







2.3 Skip List算法性能分析
2.3.1 计算随机层数算法
首先分析的是执行插入操作时计算随机数的过程,这个过程会涉及层数的计算,所以十分重要。对于节点他有如下特性:
-
节点都有第一层的指针
-
节点有第i层指针,那么第i+1层出现的概率为p
-
节点有最大层数限制,MaxLevel
计算随机层数的伪代码:
论文中的示例
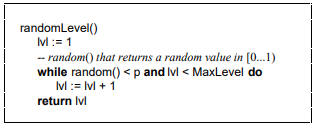
Java版本
1public int randomLevel(){
2 int level = 1;
3 // random()返回一个[0…1)的随机数
4 while (random() < p && level < MaxLevel){
5 level += 1;
6 }
7 return level;
8}
代码中包含两个变量P和MaxLevel,在Redis中这两个参数的值分别是:
1p = 1/4
2MaxLevel = 64
2.3.2 节点包含的平均指针数目
Skip List属于空间换时间的数据结构,这里的空间指的就是每个节点包含的指针数目,这一部分是额外的内内存开销,可以用来度量空间复杂度。random()是个随机数,因此产生越高的节点层数,概率越低(Redis标准源码中的晋升率数据1/4,相对来说Skip List的结构是比较扁平的,层高相对较低)。其定量分析如下:
-
level = 1 概率为1-p
-
level >=2 概率为p
-
level = 2 概率为p(1-p)
-
level >= 3 概率为p^2
-
level = 3 概率为p^2(1-p)
-
level >=4 概率为p^3
-
level = 4 概率为p^3(1-p)
-
……
得出节点的平均层数(节点包含的平均指针数目):
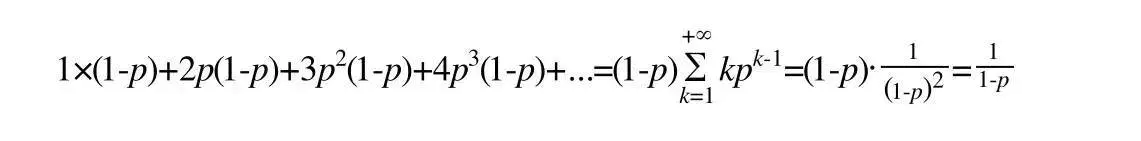
所以Redis中p=1/4计算的平均指针数目为1.33
2.3.3 时间复杂度计算
以下推算来自论文内容
假设p=1/2,在以p=1/2生成的16个元素的跳过列表中,我们可能碰巧具有9个元素,1级3个元素,3个元素3级元素和1个元素14级(这不太可能,但可能会发生)。我们该怎么处理这种情况?如果我们使用标准算法并在第14级开始我们的搜索,我们将会做很多无用的工作。那么我们应该从哪里开始搜索?此时我们假设SkipList中有n个元素,第L层级元素个数的期望是1/p个;每个元素出现在L层的概率是p^(L-1), 那么第L层级元素个数的期望是 n * (p^L-1);得到1 / p =n * (p^L-1)
11 / p = n * (p^L-1)
2n = (1/p)^L
3L = log(1/p)^n
所以我们应该选择MaxLevel = log(1/p)^n
定义:MaxLevel = L(n) = log(1/p)^n
推算Skip List的时间复杂度,可以用逆向思维,从层数为i的节点x出发,返回起点的方式来回溯时间复杂度,节点x点存在两种情况:
-
节点x存在(i+1)层指针,那么向上爬一级,概率为p,对应下图situation c.
-
节点x不存在(i+1)层指针,那么向左爬一级,概率为1-p,对应下图situation b.
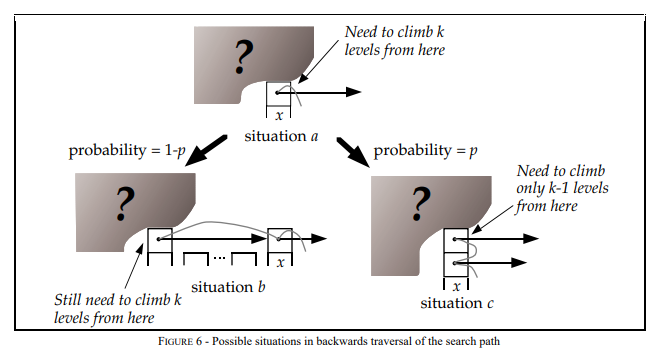
设C(k) = 在无限列表中向上攀升k个level的搜索路径的预期成本(即长度)那么推演如下:
1C(0)=0
2C(k)=(1-p)×(情况b的查找长度) + p×(情况c的查找长度)
3C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
4C(k)=1/p+C(k-1)
5C(k)=k/p
上面推演的结果可知,爬升k个level的预期长度为k/p,爬升一个level的长度为1/p。
由于MaxLevel = L(n), C(k) = k / p,因此期望值为:(L(n) – 1) / p;将L(n) = log(1/p)^n 代入可得:(log(1/p)^n - 1) / p;将p = 1 / 2 代入可得:2 * log2^n - 2,即O(logn)的时间复杂度。
三、Skip List特性及其实现
3.1 Skip List特性
Skip List跳跃列表通常具有如下这些特性
-
Skip List包含多个层,每层称为一个level,level从0开始递增
-
Skip List 0层,也就是最底层,应该包含所有的元素
-
每一个level/层都是一个有序的列表
-
level小的层包含level大的层的元素,也就是说元素A在X层出现,那么 想X>Z>=0的level/层都应该包含元素A
-
每个节点元素由节点key、节点value和指向当前节点所在level的指针数组组成
3.2 Skip List查询
假设初始Skip List跳跃列表中已经存在这些元素,他们分布的结构如下所示:
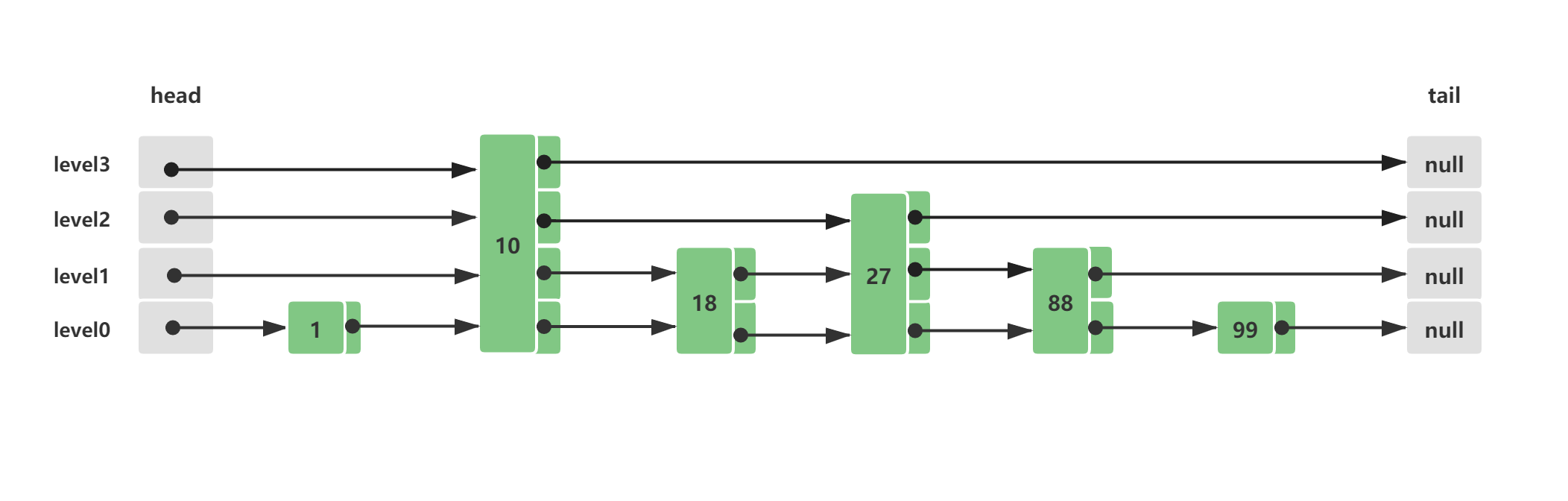
此时查询节点88,它的查询路线如下所示:
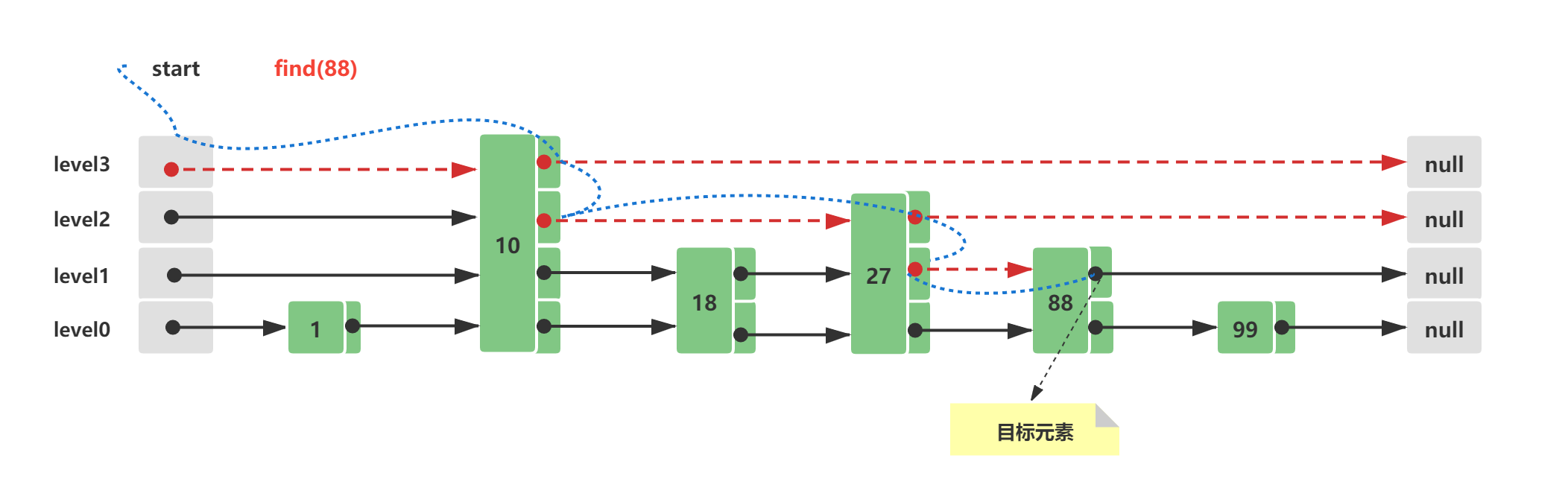
-
从Skip List跳跃列表最顶层level3开始,往后查询到10 < 88 && 后续节点值为null && 存在下层level2
-
level2 10往后遍历,27 < 88 && 后续节点值为null && 存在下层level1
-
level1 27往后遍历,88 = 88,查询命中
3.3 Skip List插入
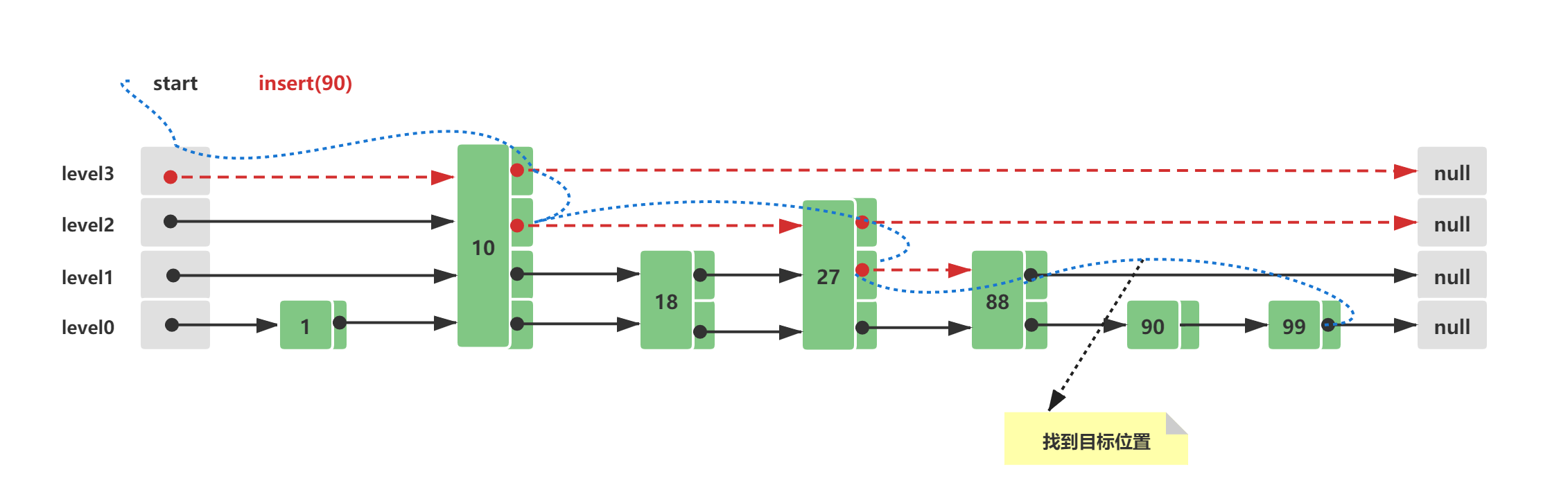
Skip List的初始结构与2.3中的初始结构一致,此时假设插入的新节点元素值为90,插入路线如下所示:
-
查询插入位置,与Skip List查询方式一致,这里需要查询的是第一个比90大的节点位置,插入在这个节点的前面, 88 < 90 < 100
-
构造一个新的节点Node(90),为插入的节点Node(90)计算一个随机level,这里假设计算的是1,这个level时随机计算的,可能时1、2、3、4…均有可能,level越大的可能越小,主要看随机因子x ,层数的概率大致计算为 (1/x)^level ,如果level大于当前的最大level3,需要新增head和tail节点
-
节点构造完毕后,需要将其插入列表中,插入十分简单步骤 -> Node(88).next = Node(90); Node(90).prev = Node(80); Node(90).next = Node(100); Node(100).prev = Node(90);
3.4 Skip List删除
删除的流程就是查询到节点,然后删除,重新将删除节点左右两边的节点以链表的形式组合起来即可,这里不再画图
四、手写实现一个简单Skip List
实现一个Skip List比较简单,主要分为两个步骤:
-
定义Skip List的节点Node,节点之间以链表的形式存储,因此节点持有相邻节点的指针,其中prev与next是同一level的前后节点的指针,down与up是同一节点的多个level的上下节点的指针
-
定义Skip List的实现类,包含节点的插入、删除、查询,其中查询操作分为升序查询和降序查询(往后和往前查询),这里实现的Skip List默认节点之间的元素是升序链表
3.1 定义Node节点
Node节点类主要包括如下重要属性:
-
score -> 节点的权重,这个与Redis中的score相同,用来节点元素的排序作用
-
value -> 节点存储的真实数据,只能存储String类型的数据
-
prev -> 当前节点的前驱节点,同一level
-
next -> 当前节点的后继节点,同一level
-
down -> 当前节点的下层节点,同一节点的不同level
-
up -> 当前节点的上层节点,同一节点的不同level
1package com.liziba.skiplist;
2
3/**
4 *
5 * 跳表节点元素
6 *
7 *
8 * @Author: Liziba
9 * @Date: 2021/7/5 21:01
10 */
11public class Node {
12
13 /** 节点的分数值,根据分数值来排序 */
14 public Double score;
15 /** 节点存储的真实数据 */
16 public String value;
17 /** 当前节点的 前、后、下、上节点的引用 */
18 public Node prev, next, down, up;
19
20 public Node(Double score) {
21 this.score = score;
22 prev = next = down = up = null;
23 }
24
25 public Node(Double score, String value) {
26 this.score = score;
27 this.value = value;
28 }
29}
3.2 SkipList节点元素的操作类
SkipList主要包括如下重要属性:
-
head -> SkipList中的头节点的最上层头节点(level最大的层的头节点),这个节点不存储元素,是为了构建列表和查询时做查询起始位置的,具体的结构请看2.3中的结构
-
tail -> SkipList中的尾节点的最上层尾节点(level最大的层的尾节点),这个节点也不存储元素,是查询某一个level的终止标志
-
level -> 总层数
-
size -> Skip List中节点元素的个数
-
random -> 用于随机计算节点level,如果 random.nextDouble() < 1/2则需要增加当前节点的level,如果当前节点增加的level超过了总的level则需要增加head和tail(总level)
1package com.liziba.skiplist;
2
3import java.util.Random;
4
5/**
6 *
7 * 跳表实现
8 *
9 *
10 * @Author: Liziba
11 */
12public class SkipList {
13
14 /** 最上层头节点 */
15 public Node head;
16 /** 最上层尾节点 */
17 public Node tail;
18 /** 总层数 */
19 public int level;
20 /** 元素个数 */
21 public int size;
22 public Random random;
23
24 public SkipList() {
25 level = size = 0;
26 head = new Node(null);
27 tail = new Node(null);
28 head.next = tail;
29 tail.prev = head;
30 }
31
32 /**
33 * 查询插入节点的前驱节点位置
34 *
35 * @param score
36 * @return
37 */
38 public Node fidePervNode(Double score) {
39 Node p = head;
40 for(;😉 {
41 // 当前层(level)往后遍历,比较score,如果小于当前值,则往后遍历
42 while (p.next.value == null && p.prev.score <= score)
43 p = p.next;
44 // 遍历最右节点的下一层(level)
45 if (p.down != null)
46 p = p.down;
47 else
48 break;
49 }
50 return p;
51 }
52
53 /**
54 * 插入节点,插入位置为fidePervNode(Double score)前面
55 *
56 * @param score
57 * @param value
58 */
59 public void insert(Double score, String value) {
60
61 // 当前节点的前置节点
62 Node preNode = fidePervNode(score);
63 // 当前新插入的节点
64 Node curNode = new Node(score, value);
65 // 分数和值均相等则直接返回
66 if (curNode.value != null && preNode.value != null && preNode.value.equals(curNode.value)
67 && curNode.score.equals(preNode.score)) {
68 return;
69 }
70
71 preNode.next = curNode;
72 preNode.next.prev = curNode;
73 curNode.next = preNode.next;
74 curNode.prev = preNode;
75
76 int curLevel = 0;
77 while (random.nextDouble() < 1/2) {
78 // 插入节点层数(level)大于等于层数(level),则新增一层(level)
79 if (curLevel >= level) {
80 Node newHead = new Node(null);
最后
题外话,我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在IT学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多程序员朋友无法获得正确的资料得到学习提升,故此将并将重要的Android进阶资料包括自定义view、性能优化、MVC与MVP与MVVM三大框架的区别、NDK技术、阿里面试题精编汇总、常见源码分析等学习资料。
【Android思维脑图(技能树)】
知识不体系?这里还有整理出来的Android进阶学习的思维脑图,给大家参考一个方向。

【Android进阶学习视频】、【全套Android面试秘籍】
希望我能够用我的力量帮助更多迷茫、困惑的朋友们,帮助大家在IT道路上学习和发展
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!
Node newHead = new Node(null);
最后
题外话,我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在IT学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多程序员朋友无法获得正确的资料得到学习提升,故此将并将重要的Android进阶资料包括自定义view、性能优化、MVC与MVP与MVVM三大框架的区别、NDK技术、阿里面试题精编汇总、常见源码分析等学习资料。
【Android思维脑图(技能树)】
知识不体系?这里还有整理出来的Android进阶学习的思维脑图,给大家参考一个方向。
[外链图片转存中…(img-hD3Y7NyA-1715425268470)]
【Android进阶学习视频】、【全套Android面试秘籍】
希望我能够用我的力量帮助更多迷茫、困惑的朋友们,帮助大家在IT道路上学习和发展
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









