







最后
这份《“java高分面试指南”-25分类227页1000+题50w+字解析》同样可分享给有需要的朋友,感兴趣的伙伴们可挑战一下自我,在不看答案解析的情况,测试测试自己的解题水平,这样也能达到事半功倍的效果!(好东西要大家一起看才香)


我们下面进行训练数据集、测试数据集的拆分工作(train_test_split)。
一般情况下我们按照0.8:0.2的比例进行拆分,但是有时候我们不能简单地把前n个数据作为训练数据集,后n个作为测试数据集。
比如下面这个,是有顺序的。

为了解决这个问题,我们可以将数据集打乱,做一个shuffle操作。但是本数据集的特征和标签是分开的,也就是说我们分别乱序后,原来的对应关系就不存在了。有两种方法解决这一问题:
-
将X和y合并为同一个矩阵,然后对矩阵进行shuffle,之后再分解
-
对y的索引进行乱序,根据索引确定与X的对应关系,最后再通过乱序的索引进行赋值
第一种方法
首先看第一种方法:
方法1# 使用concatenate函数进行拼接,因为传入的矩阵必须具有相同的形状。因此需要对label进行reshape操作,reshape(-1,1)表示行数自动计算,1列。axis=1表示纵向拼接。tempConcat = np.concatenate((X, y.reshape(-1,1)), axis=1)# 拼接好后,直接进行乱序操作np.random.shuffle(tempConcat)# 再将shuffle后的数组使用split方法拆分shuffle_X,shuffle_y = np.split(tempConcat, [4], axis=1)# 设置划分的比例test_ratio = 0.2test_size = int(len(X) * test_ratio)
X_train = shuffle_X[test_size:]
y_train = shuffle_y[test_size:]
X_test = shuffle_X[:test_size]
y_test = shuffle_y[:test_size]
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(120, 4)
(30, 4)
(120, 1)
(30, 1)
第二种方法
方法2# 将x长度这么多的数,返回一个新的打乱顺序的数组,注意,数组中的元素不是原来的数据,而是混乱的索引shuffle_index = np.random.permutation(len(X))# 指定测试数据的比例test_ratio = 0.2test_size = int(len(X) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(120, 4)
(30, 4)
(120,)
(30,)
1.3 编写自己的train_test_split
下面我们将编写自己的train_test_split,并封装成方法。
编写
还记得我们的github上的工程吗?https://github.com/japsonzbz/ML_Algorithms
编写一个自己的train_test_split方法。这个方法可以放到model——selection.py下。因为分割训练集和测试集合,可以帮助我们测试机器学习性能,能够帮助我们更好地选择模型。
import numpy as npdef train_test_split(X, y, test_ratio=0.2, seed=None):
“”“将矩阵X和标签y按照test_ration分割成X_train, X_test, y_train, y_test”“”
assert X.shape[0] == y.shape[0], \ “the size of X must be equal to the size of y”
assert 0.0 <= test_ratio <= 1.0, \ “test_train must be valid”
if seed: # 是否使用随机种子,使随机结果相同,方便debug
np.random.seed(seed) # permutation(n) 可直接生成一个随机排列的数组,含有n个元素
shuffle_index = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index] return X_train, X_test, y_train, y_test
调用
from myAlgorithm.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(120, 4)
(30, 4)
(120,)
(30,)
再得到分割好的训练数据集和测试数据集以后,下面将其应用于kNN算法中。
我们可以简单验证一下,X_train, y_train通过fit传入算法,然后对X_test做预测,得到y_predict。
然后我们可以直观地把y_predict和实际的结果y_test进行一个比较,看有多少个元素一样。当然我们也可以自己计算一下正确率
from myAlgorithm.kNN import kNNClassifier
my_kNNClassifier = kNNClassifier(k=3)
my_kNNClassifier.fit(X_train, y_train)
y_predict = my_kNNClassifier.predict(X_test)
y_predict
y_test# 两个向量的比较,返回一个布尔型向量,对这个布尔向量(faluse=1,true=0)sum,sum(y_predict == y_test)29sum(y_predict == y_test)/len(y_test)0.96666666666667
1.4 sklearn中的train_test_split
我们自己写的train_test_split其实也是在模仿sklearn风格,更多的时候我们可以直接调用。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(112, 4)
(38, 4)
(112,)
(38,)
0x02 分类准确度accuracy
在划分出测试数据集后,我们就可以验证其模型准确率了。在这了引出一个非常简单且常用的概念:accuracy(分类准确度)
accuracy_score:函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)
因accuracy定义清洗、计算方法简单,因此经常被使用。但是它在某些情况下并不一定是评估模型的最佳工具。精度(查准率)和召回率(查全率)等指标对衡量机器学习的模型性能在某些场合下要比accuracy更好。
当然这些指标在后续都会介绍。在这里我们就使用分类精准度,并将其作用于一个新的手写数字识别分类算法上。
2.1 数据探索
import numpy as npimport matplotlibimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# 手写数字数据集,封装好的对象,可以理解为一个字段digits = datasets.load_digits()# 可以使用keys()方法来看一下数据集的详情digits.keys()
输出:dict_keys([‘data’, ‘target’, ‘target_names’, ‘images’, ‘DESCR’])
我们可以看一下sklearn.datasets提供的数据描述:
5620张图片,每张图片有64个像素点即特征(8*8整数像素图像),每个特征的取值范围是1~16(sklearn中的不全),对应的分类结果是10个数字print(digits.DESCR)
下面我们根据datasets提供的方法,进行简单的数据探索。
特征的shapeX = digits.data
X.shape
(1797, 64)# 标签的shapey = digits.target
y.shape
(1797, )# 标签分类digits.target_names
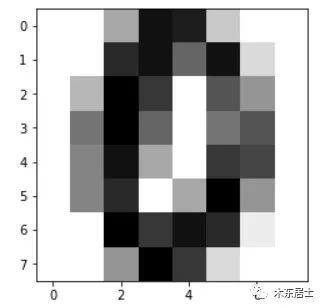
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])# 去除某一个具体的数据,查看其特征以及标签信息some_digit = X[666]
some_digit
array([ 0., 0., 5., 15., 14., 3., 0., 0., 0., 0., 13., 15., 9.,15., 2., 0., 0., 4., 16., 12., 0., 10., 6., 0., 0., 8.,16., 9., 0., 8., 10., 0., 0., 7., 15., 5., 0., 12., 11.,0., 0., 7., 13., 0., 5., 16., 6., 0., 0., 0., 16., 12.,15., 13., 1., 0., 0., 0., 6., 16., 12., 2., 0., 0.])
y[666]0# 也可以这条数据进行可视化some_digmit_image = some_digit.reshape(8, 8)
plt.imshow(some_digmit_image, cmap = matplotlib.cm.binary)
plt.show()
2.2 自己实现分类准确度
在分类任务结束后,我们就可以计算分类算法的准确率。其逻辑如下:
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)# 比对y_predict和y_test结果是否一致sum(y_predict == y_test) / len(y_test)0.9955555555555555
下面我们在我们自己的工程文件中添加一个metrics.py,用来度量性能的各种指标。
import numpy as npfrom math import sqrtdef accuracy_score(y_true, y_predict):
“”“计算y_true和y_predict之间的准确率”“”
assert y_true.shape[0] != y_predict.shape[0], \ “the size of y_true must be equal to the size of y_predict”
return sum(y_true == y_predict) / len(y_true)
这样以后就不用一遍遍地写逻辑了,直接调用我们写好的封装函数。我们再调用一下:
from myAlgorithm.metrics import accuracy_score
accuracy_score(y_test, y_predict)
但在实际情况下,我们有时可能还有这样的需求:用classifier将我们的预测值y_predicr预测出来了,再去看和真值的比例。但是有时候我们对预测值y_predicr是多少不感兴趣,我们只对模型的准确率感兴趣。
可以在kNN算法模型中进一步封装一个函数(完整代码见https://github.com/japsonzbz/ML_Algorithms)
def score(self, X_test, y_test):
“”“根据X_test进行预测, 给出预测的真值y_test,计算预测算法的准确度”“”
y_predict = self.predict(X_test) return accuracy_score(y_test, y_predict)
然后我们就可以直接运行着这命令,直接测出模型分类准确度:
my_knn_clf.score(X_test, y_test)
2.3 sklearn中的准确度
更多的时候,我们还是使用sklearn中封装好的方法。我们自己实现一遍,其实是简化版的,只是帮助我们更好地了解其底层原理。
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
accuracy_score(y_test, y_predict)
输出:0.9888888888888889# 不看y_predictknn_clf.score(X_test,y_test)
输出:0.9888888888888889
0x03 超参数
3.1 超参数简介
之前我们都是为knn算法传一个默认的k值。在具体使用时应该传递什么值合适呢?
这就涉及了机器学习领域中的一个重要问题:超参数。所谓超参数,就是在机器学习算法模型执行之前需要指定的参数。(调参调的就是超参数) 如kNN算法中的k。
与之相对的概念是模型参数,即算法过程中学习的属于这个模型的参数(kNN中没有模型参数,回归算法有很多模型参数)
如何选择最佳的超参数,这是机器学习中的一个永恒的问题。在实际业务场景中,调参的难度大很多,一般我们会业务领域知识、经验数值、实验搜索等方面获得最佳参数。
3.2 寻找好的k
Kafka进阶篇知识点

Kafka高级篇知识点

44个Kafka知识点(基础+进阶+高级)解析如下

由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**
验数值、实验搜索等方面获得最佳参数。
3.2 寻找好的k
Kafka进阶篇知识点
[外链图片转存中…(img-v9frZA3Y-1715606920761)]
Kafka高级篇知识点
[外链图片转存中…(img-Xw3TGAQb-1715606920762)]
44个Kafka知识点(基础+进阶+高级)解析如下
[外链图片转存中…(img-ze6qoSiB-1715606920762)]
由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









