前第 i 趟所交换的最后一个位置的下标,在进行第 i+1趟的时候, 只需要内循`
`环到标记位置就可以了, 因为后面位置上的元素在上一趟中没有换位, 这一次也不可能会换位置了.`
//升序排序
void bubble_sort(int a[], int len){
int pos;
for(int i = 0; i < len; i ++){
bool flag = true;
for(int j = 0; j < len - i - 1; j ++){
if(a[j] > a[j + 1]){
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
pos = j;//记录交换的位置
flag = false;//发生交换
}
}
len = pos;//记录上一次已比较好的位置,用来更新 len
if(flag) break;
}
}
**总结:**
`一次优化主要是针对在中间的某一次已经完全排好序,无需再进行后续比较的情况,增加一个标记,根据标记判断当`
`前数组是否已经完全排好序,一旦排好序,循环立即退出,减少了后续不必要的比较.`
`二次优化代码主要是在之前的基础上增加一个pos变量,用于记录上一趟发生交换元素最后一个位置,目的是略过之`
`前已经排好序的元素,枚举到未排好序的元素为止.`
##### 1.10 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 20;
int num;
int data[N],idx;
//冒泡排序
void BubbleSort(int a[], int n){
for(int i = 0; i < n - 1; i ++){// 控制趟数, n-1趟
bool flag = false;//标记每一趟是否有元素发生交换
for(int j = n - 1; j > i; j --){//从后往前依次枚举
if(a[j] < a[j - 1]){
swap(a[j], a[j - 1]);
flag = true;//发生交换
}
}
if(flag == false) return;//本趟未发生交换,即所有元素都已经有序
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
BubbleSort(data, idx);
cout << "使用冒泡排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.11 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.12 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
#### 2. [快速排序]( )
##### 2.1 算法思想
在待排序表 `a[0...n-1]`中任取一个元素`pivot`作为枢轴(或基准,通常取首元素),通过一趟排序将待排序表划分为独立的两个部分`a[0...k-1]`和`a[k + 1 ...n-1]`,使得`a[0...k-1]`中的所有元素均小于`pivot`,`a[k + 1...n - 1]`中所有元素均大于等于`pivot`,则`pivot`放在其最终的位置`a[k]`上,这一过程成为一次“划分”,然后分别递归地对两个子表重复上述过程,直到每一部分内只有一个元素或空为止,即所有元素放在了其最终的位置上。
##### 2.2 演示动画

##### 2.3 时间复杂度
1. 最好 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn) `序列均匀分割`
2. 最坏 —
O
(
n
2
)
O(n^2)
O(n2) `序列有序`
3. 平均 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
##### 2.4 空间复杂度
1. 最好 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn) `序列均匀分割`
2. 最坏 —
O
(
n
)
O(n)
O(n) `序列有序`
##### 2.5 稳定性
不稳定
##### 2.6 适用性
仅适用于顺序表
##### 2.7 算法特点
1. 当n较大时,在平均情况下快速排序是所有内部排序方法中速度最快的一种,所以其适合初始记录无序、n较大时的情况
2. 记录非顺次的移动导致排序方法是不稳定的
3. 排序过程中需要定位表的上界和下界,所以仅适合于顺序结构,很难适用于链式结构
##### 2.8 核心代码
//划分函数,选取枢轴元素,且定位数轴元素下标
int Partion(int a[], int low, int high){
int pivot = a[low];//选取第一个元素作为枢轴,当然也可以选最后一个元素作为枢轴
while(low < high){//在low和high之间搜索枢轴位置
while(low < high && pivot <= a[high]) high --;
a[low] = a[high];//比枢轴小的移动到左端
while(low < high && a[low] <= pivot) low ++;
a[high] = a[low];//比枢轴大的移动到右端
}
a[low] = pivot;//将枢轴存放到最终位置
return low;//返回存放枢轴的最终的位置
}
//快速排序
void QuickSort(int a[], int low, int high){
if(low < high){//递归跳出条件
int pivotpos = Partion(a, low, high);//划分
QuickSort(a, low, pivotpos - 1);//划分左子表
QuickSort(a, pivotpos + 1, high);//划分右子表
}
}
##### 2.9 精简代码
void quick_sort(int q[], int l, int r)
{
if(l >= r) return;
int x = q[l + r >> 1], i = l - 1, j = r + 1;
while(i < j)
{
do i++; while(q[i] < x);
do j–; while(q[j] > x);
if(i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}

此乃 y 总毕生锤炼之精华,全网最简,没有之一,不接受反驳,哈哈 ~
##### 2.10 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 20;
int num;
int data[N],idx;
//划分函数,选取枢轴元素,且定位数轴元素下标
int Partion(int a[], int low, int high){
int pivot = a[low];//选取第一个元素作为枢轴
while(low < high){//在low和high之间搜索枢轴位置
while(low < high && pivot <= a[high]) high --;
a[low] = a[high];//比枢轴小的移动到左端
while(low < high && a[low] <= pivot) low ++;
a[high] = a[low];//比枢轴大的移动到右端
}
a[low] = pivot;//将枢轴存放到最终位置
return low;//返回存放枢轴的最终的位置
}
//快速排序
void QuickSort(int a[], int low, int high){
if(low < high){//递归跳出条件
int pivotpos = Partion(a, low, high);//划分
QuickSort(a, low, pivotpos - 1);//划分左子表
QuickSort(a, pivotpos + 1, high);//划分右子表
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
cout << "使用sort函数排序后序列: " << endl;
sort(data, data + idx);
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
QuickSort(data, 0, idx - 1);
cout << "使用快速排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 2.11 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 2.12 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
##### 2.13 经典例题
[快速排序]( )
###### [返回排序算法目录](#jump)
---
### 五、 归并类排序
#### 1. [归并排序]( )
##### 1.1 算法思想
将两个或多个有序序列合并为一个有序序列
###### 注:
1. 二叉树的第 h 层最多有 2h-1 个结点,若树高为 h ,则应该满足 n <= 2h-1 , 即
h
−
1
=
⌈
l
o
g
2
n
⌉
h - 1 = \lceil log{\_2}n\rceil
h−1=⌈log2n⌉, 即趟数 =
⌈
l
o
g
2
n
⌉
\lceil log{\_2}n\rceil
⌈log2n⌉
2. 每趟归并时间复杂度为
O
(
n
)
O(n)
O(n) ,则算法时间复杂度为
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
3. 空间复杂度为
O
(
n
)
O(n)
O(n) ,来自于辅助数组
##### 1.2 演示动画
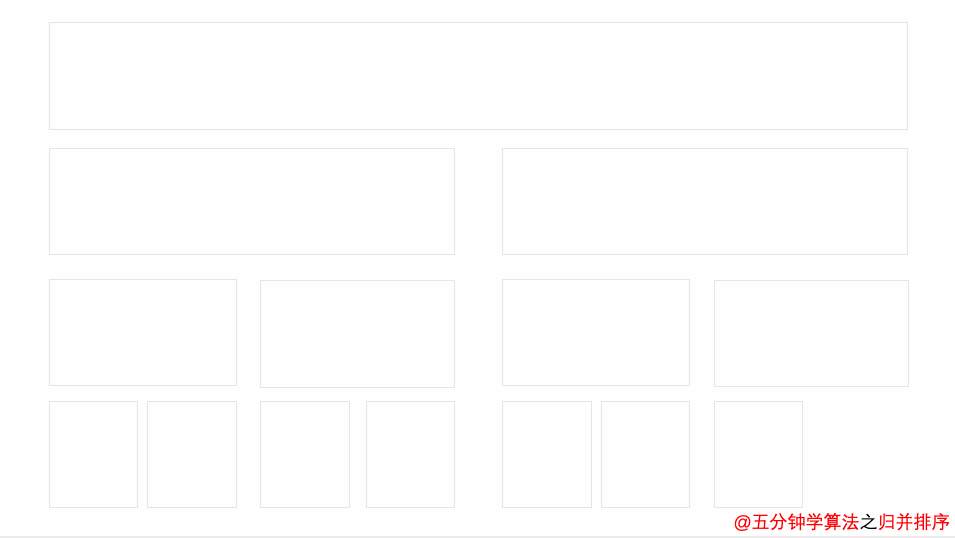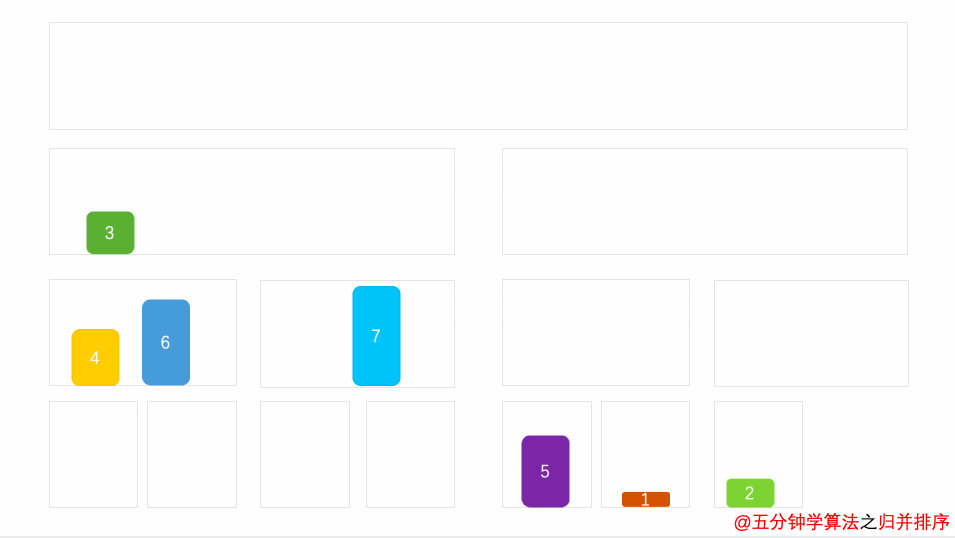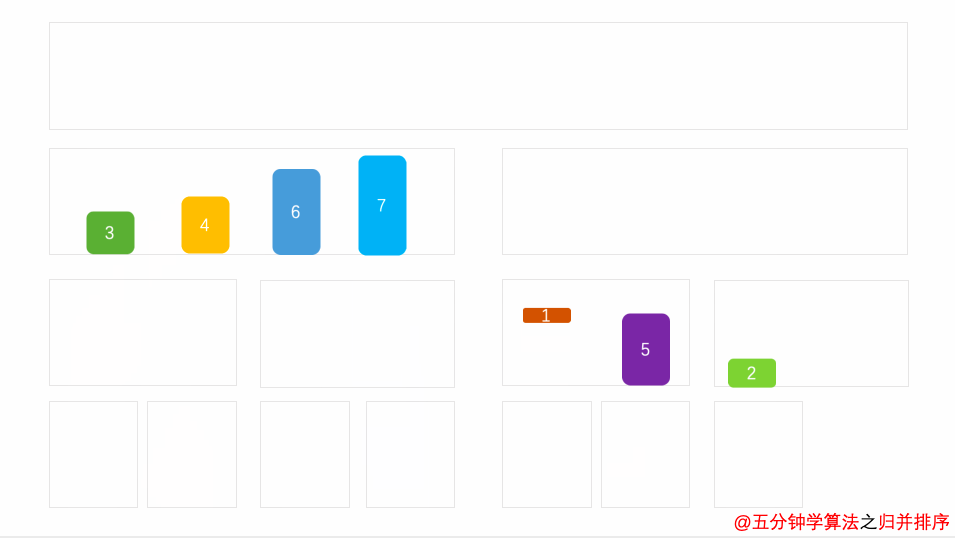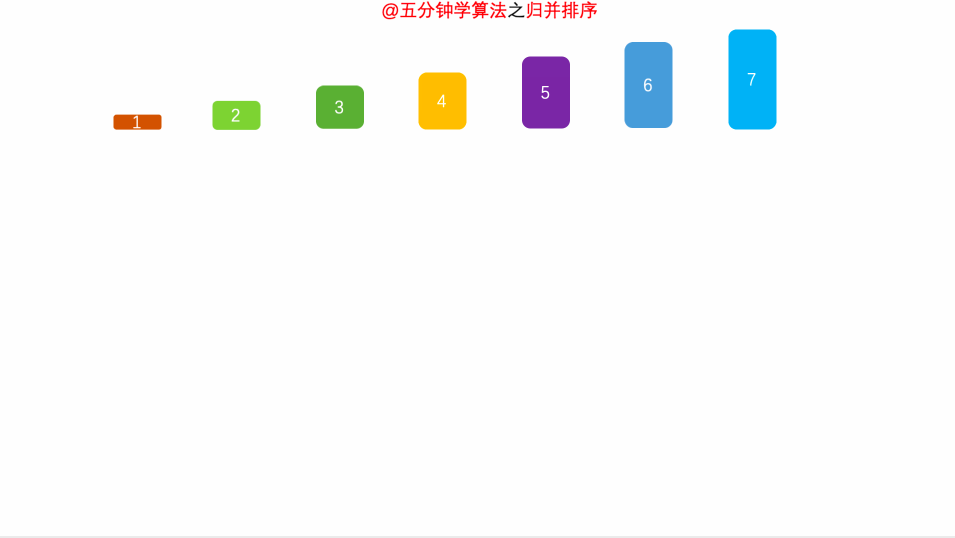
##### 1.3 时间复杂度
1. 最好 —
O
(
n
l
o
g
n
)
O ( nlogn )
O(nlogn)
2. 最坏 —
O
(
n
l
o
g
n
)
O ( nlogn )
O(nlogn)
3. 平均 —
O
(
n
l
o
g
n
)
O ( nlogn )
O(nlogn)
**注:** 归并排序分割子序列与初始序列无关,因此它的最好、最坏、平均时间复杂度均为
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
##### 1.4 空间复杂度
需要一个辅助数组 ----
O
(
n
)
O(n)
O(n)
##### 1.5 稳定性
稳定
##### 1.6 适用性
1. 顺序表
2. 链表
##### 1.7 算法特点
1. 稳定排序
2. 可用于顺序结构,也可用于链式结构。使用链式结构不需要附加的存储空间,但递归实现时仍需要开辟相应的递归工作栈。
3. 一般而言,对于
n
n
n 个元素进行
k
k
k 路归并排序时,排序的趟数
m
m
m 满足
k
m
=
n
k^m = n
km=n, 从而
m
=
l
o
g
k
n
m = log{\_k}n
m=logkn ,又考虑到
m
m
m为整数,所以
m
=
⌈
l
o
g
k
n
⌉
m = \lceil log{\_k}n\rceil
m=⌈logkn⌉
##### 1.8 核心代码
//a[low … mid] 和 a[mid + 1 …high]各自有序,将二者归并
void Merge(int a[], int low, int mid, int high){
int k = low;
int i = low, j = mid + 1;//左、右部分首元素
//将 a数组数据复制到 b数组
for(int i = low; i <= high; i ++) b[i] = a[i];
//将 a[low ... mid] 和 a[mid + 1 ...high]归并
while(i <= mid && j <= high){
if(b[i] < b[j]) a[k ++] = b[i ++];
else a[k ++] = b[j ++];
}
while(i <= mid) a[k ++] = b[i ++];//a数组已经枚举完
while(j <= high) a[k ++] = b[j ++];//b数组已经枚举完
}
// 归并排序
void MergeSort(int a[], int low, int high){//a[low …high]
if(low < high){
int mid = low + high >> 1;//从中间划分
MergeSort(a, low, mid);//对左半部分进行归并排序
MergeSort(a, mid + 1, high);//对左半部分进行归并排序
Merge(a, low, mid, high);//归并
}
}
##### 1.9 极简代码
//归并排序
void merge_sort(int a[], int l, int r){
if(l >= r) return;
int mid = l + r >> 1;
merge_sort(a, l, mid), merge_sort(a, mid + 1, r);//递归划分
int k = 0, i = l, j = mid + 1;
while(i <= mid && j <= r){
if(a[i] <= a[j]) q[k ++] = a[i ++];
else q[k ++] = a[j ++];
}
while(i <= mid) q[k ++] = a[i ++];
while(j <= r) q[k ++] = a[j ++];
for(int i = l, j = 0; i <= r; i ++, j ++) a[i] = q[j];//合并
}

##### 1.10 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 20;
int num;
int data[N],idx, b[N];
//a[low … mid] 和 a[mid + 1 …high]各自有序,将二者归并
void Merge(int a[], int low, int mid, int high){
int k = low;
int i = low, j = mid + 1;//左、右部分首元素
//将 a数组数据复制到 b数组
for(int i = low; i <= high; i ++) b[i] = a[i];
//将 a[low ... mid] 和 a[mid + 1 ...high]归并
while(i <= mid && j <= high){
if(b[i] < b[j]) a[k ++] = b[i ++];
else a[k ++] = b[j ++];
}
while(i <= mid) a[k ++] = b[i ++];//a数组已经枚举完
while(j <= high) a[k ++] = b[j ++];//b数组已经枚举完
}
// 归并排序
void MergeSort(int a[], int low, int high){//a[low …high]
if(low < high){
int mid = low + high >> 1;//从中间划分
MergeSort(a, low, mid);//对左半部分进行归并排序
MergeSort(a, mid + 1, high);//对左半部分进行归并排序
Merge(a, low, mid, high);//归并
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
cout << "使用sort函数排序后序列: " << endl;
sort(data, data + idx ); //sort排序区间左闭右开
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
MergeSort(data, 0, idx - 1);
cout << "使用堆排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.11 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.12 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
### 六、选择类排序
#### 1. [简单选择排序]( )
##### 1.1 算法思想
每一趟在待排元素中选取关键字最小的元素加入到有序序列
###### 注:
`简单选择排序与序列的初始状态无关,仅与序列的元素个数有关`
##### 1.2 演示动画

##### 1.3 时间复杂度
1. 最好 —
O
(
n
2
)
O ( n^2)
O(n2)
2. 最坏 —
O
(
n
2
)
O ( n^2)
O(n2)
3. 平均 —
O
(
n
2
)
O ( n^2)
O(n2)
##### 1.4 空间复杂度
仅用一个临时变量 min —
O
(
1
)
O ( 1)
O(1)
##### 1.5 稳定性
不稳定
##### 1.6 适用性
1. 顺序表
2. 链表
##### 1.7 算法特点
1. 不稳定,但改变策略可以写出不产生“不稳定现象”的选择排序算法
2. 可用于链式存储结构
3. 移动次数较少,当每一记录占用的空间较多时,此方法比直接插入排序快
4. 选择排序的主要操作是关键字的比较,因此,改进此算法应从减少“比较次数”出发考虑
##### 1.8 核心代码
//交换两个元素
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
//选择排序
void SelectSort(int a[], int n){
for(int i = 0; i < n; i ++){
int min = i;//min记录最下元素的下标
for(int j = i; j < n; j ++){
if(a[j] < a[min]) min = j;
}
if(min != i) swap(a[i], a[min]);//交换两个值
}
}
##### 1.9 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 20;
int num;
int data[N],idx;
//交换两个元素
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
//选择排序
void SelectSort(int a[], int n){
for(int i = 0; i < n; i ++){
int min = i;//min记录最下元素的下标
for(int j = i; j < n; j ++){
if(a[j] < a[min]) min = j;
}
if(min != i) swap(a[i], a[min]);//交换两个值
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
cout << "使用sort函数排序后序列: " << endl;
sort(data, data + idx);
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
SelectSort(data, idx);
cout << "使用选择排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.10 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.11 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
#### 2. [堆排序]( )
##### 2.1 算法思想
首先将待排序列构成一个大根堆,然后每一趟将堆顶元素加入到有序子序列(与待排元序列中的最后一个元素交换),并将待排序列再次调整为大根堆(即将小元素 “下坠” )。如此反复执行,最终便能得到一个递增的有序序列。
**注:**
1. 基于 “大根堆” 的堆排序得到的是递增序列
2. 建堆从最后一个非叶子结点开始(叶结点自然不用再调整)
3. 一个结点每“下坠”一层,最多只需要比对关键字两次
4. 若树高为h,某结点在第i层,将这个结点向下调整最多只需要“下坠”h - i层,关键字的比对次数不超过2(h - i)
5. n个结点的完全二叉树,树高
h
=
⌊
l
o
g
2
n
⌋
+
1
h = \lfloor log{\_2}n \rfloor + 1
h=⌊log2n⌋+1
##### 2.2 演示动画

##### 2.3 时间复杂度
1. 最好 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
2. 最坏 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
3. 平均 —
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
注:时间复杂度 =
O
(
n
)
+
O
(
n
l
o
g
2
n
)
=
O
(
n
l
o
g
n
)
O(n) + O(nlog\_2n) = O(nlogn)
O(n)+O(nlog2n)=O(nlogn)
##### 2.4 空间复杂度
O
(
1
)
O(1)
O(1)
##### 2.5 稳定性
不稳定
##### 2.6 适用性
仅适用于顺序表
##### 2.7 算法特点
1. 不稳定排序
2. 只能用于顺序结构,不能用于链式结构
3. 初始建堆所需要的比较次数比较多。因此,当记录数较少时,不宜采用。当记录较多时,较为高效。
##### 2.8 核心代码
//将以k为根结点的树调整为大根堆
void HeadAdjust(int a[], int k, int len){//注:除k结点外其他已经有序
a[0] = a[k];//a[0]暂存子树根节点
for(int i = 2 * k; i <= len; i *= 2){//沿较大子结点筛选
if(i < len && a[i] < a[i + 1]) i ++;//i为较大子结点下标 (i<len表示k有右孩子)
if(a[0] >= a[i]) break;//筛选结束
else{
a[k] = a[i];//递归处理子结点
k = i;
}
}
a[k] = a[0];
}
//建大根堆 时间复杂度—O(n)
void BuildHeap(int a[], int len){//从下往上建堆,从最后一个叶子结点的根节点开始
for(int i = len / 2; i > 0; i --){//处理所有非终端结点
HeadAdjust(a, i , len);
}
}//建堆过程关键字的比较次数不超过4n(定理)
//堆排序的完整逻辑
void HeapSort(int a[], int len){
BuildHeap(a, len);//建堆 O(n)
for(int i = len; i > 1; i --){//从后往前处理 ,共n-1趟交换和调整
swap(a[i], a[1]);//将堆顶元素(最大元素)与堆底元素交换
HeadAdjust(a, 1, i - 1);//把剩余待排元素调整为堆
}
}//每趟时间复杂度不超过o(h) = O(logn),共 n-1趟
##### 2.9 建大根堆思路
把所有非终端结点都检查一遍,是否满足大根堆的要求,如果不满足,则进行调整:
1. 检查当前结点是否满足根 >= 左、右,如果不满足,则将当前结点与更大的一个孩子交换
2. 若元素互换破坏了下一级的堆,则采用相同的方式继续往下调整(小元素不断“下坠”)
//将以k为根结点的树调整为大根堆
void HeadAdjust(int a[], int k, int len){//注:除k结点外其他已经有序
a[0] = a[k];//a[0]暂存子树根节点
for(int i = 2 * k; i <= len; i *= 2){//沿较大子结点筛选
if(i < len && a[i] < a[i + 1]) i ++;//i为较大子结点下标 (i<len表示k有右孩子)
if(a[0] >= a[i]) break;//筛选结束
else{
a[k] = a[i];//递归处理子结点
k = i;
}
}
a[k] = a[0];
}
//建大根堆 时间复杂度—O(n)
void BuildHeap(int a[], int len){//从下往上建堆,从最后一个叶子结点的根节点开始
for(int i = len / 2; i > 0; i --){//处理所有非终端结点
HeadAdjust(a, i , len);
}
}//建堆过程关键字的比较次数不超过4n(定理)
##### 2.10 堆排序思路
每一趟将堆顶元素加入到有序子序列(与待排列中的最后一个元素交换),并将待排序列再次调整为大根堆(小元素不断“下坠”)
//堆排序的完整逻辑 —— 建堆从最后一个非叶子结点开始(叶结点自然不用调整)
void HeapSort(int a[], int len){
BuildHeap(a, len);//建堆 O(n)
for(int i = len; i > 1; i --){//从后往前处理 ,共n-1趟交换和调整
swap(a[i], a[1]);//将堆顶元素(最大元素)与堆底元素交换
HeadAdjust(a, 1, i - 1);//把剩余待排元素调整为堆
}
}//每趟时间复杂度不超过o(h) = O(logn),共 n-1趟
##### 2.11 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 20;
int num;
int data[N],idx;
//将以k为根结点的树调整为大根堆
void HeadAdjust(int a[], int k, int len){//注:除k结点外其他已经有序
a[0] = a[k];//a[0]暂存子树根节点
for(int i = 2 * k; i <= len; i *= 2){//沿较大子结点筛选
if(i < len && a[i] < a[i + 1]) i ++;//i为较大子结点下标 (i<len表示k有右孩子)
if(a[0] >= a[i]) break;//筛选结束
else{
a[k] = a[i];//递归处理子结点
k = i;
}
}
a[k] = a[0];
}
//建大根堆 时间复杂度—O(n)
void BuildHeap(int a[], int len){//从下往上建堆,从最后一个叶子结点的根节点开始
for(int i = len / 2; i > 0; i --){//处理所有非终端结点
HeadAdjust(a, i , len);
}
}//建堆过程关键字的比较次数不超过4n(定理)
//堆排序的完整逻辑
void HeapSort(int a[], int len){
BuildHeap(a, len);//建堆 O(n)
for(int i = len; i > 1; i --){//从后往前处理 ,共n-1趟交换和调整
swap(a[i], a[1]);//将堆顶元素(最大元素)与堆底元素交换
HeadAdjust(a, 1, i - 1);//把剩余待排元素调整为堆
}
}//每趟时间复杂度不超过o(h) = O(logn),共 n-1趟
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[++ idx];
}
cout << "排序前元素序列:" << endl;
for(int i = 1; i <= idx; i ++) cout << data[i] << ' '; cout << endl;
cout << "使用sort函数排序后序列: " << endl;
sort(data + 1, data + 1 + idx);
for(int i = 1; i <= idx; i ++) cout << data[i] << ' '; cout << endl;
HeapSort(data, idx);
cout << "使用堆排序后序列为:" << endl;
for(int i = 1; i <= idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 2.12 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 2.13 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
### 七、非比较类排序
#### 1. [计数排序]( )
##### 1.1 算法思想
首先,扫描一下整个原始序列
a
a
a,获取最小值
m
i
n
min
min 和最大值
m
a
x
max
max,其次开辟一块新的存储空间
b
[
d
]
b [ d ]
b[d],该数组长度为
d
=
m
a
x
−
m
i
n
+
1
d = max - min + 1
d=max−min+1,
b
[
d
]
b[d]
b[d]中存储的是在min ~ max之间的相应数值出现的次数,如:
b
[
5
]
=
2
b[5] = 2
b[5]=2,表示
5
5
5 出现
2
2
2 次,最后根据
b
b
b 数组的统计的元素次数,依次输出各元素。
[inference]( )
##### 1.2 演示动画
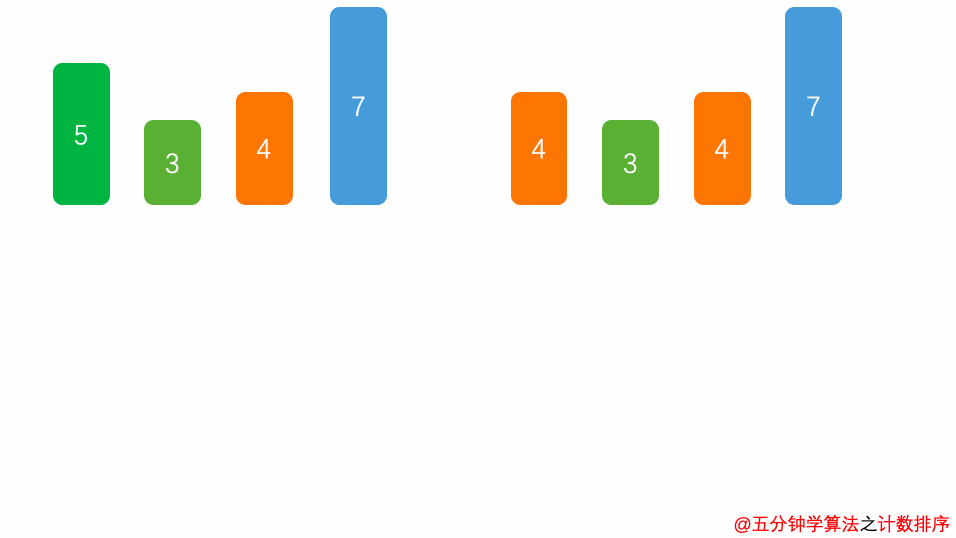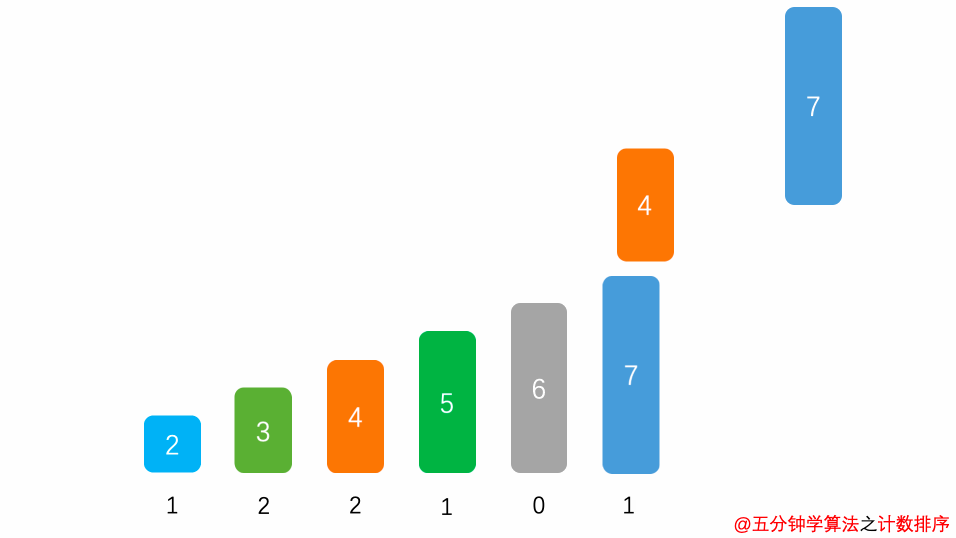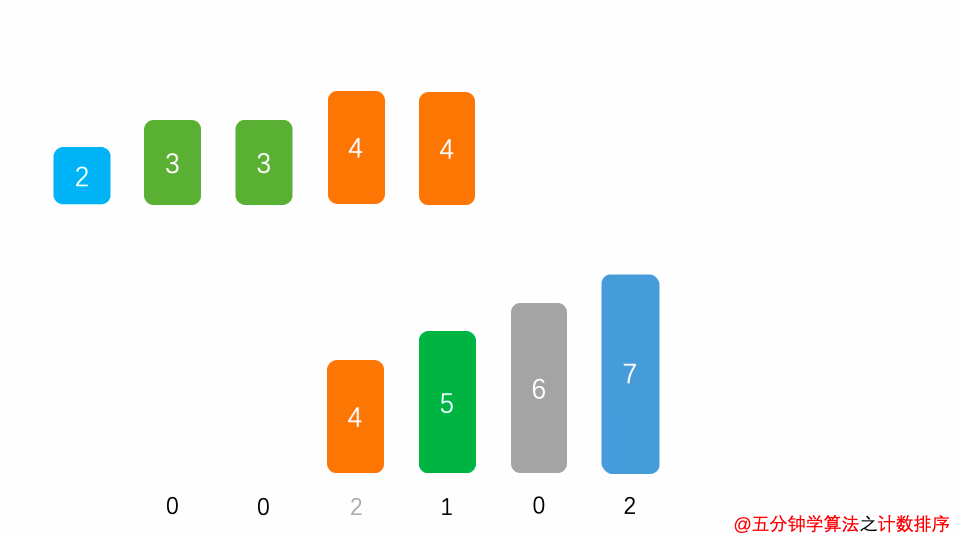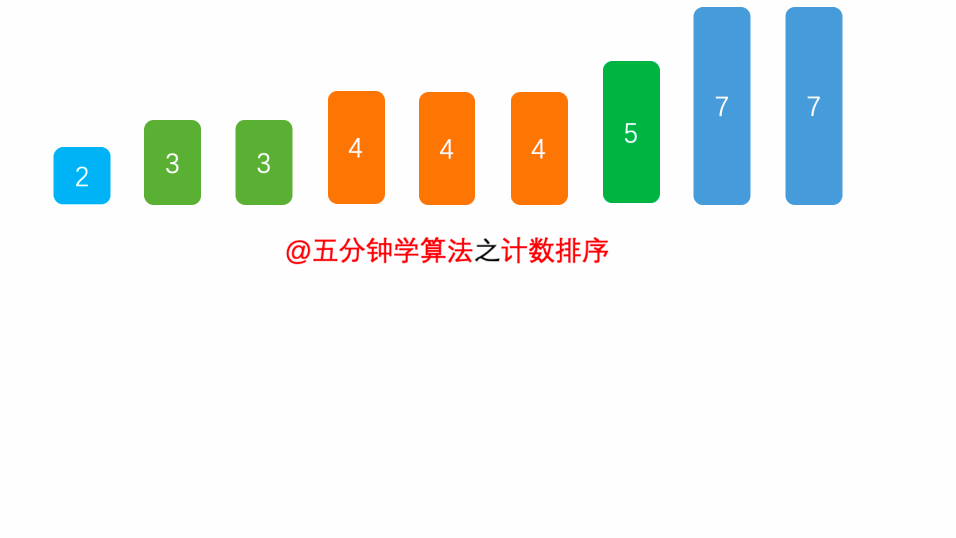
##### 1.3 时间复杂度
1. 最好 —
O
(
n
+
m
)
O(n + m)
O(n+m)
2. 最坏 —
O
(
n
+
m
)
O(n + m)
O(n+m)
3. 平均 —
O
(
n
+
m
)
O(n + m)
O(n+m)
##### 1.4 空间复杂度
O
(
m
)
O(m)
O(m)
##### 1.5 稳定性
稳定、不稳定均可设定
##### 1.6 算法特点
1.当数列最大最小值差距过大时,并不适用计数排序。
比如给定20个随机整数,范围在0到1亿之间,这时候如果使用计数排序,需要创建长度1亿的数组。不但严重浪费空间,而且时间复杂度也随之升高。
2.当数列元素不是整数,并不适用计数排序。
如果数列中的元素都是小数,比如25.213,或是0.00000001这样,则无法创建对应的统计数组。这样显然无法进行计数排序。
##### 1.7 算法适用性
1. 顺序表
2. 链表
##### 1.8 朴素版特点
1. 代码简洁、易实现
2. 由于根据最大值开辟存储空间,可能造成空间的浪费,因此耗费存储空间大
3. 无法保证元素的稳定性
##### 1.9 核心代码
//朴素版
void CountSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//遍历数组求得最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int cnt[maxval + 1] = {0};//根据最大值开辟新数组空间
for(int i = 0; i < n; i ++) cnt[a[i]] ++;//统计原数组中元素出现的次数
for(int i = minval, k = 0; i <= maxval; i ++){
while(cnt[i] != 0){
data[k ++] = i;//将排序后的序列赋给原数组
cnt[i] --;//i出现的次数减1
}
}
}
##### 1.10 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 200;//注意数组越界问题,开大点
int num;
int data[N],idx;
//朴素版
void CountSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//遍历数组求得最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int cnt[maxval + 1] = {0};//根据最大值开辟新数组空间
for(int i = 0; i < n; i ++) cnt[a[i]] ++;//统计原数组中元素出现的次数
for(int i = minval, k = 0; i <= maxval; i ++){
while(cnt[i] != 0){
data[k ++] = i;//将排序后的序列赋给原数组
cnt[i] --;//i出现的次数减1
}
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
CountSort(data, idx);
cout << "使用计数排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.11 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.12 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
---
##### 1.13 一次优化特点
1. 相比于朴素版, 空间复杂度大大降低
2. 不能保证稳定性
##### 1.14 核心代码
//一次优化
void CountSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//遍历数组求得最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int d = maxval - minval + 1;// 计数数组的实际长度
int cnt[d] = {0};//根据最大值开辟新数组空间
//统计原数组中元素出现的次数
for(int i = 0; i < n; i ++) cnt[a[i] - minval] ++;//将元素映射到a[0...d-1]
for(int i = 0, k = 0; i <= maxval - minval; i ++){
while(cnt[i] != 0){
data[k ++] = i + minval;//将排序后的序列赋给原数组
cnt[i] --;//i出现的次数减1
}
}
}
##### 1.15 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 200;//注意数组越界问题,开大点
int num;
int data[N],idx;
//一次优化
void CountSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//遍历数组求得最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int d = maxval - minval + 1;// 计数数组的实际长度
int cnt[d] = {0};//根据最大值开辟新数组空间
//统计原数组中元素出现的次数
for(int i = 0; i < n; i ++) cnt[a[i] - minval] ++;//将元素映射到a[0...d-1]
for(int i = 0, k = 0; i <= maxval - minval; i ++){
while(cnt[i] != 0){
data[k ++] = i + minval;//将排序后的序列赋给原数组
cnt[i] --;//i出现的次数减1
}
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
CountSort(data, idx);
cout << "使用计数排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.16 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.17 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
---
##### 1.18 二次优化特点
1. 相比于朴素版, 空间复杂度大大降低
2. 可以保证稳定性,该排序稳定
##### 1.19 核心代码
//二次优化
void CountSort(int a[], int n){
//遍历数组求得最大值和最小值
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int d = maxval - minval + 1;// 计数数组的实际长度
int cnt[d] = {0};//根据最大值开辟新数组空间
//统计原数组中元素出现的次数
for(int i = 0; i < n; i ++) cnt[a[i] - minval] ++;//将元素映射到a[0...d-1]
int sum = 0;
for(int i = 0; i < d; i ++){//本质为前缀和数组,用于求位次
sum += cnt[i];//此处的cnt既为元素又为之前的元素和,即cnt[i] = cnt[i] + cnt[i - 1]
cnt[i] = sum;// 比如, cnt[5] = 3,表示分数95, 排名第 3
}
int sortArray[d];//sortArray[]存元素真实序列
for(int i = n - 1; i >= 0; i --){//将原数组元素从后往前遍历
sortArray[cnt[a[i] - minval] - 1] = a[i];
cnt[a[i] - minval] --;
}
//将排序后的序列赋给原数组
for(int i = 0, k = 0; i < d; i ++){
data[k ++] = sortArray[i];
}
}
##### 1.20 完整代码
#include
#include
#include
#include
#include
using namespace std;
const int N = 200;//注意数组越界问题,开大点
int num;
int data[N],idx;
//二次优化
void CountSort(int a[], int n){
//遍历数组求得最大值和最小值
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int d = maxval - minval + 1;// 计数数组的实际长度
int cnt[d] = {0};//根据最大值开辟新数组空间
//统计原数组中元素出现的次数
for(int i = 0; i < n; i ++) cnt[a[i] - minval] ++;//将元素映射到a[0...d-1]
int sum = 0;
for(int i = 0; i < d; i ++){//本质为前缀和数组,用于求位次
sum += cnt[i];//此处的cnt既为元素又为之前的元素和,即cnt[i] = cnt[i] + cnt[i - 1]
cnt[i] = sum;// 比如, cnt[5] = 3,表示分数95, 排名第 3
}
int sortArray[d];//sortArray[]存元素真实序列
for(int i = n - 1; i >= 0; i --){//将原数组元素从后往前遍历
sortArray[cnt[a[i] - minval] - 1] = a[i];
cnt[a[i] - minval] --;
}
//将排序后的序列赋给原数组
for(int i = 0, k = 0; i < d; i ++){
data[k ++] = sortArray[i];
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
CountSort(data, idx);
cout << "使用计数排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 1.21 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 1.22 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
#### 2. [桶排序]( )
---
##### 2.1 算法思想
首先, 遍历原始序列确定最大值
m
a
x
v
a
l
maxval
maxval 和最小值
m
i
n
v
a
l
minval
minval,并确定桶的个数
n
n
n; 然后,将待排序集合中处于同一个值域的元素存入同一个桶中,在桶内使用各种现有的算法进行排序; 最后按照从小到大的顺序依次收集桶中的每一个元素, 即为最终结果。
[inference]( )
[inference]( )
##### 2.2 演示动画

##### 2.3 时间复杂度
1. 最好 —
O
(
n
+
k
)
O(n + k)
O(n+k)
2. 最坏 —
O
(
n
2
)
O(n^2)
O(n2)
3. 平均 —
O
(
n
+
k
)
O(n + k)
O(n+k)
**注:**
其
中
k
=
n
l
o
g
(
n
/
m
)
其中 k = nlog(n / m)
其中k=nlog(n/m)
##### 2.4 空间复杂度
O
(
n
+
k
)
O(n + k)
O(n+k)
**注:**
其
中
k
=
n
l
o
g
(
n
/
m
)
其中 k = nlog(n / m)
其中k=nlog(n/m)
##### 2.5 稳定性
稳定
##### 2.6 算法特点
1. 桶排序是一种用空间换取时间的排序
2. 桶排序并非像常规排序那样没有限制,桶排序有相当的限制。因为桶的个数和大小都是我们人为设置的。而每个桶又要避免空桶的情况。所以我们在使用桶排序的时候即需要对待排序数列要求偏均匀,又要要求桶的设计兼顾效率和空间。
3. 数要相对均匀分布,桶的个数也要合理设计。在设计桶排序时,需要知道输入数据的上界和下界,根据数据的分布情况考虑是否用桶排序,当然如果能用好桶排序,效率还是很高的!
##### 2.7 算法适用性
1. 顺序表
2. 链表
##### 2.8 核心代码
//桶排序
void BucketSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//寻找原序列数组元素的最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int bnum = 10;//桶中元素个数
int m = (maxval - minval) / bnum + 1;//桶的个数
vector< vector<int> > bucket(m);
//收集,将元素入相应的桶中. 减偏移量是为了将元素映射到更小的区间内,省内存
for(int i = 0; i < n; i ++) bucket[(a[i] - minval) / bnum].push_back(a[i]);
//将桶内元素排序
for(int i = 0; i < m; i ++) sort(bucket.begin(), bucket.end());
//收集, 将各个桶中的元素收集到一起
for(int i = 0, k = 0; i < m; i ++){
for(int j = 0; j < bucket[i].size(); j ++){
data[k ++] = bucket[i][j];
}
}
}
##### 2.9 完整代码
#include
#include
#include
#include
#include
#include
using namespace std;
const int N = 200;
int data[N], num, idx;
//桶排序
void BucketSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//寻找原序列数组元素的最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int bnum = 10;//桶中元素个数
int m = (maxval - minval) / bnum + 1;//桶的个数
vector< vector<int> > bucket(m);
//收集,将元素入相应的桶中. 减偏移量是为了将元素映射到更小的区间内,省内存
for(int i = 0; i < n; i ++) bucket[(a[i] - minval) / bnum].push_back(a[i]);
//将桶内元素排序
for(int i = 0; i < m; i ++) sort(bucket.begin(), bucket.end());
//收集, 将各个桶中的元素收集到一起
for(int i = 0, k = 0; i < m; i ++){
for(int j = 0; j < bucket[i].size(); j ++){
data[k ++] = bucket[i][j];
}
}
}
int main(){
//打开文件
ifstream infile;
infile.open(“D:\学习\数据结构\第8章排序\in.txt”, ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
BucketSort(data, idx);
cout << "使用桶排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
##### 2.10 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
##### 2.11 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
###### [返回排序算法目录](#jump)
---
#### 3. [基数排序]( )
---
##### 3.1 算法思想
将整个关键字拆分为d位(或“组”), 按照各个关键字权重递增的次序(如:个、十、百), 做
d
d
d 趟“分配”和“收集”, 若当前处理的关键字位可能取得
r
r
r 个值,则需要建立
r
r
r 个队列,顺序扫描各个元素, 根据当前处理的关键字位, 将元素插入到相应的队列, 把各个队列中的结点,依次出队并连接。
[inference]( )
[inference]( )
##### 3.2 演示动画

##### 3.3 时间复杂度
1. 最好 —
O
(
d
(
n
+
r
)
)
O(d(n + r))
O(d(n+r))
2. 最坏 —
O
(
d
(
n
+
r
)
)
O(d(n + r))
O(d(n+r))
3. 平均 —
O
(
d
(
n
+
r
)
)
O(d(n + r))
O(d(n+r))
**注:**
1. 以
r
r
r 为 基数, 例如:十进制
r
=
10
r = 10
r=10
2. n
n
n 表示有
n
n
### 最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
### 资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

**如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
using namespace std;
const int N = 200;
int data[N], num, idx;
//桶排序
void BucketSort(int a[], int n){
int minval = a[0], maxval = a[0];
for(int i = 0; i < n; i ++){//寻找原序列数组元素的最大值和最小值
minval = min(minval, a[i]);
maxval = max(maxval, a[i]);
}
int bnum = 10;//桶中元素个数
int m = (maxval - minval) / bnum + 1;//桶的个数
vector< vector<int> > bucket(m);
//收集,将元素入相应的桶中. 减偏移量是为了将元素映射到更小的区间内,省内存
for(int i = 0; i < n; i ++) bucket[(a[i] - minval) / bnum].push_back(a[i]);
//将桶内元素排序
for(int i = 0; i < m; i ++) sort(bucket.begin(), bucket.end());
//收集, 将各个桶中的元素收集到一起
for(int i = 0, k = 0; i < m; i ++){
for(int j = 0; j < bucket[i].size(); j ++){
data[k ++] = bucket[i][j];
}
}
}
int main(){
//打开文件
ifstream infile;
infile.open("D:\\学习\\数据结构\\第8章排序\\in.txt", ios::in);
//写文件
ofstream outfile;
outfile.open("D:\\学习\\数据结构\\第8章排序\\out.txt", ios::out);
if(!infile.is_open()){//判断文件打开是否成功
cout << "file open failure!" << endl;
}
infile >> num;//读取元素个数
while(num --){//将文件中的元素复制到data[1...n] 数组中
infile >> data[idx ++];
}
cout << "排序前元素序列:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
//cout << "使用sort函数排序后序列: " << endl;
//sort(data, data + idx);
//for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
BucketSort(data, idx);
cout << "使用桶排序后序列为:" << endl;
for(int i = 0; i < idx; i ++) cout << data[i] << ' '; cout << endl;
num = idx, idx = 0, outfile << num << endl;//写入数据数num以及在行末写入\n
while(num --){
outfile << data[++ idx] << ' ';//将排序后的数据写到文件中
}
outfile << endl;//向文件末尾写入\n结束符
//关闭文件
infile.close();
outfile.close();
return 0;
}
2.10 输入数据(in.txt)
10
13 69 86 99 59 23 64 32 86 72
2.11 输出数据(out.txt)
10
13 23 32 59 64 69 72 86 86 99
返回排序算法目录
3. 基数排序
3.1 算法思想
将整个关键字拆分为d位(或“组”), 按照各个关键字权重递增的次序(如:个、十、百), 做
d
d
d 趟“分配”和“收集”, 若当前处理的关键字位可能取得
r
r
r 个值,则需要建立
r
r
r 个队列,顺序扫描各个元素, 根据当前处理的关键字位, 将元素插入到相应的队列, 把各个队列中的结点,依次出队并连接。
3.2 演示动画

3.3 时间复杂度
- 最好 —
O
(
d
(
n
r
)
)
O(d(n + r))
O(d(n+r))
2. 最坏 —
O
(
d
(
n
r
)
)
O(d(n + r))
O(d(n+r))
3. 平均 —
O
(
d
(
n
r
)
)
O(d(n + r))
O(d(n+r))
注:
- 以
r
r
r 为 基数, 例如:十进制
r
=
10
r = 10
r=10
2. n
n
n 表示有
n
n
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
[外链图片转存中…(img-qgT8kyM6-1713544285869)]
给大家整理的电子书资料:
[外链图片转存中…(img-SbhfLwFx-1713544285869)]
如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-GX8gitFP-1713544285870)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









