







本文将从Encoder-Decoder的本质、Encoder-Decoder的原理、Encoder-Decoder的应用三个方面,带您一文搞懂Encoder-Decoder(编码器-解码器)。

Encoder-Decoder的本质
核心逻辑:将现实问题转化为数学问题,通过求解数学问题来得到现实世界的解决方案。
- Encoder (编码器):“将现实问题转化为数学问题”

Encoder编码器
- Decoder (解码器):“求解数学问题,并转化为现实世界的解决方案”

Decoder解码器
Seq2Seq(Sequence-to-sequence)输入一个序列,输出另一个序列
-
Seq2Seq(序列到序列):强调模型的目的——将输入序列转换为输出序列。
-
Encoder-Decoder(编码器-解码器):强调模型的实现方法——提供实现这一目的的具体方法或架构。
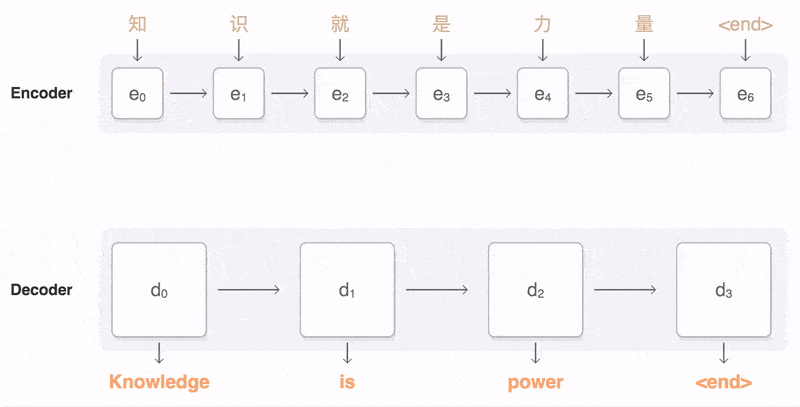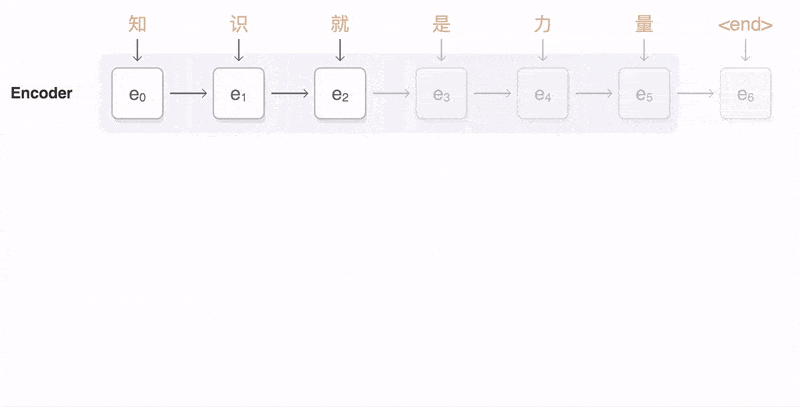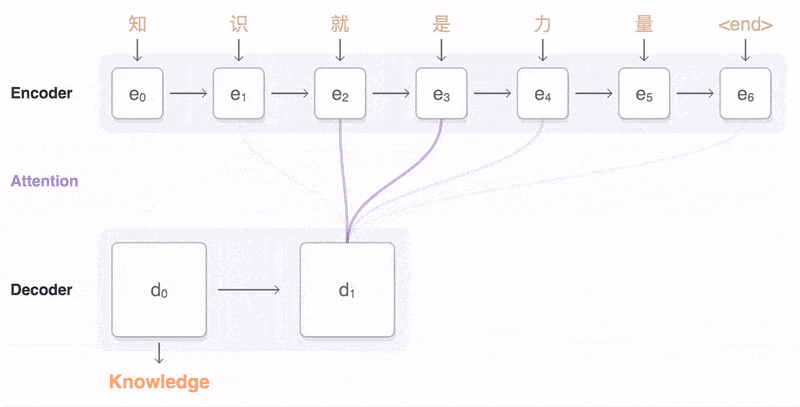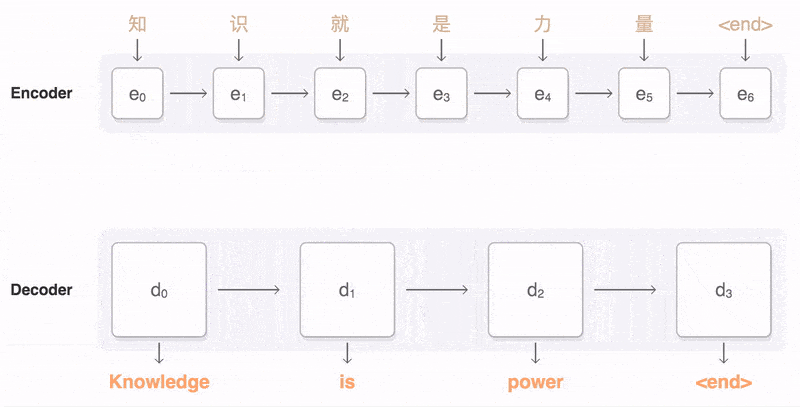
Seq2Seq
二、Encoder-Decoder的原理

Encoder(编码器):
-
编码器的作用是将输入序列转换成一个固定长度的上下文向量。
-
它通常使用循环神经网络(RNN)或其变体(如LSTM、GRU)来实现。
-
在每个时间步,编码器会读取输入序列的一个元素,并更新其隐藏状态。
-
编码完成后,最终的隐藏状态或隐藏状态的某种变换被用作上下文向量。
Decoder(解码器):
-
解码器的任务是从上下文向量中生成输出序列。
-
它也通常使用循环神经网络(RNN)来实现。
-
在每个时间步,解码器会基于上一个时间步的输出、当前的隐藏状态和上下文向量来生成当前时间步的输出。
三、Encoder-Decoder的应用
机器翻译(文本 – 文本):

这是Encoder-Decoder最经典的应用。编码器将源语言的句子编码成上下文向量,解码器则从该向量中生成目标语言的翻译。
机器翻译中Encoder-Decoder的6个步骤:
-
源语言输入:将源语言的句子转换为词向量序列,作为编码器的输入。
-
编码器:通过循环神经网络处理源语言词向量,输出包含句子全部信息的上下文向量。
-
上下文向量:作为解码器的初始输入,它固定长度地编码了源语言句子的整体语义。
-
解码器:基于上下文向量,逐步生成目标语言的词序列,形成翻译结果。
-
目标语言输出:解码器生成的词序列构成最终翻译的目标语言句子。
-
训练与优化:通过比较模型生成的翻译与真实目标句子,优化模型参数以提高翻译准确性。
语音识别(音频 – 文本):

在语音识别任务中,编码器将音频信号转换为特征表示,解码器则从这些特征中生成文本转录。
语音识别任务中Encoder-Decoder的6个步骤:
-
音频信号输入:将原始音频信号进行预处理,准备送入编码器进行特征提取。
-
编码器处理:编码器接收预处理后的音频,逐帧提取声学特征,转换为高维特征向量序列。
-
特征表示:编码器输出的特征向量序列捕捉了音频中的关键信息,为解码器提供输入。
-
解码器生成:解码器根据特征向量序列和语言模型,逐步预测并生成对应的文本转录。
-
文本转录输出:解码器完成预测,输出最终的文本转录结果。
-
训练与优化:通过比较生成的文本转录与真实标签,优化模型参数以提高识别准确率。


















 8871
8871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









