






隐语课程第9课,是由来自隐语团队的周金金老师做的实战分享,这次分享可谓干货多多,都是一线开发者在实际开发过程中可能遇到的问题。对视频看了多遍,其中涉及到很多思考的内容,对自身理解隐语开发、明文算法迁移到密文算法有进一步帮助,感谢!
接下来会逐步分析周金金老师的分享内容,来推进介绍本轮课程的核心:明文算法迁移密文算法的实践。
一、角色视角差异
对于PPML,涉及两个方面,PP + ML,如何去弥补这两种不同技术之间的认知鸿沟?机器学习领域一般比较关注模型的训练、不同优化器的使用、不同的模型结构等,而隐私计算一般关注底层的基础密文算子(加减乘除+比较+逻辑运算等)、恶意/诚实模型、隐私计算协议、模运算。

SPU是解决这两者鸿沟的一种可行技术解。首先其提供了原生的主流AI前端,对于机器学习专家的额外学习成本低,复用AI框架前端能力(如自动求导),编程语言为python。其次,SPU自带面向隐私保护场景的编译器,支持带隐私保护语义的IR,复用AI框架的部分编译优化以及MPC语义下的独占优化和翻译。最后在运行时,可以支持多并发计算、多种安全多方计算协议(semi2k、cheetah、aby3)以及透明的部署方式。具体对SPU的分析,可以参考我之前的文章:隐语课程学习笔记8-理解密态引擎SPU框架
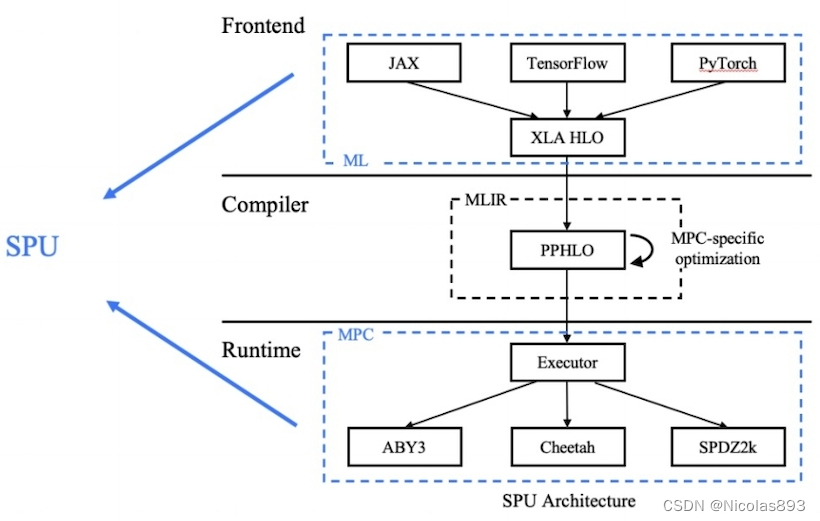
二、浮点数与定点数差异
为什么要了解这两种不同数值表示的差异呢?因为安全多方计算中,一般是基于定点数来执行计算的,首先会将浮点型数值转换成定点数后再进行MPC算子计算。了解浮点数与定点数的关系,对后续基于SPU实现PPML或者联合统计等算法出现结果异常时,会明白一些问题存在的原因,以及如何排查。另外,需要注意,以8bit环来举例,虽然正常来说定点数的取值范围为,但在SPU中,为了基于MSB的比较能正常工作,定点数取值范围设置为了
。

定点数相对于浮点数,在MPC中有明显的计算优势,计算相对简单(整数运算,低次多项式)。当然也有一些需要注意的点,比如精度较低(一般需要设置更大的环和fixed point来应对),乘法依赖truncation,数学函数一般需要使用近似解。

三、明文算法迁移流程
周金金老师给出了详细的明文算法迁移流程。在隐语SPU框架下,对于将明文算法改造成密文算法,有了较为清晰的感知。
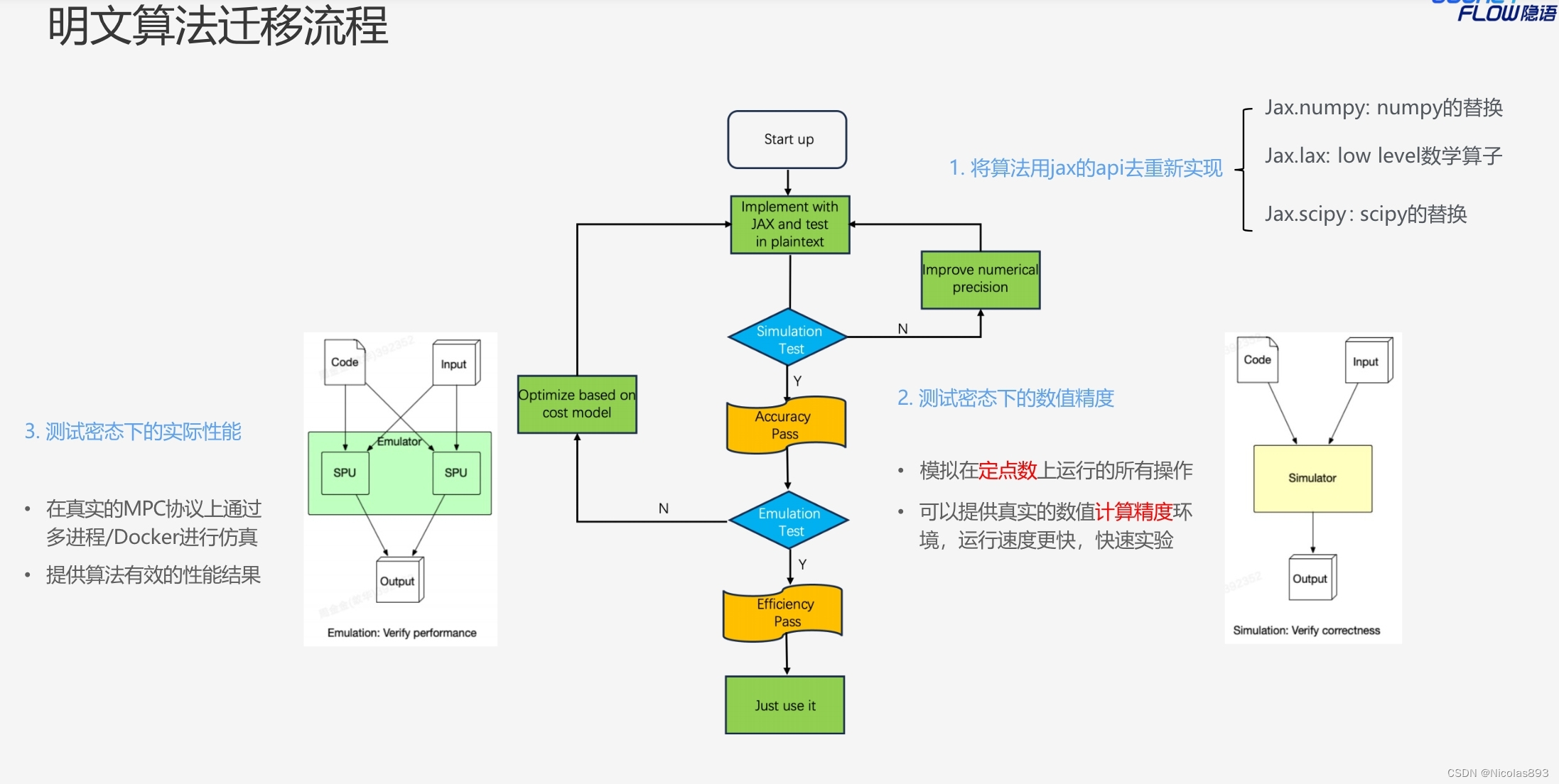
步骤如下:
1. 将明文算法用JAX的api重新实现
JAX(Just Another XLA)是Google开发的一个用于高性能数值计算和机器学习的开源软件库,提供用于构建、训练和执行高效、可扩展的数值计算和机器学习模型的编程接口。提供与 NumPy 非常相似的编程接口,所以上手应该很快。在明文代码下可以先做一下算法的准确性验证。
Step1.1: 使用JAX实现算法; Step1.2: 修改的一些见解介绍(优化) Step1.3:明文下精度验证

2. SPU下验证精度(simulation test)
Step2.1: 定义simulator(包括定义mpc协议、环大小、定点数参数fxp(fxp_fraction_bits))
Step2.2: 定义运行函数
Step2.3: 运行密态程序(评估精度是否满足预期)
Step2.4: 分析和定位问题

如果精度不能满足预期,需要进一步分析问题原因。可以从两个角度出发分析:
(1)算法本身问题分析(参数设置、学习问题等);(2)从MPC角度分析(比如数值溢出)

3. SPU下验证性能(emulation)
在真实的MPC协议上通过多进程/docker进行仿真,输出算法有效的性能结果。
Step3.1: 定义emulator;
Step3.2: 准备数据(需要做数据做seal,使得后续能够被作为密文数据对待);
Step3.3: 运行程序
Step3.4: 根据cost profile进行性能优化(可以通过通信次数、使用的底层算子及耗时等分析),
调整为对mpc友好的实现方案

四、常见问题分析
对于一些常见的问题做了分析。其中关于密态算法优化的思考对于后续开发算法值得多次品读。
Q:如何对密态算法进行优化?
A:有以下几个思路可以参考:
- 1.减少耗时算子的调用(计算公式重写,多项式近似等)
- 2.避免重复计算(空间换效率)
- 3.并行化,SPU内部已经做了大量的并行操作,若希望进一步优化,可以尝试:
1.算法层:for循环很多时候可以通过高阶tensor运算来代替,也可以考虑使用jax.vmap进行
自动向量化
2.Runtime:尝试开启更多并行(experimental feature),如
experimiental_enable_inter_op_par (即DAG并行)


五、实操篇(明文算子迁移的实践)

5.1 题目分析
Q:何为MPC-friendly?
A:“MPC friendly”意味着算法在多方计算环境中具有良好的性能和安全性,能够高效、安全地完成计算任务。具体指在多方计算(Multi-Party Computation,简称MPC)协议中,设计的算法或协议具有良好的特性,适合在MPC环境中高效、安全地执行。MPC是一种密码学技术,允许多个参与方在不泄露各自输入的情况下,共同计算一个函数的值。
算法需要具备以下特性:
- 低通信复杂度:在MPC中,参与方之间需要频繁交换信息。如果通信复杂度过高,会导致计算过程缓慢且成本高。因此,MPC friendly的算法应尽量减少参与方之间的信息交换量。
- 低计算复杂度:参与方的计算开销应尽可能低,以提高整体计算效率。这包括优化算法的时间复杂度和空间复杂度。
- 易于分割和并行化:算法应能够自然地分割成多个部分,使得每个参与方只需处理一部分数据。这种特性便于并行计算,有助于提升计算速度。
- 安全性:算法应能够抵抗各种可能的攻击,包括被动攻击(窃取信息)和主动攻击(篡改数据)。在MPC环境中,安全性至关重要,因为任何泄露或篡改都可能导致整个计算的结果不可信。
- 兼容性:算法应能够兼容现有的MPC协议和框架,使其能够容易地集成到现有系统中。
5.2 实际操作
1.先配置下secretnote环境
为了方便设置网络参数,我们在docker-compose.yml增加cap add: NET_ADMIN。
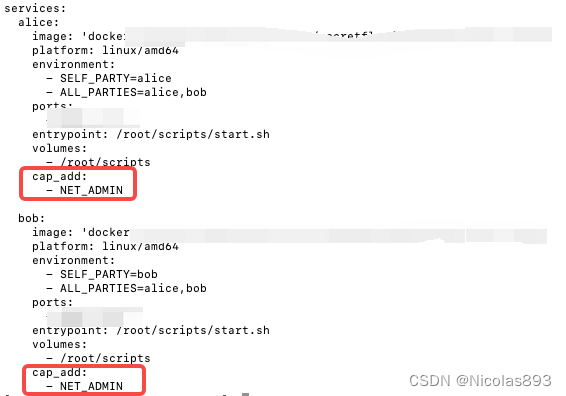
使用docker compose up启动alice和bob两个docker节点。
2. 首先使用jax实现新的digitize函数
digitize函数是一个常见的数值处理函数,用于将连续的数值数据转换为离散的分箱或分类索引值。
 虽然jax有自带的digitize函数,但实现上不一定适合直接在mpc下使用,因为其采用二分查找的方式进行,在mpc下会涉及大量的比较判断、乘法计算等。
虽然jax有自带的digitize函数,但实现上不一定适合直接在mpc下使用,因为其采用二分查找的方式进行,在mpc下会涉及大量的比较判断、乘法计算等。
我们直接使用SPU翻译的方式,测试一下这个算子的性能。 我们还是一步步来。
(1)首先定义明文算子,因为是已经自带了,所以可以直接使用,结果没问题。
x = np.array([0.0, 0.2, 6.4, 3.0, 1.6, 12.0])
bins = np.array([0.0, 1.0, 2.5, 4.0, 10.0])
jnp.digitize(x, bins)
(2)使用simulation test验证spu下的任务执行,可以看到整体的通信量62632bytes, 发送次数为2420次,非常夸张,直接用自带的digitize,对于mpc非常不友好。

(3)显然直接采用翻译的方式,得到的digitize执行效率比较差。因此我们需要重写该函数,可以看到结果也是正确的。
def refined_digitize(x, bins):
# 矢量化,比较x和bins的元素,得到一个布尔矩阵
com = x.reshape(*x.shape, -1) >= bins
# 统计x中大于等于bins的元素个数
return jnp.sum(com, axis=-1)
refined_digitize(x, bins)
3. 对优化后的明文digitize算子进行simulation test
(1)使用aby3协议测试
config_aby = spu.RuntimeConfig(
protocol=spu_pb2.ProtocolKind.ABY3,
field=spu.FieldType.FM64,
fxp_fraction_bits=18,
enable_hal_profile=True,
enable_pphlo_profile=True,
)
sim_aby = spsim.Simulator(3, config_aby)
print(spsim.sim_jax(sim_aby, refined_digitize)(x, bins))
print(x)
(2)使用semi2k协议测试
config_semi2k = spu.RuntimeConfig(
protocol=spu_pb2.ProtocolKind.SEMI2K,
field=spu.FieldType.FM64,
fxp_fraction_bits=18,
enable_hal_profile=True,
enable_pphlo_profile=True,
)
sim_semi2k = spsim.Simulator(2, config_semi2k)
print(spsim.sim_jax(sim_semi2k, refined_digitize)(x, bins))
(3)使用cheetah协议测试
config_cheetah = spu.RuntimeConfig(
protocol=spu_pb2.ProtocolKind.CHEETAH,
field=spu.FieldType.FM64,
fxp_fraction_bits=18,
enable_hal_profile=True,
enable_pphlo_profile=True,
)
sim_cheetah = spsim.Simulator(2, config_cheetah)
print(spsim.sim_jax(sim_cheetah, refined_digitize)(x, bins))
| MPC协议 | 算子 | 耗时 (s) | 通信量(bytes) | 通信次数 |
| aby3 | digitize | 0.003968 | 1376 | 13 |
| semi2k | digitize | 0.002636 | 1920 | 10 |
| cheetah | digitize | 1.55439 | 738839 | 2232 |
对比下来,发现semi2k在通信次数上是最优,aby3则是在通信量上最优。出乎意料的是,cheetah反而是最低效的,接下来需要进一步对照论文原理来查找原因。















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









