







最近这一两周看到不少互联网公司都已经开始秋招发放Offer。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

上个月初,一位刚进训练营的 211 硕士悄悄告诉我他雄赳赳气昂昂去面试大模型岗位,本以为胜券在握,却在常见的稀疏注意力机制上栽了跟头。那瞬间的尴尬,说不出什么滋味。
到底这小小的机制有何奥秘?一起走进这场面试 “小意外”,探寻大模型岗位背后的挑战与故事。
01
面试官心理分析
这道面试题在面试中考察频率还是比较高。面试官问这个问题,主要就是想看两点:
第一, 你知不知道常见的稀疏注意力机制有哪些。
第二, 讲一下它们各自的核心思想。
02
面试题解析
第一个你应该答出来的,就是 Atrous Self Attention,也就是"空洞自注意力",它借用了卷积运算中空洞的概念,计算注意力的时候是"跳着"来的。
来看这张图,我们把空洞参数设置为 k,(k=3),所以实际上每个元素只跟 n/k 个元素算相关性。
这样一来,理想情况下运行效率和显存占用都变成了 O(n²/k),也就是说,复杂度能够直接降低到原来的 1/k。
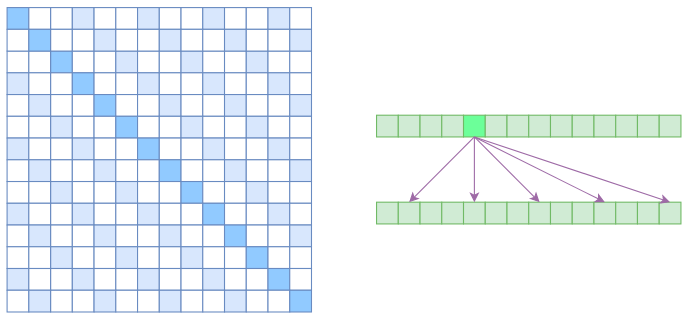
第二种是是 Local Self Attention,也就是局部自注意力。
其实自注意力机制在 CV 领域统称为“Non Local”,也就是局部感受野,而显然 Local Self Attention 是要放弃全局关联,重新引入局部关联。
具体来说,就是约束每个元素,只与前后 k 个元素以及自身有关联,我们看下面这张图。从注意力矩阵来看,就是相对距离超过k的注意力都直接设为 0。
这时候 Local Self Attention 其实就跟普通卷积很像了,都是保留了一个 2k+1 大小的窗口,然后在窗口内进行一些运算。
不同是什么呢?普通卷积是把窗口展平,然后接一个全连接层得到输出,而现在是窗口内通过注意力加权平均得到输出。
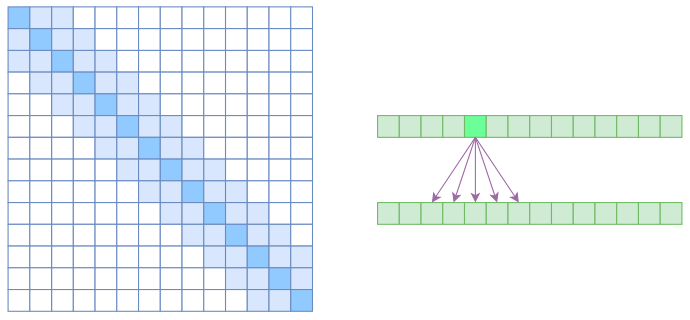
好,回答到这里,我们自然就要引出 OpenAI 提出的 Sparse Self Attention 了,它的思想是什么呢?
我们知道,Atrous Self Attention 是带有一些"洞"的,而 Local Self Attention 正好填补了这些"洞"。
所以一个简单的方式就是将 Local Self Attention 和 Atrous Self Attention 交替使用,两者累积起来,理论上也可以学习到全局关联性,同时也节省了显存。
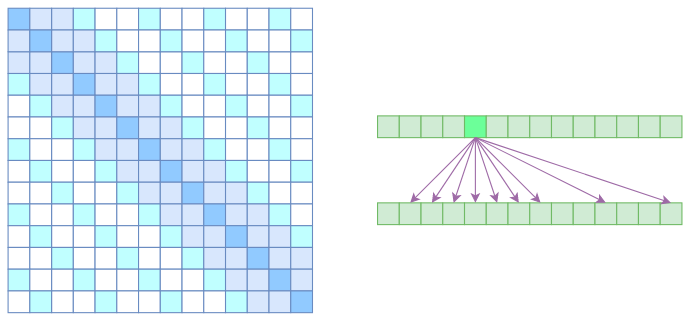
那从注意力矩阵上看呢,除了相对距离不超过 k 的,相对距离为 k,2k,3k 等 k 的倍数的注意力,我们都设为 0,这样一来 Attention 就具有"局部紧密相关和远程稀疏相关"的特性了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









