







### 3.主从复制的原理
'主从复制的原理'
1. 副本库(从库)通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库
2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3. 副本库接收后会应用RDB快照
4. 主库会陆续将中间产生的新的操作,保存并发送给副本库
5. 到此,我们主复制集就正常工作了
6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库.
7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在.
8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
'那么主从复制要不要开启持久化'
无论创不创建持久化,都可以开启主从,但是如果不开持久化,主库重启操作,会造成所有主从数据丢失!
### 4.主从搭建
#### 1)准备工作
'启动两个redis-server的进程,来模拟两台机器的两个redis进程'
' 也可以多个从库,复制从库配置即可,修改端口和保存文件的文件夹即可'
-准备两个配置文件
'配置文件1'
daemonize yes
bind 0.0.0.0
pidfile "/var/run/redis.pid"
requirepass "1234" # 主库密码,redis最好设置密码 ,设置redis登录密码 这个看自己需求可以不要
port 6379
dir "/root/redis-7.2.4/data"
logfile "6379.log"
appendonly yes
appendfilename "appendonly-6379.aof"
appendfsync everysec
no-appendfsync-on-rewrite yes
aof-use-rdb-preamble yes
-------------------------------
'配置文件2'
daemonize yes
bind 0.0.0.0
port 6380
dir "/root/redis-7.2.4/data1"
masterauth 1234 # 这里是主库的访问密码,主从认证密码,否则主从不能同步,这个看自己需求可以不要,如果不要就不能设置主库密码
logfile "6380.log"
appendonly yes
appendfilename "appendonly-6380.aof"
appendfsync everysec
no-appendfsync-on-rewrite yes
aof-use-rdb-preamble yes
'注意:如果两个配置都没有密码的情况下,可以直接操作,设置那个为从库,然后从库执行命令即可'
'如果有密码的情况,必须提前设置从库,然后在从库中设置主库的访问密码才可以,我这里设置了密码,所以需要先设置'
-启动两个进程(当前文件下)
reids-server ./redis.conf
reids-server ./redis_6380.conf
#### 2)方式一
-6379设置为主,6380设置为从
-链接到从库,执行:slaveof 127.0.0.1 6379
# 异步,因为我是一台机器做的模拟,所以链接本地地址,如果不同机器就写设置主库的机器的ip地址和端口
-info 可以查看主从关系
-主从既能查,又能写
-从库只能查
-flushall # 清空库数据
-断开主从关系(也是在从库执行命令):slaveof no one # 取消复制,不会把之前的数据清除
'一旦断开关系,那么从断开那刻开始,从库将接收不到主库数据,但是断开之前的数据任然保留着'
#### 3)方式二
通过配置文件
min-slaves-to-write 1
min-slaves-max-lag 3
#在从服务器的数量少于1个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
-核心配置通过配置文件
slaveof 127.0.0.1 6379
slave-read-only yes
'这种方式一配置好,从库就已经有主库的数据了'
### 5.python中操作
#### 1)原生操作
'原生操作'
-主:10.0.0.111::6379
-从:10.0.0.111::6380
-从:10.0.0.111::6381
'主库'
conn=10.0.0.111::6379
以后只 set mset rpush 操作
'从库'
conn1=10.0.0.111::6380
conn2=10.0.0.111::6381
只要是查询,随机从conn1和conn2中出
10.0.0.111
#### 2)Django的缓存操作
第一步:redis的配置中配置多个redis
CACHES = {
"default": {
"BACKEND": "django\_redis.cache.RedisCache",
"LOCATION": "redis://xxx.xxx.xxx.xxx:6379/1",
"OPTIONS": {
"CLIENT\_CLASS": "django\_redis.client.DefaultClient",
}
},
"redis1": {
"BACKEND": "django\_redis.cache.RedisCache",
"LOCATION": "redis://xxx.xxx.xxx.xxx:6379/0",
"OPTIONS": {
"CLIENT\_CLASS": "django\_redis.client.DefaultClient",
}
}
}
第二步:使用
from django.core.cache import caches
caches['default'].set("name",'jack') # 写
res=caches['redis1'].get('name') # 读
## 二、Redis哨兵(Redis-Sentinel)
### 1.主从复制存在的问题
主从复制存在的问题:
'当主从复制中,有一主多从的情况下,如果主库发生故障,那么整个就会崩掉,因为需要解决这个问题,所以就需要用到哨兵'
1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master
-使用哨兵来解决该问题
2 主从复制,只能主写数据,所以写能力和存储能力有限
-使用集群来解决该问题
### 2.哨兵(Redis-Sentinel)
#### 1)什么是哨兵
>
> 在主从模式下(主从模式就是把下图的所有哨兵去掉),master节点负责写请求,然后异步同步给slave节点,从节点负责处理读请求。如果master宕机了,需要手动将从节点晋升为主节点,并且还要切换客户端的连接数据源。这就无法达到高可用,而通过哨兵模式就可以解决这一问题。
>
>
>
>
> `哨兵模式是Redis的高可用方式,哨兵节点是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点`。 哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,`当redis的主节点挂掉时,哨兵会第一时间感知到,并且在slave节点中重新选出来一个新的master`,然后将新的master信息通知给client端,从而实现高可用。这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息。
>
>
>
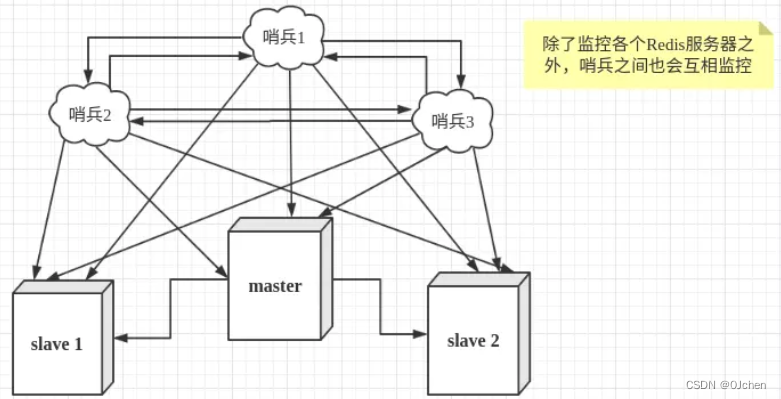
#### 2)架构说明
'可以做故障判断,故障转移,通知客户端(sentinal其实是一个进程),客户端直接连接sentinel的地址'
1 多个sentinel发现并确认master有问题(内部已经帮你实现了)
2 选举出一个sentinel作为领导(Raft算法(共识算法/选举算法))
3 选取一个slave作为新的master
4 通知其余slave成为新的master的slave
5 通知客户端主从变化
6 等待老的master复活成为新master的slave
'哨兵只需要配置文件配置好,上面的操作,可以自动实现'
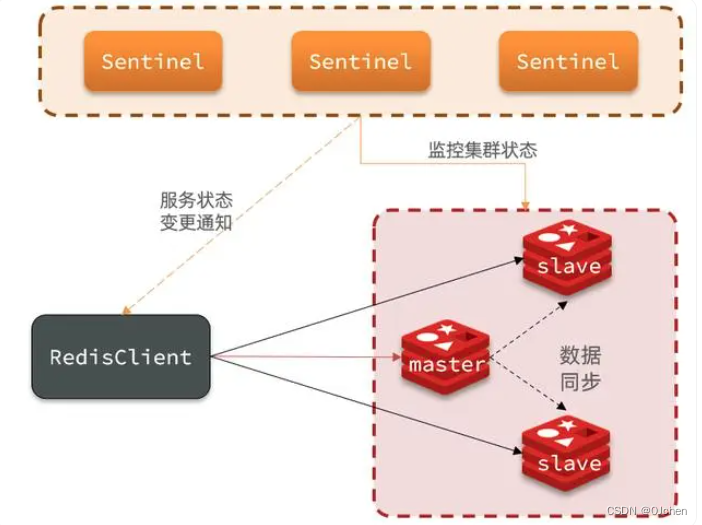
#### 3)搭建哨兵的目的
一旦一主多从的架构,主库发生故障,能够自动转移
一主多从架构的:高可用
-redis服务对外高度可用
-django服务项目是否是高可用的?
-nginx的转发(负载解决)
#### 4)哨兵的主要工作任务
(1)监控:哨兵会不断地检查你的Master和Slave是否运作正常。
(2)通知提醒:当被监控的某个Redis节点出现问题时,哨兵可以通过 API 向管理员或者其他应用程序发送通知。
(3)自动故障迁移:
当一个Master不能正常工作时,哨兵会进行自动故障迁移操作,将失效Master的其中一个Slave升级为新的Master,
并让失效Master的其他Slave改为复制新的Master;当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,
使得集群可以使用新Master代替失效Master。
### 3.哨兵的搭建
哨兵配置步骤:
'这里我就在一台机器上演示,做一主两从的(也可以搞更多都行)'
(启动三个哨兵,也就会开启三个进程)
-一台机器,启动三个sentinel
1.先搭建一主两从的配置(跟上面搭建主从复制差不多的配置)
# 记得得在当前路径下创建 data data1 data2 个文件夹,因为下面的配置文件中dir都需要一个文件夹
'第一个是主库配置文件'
daemonize yes
pidfile /var/run/redis.pid
port 6379
dir "/root/redis/data"
logfile “6379.log”
requirepass 1234 # 我配置的redis设置密码,再生产环境都是需要的
'第二个是从库配置文件'
daemonize yes
pidfile /var/run/redis2.pid
port 6380
dir "/root/redis/data1"
logfile “6380.log”
masterauth 1234 # 连接master密码,这里是主库的访问密码 '如果主库没有配置,就无需操作这个'
slaveof 127.0.0.1 6379
slave-read-only yes
'第三个是从库配置文件'
daemonize yes
pidfile /var/run/redis3.pid
port 6381
dir "/root/redis/data2"
logfile “6381.log”
masterauth 1234 # 连接master密码,这里是主库的访问密码
slaveof 127.0.0.1 6379
slave-read-only yes
2.启动三个redis服务(后台启动)
redis-server ./redis.conf
redis-server ./redis_6380.conf
redis-server ./redis_6381.conf
3.三个Sentinel配置
# sentinel.conf这个文件
# 把哨兵也当成一个redis服务器
创建三个配置文件分别叫sentinel_26379.conf sentinel_26380.conf sentinel_26381.conf
#内容如下(需要修改端口,文件地址日志文件名字)
'sentinel\_26379.conf sentinel\_26380.conf sentinel\_26381.conf'
-三个配置文件,改一下端口和dir即可
port 26379
daemonize yes
dir ./data
protected-mode no
bind 0.0.0.0
logfile "redis\_sentinel3.log"
sentinel auth-pass mymaster 1234 'redispass密码' # 连接master密码,如果主库有密码,就需要配置
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
4.启动哨兵
./src/redis-sentinel ./sentinel_26379.conf
./src/redis-sentinel ./sentinel_26380.conf
./src/redis-sentinel ./sentinel_26381.conf
5.查看哨兵是否正常启动
ps aux |grep redis # 可以看到有三个redis-server和三个哨兵
6.哨兵,客户端也可以链接
redis-cli -p 26379
-info # 查看
master0:name=mymaster,status=sdown,address=127.0.0.1:6379,slaves=2,sentinels=3
集群名字叫:mymaster,状态ok,主库是:127.0.0.1:6379,有两个从库,哨兵有三个
7.停止主库,启动哨兵,会故障转移,会从中选举一个从库,将之变成主库,而其他从库,复制现在的主库
-kill -9 主库服务的进程号# 杀进程
-pkill -9 redis # 批量杀,会把跟redis相关的都停止掉
-停止一个从库,是不会做转移
-即便原来的主库启动,它也是从库了
### 4.配置文件解释
配置文件解释
sentinel monitor mymaster 10.0.0.111 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
解释:
1.sentinel monitor mymaster:
-监控一个名为 mymaster 的主服务器,后面跟着主服务器的IP和端口,以及最少需要有多少个哨兵同意才进行故障转移。
-告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效
2.sentinel down-after-milliseconds:
-如果一个服务器在指定的毫秒数内没有响应,则认为它是主观下线。
-这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒
3.sentinel parallel-syncs:
-在故障转移期间,可以有几个从服务器同时进行同步。
-这个配置项指定了在发生主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成主备切换所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
4.sentinel failover-timeout: 故障转移超时时间
### 5.Python操作哨兵
‘’‘python操作哨兵’‘’
import redis
from redis.sentinel import Sentinel
‘’‘连接哨兵服务器(主机名也可以用域名)’‘’
192.168.200.100
sentinel = Sentinel([(‘192.168.200.100’, 26379),
(‘192.168.200.100’, 26380),
(‘192.168.200.100’, 26381)],
socket_timeout=5)
print(sentinel)
获取主服务器地址
master = sentinel.discover_master(‘mymaster’)
print(master)
获取从服务器地址
slave = sentinel.discover_slaves(‘mymaster’)
print(slave)
读写分离
获取主服务器进行写入
master = sentinel.master_for(‘mymaster’, socket_timeout=0.5)
w_ret = master.set(‘foo’, ‘bar’)
slave = sentinel.slave_for(‘mymaster’, socket_timeout=0.5)
r_ret = slave.get(‘foo’)
print(r_ret)
## 三、Redis集群(Redis Cluser)
### 1.Redis集群介绍背景
#### 1)主从与哨兵存在的问题
#1 主从---》提高并发量
#2 哨兵----》高可用
1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g,如果存500g数据呢?
#### 2)解决
解决:加机器,分布式
redis cluster 在2015年的 3.0 版本加入了,满足分布式的需求
### 2.数据分布(分布式数据库)
#### 1)存在问题
>
> 假设全量的数据非常大,500g,单机已经无法满足,我们需要进行分区,分到若干个子集中
>
>
>
#### 2)分区方案
| 分布方式 | 特点 | 产品 |
| --- | --- | --- |
| 哈希分布 | 数据分散度高,建值分布于业务无关,无法顺序访问,支持批量操作 | 一致性哈希memcache,redis cluster,其他缓存产品 |
| 顺序分布 | 数据分散度易倾斜,建值业务相关,可顺序访问,支持批量操作 | BigTable,HBase |
1.顺序分区
原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点(很多关系型数据库使用此种方式)
'数据分散度易倾斜,建值业务相关,可顺序访问,支持批量操作'
2.哈希分区
原理:hash分区: 节点取余 ,假设3台机器, hash(key)%3,落到不同节点上
'数据分散度高,建值分布于业务无关,无法顺序访问,支持批量操作 一致性哈希memcache,redis cluster,其他缓存产品'
节点取余分区:
缺点:节点扩容,添加一个节点,存在问题,很多数据需要偏移,总偏移量要大于80%,推荐翻倍扩容,由3变成6,数据量迁移为50%,比80%降低
一致性哈希分区
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响临近节点,但是还有数据迁移的情况
伸缩:保证最小迁移数据和无法保证负载均衡(这样总共5个节点,数据就不均匀了),翻倍扩容可以实现负载均衡
虚拟槽分区(redis集群)
预设虚拟槽:每个槽映射一个数据子集(16384个槽),一般比节点数大(redis集群不会超过16384台机器)
良好的哈希函数:如CRC16
服务端管理节点、槽、数据:如redis cluster(槽的范围0–16383)
5个节点,把16384个槽平均分配到每个节点,客户端会把数据发送给任意一个节点,通过CRC16对key进行哈希对16383进行取余,
算出当前key属于哪部分槽,属于哪个节点,每个节点都会记录是不是负责这部分槽,如果是负责的,进行保存,如果槽不在自己范围内,
redis cluster是共享消息的模式,它知道哪个节点负责哪些槽,返回结果,让客户端找对应的节点去存
服务端管理节点,槽,关系
### 3.集群搭建
'这里就演示,启动6个redis节点,一主一从架构 3个节点 存数据,每个有一个从库,做高可用'
搭建步骤:
1.第一步:写6个redis配置文件 (redis-7000 ------7005)
i redis-7000.conf
port 7000
daemonize yes
dir "/root/redis-7.2.4/data/"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage yes
2.第二步:快速生成剩余5个配置文件
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









