







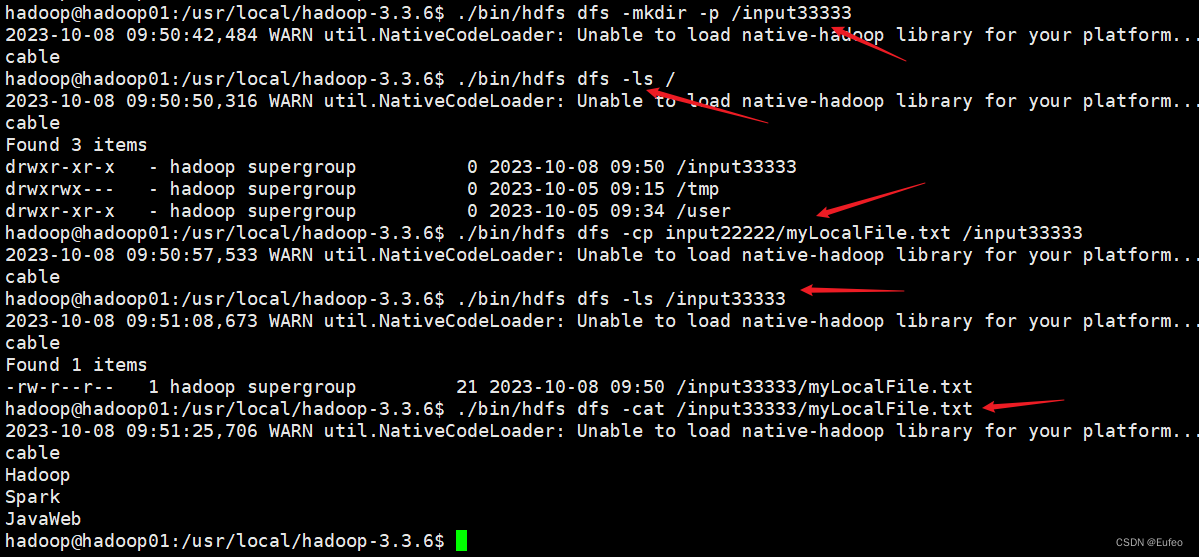
1.2.3 文件在HDFS中拷贝
了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的“/user/hadoop/input22222/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input33333”中(注意,这个input33333目录位于HDFS根目录下),可以使用如下命令:
先在根目录下创建input33333文件夹:
./bin/hdfs dfs -mkdir -p /input33333
./bin/hdfs dfs -ls /
执行复制指令:
./bin/hdfs dfs -cp input22222/myLocalFile.txt /input33333
查看文件是否复制成功:
./bin/hdfs dfs -ls /input33333
./bin/hdfs dfs -cat /input33333/myLocalFile.txt
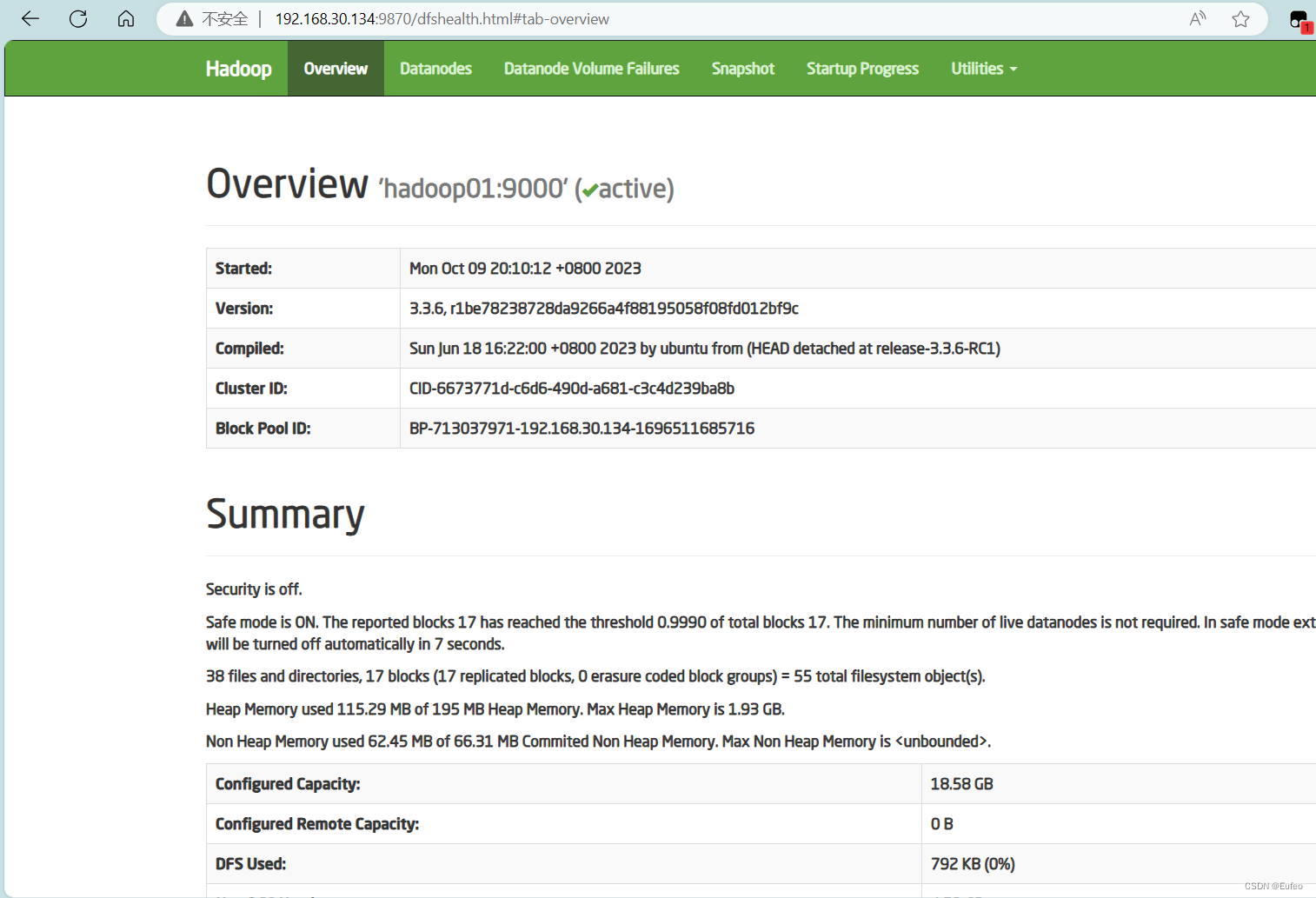
二、利用Web界面管理HDFS
在master节点上启动Hadoop(版本是Hadoop3.3.6)的前提下。可以使用:"IP地址:9870"的方式进入HDFS的Web界面即可看到HDFS的web管理界面。WEB界面的访问地址是http://localhost:9870。
三、利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
利用Java API进行交互,需要利用软件IDEA编写Java程序。
3.1 在Debian系统中安装IDEA软件
详细教程,可以参考此处。
3.2 使用IDEA开发调试HDFS Java程序
进入IDEA的安装目录,启动IDEA工具。
cd /opt/idea-IC-23.2/bin
ls -l
./bin/idea.sh
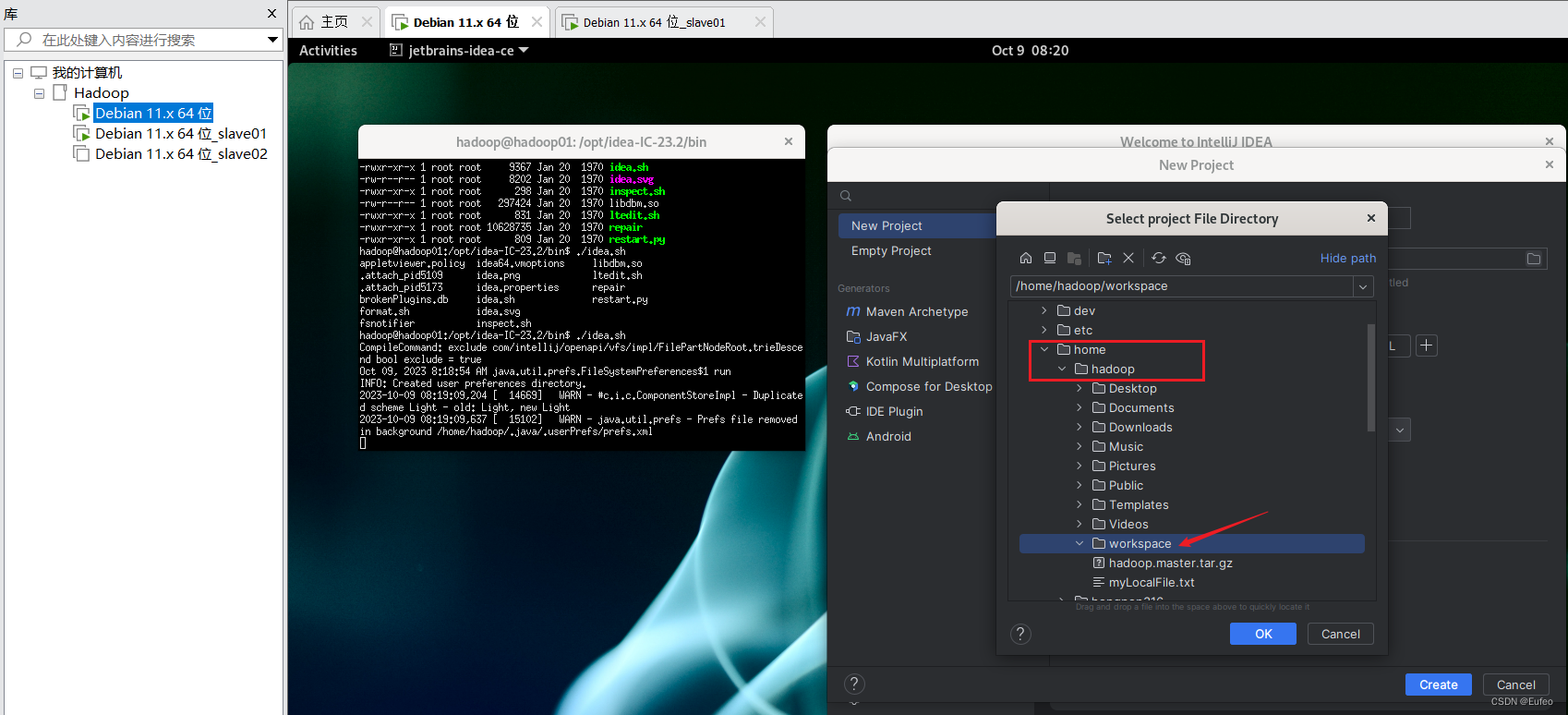
启动IDEA工具。当IDEA启动以后,会弹出如下图所示界面,提示设置工作空间(workspace)。
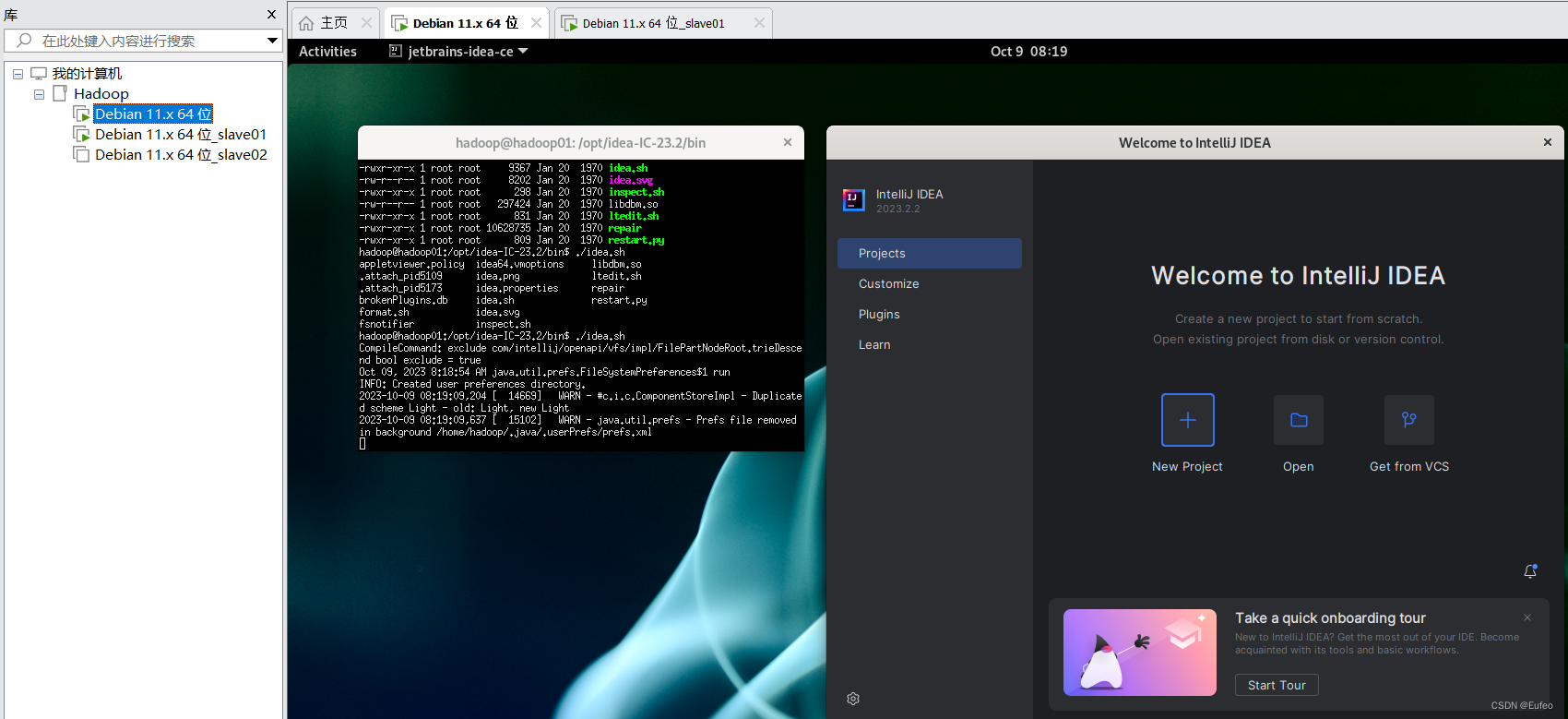
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
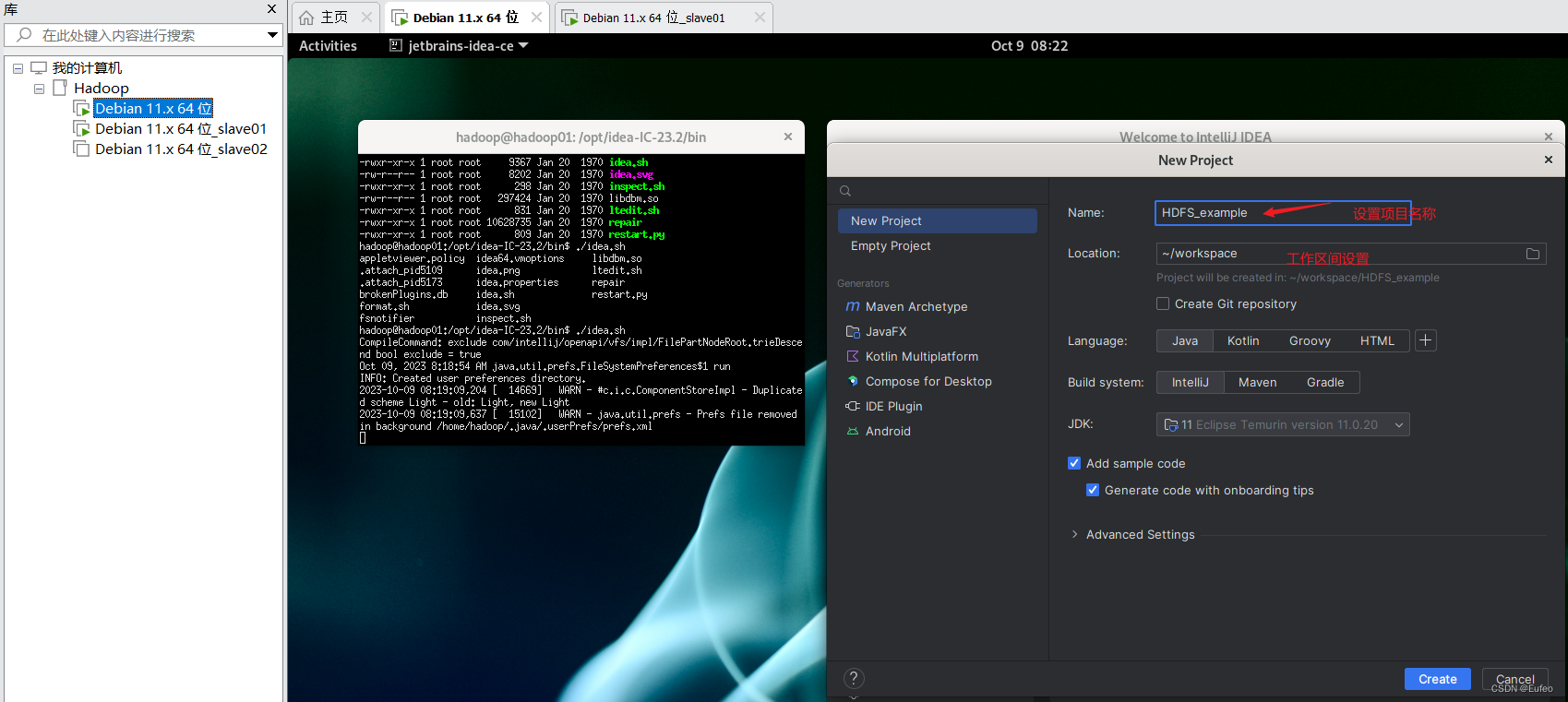
IDEA启动以后,会呈现如下图所示的界面。
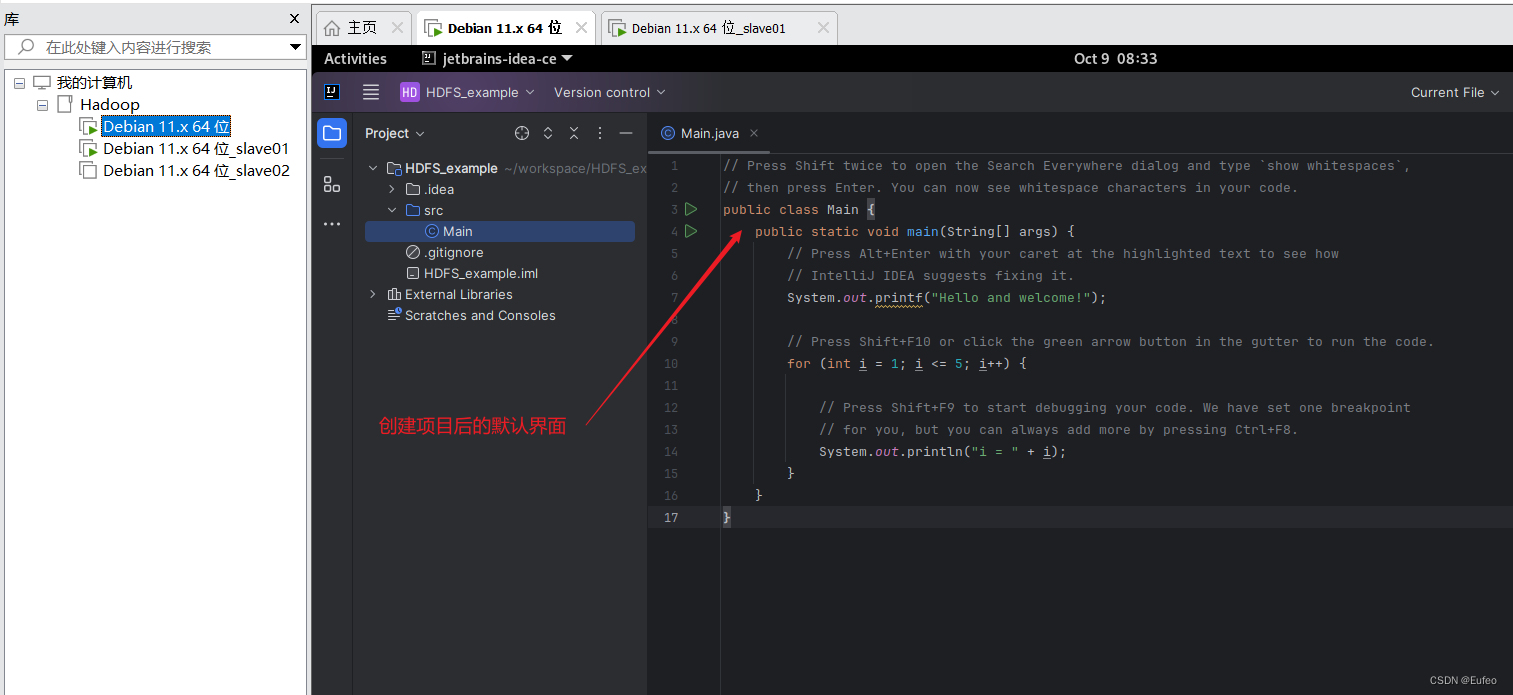
3.3 为项目添加需要用到的JAR包
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop-3.3.6**/common**”目录下的所有JAR包,包括hadoop-common-3.3.6.jar、hadoop-common-3.3.6-tests.jar、haoop-nfs-3.3.6.jar、haoop-kms-3.3.6.jar和hadoop-registry-3.3.6.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop-3.3.6/share/hadoop**/common/lib**”目录下的所有JAR包;
(3)“/usr/local/hadoop-3.3.6/share/hadoop**/hdfs**”目录下的所有JAR包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop-3.3.6/share/hadoop**/hdfs/lib**”目录下的所有JAR包。

第一步:创建libs文件夹。如果已经存在libs文件夹,则可以直接进行下一步。

第二步:将需要导入的jar包复制粘贴到libs文件夹中。
将jar复制到libs中,记住刚放入时的jar包状态,不可点击打开 。
例如:可以通过输入命令以下命令,然后进入 /usr/local/hadoop-3.3.6/share/hadoop/common 文件夹中查到需要导入到HDFS_example项目中的jar包:
nautilus /
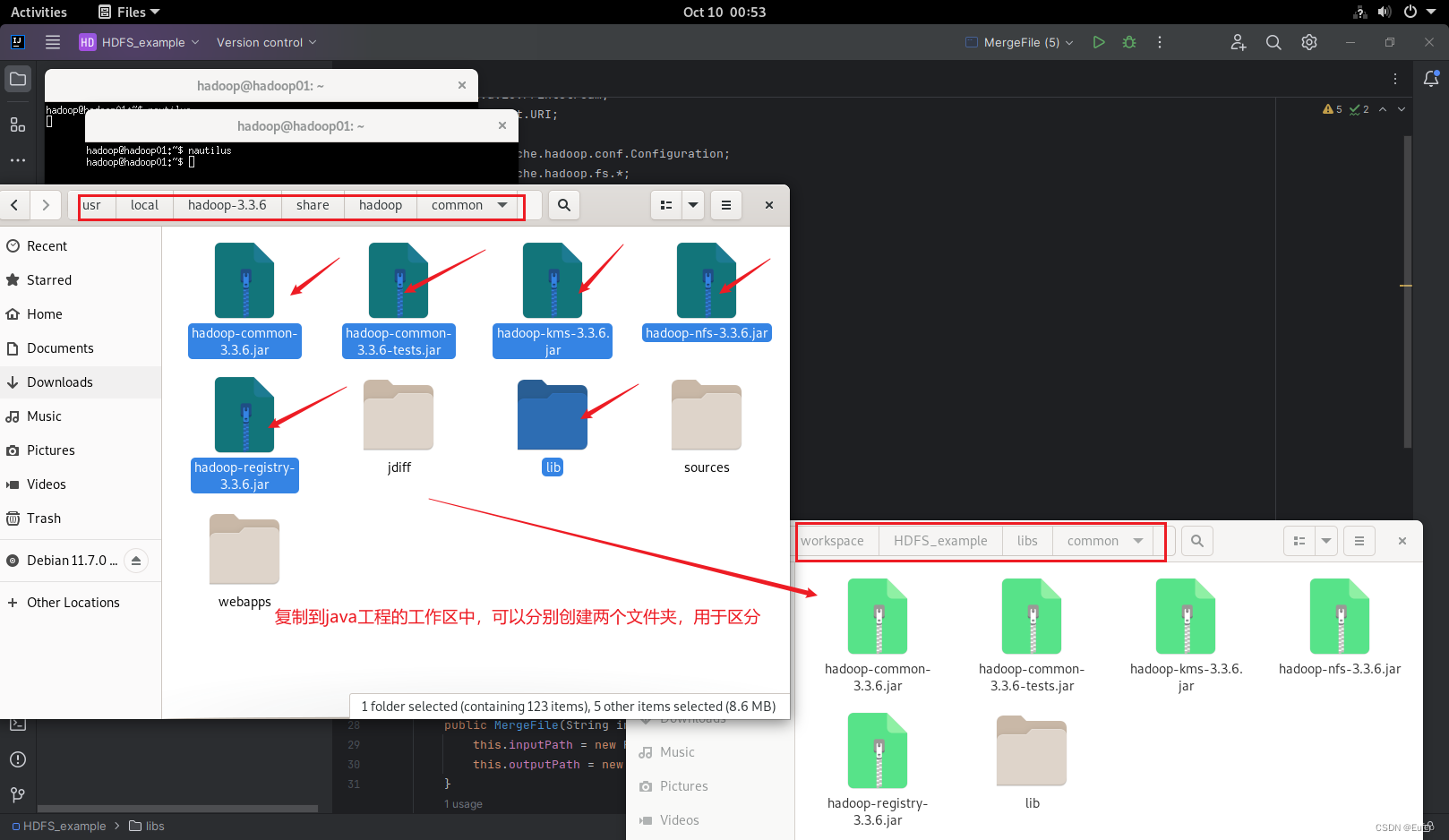
包括lib和其他的jar包:
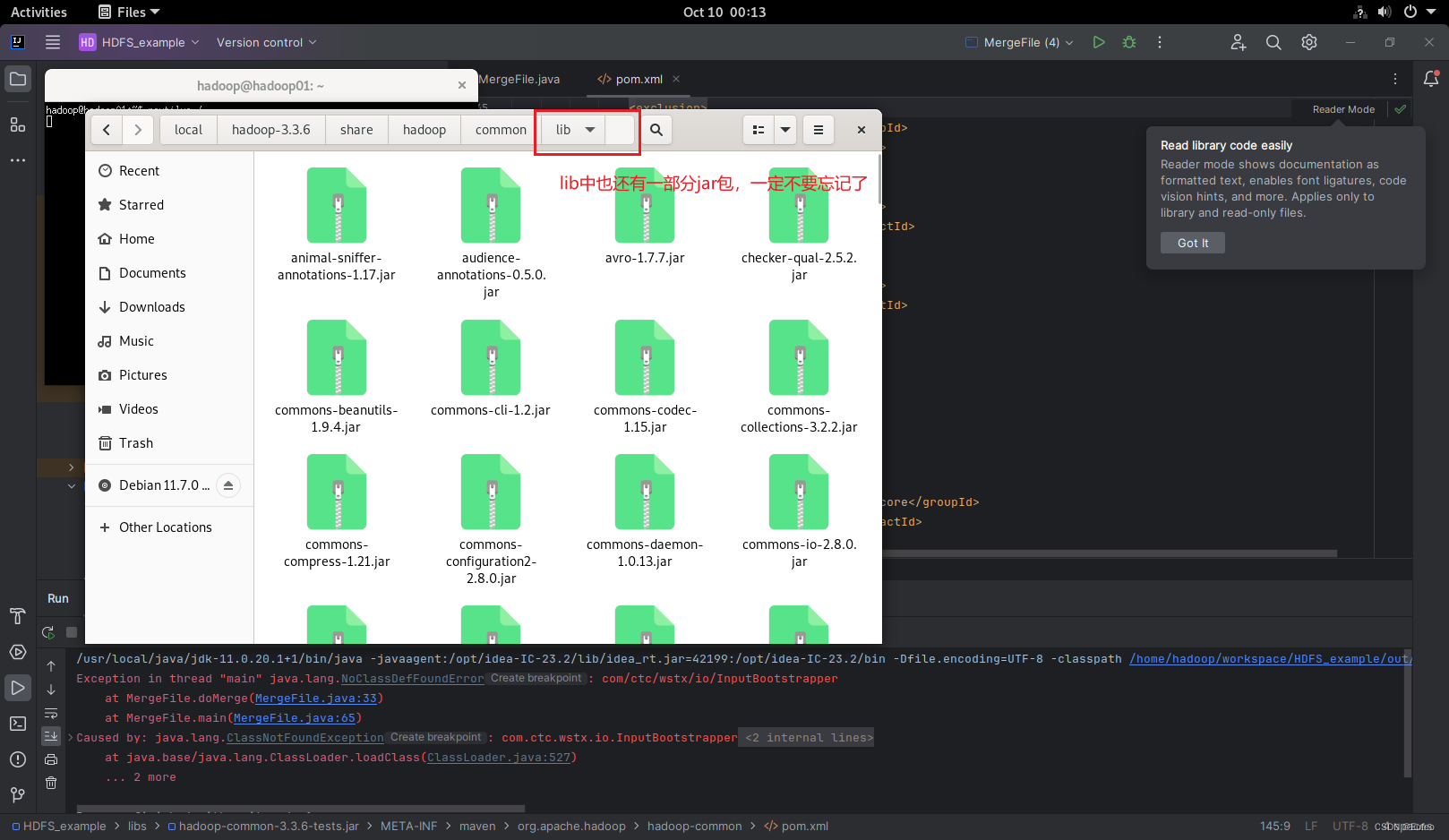
同样地,复制hdfs下的jar包和lib:


然后在IDEA中的Java工程中导入以上的包:
第三步:建立对libs文件夹的依赖。在IDEA中右键单击项目,选择’Open Module Settings”(或者"Project Structure"”),在弹出的窗口中选择’Modules”,然后选择“Dependencies”选项卡。
点击“+"按钮,选择"JARs or directories”,然后在弹出的窗口中选择刚才放置jar包的libs文件夹,然后点击OK(我在此处直接选择的是文件夹)。

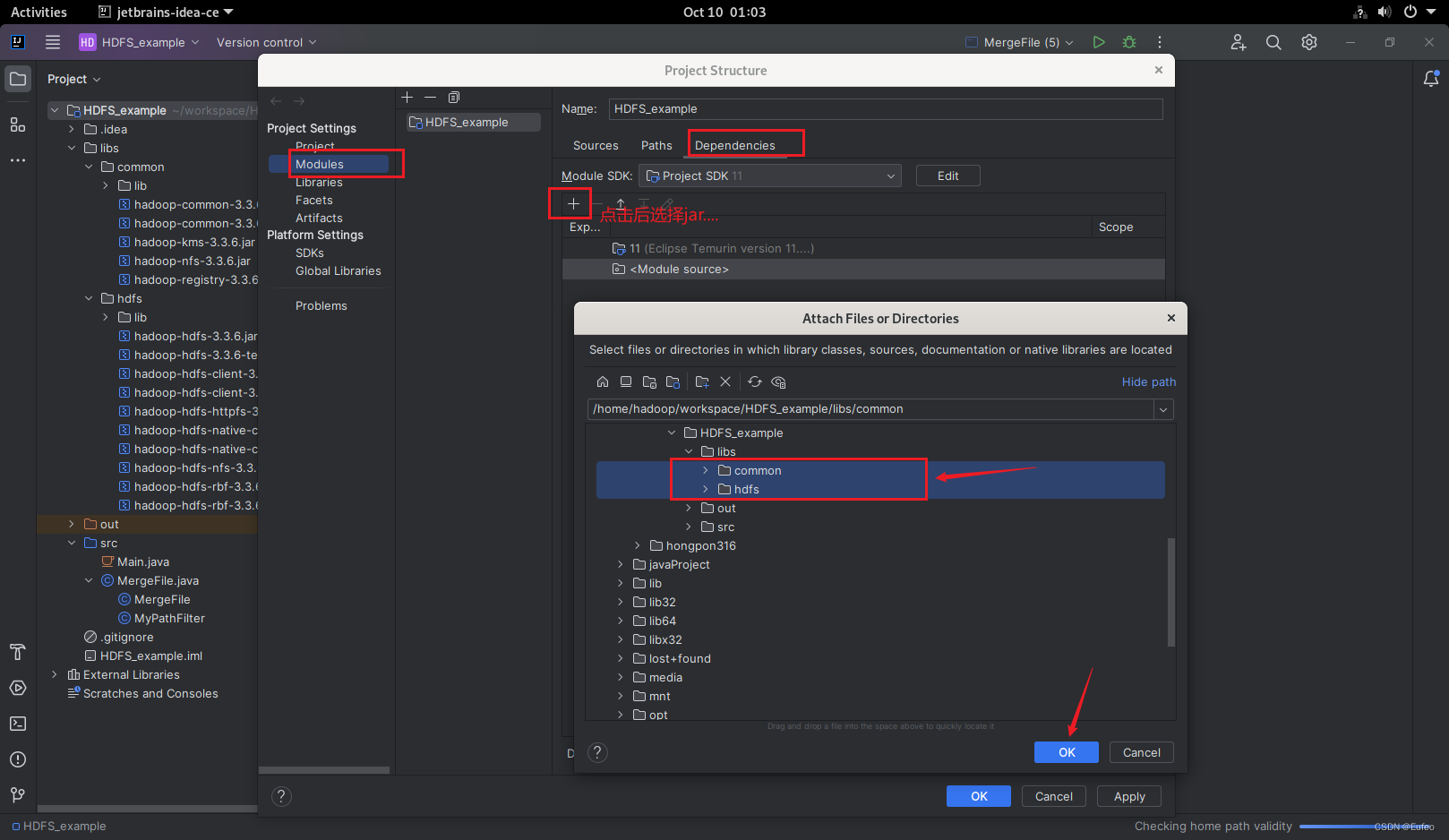

在此处选择“compile”:然后点击“apply”和“ok”:
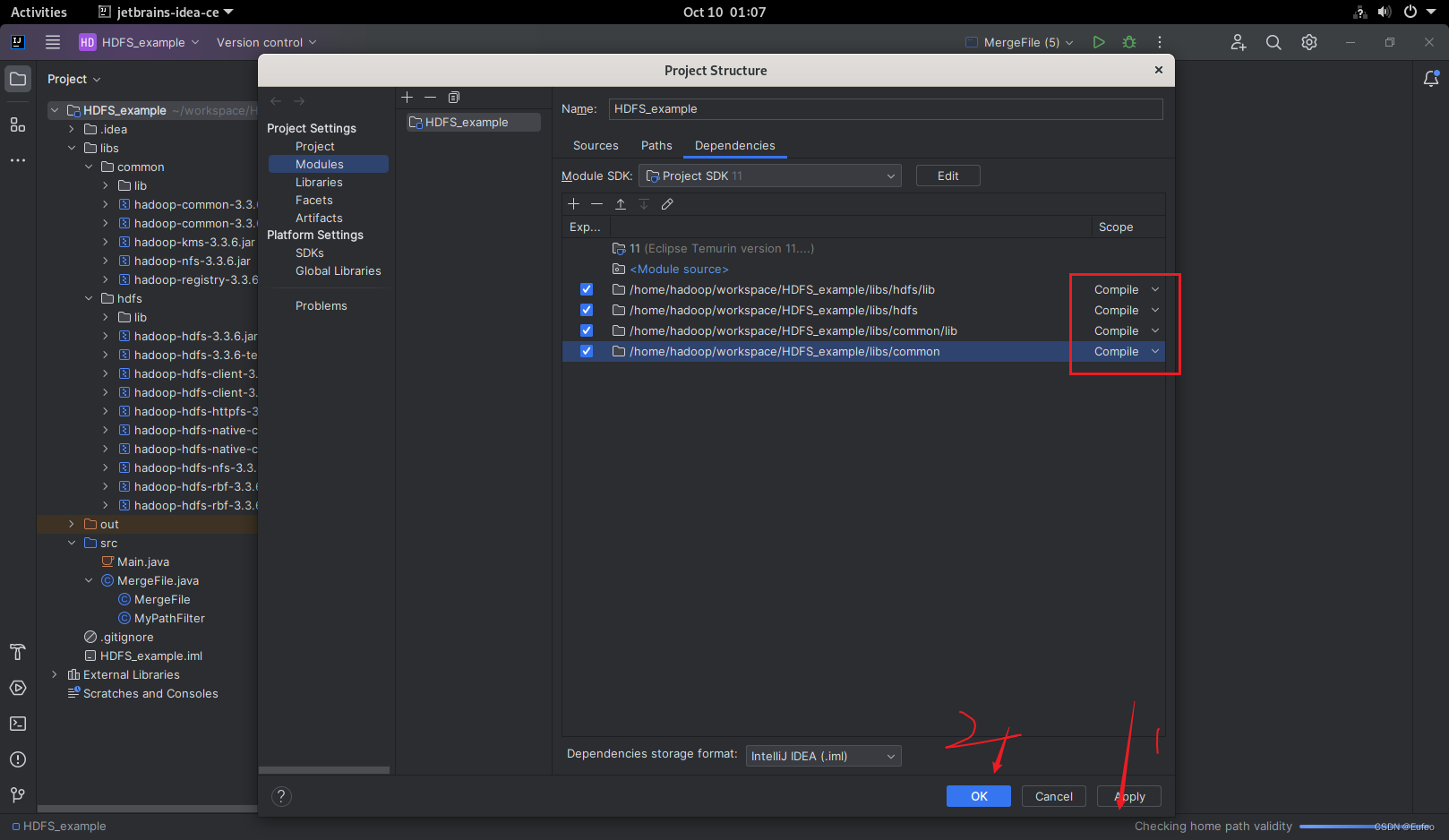
如果是这个状态表示导入成功:
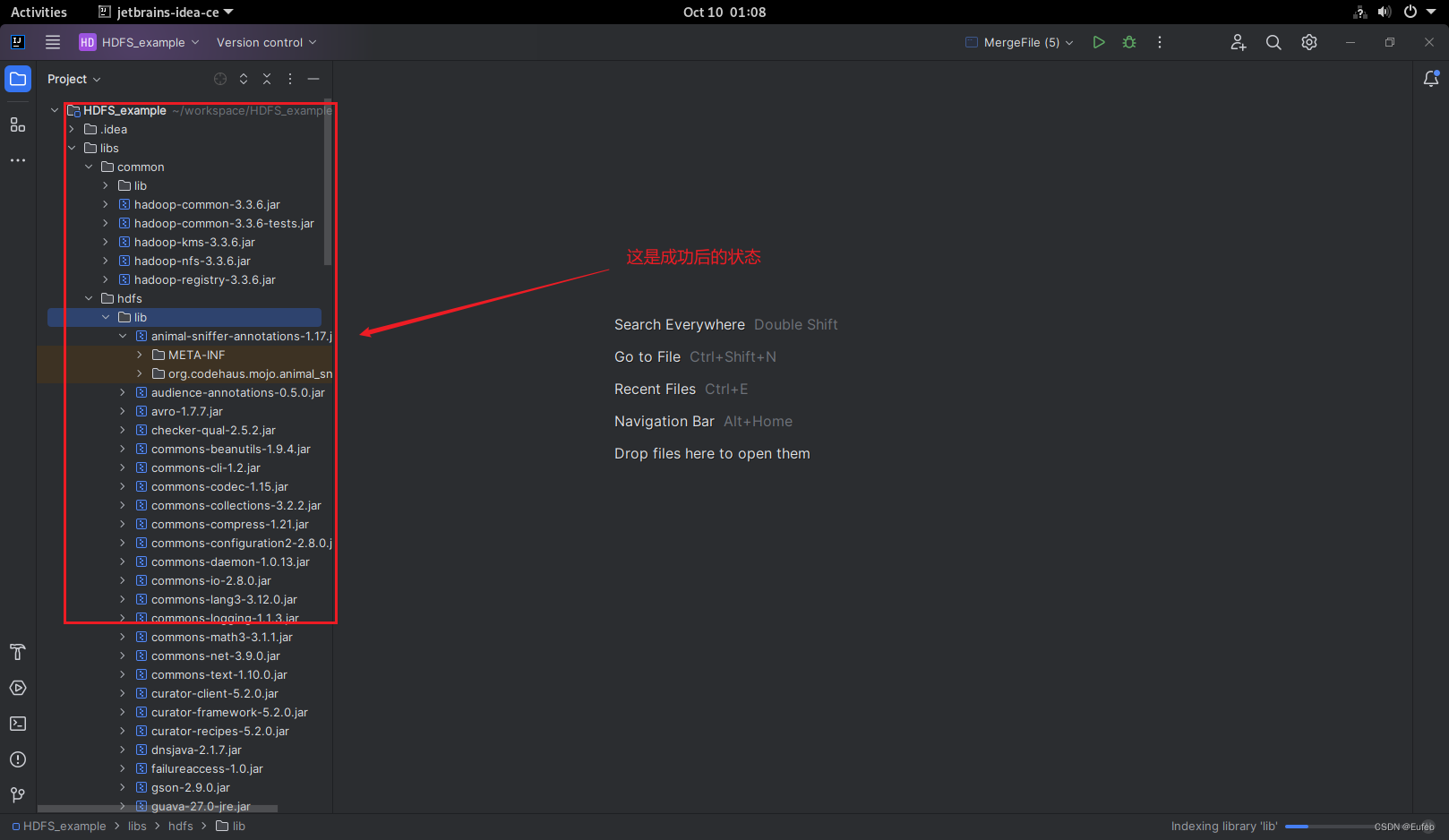
这样,导入jar包的操作就完成了。现在你可以直接编写或运行代码了。如果需要进一步优化导包设置,可以根据IDEA的环境配置和插件进行相应的调整(如Maven)。
四、编写Java应用程序
4.1 新建MergeFile.java的文件
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.compress.DefaultCodec;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/***
* 利用XMLRecordReader和SequenceFile.Writer合并HDFS中的XML文件
*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
// 下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath, new MyPathFilter(".*\\.abc"));
// 创建SequenceFile.Writer来写入合并后的文件
SequenceFile.Writer writer = SequenceFile.createWriter(fsDst, conf, outputPath, Text.class, Text.class,
SequenceFile.CompressionType.BLOCK, new DefaultCodec());
// 下面读取过滤之后的每个文件的内容,并将每个文件的内容写入SequenceFile中
for (FileStatus status : sourceStatus) {
FSDataInputStream fsdis = fsSource.open(status.getPath());
byte[] data = new byte[(int) status.getLen()];
fsdis.readFully(data);
fsdis.close();
// 将文件路径作为key,文件内容作为value写入SequenceFile
writer.append(new Text(status.getPath().toString()), new Text(data));
}
writer.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile("hdfs://localhost:9000/user/hadoop/", "hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}
作用:使用FSDataOutputStream和FSDataInputStream来合并HDFS中的文件。它通过循环读取每个文件的内容,并将其写入输出文件中。
4.2 编译运行程序
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop:
cd /usr/local/hadoop-3.3.6/bin/
./bin/hdfs start-dfs.sh
也可通过 jps 命令查看是否已经启动:

然后,要确保HDFS的“/user/hadoop”目录下已经存在file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,每个文件里面有内容。这里,假设文件内容如下:
file1.txt的内容是: this is file1.txt
file2.txt的内容是: this is file2.txt
file3.txt的内容是: this is file3.txt
file4.abc的内容是: this is file4.abc
file5.abc的内容是: this is file5.abc
如果没有创建,可以使用一个脚本命令来快速创建:
cd ~
pwd # 显示当前的路径
vim create_files.sh # 编辑脚本
chmod +x create_files.sh # 修改脚本的权限
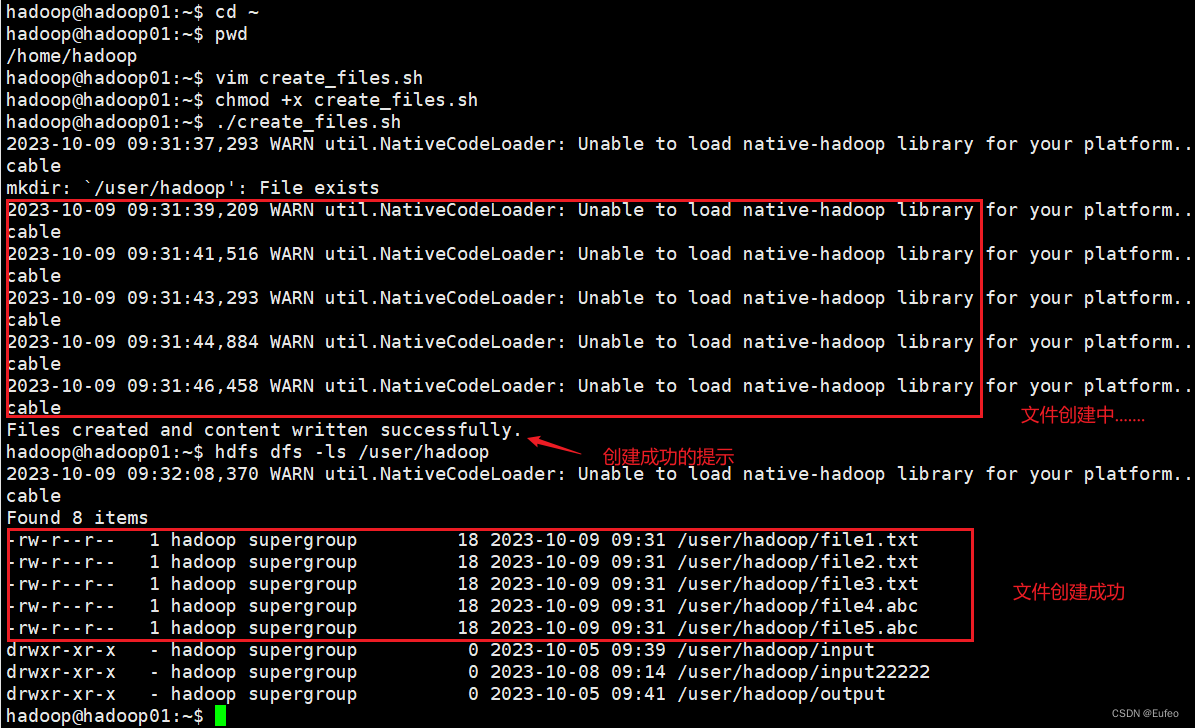
./create_files.sh # 执行脚本
hdfs dfs -ls /user/hadoop # 查看是否创建成功
#!/bin/bash
hdfs dfs -mkdir /user/hadoop
echo “this is file1.txt” | hdfs dfs -put - /user/hadoop/file1.txt
echo “this is file2.txt” | hdfs dfs -put - /user/hadoop/file2.txt
echo “this is file3.txt” | hdfs dfs -put - /user/hadoop/file3.txt
echo “this is file4.abc” | hdfs dfs -put - /user/hadoop/file4.abc
echo “this is file5.abc” | hdfs dfs -put - /user/hadoop/file5.abcecho “Files created and content written successfully.”
 执行该代码:
执行该代码:
特别注意:在执行代码之前,请将/user/hadoop 下的 **文件夹(如input、input22222、output、input33333之类的,在之前操作过程中产生的文件)**全部删除干净。
hdfs dfs -ls # 查看/user/hadoop 目录下有哪些文件夹
hdfs dfs -rm -r 文件名 # 删除文件夹
可能出现的问题:
Exception in thread “main“ java.lang.NoClassDefFoundError:com/ctc/wstx/io/InputBootstrap,参考 Hadoop(4-1)")解决。
Exception in thread “main” java.net.ConnectException: Call From hadoop01/192.168.30.134 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; 参考 Hadoop(4-2)")解决。
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). ,参考 Hadoop(4-3)") 解决。
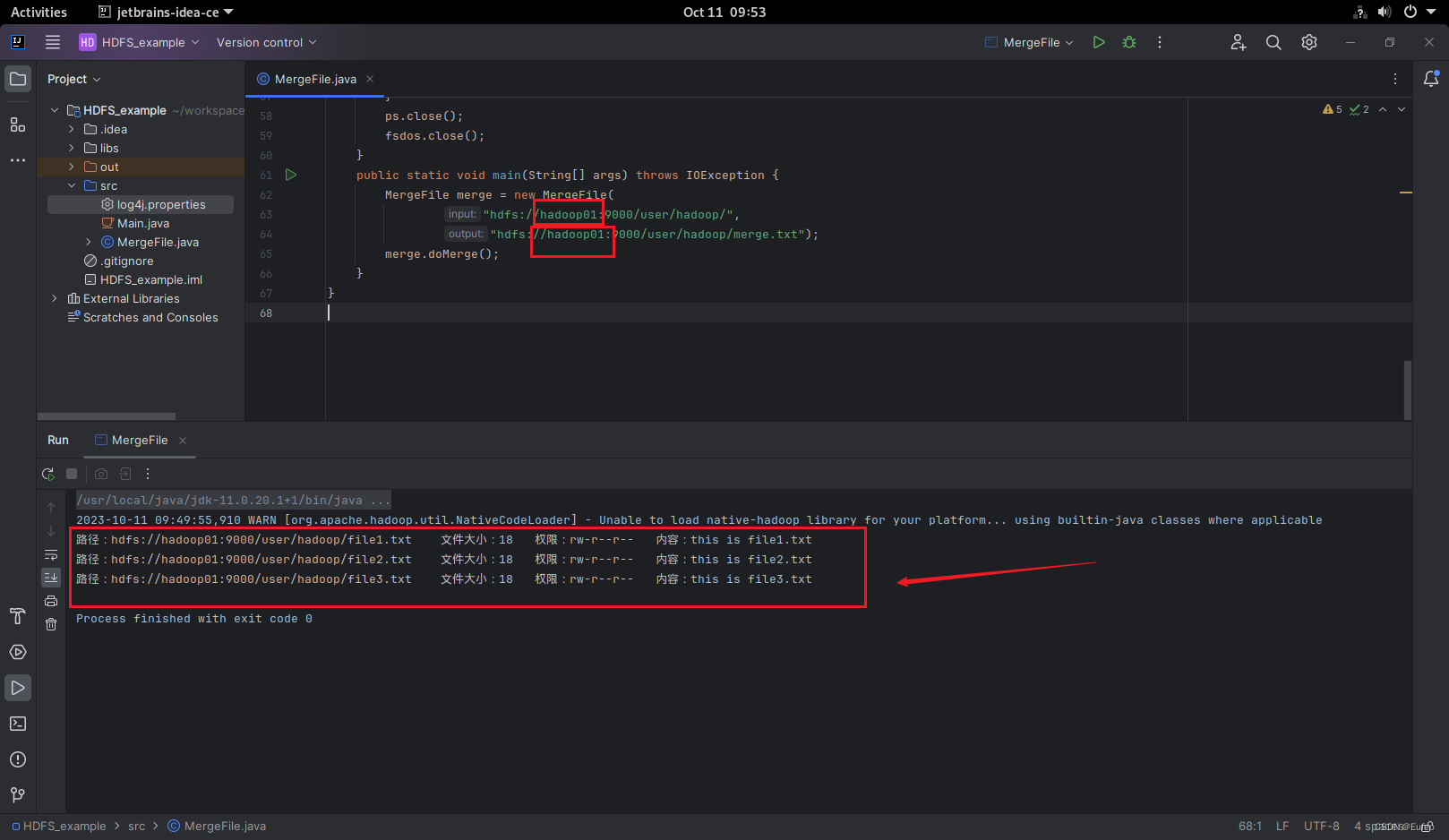
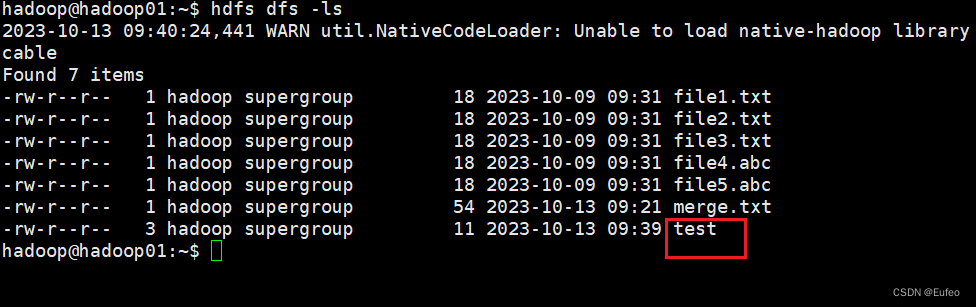
如果程序运行成功,这时,可以到HDFS中查看生成的merge.txt文件,比如,可以在Linux终端中执行如下命令:
hdfs dfs -ls
hdfs dfs -cat merge.txt
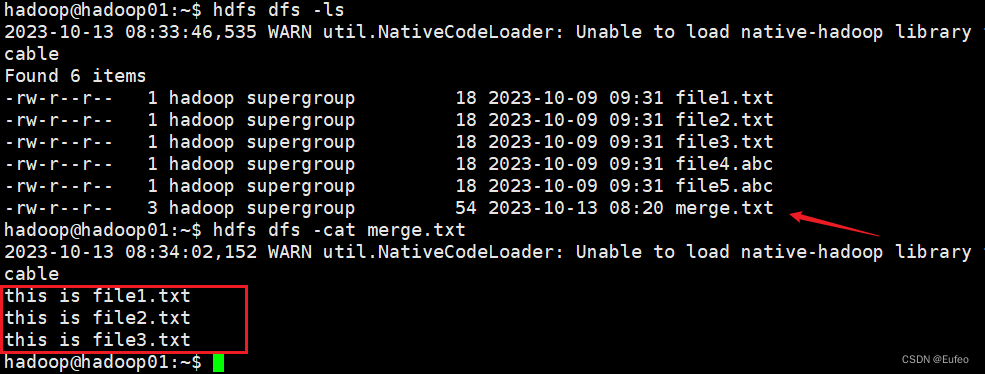 可以看到merge.txt中的如下结果:
可以看到merge.txt中的如下结果:
this is file1.txt
this is file2.txt
this is file3.txt
五. Java应用程序的部署
下面介绍如何把Java应用程序生成JAR包,部署到Hadoop平台上运行。首先,在Hadoop安装目录下新建一个名称为myapp的目录,用来存放我们自己编写的Hadoop应用程序,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop-3.3.6/
mkdir myapp

5.1 使用IDEA自带的打包工具打包JAR
在IDEA工作界面左侧的“Package Explorer”面板中,在工程名称“HDFS_example”上点击鼠标右键,在弹出的菜单中选择“Open Module Setting”,如下图所示。
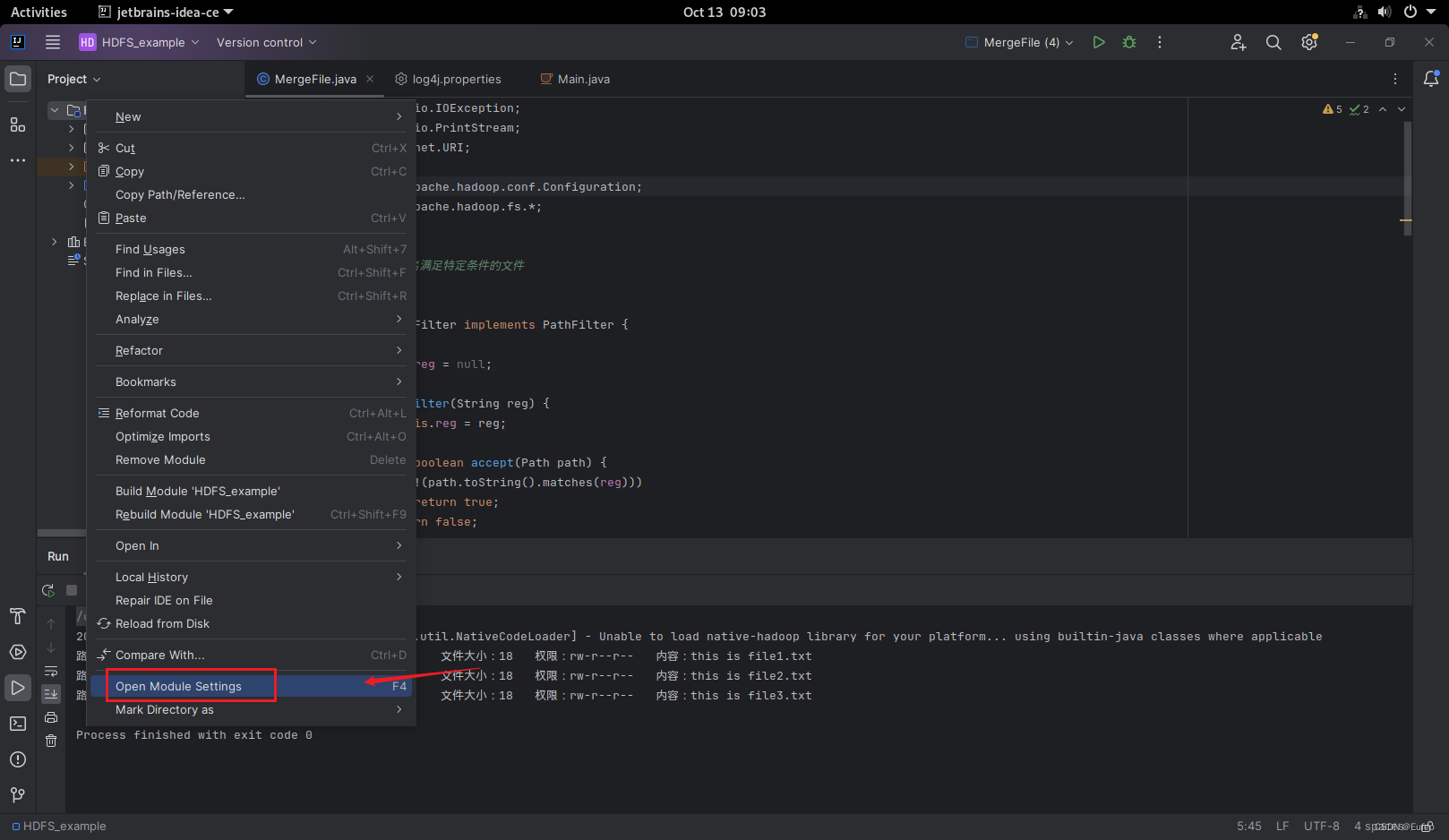

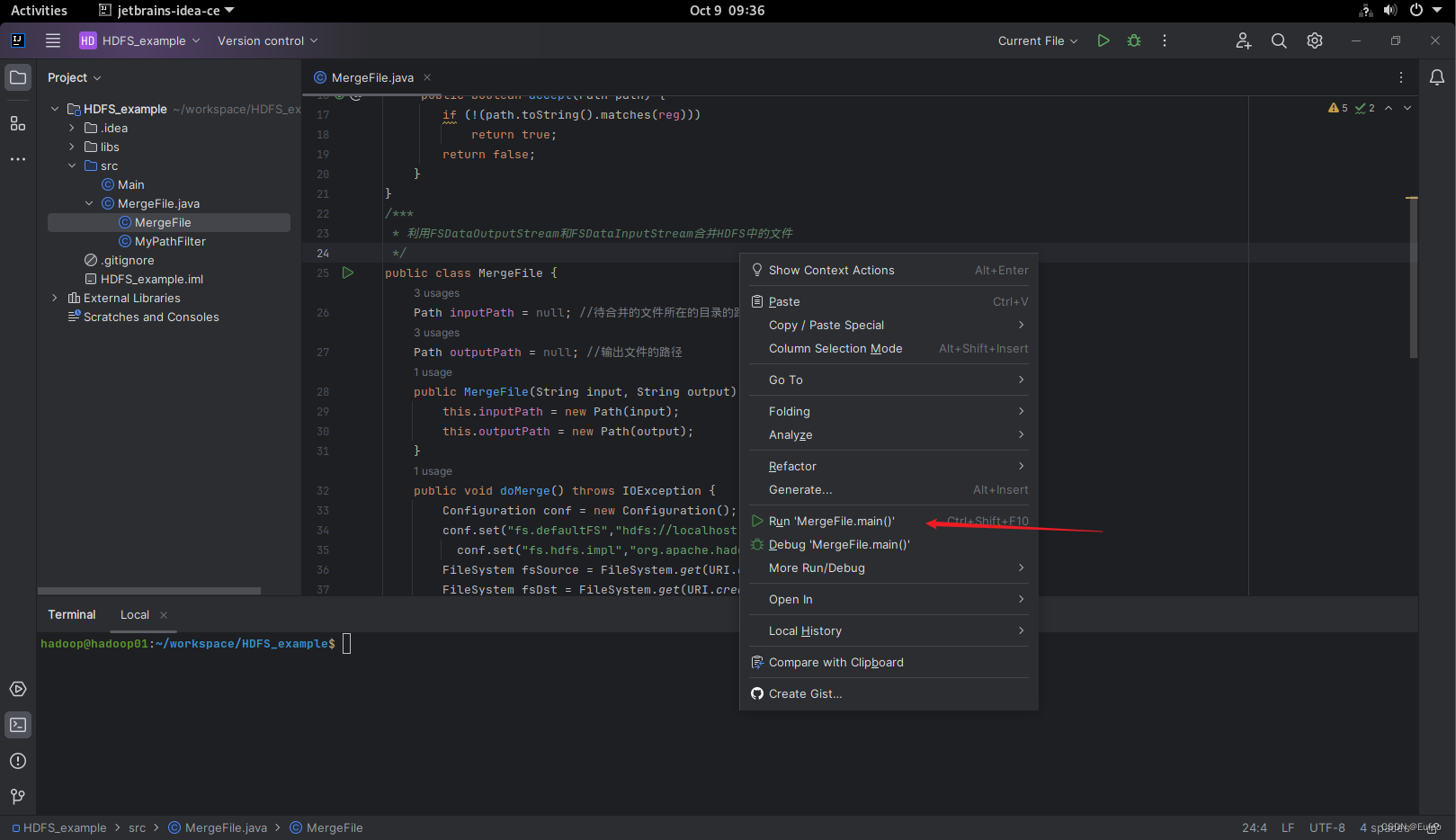
然后选择需要 运行的那个 类文件,此处为 MergeFile.java
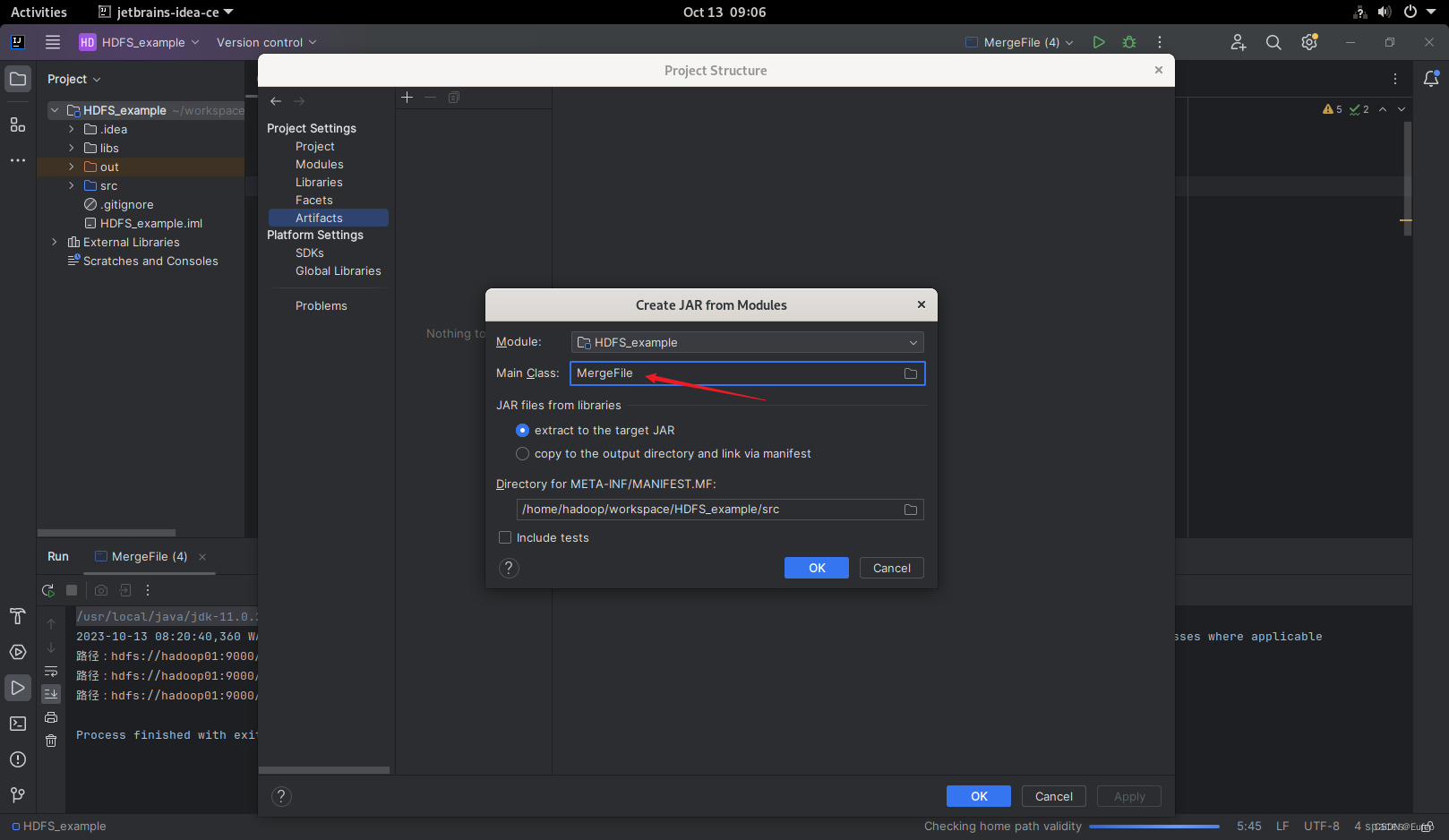
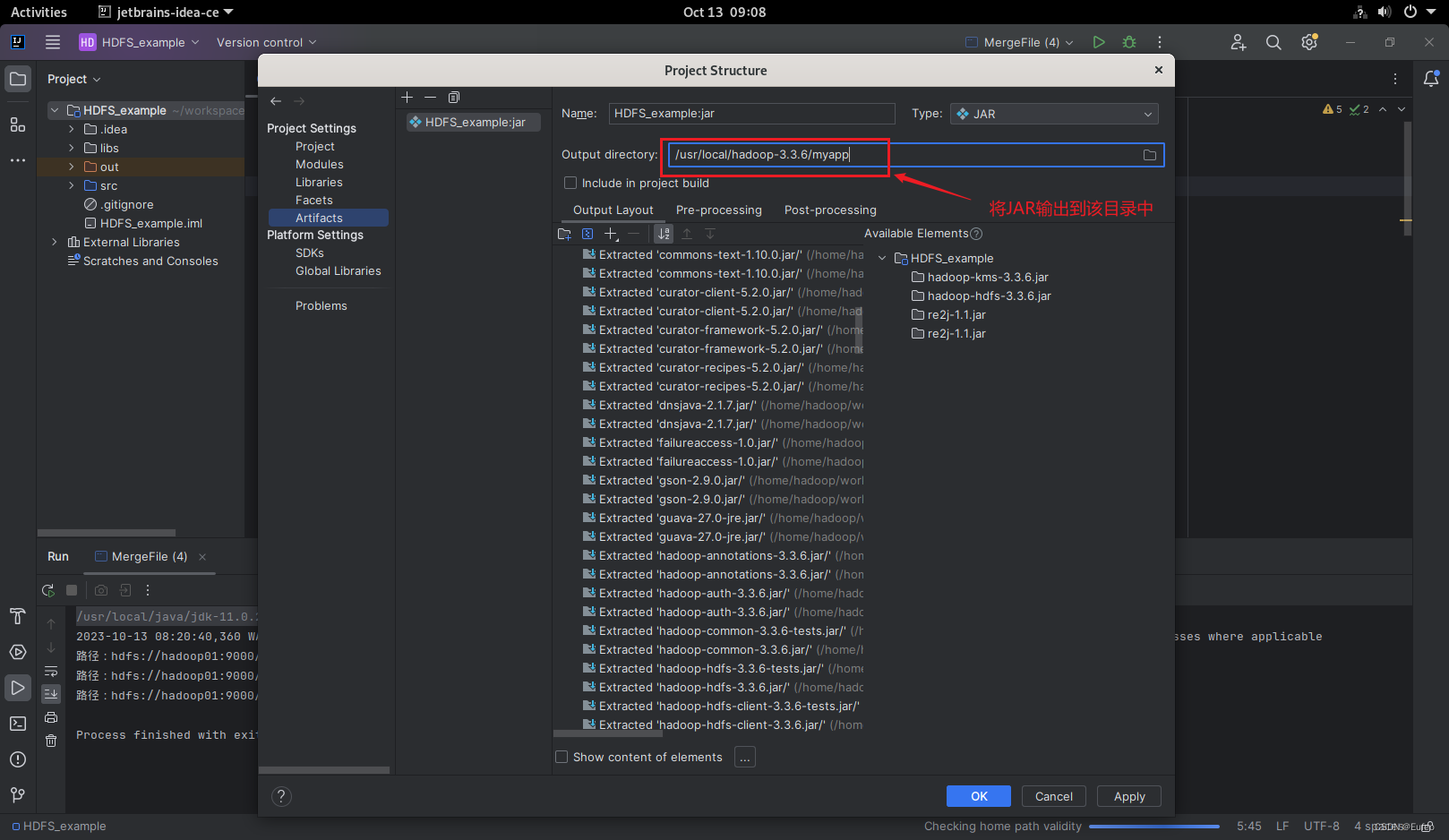 然后点击apply和ok 。确定后重新 Build Artifas–jar包,如图所示,之后在项目out 输出里就会有相应的jar包了。
然后点击apply和ok 。确定后重新 Build Artifas–jar包,如图所示,之后在项目out 输出里就会有相应的jar包了。

 查看目录/usr/local/hadoop-3.3.6/myapp 中,此时jar目录已经存在了。
查看目录/usr/local/hadoop-3.3.6/myapp 中,此时jar目录已经存在了。
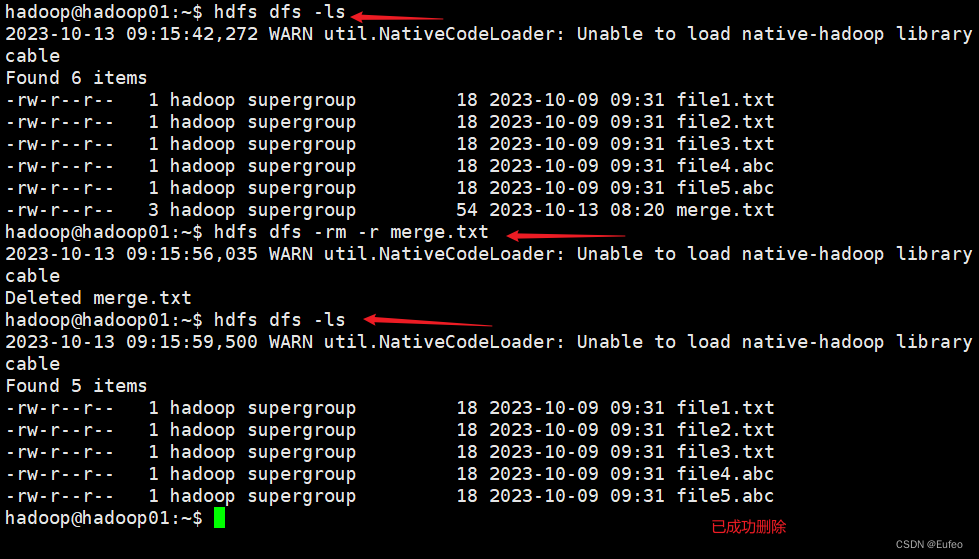
 由于之前已经运行过一次程序,已经生成了merge.txt,因此,需要首先在linux中执行如下命令删除该文件:
由于之前已经运行过一次程序,已经生成了merge.txt,因此,需要首先在linux中执行如下命令删除该文件:
hdfs dfs -ls # 查看文件
hdfs dfs -rm -r merge.txt # 删除文件
hdfs dfs -ls
5.2 hadoop jar命令运行程序
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop-3.3.6/
./bin/hadoop jar ./myapp/HDFS_example.jar
hdfs dfs -ls
hdfs dfs -cat merge.txt
命令解释:
hadoop jar <JAR文件路径> <应用程序主类> [应用程序参数]
六、练习
下面给出几个代码文件,供读者自己练习。
6.1 写入文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
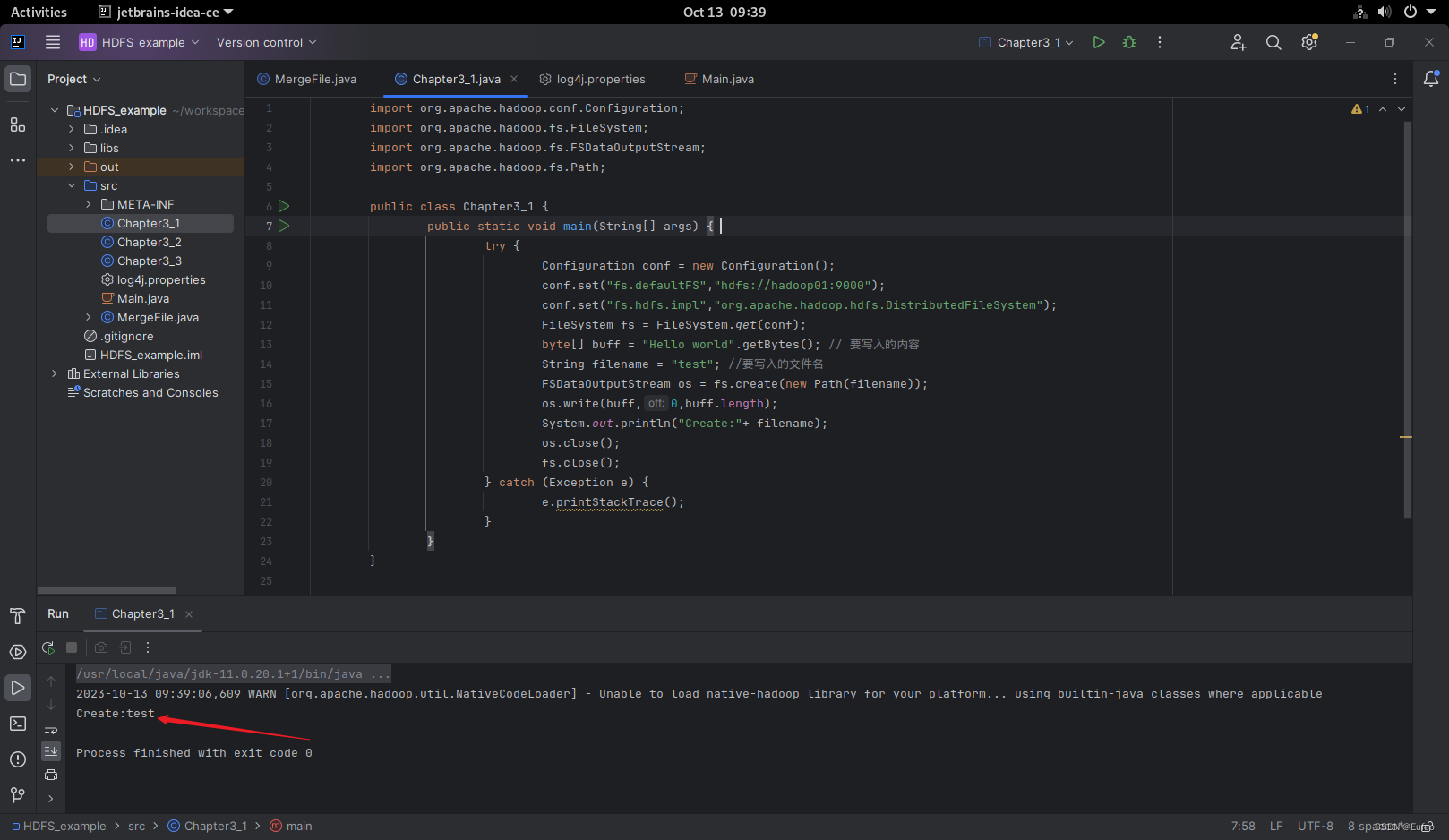
public class Chapter3_1 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop01:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "Hello world".getBytes(); // 要写入的内容
String filename = "test"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}

6.2 判断文件是否存在
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1864
1864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









