







==============================================================================
import urllib.request # 导入urllib.request模块
url= ‘xxxxxxxxxxxxxxx’
创建代理IP
proxy_handler = urllib.request.ProxyHandler({
‘https’: ‘xxxxxxxxxxxxxxxxx’ # 写入代理IP
})
创建opener对象
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(url,timeout=2)
print(response.read().decode(‘utf-8’))
=============================================================================
urllib模块中的urllib.error子模块包含了URLError与HTTPError两个比较重要的异常类。
URLError类提供了一个reason属性,可以通过这个属性了解错误的原因。示例如下:
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
向不存在的网络地址发送请求
response = urllib.request.urlopen(‘https://www.python.org/1111111111.html’)
except urllib.error.URLError as error: # 捕获异常信息
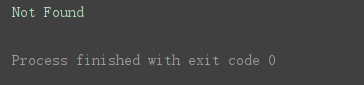
print(error.reason) # 打印异常原因
程序运行结果:
HTTPError类是URLError的子类,主要用于处理HTTP请求所出现的一次。此类有以下三个属性。
-
code :返回HTTP状态码
-
reason 返回错误原因
-
headers 返回请求头
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
向不存在的网络地址发送请求
response = urllib.request.urlopen(‘https://www.python.org/1111111111.html’)
print(response.status)
except urllib.error.HTTPError as error: # 捕获异常信息
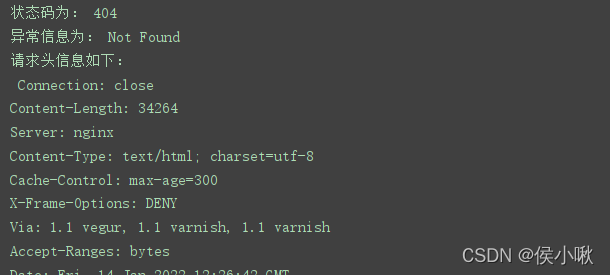
print(‘状态码为:’,error.code) # 打印状态码
print(‘异常信息为:’,error.reason) # 打印异常原因
print(‘请求头信息如下:\n’,error.headers) # 打印请求头
结果如下(部分):
因为URLError是HTTPError的父类,所以在捕获异常的时候可以先找子类是否异常,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常。
URLError产生的原因主要是
-
- 网络没有连接,
-
- 服务器连接失
-
- 找不到指定的服务器。
当使用urlopen或 opener.open 不能处理的,服务器上都对应一个响应对象,其中包含一个数字(状态码),如果urlopen不能处理,urlopen会产生一个相应的HTTPError对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态码。
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
response = urllib.request.urlopen(‘https://www.python.org/’,timeout=0.1)
except urllib.error.HTTPError as error: # HTTPError捕获异常信息
print(‘状态码为:’,error.code) # 打印状态码
print(‘HTTPError异常信息为:’,error.reason) # 打印异常原因
print(‘请求头信息如下:\n’,error.headers) # 打印请求头
except urllib.error.URLError as error: # URLError捕获异常信息
print(‘URLError异常信息为:’,error.reason)
这里访问了一个真实存在的URL,输出结果为:

==============================================================================
urllin模块提供了parse子模块用来解析URL。
urlparse()方法
parse子模块提供了urlparse()方法,实现将URL分解成不同部分,语法格式如下:
urllib.parse.urlparse(urlstring,scheme=’’,allow_fragment=True)
-
urlstring:需要拆分的URL,必选参数。
-
scheme:可选参数,需要设置的默认协议,默认为空字符串,如果要拆分的URL中没有协议,可通过该参数设置一个默认协议。
-
allow_fragment:可选参数,如果该参数设置为False,则表示忽略fragment这部分内容,默认为True。
示例:
import urllib.parse #导入urllib.parse模块
parse_result = urllib.parse.urlparse(‘https://docs.python.org/3/library/urllib.parse.html’)
print(type(parse_result)) # 打印类型
print(parse_result) # 打印拆分后的结果
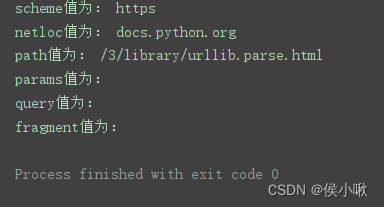
程序运行结果:

用此方法,除了返回ParseResult对象以外,还可以直接获取ParseResult对象中的每个属性值:
print(‘scheme值为:’, parse_result.scheme)
print(‘netloc值为:’, parse_result.netloc)
print(‘path值为:’, parse_result.path)
print(‘params值为:’, parse_result.params)
print(‘query值为:’, parse_result.query)
print(‘fragment值为:’, parse_result.fragment)
urlsplit()方法
urlsplit()方法与urlparse()方法类似,都可以实现URL的拆分。只是urlsplit()方法不再单独拆分params这部分内容,而是将params合并到path中,所以返回结果只有5部分内容。且返回的数据类型为SplitResult。
import urllib.parse #导入urllib.parse模块
需要拆分的URL
url = ‘https://docs.python.org/3/library/urllib.parse.html’
print(urllib.parse.urlsplit(url)) # 使用urlsplit()方法拆分URL
print(urllib.parse.urlparse(url)) # 使用urlparse()方法拆分URL
程序运行结果:

urlunparse()方法
urlunparse()方法实现URL的组合
语法:urlunparse(parts)
parts表示用于组合url的可迭代对象
import urllib.parse #导入urllib.parse模块
list_url = [‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’, ‘’]
tuple_url = (‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’, ‘’)
dict_url = {‘scheme’: ‘https’, ‘netloc’: ‘docs.python.org’, ‘path’: ‘/3/library/urllib.parse.html’, ‘params’: ‘’, ‘query’:‘’, ‘fragment’: ‘’}
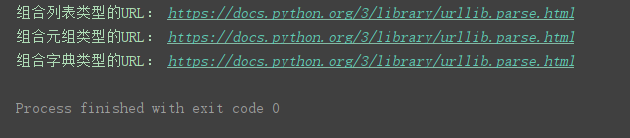
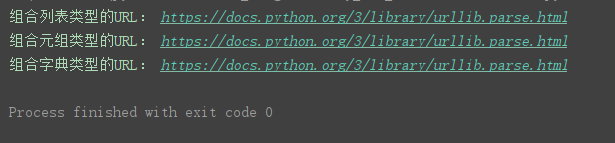
print(‘组合列表类型的URL:’, urllib.parse.urlunparse(list_url))
print(‘组合元组类型的URL:’, urllib.parse.urlunparse(tuple_url))
print(‘组合字典类型的URL:’, urllib.parse.urlunparse(dict_url.values()))
程序运行结果:
urlunsplit()方法
同样用于URL组合,只是参数中的元素必须是5个。
import urllib.parse #导入urllib.parse模块
list_url = [‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’]
tuple_url = (‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’)
dict_url = {‘scheme’: ‘https’, ‘netloc’: ‘docs.python.org’, ‘path’: ‘/3/library/urllib.parse.html’, ‘query’: ‘’, ‘fragment’: ‘’}
print(‘组合列表类型的URL:’, urllib.parse.urlunsplit(list_url))
print(‘组合元组类型的URL:’, urllib.parse.urlunsplit(tuple_url))
print(‘组合字典类型的URL:’, urllib.parse.urlunsplit(dict_url.values()))
程序运行结果
用**urljoin()**方法来实现URL的连接。
urllib.parse.urljoin(base,url,allow_fragments=True)
-
base 表示基础链接
-
url 表示新的链接
-
allow_fragments 为可选参数,默认为Ture,设为False则忽略fragment这部分内容。
import urllib.parse #导入urllib.parse模块
base_url = ‘https://docs.python.org’ # 定义基础链接
第二参数不完整时
print(urllib.parse.urljoin(base_url,‘3/library/urllib.parse.html’))
第二参数完整时,直接返回第二参数的链接
print(urllib.parse.urljoin(base_url,‘https://docs.python.org/3/library/urllib.parse.html#url-parsing’))
程序运行结果:

使用urlencode()方法编码请求参数,该方法接收的参数值为字典。
示例
import urllib.parse # 导入urllib.parse模块
base_url = ‘http://httpbin.org/get?’ # 定义基础链接
params = {‘name’: ‘Jack’, ‘country’: ‘China’, ‘age’: 18} # 定义字典类型的请求参数
url = base_url+urllib.parse.urlencode(params) # 连接请求地址
print(‘编码后的请求地址为:’, url)
程序运行结果:

使用quote方法编码请求参数,该方法接收的参数值类型为字符串。
示例:
import urllib.parse #导入urllib.parse模块
base_url = ‘http://httpbin.org/get?country=’ # 定义基础链接
url = base_url + urllib.parse.quote(‘中国’) # 字符串编码
print(‘编码后的请求地址为:’, url)
程序运行结果:

使用unquote()方法解码请求参数,即逆向解码。
示例:
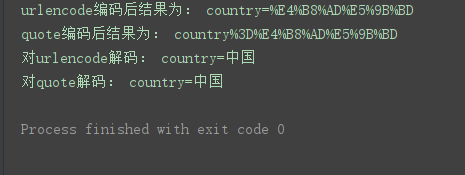
import urllib.parse #导入urllib.parse模块
u = urllib.parse.urlencode({‘country’: ‘中国’}) # 使用urlencode编码
q = urllib.parse.quote(‘country=中国’) # 使用quote编码
print(‘urlencode编码后结果为:’, u)
print(‘quote编码后结果为:’, q)
print(‘对urlencode解码:’, urllib.parse.unquote(u))
print(‘对quote解码:’, urllib.parse.unquote(q))
程序运行结果:
使用parse_qs()方法将参数转换为字典类型。
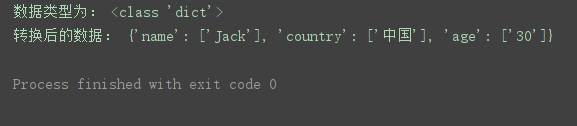
import urllib.parse #导入urllib.parse模块
定义一个请求地址
url = ‘http://httpbin.org/get?name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30’
q = urllib.parse.urlsplit(url).query # 获取需要的参数
q_dict = urllib.parse.parse_qs(q) # 将参数转换为字典类型的数据
print(‘数据类型为:’, type(q_dict))
print(‘转换后的数据:’, q_dict)
(其中query是前边拆分部分提到的拆分结果对象的一个属性)
程序运行结果:
使用parse_qsl()方法将参数转换为元组组成的列表
import urllib.parse # 导入urllib.parse模块
str_params = ‘name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30’ # 字符串参数
list_params = urllib.parse.parse_qsl(str_params) # 将字符串参数转为元组所组成的列表
print(‘数据类型为:’, type(list_params))
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
存中…(img-o7pZk041-1712163555298)]
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算















 5090
5090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









