







背景描述
泰坦尼克号轮船的沉没是历史上最为人熟知的海难事件之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在船上的 2224 名乘客和机组人员中,共造成 1502 人死亡。这场耸人听闻的悲剧震惊了国际社会,从而促进了船舶安全规定的完善。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。
数据说明
数据描述:
| 变量名称 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变量解释 | 乘客编号 | 是否存活 | 船舱等级 | 姓名 | 性别 | 年龄 | 兄弟姐妹和配偶数量 | 父母与子女数量 | 票的编号 | 票价 | 座位号 | 登船码头 |
数据来源
Titanic Competition : How top LB got their score
目录
一 数据读取与分析
1. 数据读取
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
#设置中文编码和负号的正常显示
plt.rcParams['font.family']='Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
import pandas as pd
import numpy as np
data_train = pd.read_csv('train.csv') # 训练集数据
data_test = pd.read_csv('test.csv') # 测试集数据
data_train.shape, data_test.shape, data_train.columns

2. 简单描述性分析
看一下数据类型及缺失情况
data_train.info()

data_train.describe()
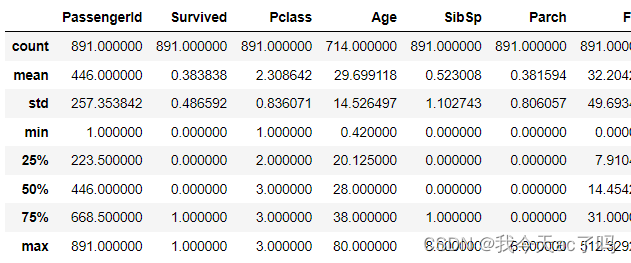
data_test.describe()
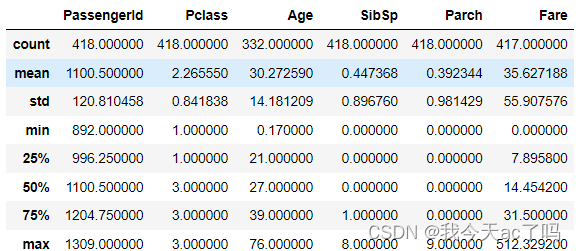
训练集和测试集大致的分布相差不大
3. 探索性分析
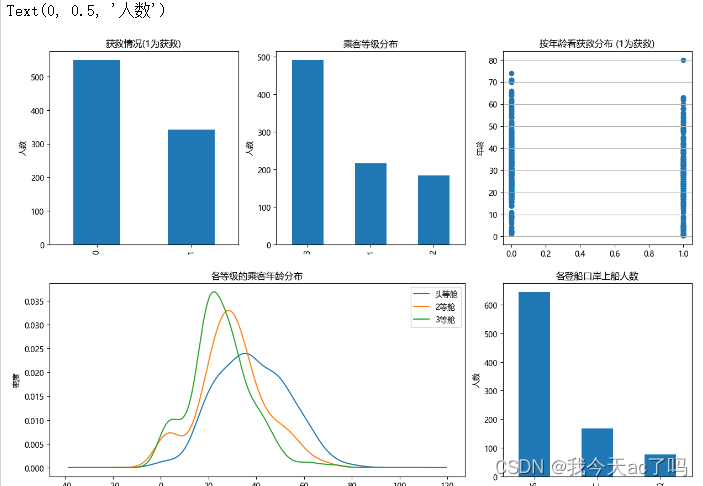
3.1 乘客不同特征的描述性统计
3.2 看看各乘客等级的获救情况
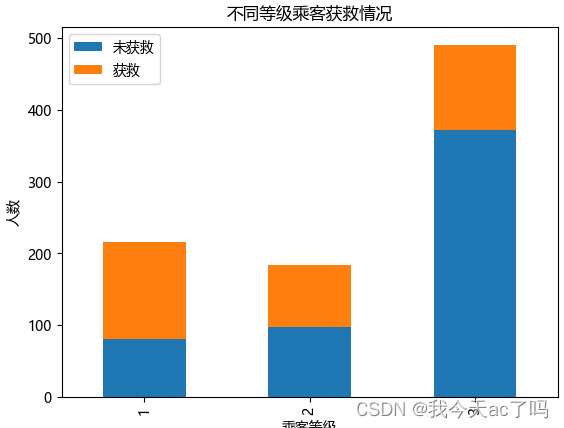
data_train[['Pclass', 'Survived']].groupby('Pclass').mean()

从图中可以看出,等级为1的乘客,获救的概率最大
3.3 查看各性别的获救情况
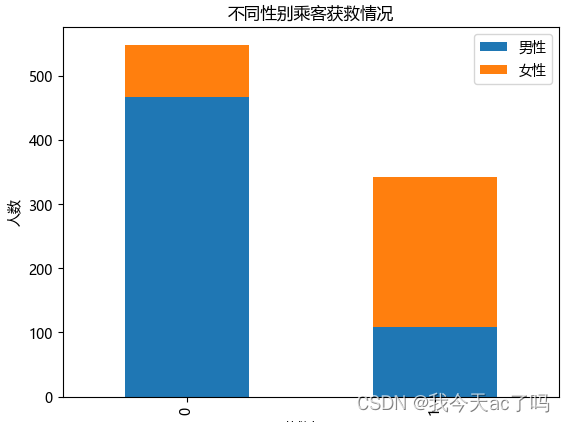
data_train[['Sex','Survived']].groupby('Sex').mean()
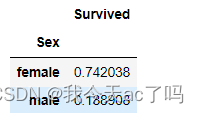
从图中可以看出,相对男性来说,女性的获救率远远高于男性
3.4 查看各登船港口的获救情况
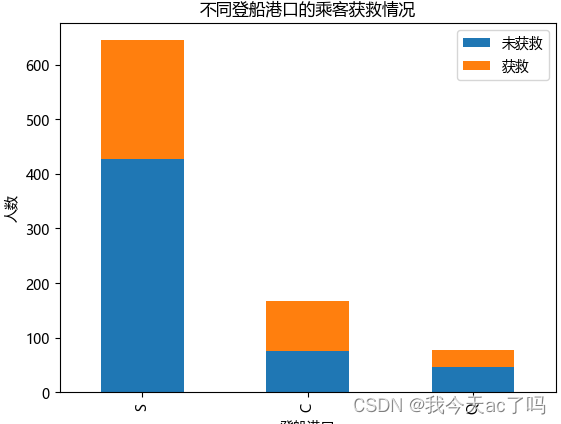
data_train[['Embarked','Survived']].groupby('Embarked').mean()
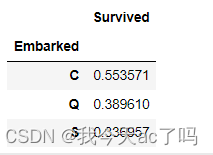
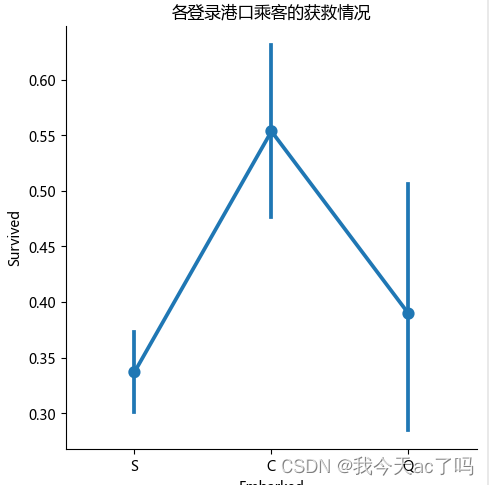
可以看出,再不同港口上船,生还率不同,其中C港口最高,Q次之,S港口最低;
3.5 查看携带家人数量不同的获救情况
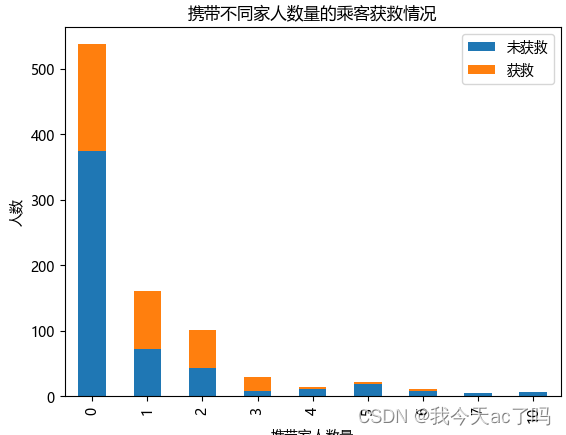
data_train[['family', 'Survived']].groupby('family').mean().plot.bar()
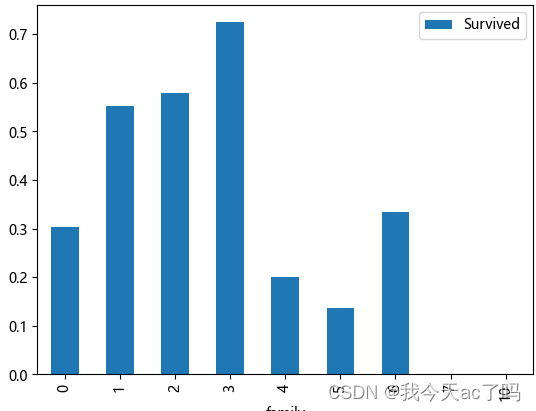
独自一人和亲友太多,存活率都比较低
3.6 不同船舱类型的乘客获救情况
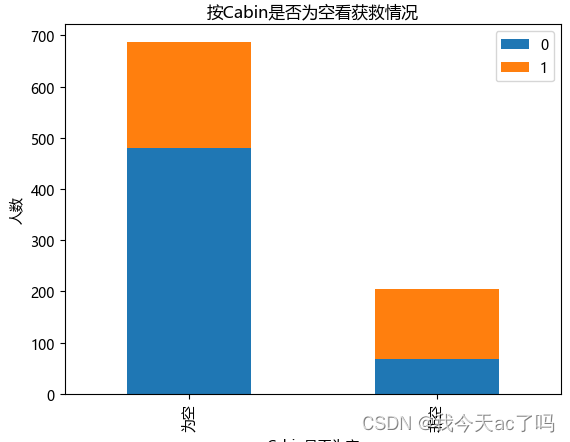
data_train.Survived[data_train.Cabin.notnull()].value_counts(normalize=True)

data_train.Survived[data_train.Cabin.isnull()].value_counts(normalize=True)

有cabin记录的乘客survival比例比无记录的高很多
3.7 缺失值处理
处理Embarked和数据
data_train.Embarked[data_train.Embarked.isnull() == True] = data_train.Embarked.dropna().mode().values
data_train['Cabin'] = data_train.Cabin.fillna('U0') # 先简单填充Cabin
处理Age数据
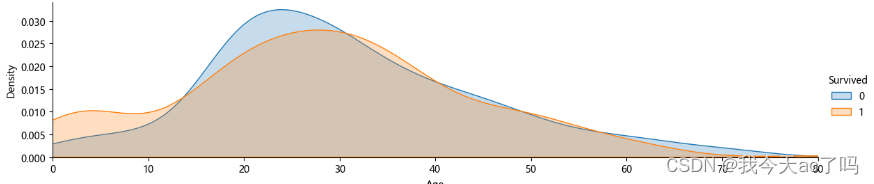
facet = sns.FacetGrid(data_train,hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade=True)
facet.set(xlim=(0,data_train['Age'].max()))
facet.add_legend()
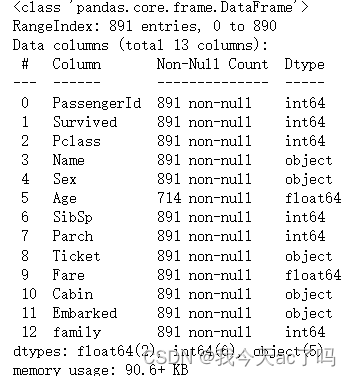
data_train.info()
from sklearn.ensemble import RandomForestRegressor
cols = ['Age', 'Survived', 'Pclass', 'SibSp', 'Parch', 'Fare']
age_df = data_train[cols]
X_train = age_df[age_df.Age.notnull()][cols[1:]]
y_train = age_df[age_df.Age.notnull()][cols[0]]
X_test = age_df[age_df.Age.isnull()][cols[1:]]
rfr = RandomForestRegressor(n_estimators=1000, n_jobs=-1) #n_estimators控制随机森林决策树的数量;n_jobs=-1会使用CPU的全部内核,大幅度提升速度
rfr.fit(X_train, y_train)
y_predict = rfr.predict(X_test)
data_train.loc[data_train.Age.isnull(),'Age'] = y_predict # 缺失值填充
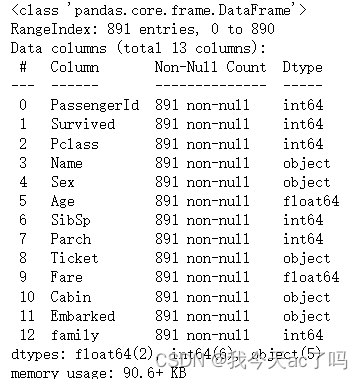
data_train.info()
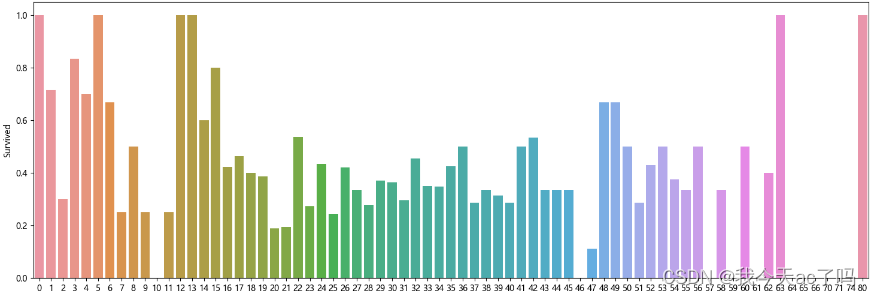
3.8 不同年龄下的平均生存率
plt.figure(figsize=(18,6))
data_train['Age_int'] = data_train.Age.astype(int)
rate = data_train[['Age_int', 'Survived']].groupby('Age_int', as_index=False).mean()
sns.barplot(x='Age_int', y='Survived', data=rate)
plt.show()
data_train['Age'].describe()
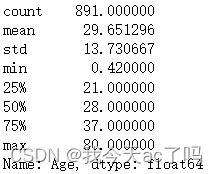
训练样本共有891份,平均年龄在29.5岁,标准差为13.7岁,最小年龄0.42岁,最大年龄80岁
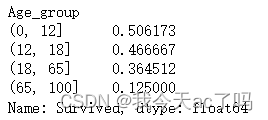
bins = [0, 12, 18, 65, 100]
data_train['Age_group'] = pd.cut(data_train['Age'], bins)
age_group_survived_rate = data_train.groupby('Age_group')['Survived'].mean()
age_group_survived_rate
age_group_survived_rate.plot(kind='bar')
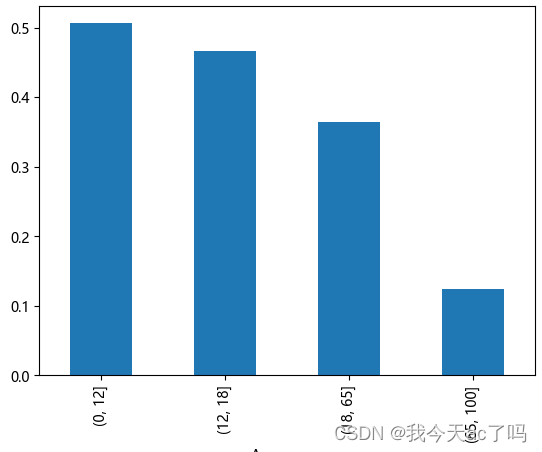
从图中可以看出,0到12岁儿童的存活率是最高的,达到了50%左右,其次是少年群体,在45%以上,最低的就属于65岁到100岁的老年群体,存活率最低,在12%左右
3.9 不同称呼的乘客生存情况
data_train['Name']

#方法一:
data_train['Title'] = data_train['Name'].apply(lambda x : x.split(',')[1].split('.')[0].strip())
pd.crosstab(data_train['Title'],data_train['Sex'])
#方法二:
data_train['Title'] =data_train['Name'].str.extract(' ([A-Za-z]+)\.',expand=False)
pd.crosstab(data_train['Title'],data_train['Sex'])
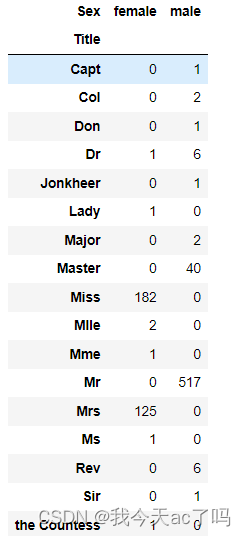
不同称呼的生存率
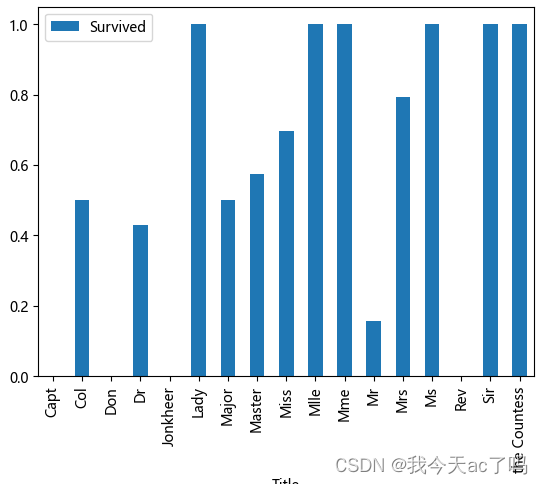
3.10 票价分布与Survived的关系
票价分布情况
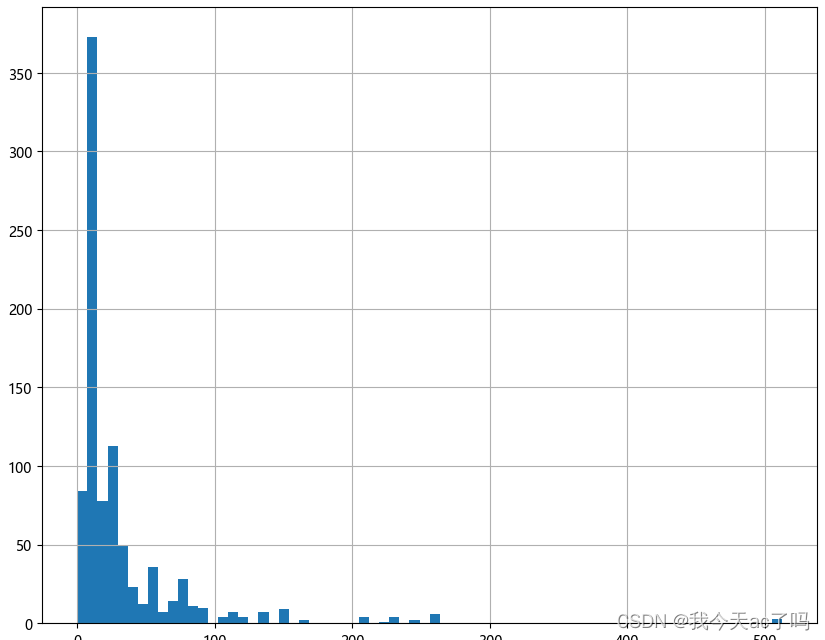
`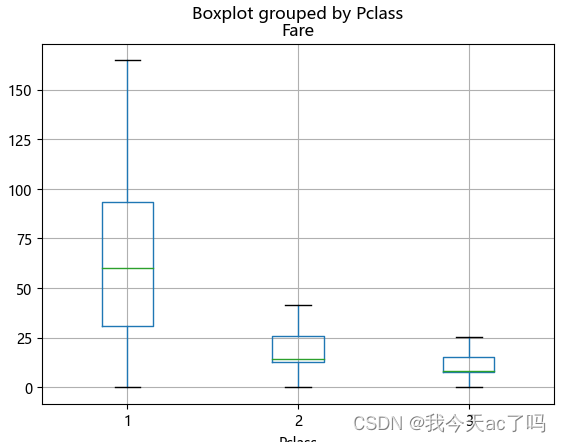
data_train['Fare'].describe()

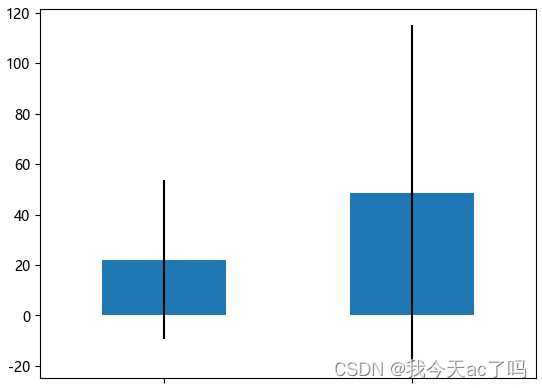
绘制survived与票价均值和方差的关系
如果本文有存在不足的地方,欢迎大家在评论区留言。
















 3570
3570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









