







ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。 使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。
在云服务器上使用docker安装Kafka:
💡 确保使用"free -h"命令, 确保剩余内存空间至少有600MB, 让自己的系统只保留redis和mysql服务, 其他的全部关闭
安装zookeeper
docker run --name some-zookeeper -dit -p 2181:2181 zookeeper
将云服务器中的2181端口放开 稍微等待15s等待 zookeeper彻底启动成功
将云服务器中的9092端口放开
安装kafka
docker run -d --name=kafka2 \
-p 9092:9092 \
-e ALLOW\_PLAINTEXT\_LISTENER=yes \
-e KAFKA\_CFG\_ZOOKEEPER\_CONNECT=服务器IP地址:2181 \
-e KAFKA\_BROKER\_ID=2 \
-e KAFKA\_NODE\_ID=2 \
-e KAFKA\_ENABLE\_KRAFT=false \
-e KAFKA\_HEAP\_OPTS="-Xmx180m -Xms180m" \
-e KAFKA\_ADVERTISED\_LISTENERS=PLAINTEXT://服务器IP地址:9092 \
-e KAFKA\_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e BITNAMI\_DEBUG=true \
bitnami/kafka
docker ps查看kafka和zookeeper容器,是否成功启动
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-99bpgehS-1691400376656)(kafka%201c1fb3fcfefa4ee2ab29cfd2c0890649/Untitled.png)]](https://img-blog.csdnimg.cn/eb9d41e4c1934888be59146069f6b3b8.png)
💡 重新安装kafka的时候, 先docker rm删除掉kafka和zookeeper容器, 然后重新安装一下zookeeper容器
docker rm -f kafka2 some-zookeeper
注意: 命令的末尾千万不要携带 /bin/bash 否则会引起kafka容器无法启动
参数释义:
- e KAFKA_BROKER_ID=2 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
- e KAFKA_CFG_ZOOKEEPER_CONNECT=服务器IP地址:12181 kafka 配置zookeeper的连接地址
- e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 把kafka的地址端口注册给zookeeper
- e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口 (是容器内部的端口)
- e KAFKA_HEAP_OPTS=“-Xmx180m -Xms180m” 设置kafka占用的内存
2.创建主题topic
topic是什么概念?topic可以实现消息的分类,不同消费者订阅不同的topic。
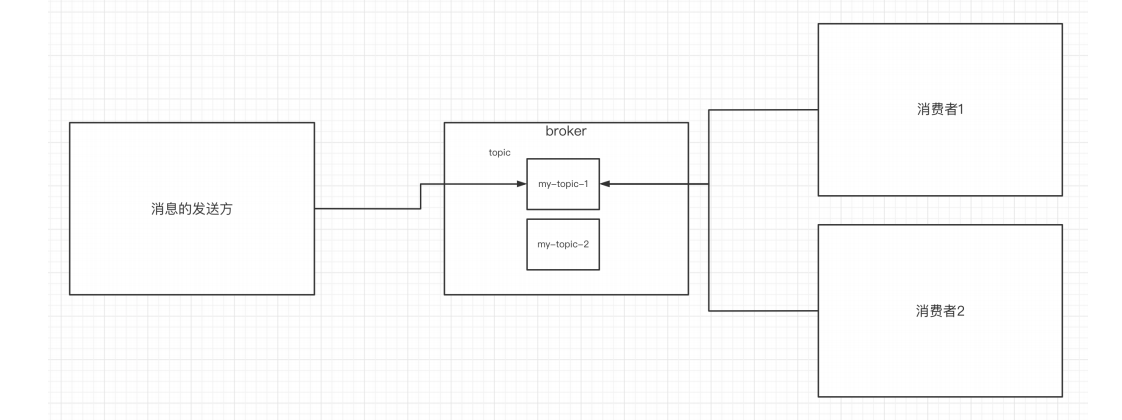
执行以下命令创建名为“test”的topic,这个topic只有一个partition,并且备份因子也设置为1
先进入到kafka2容器系统中
docker exec -it kafka2 /bin/bash
kafka的安装目录位于/opt/bitnami/kafka
cd /opt/bitnami/kafka/bin
cd bin
创建topic
./kafka-topics.sh --create --topic test --bootstrap-server 服务器IP地址:9093 --replication-factor 1 --partitions 1
查看当前kafka内有哪些topic
./kafka-topics.sh --bootstrap-server 服务器IP地址:9093 --list
3.发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址的topic中
./kafka-console-producer.sh --broker-list 服务器IP地址:9093 --topic test
4.消费消息
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输 出, 默认是消费最新的消息 。使用kafka的消费者消息的客户端,从指定kafka服务器的指定 topic中消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --topic test
方式二:从头开始消费:“--from-beginning”
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --from-beginning --topic test
几个注意点:
- 消息会被存储
- 消息是顺序存储
- 消息是有偏移量的
- 消费时可以指明偏移量进行消费
三、Kafka中的关键细节
1.消息的顺序存储
消息的发送方会把消息发送到broker中,broker会存储消息,消息是按照发送的顺序进行存储。因此消费者在消费消息时可以指明主题中消息的偏移量。默认情况下,是从最后一个消息的下一个偏移量开始消费。
一个broker相当于是一个节点 -> 一个kafka容器就是一个broker
读取和写入的顺序都是先进先出
2. 单播消息的实现
单播消息:一个消费组里 只会有一个消费者能消费到某一个topic中的消息。于是可以创建多个消费者,这些消费者在同一个消费组中。
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup --topic test
3.多播消息的实现
在一些业务场景中需要让一条消息被多个消费者消费,那么就可以使用多播模式 。
kafka实现多播,只需要让不同的消费者处于不同的消费组即可。
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup2 --topic test
4.查看消费组及信息
# 查看当broker下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9093 --list
# 查看当前topic 中的 消费组中的具体信息:比如当前偏移量、最后一条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9093 --describe --group testGroup1
- Currennt-offset: 当前消费组的已消费偏移量 * Log-end-offset: 主题对应分区消息的结束偏移量(HW) * Lag: 当前消费组未消费的消息数
运行结果:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testGroup1 test 0 12 12 0 console-consumer-e8490316-aa97-40ff-8e7b-36e8c68e9a6e /81.70.199.213 console-consumer
四、主题、分区的概念
1.主题Topic
主题Topic可以理解成是一个类别的名称。
2.partition分区
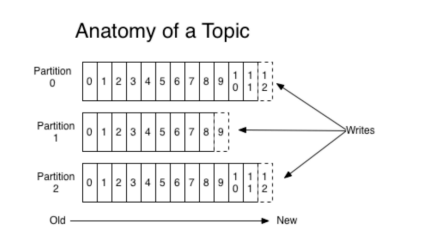
一个主题中的消息量是非常大的,因此可以通过分区的设置,来分布式(集群)存储这些消息。比如一个topic创建了 3 个分区。那么topic中的消息就会分别存放在这三个分区中。
为一个主题创建多个分区
./kafka-topics.sh --create --topic test1 --bootstrap-server 服务器IP地址:9093 --replication-factor 1 --partitions 2
可以通过这样的命令查看topic的分区信息
./kafka-topics.sh --bootstrap-server 服务器IP地址:9093 --topic test1 --describe
test的结果
##结果
Topic: test1 TopicId: UBg9xwGhSKyaeWV-RdiNcQ PartitionCount: 2 ReplicationFactor: 1 Configs:
Topic: test1 Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
通过查看topic信息,其中的关键数据:
- replicas:当前副本存在的broker节点
- leader:副本里的概念
- 每个partition都有一个broker作为leader。
- 消息发送方要把消息发给哪个broker?就看副本的leader是在哪个broker上面。副本里的leader专⻔用来接收消息。
- 接收到消息,其他follower通过poll的方式来同步数据。
isr: 可以同步的broker节点和已同步的broker节点,存放在isr集合中。
分区的作用:
- 可以分布式存储
- 可以并行写
- producer向3个分区写入消息,consumer从3个分区拉取消息。分区内的消息通过
offset保证连续,但分区之间的消息顺序无法保证。
kafka集群创建topic中的分区和副本选择基本概念
7个broker组成的集群, 创建一个topic, 设置7个分区是最优选择, 如果选择5个分区, 也是可以的, 但是两台机器没有起到作用; 如果选择10个分区, 也是可以的, 但是会有三台机器会做双份工作, 有两个leader
设置7个副本是最优选择, 如果选择5个副本, 也是可以的, 但是又两台机器没有起到备份作用; 如果选择10个副本呢? 是不可以的, 创建逻辑上就存在问题
默认情况下,kafka 会使用三种方式来自动创建主题,下面是三种情况:
- 当一个生产者开始往主题写入消息时
- 当一个消费者开始从主题读取消息时
- 当任意一个客户端向主题发送元数据请求时
五、Kafka集群及副本的概念
1.搭建kafka集群, 2个broker
broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
使用如下命令来启动 2 台服务器
注意: 此kafka的安装依赖于zookeeper的安装,如果之前有安装过zookeeper, 不要重复使用, 重新创建新的zookeeper
前面安装过的zookeeper和kafka两个容器, 请删除掉, 重新创建zookeeper
安装zk
docker run --name some-zookeeper -dit -p 2181:2181 zookeeper
确保安装完成集群后, 至少还有800mb的剩余空间
注意: 两个kafka一个占用9092, 一个占用9093, 确保云服务防火墙中的两个端口都是放开的, 先开放防火墙
#节点1
docker run -d --name=kafka2 \
-p 9092:9092 \
-e ALLOW\_PLAINTEXT\_LISTENER=yes \
-e KAFKA\_CFG\_ZOOKEEPER\_CONNECT=服务器IP地址:2181 \
-e KAFKA\_BROKER\_ID=2 \
-e KAFKA\_NODE\_ID=2 \
-e KAFKA\_ENABLE\_KRAFT=false \
-e KAFKA\_HEAP\_OPTS="-Xmx180m -Xms180m" \
-e KAFKA\_ADVERTISED\_LISTENERS=PLAINTEXT://服务器IP地址:9092 \
-e KAFKA\_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
bitnami/kafka
# 节点2
docker run -d --name=kafka3 \
-p 9093:9092 \
-e ALLOW\_PLAINTEXT\_LISTENER=yes \
-e KAFKA\_CFG\_ZOOKEEPER\_CONNECT=服务器IP地址:2181 \
-e KAFKA\_BROKER\_ID=3 \
-e KAFKA\_NODE\_ID=3 \
-e KAFKA\_ENABLE\_KRAFT=false \
-e KAFKA\_HEAP\_OPTS="-Xmx180m -Xms180m" \
-e KAFKA\_ADVERTISED\_LISTENERS=PLAINTEXT://服务器IP地址:9093 \
-e KAFKA\_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
bitnami/kafka
参数释义:
- e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
- e KAFKA_ZOOKEEPER_CONNECT=服务器IP地址:2181 kafka 配置zookeeper
- e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 把kafka的地址端口注册给zookeeper
- e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口 是容器内部kafka占用的端口
- e KAFKA_HEAP_OPTS=“-Xmx180m -Xms180m” 设置kafka占用的内存
2.副本的概念
副本是对分区的备份。在集群中,不同的副本会被部署在不同的broker上。下面例子:创建 1个主题, 2 个分区、 2 个副本。
进入到kafka2容器中, 进入到bin目录下, 执行如下命令
./kafka-topics.sh --create --topic my-replicated-topic --bootstrap-server 服务器IP地址:9092 --replication-factor 2 --partitions 2
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --topic my-replicated-topic --describe
Topic: my-replicated-topic TopicId: eJ0M58k5RR6MwImWeHBebQ PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
通过查看topic信息,其中的关键数据:
- replicas:当前副本存在的broker节点
- leader:副本里的概念
- 每个partition都有一个broker作为leader。
- 消息发送方要把消息发给哪个broker?就看副本的leader是在哪个broker上面。副本里的leader专⻔用来接收消息。
- 接收到消息,其他follower通过poll的方式来同步数据。
isr: 可以同步的broker节点和已同步的broker节点,存放在isr集合中。
通过kill掉leader后再查看主题情况
# kill掉leader
docker stop kafka3
# 查看topic情况
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --topic my-replicated-topic --describe
运行结果:
Topic: my-replicated-topic TopicId: x61TtWHyTzCg1XlAcOQQ5w PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 3,2 Isr: 2
Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2
删除topic命令
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --delete --topic my-replicated-topic
查看当前topic有哪些
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 -list
3.broker、主题、分区、副本
- kafka集群中由多个broker组成
- 一个broker中存放一个topic的不同partition——副本
注意: 副本的数量不能超过集群节点的数量
向集群中的某个topic发送数据, 集群会首先计算出来这条数据归哪个patition存储, 确定了patition后, 存储到这个分区对应的leader中,随后,其他副本节点会将这条新的数据同步到自己的kafka副本中, 下面这张图演示的是, 3个broker, 一个topic1, topic1有2个分区, 3个副本
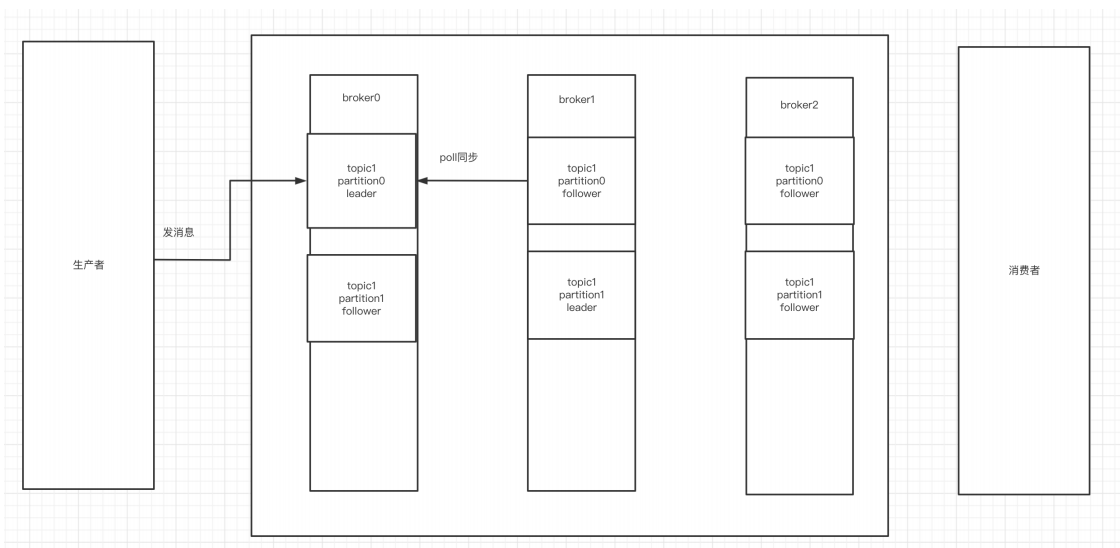
4.kafka集群消息的发送
💡 注意: 刚刚演示的kafka3被关闭了, 启动一下
创建topic
./kafka-topics.sh --create --topic my-replicated-topic --bootstrap-server 服务器IP地址:9092 --replication-factor 2 --partitions 2
发送数据
./kafka-console-producer.sh --broker-list 服务器IP地址:9092,服务器IP地址:9093 --topic my-replicated-topic
5.kafka集群消息的消费
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9092,服务器IP地址:9093 --from-beginning --topic my-replicated-topic
6.关于分区消费组消费者的细节
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9092,服务器IP地址:9093 --from-beginning --topic my-replicated-topic --consumer-property group.id=testGroup1
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9092 --describe --group testGroup1
##运行结果:
Consumer group 'testGroup1' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testGroup1 my-replicated-topic 0 3 3 0 - - -
testGroup1 my-replicated-topic 1 0 0 0 - - -
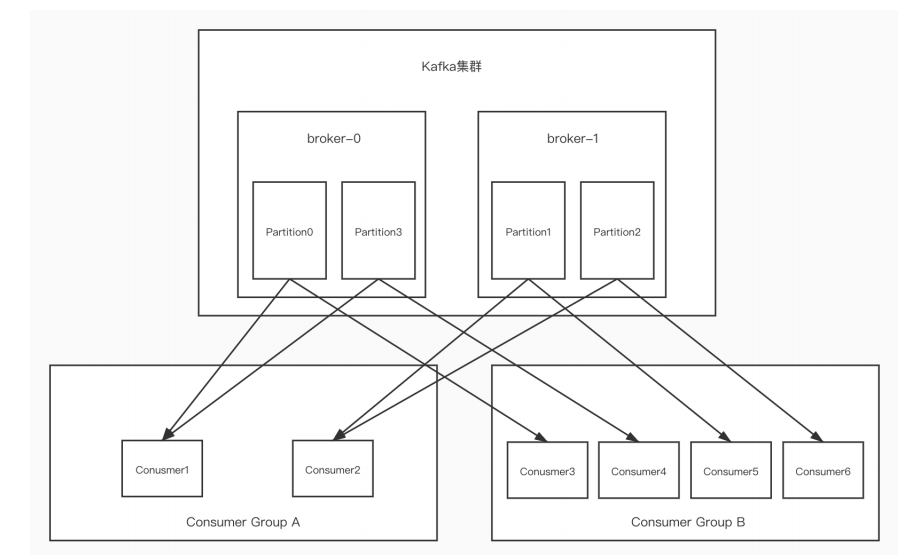
图中Kafka集群有两个broker,每个broker中有多个partition。一个partition只能被一个消费组里的某一个消费者消费,从而保证消费顺序。Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。一个消费者可以消费多个partition。
消费组中消费者的数量不能比一个topic中的partition数量多,否则多出来的消费者消费不到消息。
六、Kafka的Java客户端-生产者
1.引入依赖
kafka的maven依赖需要和docker安装的kafka版本对应上
进入到kafka容器中,查看kafka版本为3.5.1,所以Maven依赖的版本也为3.5.1
cd /opt/bitnami/kafka/libs
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>3.5.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
</dependencies>
2.生产者发送消息的基本实现
要向 Kafka 写入消息,首先需要创建一个生产者对象,并设置一些属性。Kafka 生产者有3个必选的属性
-
bootstrap.servers:该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其他的 broker 信息。不过建议至少要提供两个 broker 信息,一旦其中一个宕机,生产者仍然能够连接到集群上。 -
key.serializer:broker 需要接收到序列化之后的 key/value值,所以生产者发送的消息需要经过序列化之后才传递给 Kafka Broker。生产者需要知道采用何种方式把 Java 对象转换为字节数组。key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类,生产者会使用这个类把键对象序列化为字节数组。这里拓展一下 Serializer 类Serializer是一个接口,它表示类将会采用何种方式序列化,它的作用是把对象转换为字节,实现了 Serializer 接口的类主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默认使用的序列化器,其他的序列化器还有很多,你可以通过 这里 查看其他序列化器。要注意的一点:key.serializer 是必须要设置的,即使你打算只发送值的内容。
-
value.serializer:与 key.serializer 一样,value.serializer 指定的类会将值序列化。实现了org.apache.kafka.common.serialization.Serializer接口
此处属性详解参考文章Kafka 入门知识
/\*\*
\* 替代黑窗口中的生产者
\*/
public class KafkaProducerClient {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP\_SERVERS\_CONFIG, "服务器IP地址:9092,服务器IP地址:9093");
properties.setProperty(ProducerConfig.KEY\_SERIALIZER\_CLASS\_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE\_SERIALIZER\_CLASS\_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//String -> Object -> HashCode -> 这个字符串在内存中的地址值, 唯一值
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic", "hello, kafka3");
RecordMetadata recordMetadata = kafkaProducer.send(record).get();
System.out.println("recordMetadata = " + recordMetadata);
}
}
以上代码
- 首先创建了一个 Properties 对象
- 使用 StringSerializer 序列化器序列化 key / value 键值对
- 在这里我们创建了一个新的生产者对象,并为键值设置了恰当的类型,然后把 Properties 对象传递给他。
3.发送消息到指定分区上
最后
权威指南-第一本Docker书
引领完成Docker的安装、部署、管理和扩展,让其经历从测试到生产的整个开发生命周期,深入了解Docker适用于什么场景。并且这本Docker的学习权威指南介绍了其组件的基础知识,然后用Docker构建容器和服务来完成各种任务:利用Docker为新项目建立测试环境,演示如何使用持续集成的工作流集成Docker,如何构建应用程序服务和平台,如何使用Docker的API,如何扩展Docker。
总共包含了:简介、安装Docker、Docker入门、使用Docker镜像和仓库、在测试中使用Docker、使用Docker构建服务、使用Fig编配Docke、使用Docker API、获得帮助和对Docker进行改进等9个章节的知识。




关于阿里内部都在强烈推荐使用的“K8S+Docker学习指南”—《深入浅出Kubernetes:理论+实战》、《权威指南-第一本Docker书》,看完之后两个字形容,爱了爱了!
zer 序列化器序列化 key / value 键值对
- 在这里我们创建了一个新的生产者对象,并为键值设置了恰当的类型,然后把 Properties 对象传递给他。
3.发送消息到指定分区上
最后
权威指南-第一本Docker书
引领完成Docker的安装、部署、管理和扩展,让其经历从测试到生产的整个开发生命周期,深入了解Docker适用于什么场景。并且这本Docker的学习权威指南介绍了其组件的基础知识,然后用Docker构建容器和服务来完成各种任务:利用Docker为新项目建立测试环境,演示如何使用持续集成的工作流集成Docker,如何构建应用程序服务和平台,如何使用Docker的API,如何扩展Docker。
总共包含了:简介、安装Docker、Docker入门、使用Docker镜像和仓库、在测试中使用Docker、使用Docker构建服务、使用Fig编配Docke、使用Docker API、获得帮助和对Docker进行改进等9个章节的知识。
[外链图片转存中…(img-A6x71Gfs-1714140909216)]
[外链图片转存中…(img-mOl1cYEL-1714140909217)]
[外链图片转存中…(img-AjqmEdMC-1714140909217)]
[外链图片转存中…(img-xTKKfVQq-1714140909218)]
关于阿里内部都在强烈推荐使用的“K8S+Docker学习指南”—《深入浅出Kubernetes:理论+实战》、《权威指南-第一本Docker书》,看完之后两个字形容,爱了爱了!















 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









