







print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(120, 4)
(30, 4)
(120,)
(30,)
1.3 编写自己的train_test_split
下面我们将编写自己的train_test_split,并封装成方法。
编写
还记得我们的github上的工程吗?https://github.com/japsonzbz/ML_Algorithms
编写一个自己的train_test_split方法。这个方法可以放到model——selection.py下。因为分割训练集和测试集合,可以帮助我们测试机器学习性能,能够帮助我们更好地选择模型。
import numpy as npdef train_test_split(X, y, test_ratio=0.2, seed=None):
“”“将矩阵X和标签y按照test_ration分割成X_train, X_test, y_train, y_test”“”
assert X.shape[0] == y.shape[0], \ “the size of X must be equal to the size of y”
assert 0.0 <= test_ratio <= 1.0, \ “test_train must be valid”
if seed: # 是否使用随机种子,使随机结果相同,方便debug
np.random.seed(seed) # permutation(n) 可直接生成一个随机排列的数组,含有n个元素
shuffle_index = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index] return X_train, X_test, y_train, y_test
调用
from myAlgorithm.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(120, 4)
(30, 4)
(120,)
(30,)
再得到分割好的训练数据集和测试数据集以后,下面将其应用于kNN算法中。
我们可以简单验证一下,X_train, y_train通过fit传入算法,然后对X_test做预测,得到y_predict。
然后我们可以直观地把y_predict和实际的结果y_test进行一个比较,看有多少个元素一样。当然我们也可以自己计算一下正确率
from myAlgorithm.kNN import kNNClassifier
my_kNNClassifier = kNNClassifier(k=3)
my_kNNClassifier.fit(X_train, y_train)
y_predict = my_kNNClassifier.predict(X_test)
y_predict
y_test# 两个向量的比较,返回一个布尔型向量,对这个布尔向量(faluse=1,true=0)sum,sum(y_predict == y_test)29sum(y_predict == y_test)/len(y_test)0.96666666666667
1.4 sklearn中的train_test_split
我们自己写的train_test_split其实也是在模仿sklearn风格,更多的时候我们可以直接调用。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
输出:(112, 4)
(38, 4)
(112,)
(38,)
0x02 分类准确度accuracy
在划分出测试数据集后,我们就可以验证其模型准确率了。在这了引出一个非常简单且常用的概念:accuracy(分类准确度)
accuracy_score:函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)
因accuracy定义清洗、计算方法简单,因此经常被使用。但是它在某些情况下并不一定是评估模型的最佳工具。精度(查准率)和召回率(查全率)等指标对衡量机器学习的模型性能在某些场合下要比accuracy更好。
当然这些指标在后续都会介绍。在这里我们就使用分类精准度,并将其作用于一个新的手写数字识别分类算法上。
2.1 数据探索
import numpy as npimport matplotlibimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# 手写数字数据集,封装好的对象,可以理解为一个字段digits = datasets.load_digits()# 可以使用keys()方法来看一下数据集的详情digits.keys()
输出:dict_keys([‘data’, ‘target’, ‘target_names’, ‘images’, ‘DESCR’])
我们可以看一下sklearn.datasets提供的数据描述:
5620张图片,每张图片有64个像素点即特征(8*8整数像素图像),每个特征的取值范围是1~16(sklearn中的不全),对应的分类结果是10个数字print(digits.DESCR)
下面我们根据datasets提供的方法,进行简单的数据探索。
特征的shapeX = digits.data
X.shape
(1797, 64)# 标签的shapey = digits.target
y.shape
(1797, )# 标签分类digits.target_names
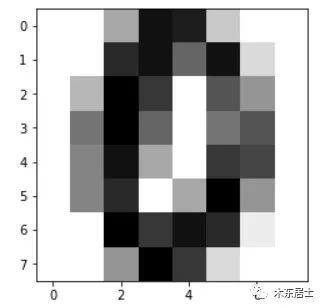
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])# 去除某一个具体的数据,查看其特征以及标签信息some_digit = X[666]
some_digit
array([ 0., 0., 5., 15., 14., 3., 0., 0., 0., 0., 13., 15., 9.,15., 2., 0., 0., 4., 16., 12., 0., 10., 6., 0., 0., 8.,16., 9., 0., 8., 10., 0., 0., 7., 15., 5., 0., 12., 11.,0., 0., 7., 13., 0., 5., 16., 6., 0., 0., 0., 16., 12.,15., 13., 1., 0., 0., 0., 6., 16., 12., 2., 0., 0.])
y[666]0# 也可以这条数据进行可视化some_digmit_image = some_digit.reshape(8, 8)
plt.imshow(some_digmit_image, cmap = matplotlib.cm.binary)
plt.show()
2.2 自己实现分类准确度
在分类任务结束后,我们就可以计算分类算法的准确率。其逻辑如下:
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)# 比对y_predict和y_test结果是否一致sum(y_predict == y_test) / len(y_test)0.9955555555555555
下面我们在我们自己的工程文件中添加一个metrics.py,用来度量性能的各种指标。
import numpy as npfrom math import sqrtdef accuracy_score(y_true, y_predict):
“”“计算y_true和y_predict之间的准确率”“”
assert y_true.shape[0] != y_predict.shape[0], \ “the size of y_true must be equal to the size of y_predict”
return sum(y_true == y_predict) / len(y_true)
这样以后就不用一遍遍地写逻辑了,直接调用我们写好的封装函数。我们再调用一下:
from myAlgorithm.metrics import accuracy_score
accuracy_score(y_test, y_predict)
但在实际情况下,我们有时可能还有这样的需求:用classifier将我们的预测值y_predicr预测出来了,再去看和真值的比例。但是有时候我们对预测值y_predicr是多少不感兴趣,我们只对模型的准确率感兴趣。
可以在kNN算法模型中进一步封装一个函数(完整代码见https://github.com/japsonzbz/ML_Algorithms)
def score(self, X_test, y_test):
“”“根据X_test进行预测, 给出预测的真值y_test,计算预测算法的准确度”“”
y_predict = self.predict(X_test) return accuracy_score(y_test, y_predict)
然后我们就可以直接运行着这命令,直接测出模型分类准确度:
my_knn_clf.score(X_test, y_test)
2.3 sklearn中的准确度
更多的时候,我们还是使用sklearn中封装好的方法。我们自己实现一遍,其实是简化版的,只是帮助我们更好地了解其底层原理。
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
accuracy_score(y_test, y_predict)
输出:0.9888888888888889# 不看y_predictknn_clf.score(X_test,y_test)
输出:0.9888888888888889
0x03 超参数
3.1 超参数简介
之前我们都是为knn算法传一个默认的k值。在具体使用时应该传递什么值合适呢?
这就涉及了机器学习领域中的一个重要问题:超参数。所谓超参数,就是在机器学习算法模型执行之前需要指定的参数。(调参调的就是超参数) 如kNN算法中的k。
与之相对的概念是模型参数,即算法过程中学习的属于这个模型的参数(kNN中没有模型参数,回归算法有很多模型参数)
如何选择最佳的超参数,这是机器学习中的一个永恒的问题。在实际业务场景中,调参的难度大很多,一般我们会业务领域知识、经验数值、实验搜索等方面获得最佳参数。
3.2 寻找好的k
针对于上一小节的手写数字识别分类代码,尝试寻找最好的k值。逻辑非常简单,就是设定一个初始化的分数,然后循环更新k值,找到最好的score
指定最佳值的分数,初始化为0.0;设置最佳值k,初始值为-1best_score = 0.0best_k = -1for k in range(1, 11): # 暂且设定到1~11的范围内
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test) if score > best_score:
best_k = k
best_score = score
print("best_k = ", best_k)
print("best_score = ", best_score)
输出:best_k = 4best_score = 0.9916666666666667
可以看到,最好的k值是4,在我们设定的k的取值范围中间。需要注意的是,如果我们得到的值正好在边界上,我们需要稍微扩展一下取值范围。因为嘛,你懂的!
3.2 另一个超参数:权重
在回顾kNN算法思想时,我们应该还记得,对于简单的kNN算法,只需要考虑最近的n个数据是什么即可。但是如果我们考虑距离呢?
如果我们认为,距离样本数据点最近的节点,对其影响最大,那么我们使用距离的倒数作为权重。假设距离样本点最近的三个节点分别是红色、蓝色、蓝色,距离分别是1、4、3。那么普通的k近邻算法:蓝色获胜。考虑权重(距离的倒数):红色:1,蓝色:1/3 + 1/4 = 7/12,红色胜。
在 sklearn.neighbors 的构造函数 KNeighborsClassifier 中有一个参数:weights,默认是uniform即不考虑距离,也可以写distance来考虑距离权重(默认是欧拉距离,如果要是曼哈顿距离,则可以写参数p(明可夫斯基距离的参数),这个也是超参数)
因为有两个超参数,因此使用双重循环,去查找最合适的两个参数,并打印。
两种方式进行比较best_method = ""best_score = 0.0best_k = -1for method in [“uniform”,“distance”]: for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method, p=2)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test) if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_method = ", method)
print("best_k = ", best_k)
print("best_score = ", best_score)
输出:best_method = distance
best_k = 4best_score = 0.9916666666666667
3.3 超参数网格搜索
在具体的超参数搜索过程中会需要很多问题,超参数过多、超参数之间相互依赖等等。如何一次性地把我们想要得到最好的超参数组合列出来。sklearn中专门封装了一个超参数网格搜索方法Grid Serach。
在进行网格搜索之前,首先需要定义一个搜索的参数param_search。是一个数组,数组中的每个元素是个字典,字典中的是对应的一组网格搜索,每一组网格搜索是这一组网格搜索每个参数的取值范围。键是参数的名称,值是键所对应的参数的列表。
param_search = [
{ “weights”:[“uniform”], “n_neighbors”:[i for i in range(1,11)]
},
{ “weights”:[“distance”], “n_neighbors”:[i for i in range(1,11)], “p”:[i for i in range(1,6)]
}
]
可以看到,当weights = uniform即不使用距离时,我们只搜索超参数k,当weights = distance即使用距离时,需要看超参数p使用那个距离公式。下面创建要进行网格搜索所对应的分类算法并调用刚哥搜索:
knn_clf = KNeighborsClassifier()# 调用网格搜索方法from sklearn.model_selection import GridSearchCV# 定义网格搜索的对象grid_search,其构造函数的第一个参数表示对哪一个分类器进行算法搜索,第二个参数表示网格搜索相应的参数grid_search = GridSearchCV(knn_clf, param_search)
下面就是针对X_train, y_train,使用grid_search在param_search列表中寻找最佳超参数组:
%%time
grid_search.fit(X_train, y_train)
输出:CPU times: user 2min 21s, sys: 628 ms, total: 2min 21s
Wall time: 2min 23s
GridSearchCV(cv=None, error_score=‘raise’,
estimator=KNeighborsClassifier(algorithm=‘auto’, leaf_size=30, metric=‘minkowski’,
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights=‘uniform’),
fit_params=None, iid=True, n_jobs=1,
param_grid=[{‘weights’: [‘uniform’], ‘n_neighbors’: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, {‘weights’: [‘distance’], ‘n_neighbors’: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], ‘p’: [1, 2, 3, 4, 5]}],
pre_dispatch=‘2*n_jobs’, refit=True, return_train_score=‘warn’,
scoring=None, verbose=0)
可以使用网格搜索的评估函数来返回最佳分类起所对应的参数
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!

Java经典面试问题(含答案解析)

阿里巴巴技术笔试心得

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。**
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!
[外链图片转存中…(img-tr28ClxC-1713735329757)]
Java经典面试问题(含答案解析)
[外链图片转存中…(img-Ubfd6hyq-1713735329757)]
阿里巴巴技术笔试心得
[外链图片转存中…(img-yQeMPjYO-1713735329758)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









