







指定 worker 子进程可以打开的最大文件句柄数。
worker_rlimit_nofile 20480; # 可以理解成每个worker子进程的最大连接数量。
worker_rlimit_core
指定 worker 子进程异常终止后的 core 文件,用于记录分析问题。
worker_rlimit_core 50M; # 存放大小限制
working_directory /opt/nginx/tmp; # 存放目录
worker_processes_number
指定 Nginx 启动的 worker 子进程数量。
worker_processes 4; # 指定具体子进程数量
worker_processes auto; # 与当前cpu物理核心数一致
worker_cpu_affinity
将每个 worker 子进程与我们的 cpu 物理核心绑定。
worker_cpu_affinity 0001 0010 0100 1000; # 4个物理核心,4个worker子进程
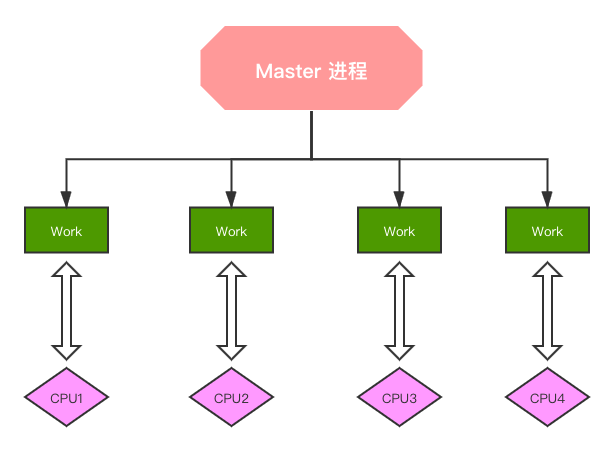
将每个 worker 子进程与特定 CPU 物理核心绑定,优势在于,避免同一个 worker 子进程在不同的 CPU 核心上切换,缓存失效,降低性能。但其并不能真正的避免进程切换。
worker_priority
指定 worker 子进程的 nice 值,以调整运行 Nginx 的优先级,通常设定为负值,以优先调用 Nginx 。
worker_priority -10; # 120-10=110,110就是最终的优先级
Linux 默认进程的优先级值是120,值越小越优先;nice 定范围为 -20 到 +19 。
[备注] 应用的默认优先级值是120加上 nice 值等于它最终的值,这个值越小,优先级越高。
worker_shutdown_timeout
指定 worker 子进程优雅退出时的超时时间。
worker_shutdown_timeout 5s;
timer_resolution
worker 子进程内部使用的计时器精度,调整时间间隔越大,系统调用越少,有利于性能提升;反之,系统调用越多,性能下降。
timer_resolution 100ms;
在 Linux 系统中,用户需要获取计时器时需要向操作系统内核发送请求,有请求就必然会有开销,因此这个间隔越大开销就越小。
daemon
指定 Nginx 的运行方式,前台还是后台,前台用于调试,后台用于生产。
daemon off; # 默认是on,后台运行模式
配置文件 events 段核心参数
use
Nginx 使用何种事件驱动模型。
use method; # 不推荐配置它,让nginx自己选择
method 可选值为:select、poll、kqueue、epoll、/dev/poll、eventport
worker_connections
worker 子进程能够处理的最大并发连接数。
worker_connections 1024 # 每个子进程的最大连接数为1024
accept_mutex
是否打开负载均衡互斥锁。
accept_mutex on # 默认是off关闭的,这里推荐打开
server_name 指令
指定虚拟主机域名。
server_name name1 name2 name3
# 示例:
server_name www.nginx.com;
域名匹配的四种写法:
-
精确匹配:
server_name www.nginx.com; -
左侧通配:
server_name *.nginx.com; -
右侧统配:
server_name www.nginx.*; -
正则匹配:
server_name ~^www\.nginx\.*$;
匹配优先级:精确匹配 > 左侧通配符匹配 > 右侧通配符匹配 > 正则表达式匹配
server_name 配置实例:
1、配置本地 DNS 解析 vim /etc/hosts ( macOS 系统)
添加如下内容,其中 121.42.11.34 是阿里云服务器IP地址
121.42.11.34 www.nginx-test.com
121.42.11.34 mail.nginx-test.com
121.42.11.34 www.nginx-test.org
121.42.11.34 doc.nginx-test.com
121.42.11.34 www.nginx-test.cn
121.42.11.34 fe.nginx-test.club
[注意] 这里使用的是虚拟域名进行测试,因此需要配置本地 DNS 解析,如果使用阿里云上购买的域名,则需要在阿里云上设置好域名解析。
2、配置阿里云 Nginx ,vim /etc/nginx/nginx.conf
这里只列举了http端中的sever端配置
左匹配
server {
listen 80;
server_name *.nginx-test.com;
root /usr/share/nginx/html/nginx-test/left-match/;
location / {
index index.html;
}
}
正则匹配
server {
listen 80;
server_name ~^..nginx-test…$;
root /usr/share/nginx/html/nginx-test/reg-match/;
location / {
index index.html;
}
}
右匹配
server {
listen 80;
server_name www.nginx-test.*;
root /usr/share/nginx/html/nginx-test/right-match/;
location / {
index index.html;
}
}
完全匹配
server {
listen 80;
server_name www.nginx-test.com;
root /usr/share/nginx/html/nginx-test/all-match/;
location / {
index index.html;
}
}
3、访问分析
-
当访问
www.nginx-test.com时,都可以被匹配上,因此选择优先级最高的“完全匹配”; -
当访问
mail.nginx-test.com时,会进行“左匹配”; -
当访问
www.nginx-test.org时,会进行“右匹配”; -
当访问
doc.nginx-test.com时,会进行“左匹配”; -
当访问
www.nginx-test.cn时,会进行“右匹配”; -
当访问
fe.nginx-test.club时,会进行“正则匹配”;
root
指定静态资源目录位置,它可以写在 http 、 server 、 location 等配置中。
root path
例如:
location /image {
root /opt/nginx/static;
}
当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png
[注意] root 会将定义路径与 URI 叠加, alias 则只取定义路径。
alias
它也是指定静态资源目录位置,它只能写在 location 中。
location /image {
alias /opt/nginx/static/image/;
}
当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png
[注意] 使用 alias 末尾一定要添加 / ,并且它只能位于 location 中。
location
配置路径。
location [ = | ~ | ~* | ^~ ] uri {
…
}
匹配规则:
-
=精确匹配; -
~正则匹配,区分大小写; -
~*正则匹配,不区分大小写; -
^~匹配到即停止搜索;
匹配优先级:= > ^~ > ~ > ~* > 不带任何字符。
实例:
server {
listen 80;
server_name www.nginx-test.com;
只有当访问 www.nginx-test.com/match_all/ 时才会匹配到/usr/share/nginx/html/match_all/index.html
location = /match_all/ {
root /usr/share/nginx/html
index index.html
}
当访问 www.nginx-test.com/1.jpg 等路径时会去 /usr/share/nginx/images/1.jpg 找对应的资源
location ~ .(jpeg|jpg|png|svg)$ {
root /usr/share/nginx/images;
}
当访问 www.nginx-test.com/bbs/ 时会匹配上 /usr/share/nginx/html/bbs/index.html
location ^~ /bbs/ {
root /usr/share/nginx/html;
index index.html index.htm;
}
}
location 中的反斜线
location /test {
…
}
location /test/ {
…
}
-
不带
/当访问www.nginx-test.com/test时,Nginx先找是否有test目录,如果有则找test目录下的index.html;如果没有test目录,nginx则会找是否有test文件。 -
带
/当访问www.nginx-test.com/test时,Nginx先找是否有test目录,如果有则找test目录下的index.html,如果没有它也不会去找是否存在test文件。
return
停止处理请求,直接返回响应码或重定向到其他 URL ;执行 return 指令后, location 中后续指令将不会被执行。
return code [text];
return code URL;
return URL;
例如:
location / {
return 404; # 直接返回状态码
}
location / {
return 404 “pages not found”; # 返回状态码 + 一段文本
}
location / {
return 302 /bbs ; # 返回状态码 + 重定向地址
}
location / {
return https://www.baidu.com ; # 返回重定向地址
}
rewrite
根据指定正则表达式匹配规则,重写 URL 。
语法:rewrite 正则表达式 要替换的内容 [flag];
上下文:server、location、if
示例:rewirte /images/(..jpg)$ /pic/$1; # $1是前面括号(..jpg)的反向引用
flag 可选值的含义:
-
last重写后的URL发起新请求,再次进入server段,重试location的中的匹配; -
break直接使用重写后的URL,不再匹配其它location中语句; -
redirect返回302临时重定向; -
permanent返回301永久重定向;
server{
listen 80;
server_name fe.lion.club; # 要在本地hosts文件进行配置
root html;
location /search {
rewrite ^/(.*) https://www.baidu.com redirect;
}
location /images {
rewrite /images/(.*) /pics/$1;
}
location /pics {
rewrite /pics/(.*) /photos/$1;
}
location /photos {
}
}
按照这个配置我们来分析:
-
当访问
fe.lion.club/search时,会自动帮我们重定向到https://www.baidu.com。 -
当访问
fe.lion.club/images/1.jpg时,第一步重写URL为fe.lion.club/pics/1.jpg,找到pics的location,继续重写URL为fe.lion.club/photos/1.jpg,找到/photos的location后,去html/photos目录下寻找1.jpg静态资源。
if 指令
语法:if (condition) {…}
上下文:server、location
示例:
if($http_user_agent ~ Chrome){
rewrite /(.*)/browser/$1 break;
}
condition 判断条件:
-
$variable仅为变量时,值为空或以0开头字符串都会被当做false处理; -
=或!=相等或不等; -
~正则匹配; -
! ~非正则匹配; -
~*正则匹配,不区分大小写; -
-f或! -f检测文件存在或不存在; -
-d或! -d检测目录存在或不存在; -
-e或! -e检测文件、目录、符号链接等存在或不存在; -
-x或! -x检测文件可以执行或不可执行;
实例:
server {
listen 8080;
server_name localhost;
root html;
location / {
if ( $uri = “/images/” ){
rewrite (.*) /pics/ break;
}
}
}
当访问 localhost:8080/images/ 时,会进入 if 判断里面执行 rewrite 命令。
autoindex
用户请求以 / 结尾时,列出目录结构,可以用于快速搭建静态资源下载网站。
autoindex.conf 配置信息:
server {
listen 80;
server_name fe.lion-test.club;
location /download/ {
root /opt/source;
autoindex on; # 打开 autoindex,,可选参数有 on | off
autoindex_exact_size on; # 修改为off,以KB、MB、GB显示文件大小,默认为on,以bytes显示出⽂件的确切⼤⼩
autoindex_format html; # 以html的方式进行格式化,可选参数有 html | json | xml
autoindex_localtime off; # 显示的⽂件时间为⽂件的服务器时间。默认为off,显示的⽂件时间为GMT时间
}
}
当访问 fe.lion.com/download/ 时,会把服务器 /opt/source/download/ 路径下的文件展示出来,如下图所示:

变量
Nginx 提供给使用者的变量非常多,但是终究是一个完整的请求过程所产生数据, Nginx 将这些数据以变量的形式提供给使用者。
下面列举些项目中常用的变量:
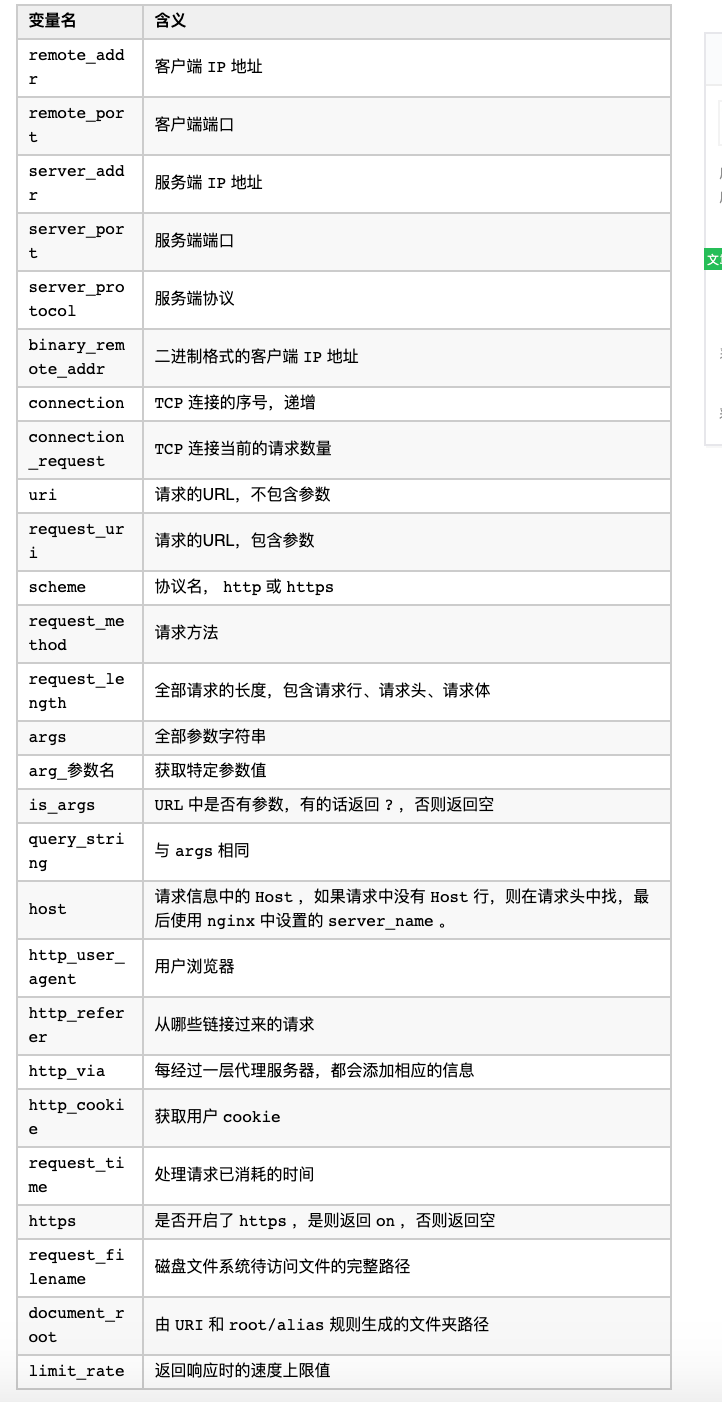
实例演示 var.conf :
server{
listen 8081;
server_name var.lion-test.club;
root /usr/share/nginx/html;
location / {
return 200 "
remote_addr: $remote_addr
remote_port: $remote_port
server_addr: $server_addr
server_port: $server_port
server_protocol: $server_protocol
binary_remote_addr: $binary_remote_addr
connection: $connection
uri: $uri
request_uri: $request_uri
scheme: $scheme
request_method: $request_method
request_length: $request_length
args: $args
arg_pid: $arg_pid
is_args: $is_args
query_string: $query_string
host: $host
http_user_agent: $http_user_agent
http_referer: $http_referer
http_via: $http_via
request_time: $request_time
https: $https
request_filename: $request_filename
document_root: $document_root
";
}
}
当我们访问 http://var.lion-test.club:8081/test?pid=121414&cid=sadasd 时,由于 Nginx 中写了 return 方法,因此 chrome 浏览器会默认为我们下载一个文件,下面展示的就是下载的文件内容:
remote_addr: 27.16.220.84
remote_port: 56838
server_addr: 172.17.0.2
server_port: 8081
server_protocol: HTTP/1.1
binary_remote_addr: 茉
connection: 126
uri: /test/
request_uri: /test/?pid=121414&cid=sadasd
scheme: http
request_method: GET
request_length: 518
args: pid=121414&cid=sadasd
arg_pid: 121414
is_args: ?
query_string: pid=121414&cid=sadasd
host: var.lion-test.club
http_user_agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36
http_referer:
http_via:
request_time: 0.000
https:
request_filename: /usr/share/nginx/html/test/
document_root: /usr/share/nginx/html
Nginx 的配置还有非常多,以上只是罗列了一些常用的配置,在实际项目中还是要学会查阅文档。
Nginx 应用核心概念
代理是在服务器和客户端之间假设的一层服务器,代理将接收客户端的请求并将它转发给服务器,然后将服务端的响应转发给客户端。
不管是正向代理还是反向代理,实现的都是上面的功能。
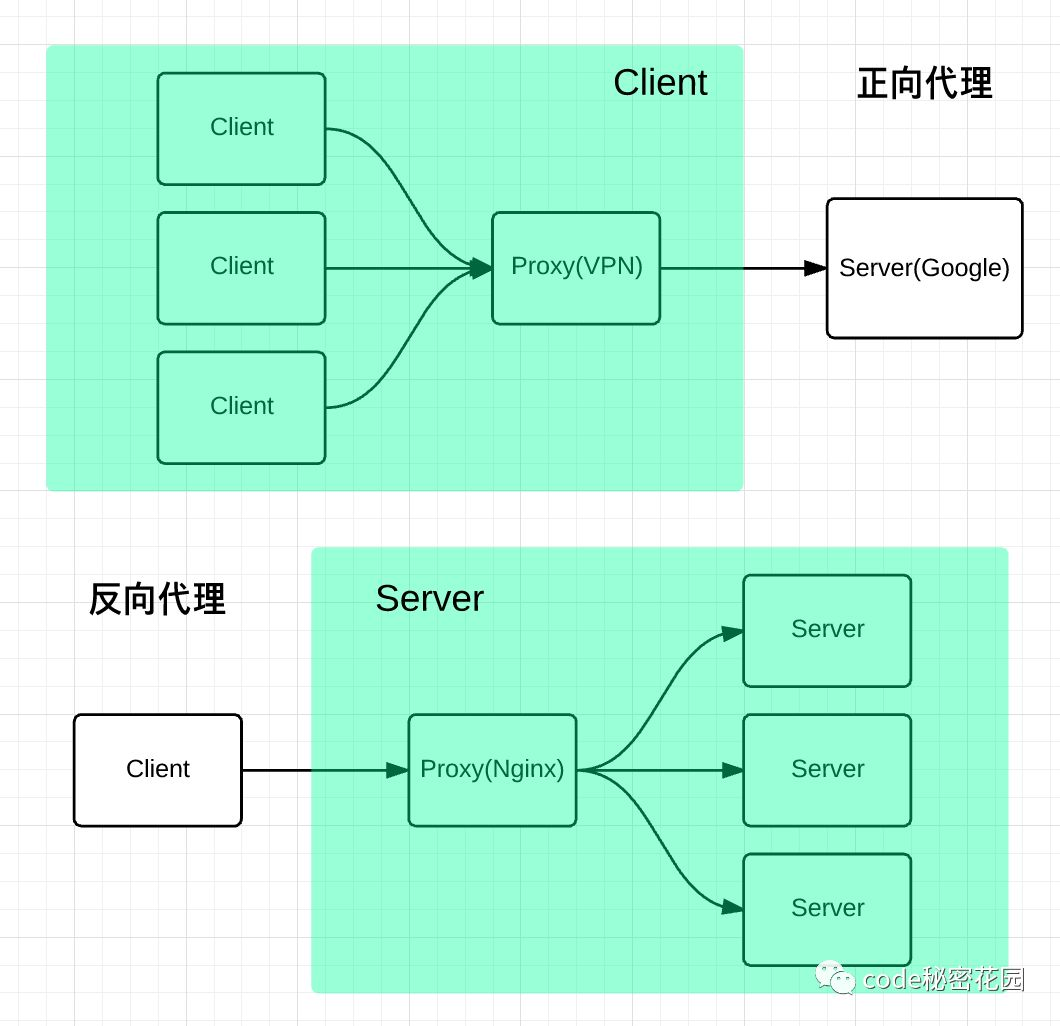
正向代理
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。
正向代理是为我们服务的,即为客户端服务的,客户端可以根据正向代理访问到它本身无法访问到的服务器资源。
正向代理对我们是透明的,对服务端是非透明的,即服务端并不知道自己收到的是来自代理的访问还是来自真实客户端的访问。
反向代理
- 反向代理*(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
反向代理是为服务端服务的,反向代理可以帮助服务器接收来自客户端的请求,帮助服务器做请求转发,负载均衡等。
反向代理对服务端是透明的,对我们是非透明的,即我们并不知道自己访问的是代理服务器,而服务器知道反向代理在为他服务。
反向代理的优势:
-
隐藏真实服务器;
-
负载均衡便于横向扩充后端动态服务;
-
动静分离,提升系统健壮性;
那么“动静分离”是什么?负载均衡又是什么?
动静分离
动静分离是指在 web 服务器架构中,将静态页面与动态页面或者静态内容接口和动态内容接口分开不同系统访问的架构设计方法,进而提示整个服务的访问性和可维护性。
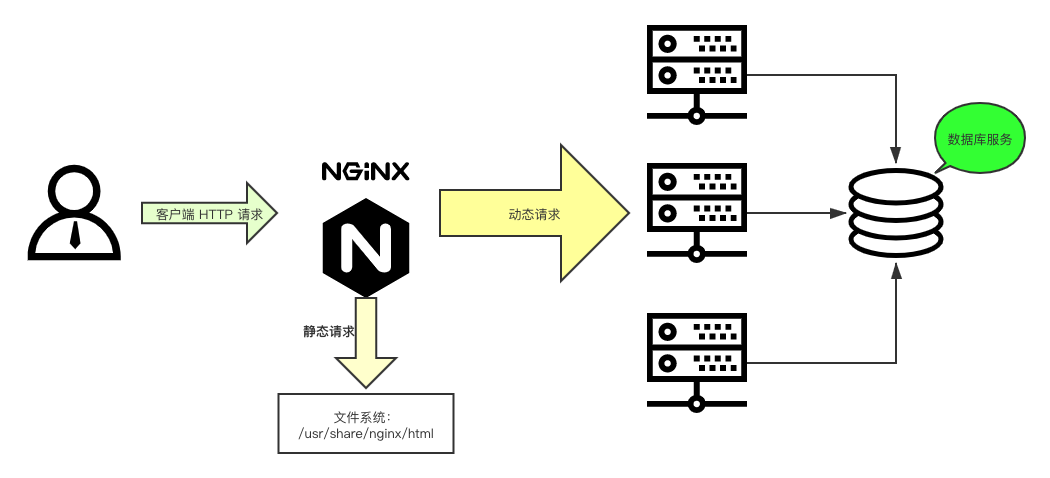
一般来说,都需要将动态资源和静态资源分开,由于 Nginx 的高并发和静态资源缓存等特性,经常将静态资源部署在 Nginx 上。如果请求的是静态资源,直接到静态资源目录获取资源,如果是动态资源的请求,则利用反向代理的原理,把请求转发给对应后台应用去处理,从而实现动静分离。
使用前后端分离后,可以很大程度提升静态资源的访问速度,即使动态服务不可用,静态资源的访问也不会受到影响。
负载均衡
一般情况下,客户端发送多个请求到服务器,服务器处理请求,其中一部分可能要操作一些资源比如数据库、静态资源等,服务器处理完毕后,再将结果返回给客户端。
这种模式对于早期的系统来说,功能要求不复杂,且并发请求相对较少的情况下还能胜任,成本也低。随着信息数量不断增长,访问量和数据量飞速增长,以及系统业务复杂度持续增加,这种做法已无法满足要求,并发量特别大时,服务器容易崩。
很明显这是由于服务器性能的瓶颈造成的问题,除了堆机器之外,最重要的做法就是负载均衡。
请求爆发式增长的情况下,单个机器性能再强劲也无法满足要求了,这个时候集群的概念产生了,单个服务器解决不了的问题,可以使用多个服务器,然后将请求分发到各个服务器上,将负载分发到不同的服务器,这就是负载均衡,核心是「分摊压力」。Nginx 实现负载均衡,一般来说指的是将请求转发给服务器集群。
举个具体的例子,晚高峰乘坐地铁的时候,入站口经常会有地铁工作人员大喇叭“请走 B 口, B 口人少车空…”,这个工作人员的作用就是负载均衡。
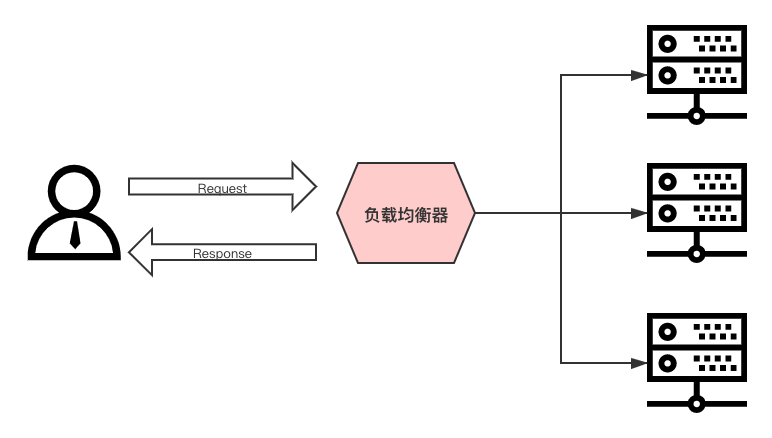
Nginx 实现负载均衡的策略:
-
轮询策略:默认情况下采用的策略,将所有客户端请求轮询分配给服务端。这种策略是可以正常工作的,但是如果其中某一台服务器压力太大,出现延迟,会影响所有分配在这台服务器下的用户。
-
最小连接数策略:将请求优先分配给压力较小的服务器,它可以平衡每个队列的长度,并避免向压力大的服务器添加更多的请求。
-
最快响应时间策略:优先分配给响应时间最短的服务器。
-
客户端
ip绑定策略:来自同一个ip的请求永远只分配一台服务器,有效解决了动态网页存在的session共享问题。
Nginx 实战配置
在配置反向代理和负载均衡等等功能之前,有两个核心模块是我们必须要掌握的,这两个模块应该说是 Nginx 应用配置中的核心,它们分别是:upstream 、proxy_pass 。
upstream
用于定义上游服务器(指的就是后台提供的应用服务器)的相关信息。
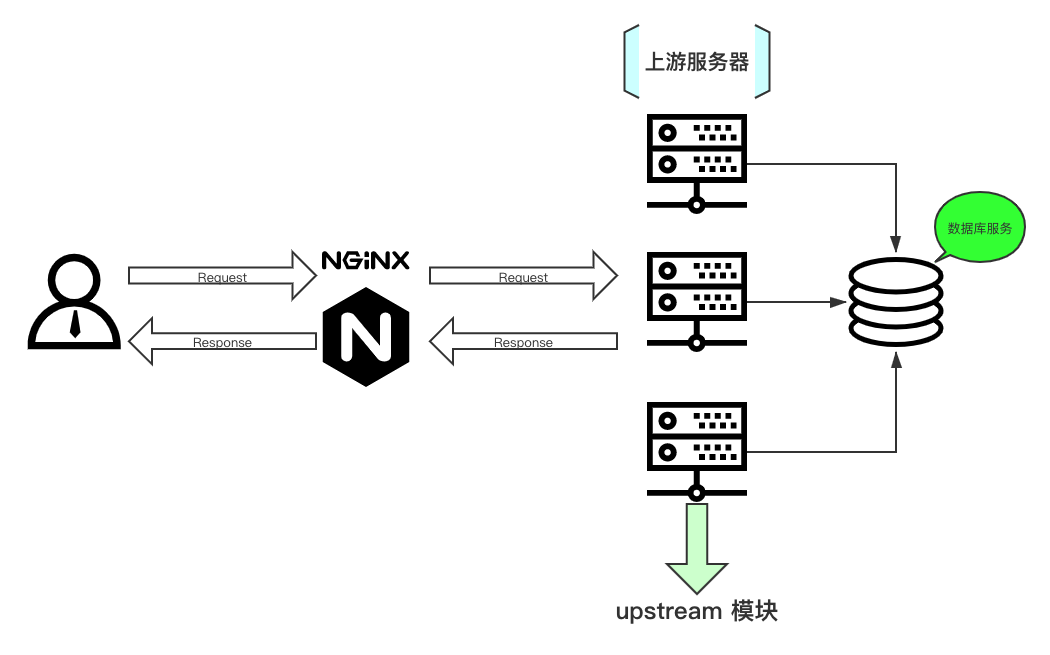
语法:upstream name {
…
}
上下文:http
示例:
upstream back_end_server{
server 192.168.100.33:8081
}
在 upstream 内可使用的指令:
-
server定义上游服务器地址; -
zone定义共享内存,用于跨worker子进程; -
keepalive对上游服务启用长连接; -
keepalive_requests一个长连接最多请求HTTP的个数; -
keepalive_timeout空闲情形下,一个长连接的超时时长; -
hash哈希负载均衡算法; -
ip_hash依据IP进行哈希计算的负载均衡算法; -
least_conn最少连接数负载均衡算法; -
least_time最短响应时间负载均衡算法; -
random随机负载均衡算法;
server
定义上游服务器地址。
语法:server address [parameters]
上下文:upstream
parameters 可选值:
-
weight=number权重值,默认为1; -
max_conns=number上游服务器的最大并发连接数; -
fail_timeout=time服务器不可用的判定时间; -
max_fails=numer服务器不可用的检查次数; -
backup备份服务器,仅当其他服务器都不可用时才会启用; -
down标记服务器长期不可用,离线维护;
keepalive
限制每个 worker 子进程与上游服务器空闲长连接的最大数量。
keepalive connections;
上下文:upstream
示例:keepalive 16;
keepalive_requests
单个长连接可以处理的最多 HTTP 请求个数。
语法:keepalive_requests number;
默认值:keepalive_requests 100;
上下文:upstream
keepalive_timeout
空闲长连接的最长保持时间。
语法:keepalive_timeout time;
默认值:keepalive_timeout 60s;
上下文:upstream
配置实例
upstream back_end{
server 127.0.0.1:8081 weight=3 max_conns=1000 fail_timeout=10s max_fails=2;
keepalive 32;
keepalive_requests 50;
keepalive_timeout 30s;
}
proxy_pass
用于配置代理服务器。
语法:proxy_pass URL;
上下文:location、if、limit_except
示例:
proxy_pass http://127.0.0.1:8081
proxy_pass http://127.0.0.1:8081/proxy
URL 参数原则
1. URL 必须以 http 或 https 开头;
2. URL 中可以携带变量;
3. URL 中是否带 URI ,会直接影响发往上游请求的 URL ;
接下来让我们来看看两种常见的 URL 用法:
-
proxy_pass http://192.168.100.33:8081 -
proxy_pass http://192.168.100.33:8081/
这两种用法的区别就是带 / 和不带 / ,在配置代理时它们的区别可大了:
-
不带
/意味着Nginx不会修改用户URL,而是直接透传给上游的应用服务器; -
带
/意味着Nginx会修改用户URL,修改方法是将location后的URL从用户URL中删除;
不带 / 的用法:
location /bbs/{
proxy_pass http://127.0.0.1:8080;
}
分析:
1. 用户请求 URL :/bbs/abc/test.html
2. 请求到达 Nginx 的 URL :/bbs/abc/test.html
3 .请求到达上游应用服务器的 URL :/bbs/abc/test.html
带 / 的用法:
location /bbs/{
proxy_pass http://127.0.0.1:8080/;
}
分析:
1. 用户请求 URL :/bbs/abc/test.html
2. 请求到达 Nginx 的 URL :/bbs/abc/test.html
3. 请求到达上游应用服务器的 URL :/abc/test.html
并没有拼接上 /bbs ,这点和 root 与 alias 之间的区别是保持一致的。
配置反向代理
这里为了演示更加接近实际,作者准备了两台云服务器,它们的公网 IP 分别是:121.42.11.34 与 121.5.180.193 。
我们把 121.42.11.34 服务器作为上游服务器,做如下配置:
# /etc/nginx/conf.d/proxy.conf
server{
listen 8080;
server_name localhost;
location /proxy/ {
root /usr/share/nginx/html/proxy;
index index.html;
}
}
# /usr/share/nginx/html/proxy/index.html
121.42.11.34 proxy html
配置完成后重启 Nginx 服务器 nginx \-s reload 。
把 121.5.180.193 服务器作为代理服务器,做如下配置:
/etc/nginx/conf.d/proxy.conf
upstream back_end {
server 121.42.11.34:8080 weight=2 max_conns=1000 fail_timeout=10s max_fails=3;
keepalive 32;
keepalive_requests 80;
keepalive_timeout 20s;
}
server {
listen 80;
server_name proxy.lion.club;
location /proxy {
proxy_pass http://back_end/proxy;
}
}
本地机器要访问 proxy.lion.club 域名,因此需要配置本地 hosts ,通过命令:vim /etc/hosts 进入配置文件,添加如下内容:
121.5.180.193 proxy.lion.club

分析:
当访问 proxy.lion.club/proxy 时通过 upstream 的配置找到 121.42.11.34:8080 ;
因此访问地址变为 http://121.42.11.34:8080/proxy ;
连接到 121.42.11.34 服务器,找到 8080 端口提供的 server ;
通过 server 找到 /usr/share/nginx/html/proxy/index.html 资源,最终展示出来。
配置负载均衡
配置负载均衡主要是要使用 upstream 指令。
我们把 121.42.11.34 服务器作为上游服务器,做如下配置( /etc/nginx/conf.d/balance.conf ):
server{
listen 8020;
location / {
return 200 ‘return 8020 \n’;
}
}
server{
listen 8030;
location / {
return 200 ‘return 8030 \n’;
}
}
server{
listen 8040;
location / {
return 200 ‘return 8040 \n’;
}
}
配置完成后:
1. nginx -t 检测配置是否正确;
2. nginx -s reload 重启 Nginx 服务器;
3. 执行 ss -nlt 命令查看端口是否被占用,从而判断 Nginx 服务是否正确启动。
把 121.5.180.193 服务器作为代理服务器,做如下配置( /etc/nginx/conf.d/balance.conf ):
upstream demo_server {
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
配置完成后重启 Nginx 服务器。并且在需要访问的客户端配置好 ip 和域名的映射关系。
# /etc/hosts
121.5.180.193 balance.lion.club
在客户端机器执行 curl http://balance.lion.club/balance/ 命令:
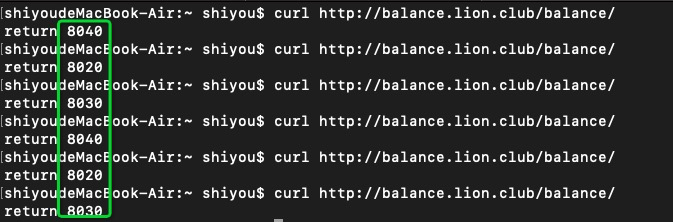
不难看出,负载均衡的配置已经生效了,每次给我们分发的上游服务器都不一样。就是通过简单的轮询策略进行上游服务器分发。
接下来,我们再来了解下 Nginx 的其它分发策略。
hash 算法
通过制定关键字作为 hash key ,基于 hash 算法映射到特定的上游服务器中。关键字可以包含有变量、字符串。
upstream demo_server {
hash $request_uri;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
hash $request_uri 表示使用 request_uri 变量作为 hash 的 key 值,只要访问的 URI 保持不变,就会一直分发给同一台服务器。
ip_hash
根据客户端的请求 ip 进行判断,只要 ip 地址不变就永远分配到同一台主机。它可以有效解决后台服务器 session 保持的问题。
upstream demo_server {
ip_hash;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
最少连接数算法
各个 worker 子进程通过读取共享内存的数据,来获取后端服务器的信息。来挑选一台当前已建立连接数最少的服务器进行分配请求。
语法:least_conn;
上下文:upstream;
示例:
upstream demo_server {
zone test 10M; # zone可以设置共享内存空间的名字和大小
least_conn;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}
最后你会发现,负载均衡的配置其实一点都不复杂。
配置缓存
缓存可以非常有效的提升性能,因此不论是客户端(浏览器),还是代理服务器( Nginx ),乃至上游服务器都多少会涉及到缓存。可见缓存在每个环节都是非常重要的。下面让我们来学习 Nginx 中如何设置缓存策略。
proxy_cache
存储一些之前被访问过、而且可能将要被再次访问的资源,使用户可以直接从代理服务器获得,从而减少上游服务器的压力,加快整个访问速度。
语法:proxy_cache zone | off ; # zone 是共享内存的名称
默认值:proxy_cache off;
上下文:http、server、location
proxy_cache_path
设置缓存文件的存放路径。
语法:proxy_cache_path path [level=levels] …可选参数省略,下面会详细列举
默认值:proxy_cache_path off
上下文:http
参数含义:
-
path缓存文件的存放路径; -
level path的目录层级; -
keys_zone设置共享内存; -
inactive在指定时间内没有被访问,缓存会被清理,默认10分钟;
proxy_cache_key
设置缓存文件的 key 。
语法:proxy_cache_key
默认值:proxy_cache_key s c h e m e scheme schemeproxy_host$request_uri;
上下文:http、server、location
proxy_cache_valid
配置什么状态码可以被缓存,以及缓存时长。
语法:proxy_cache_valid [code…] time;
上下文:http、server、location
配置示例:proxy_cache_valid 200 304 2m;; # 说明对于状态为200和304的缓存文件的缓存时间是2分钟
proxy_no_cache
定义相应保存到缓存的条件,如果字符串参数的至少一个值不为空且不等于“ 0”,则将不保存该响应到缓存。
语法:proxy_no_cache string;
上下文:http、server、location
示例:proxy_no_cache h t t p p r a g m a http_pragma httppragma http_authorization;
proxy_cache_bypass
定义条件,在该条件下将不会从缓存中获取响应。
语法:proxy_cache_bypass string;
上下文:http、server、location
示例:proxy_cache_bypass h t t p p r a g m a http_pragma httppragma http_authorization;
upstream_cache_status 变量
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Java)

总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
理服务器获得,从而减少上游服务器的压力,加快整个访问速度。
语法:proxy_cache zone | off ; # zone 是共享内存的名称
默认值:proxy_cache off;
上下文:http、server、location
proxy_cache_path
设置缓存文件的存放路径。
语法:proxy_cache_path path [level=levels] …可选参数省略,下面会详细列举
默认值:proxy_cache_path off
上下文:http
参数含义:
-
path缓存文件的存放路径; -
level path的目录层级; -
keys_zone设置共享内存; -
inactive在指定时间内没有被访问,缓存会被清理,默认10分钟;
proxy_cache_key
设置缓存文件的 key 。
语法:proxy_cache_key
默认值:proxy_cache_key s c h e m e scheme schemeproxy_host$request_uri;
上下文:http、server、location
proxy_cache_valid
配置什么状态码可以被缓存,以及缓存时长。
语法:proxy_cache_valid [code…] time;
上下文:http、server、location
配置示例:proxy_cache_valid 200 304 2m;; # 说明对于状态为200和304的缓存文件的缓存时间是2分钟
proxy_no_cache
定义相应保存到缓存的条件,如果字符串参数的至少一个值不为空且不等于“ 0”,则将不保存该响应到缓存。
语法:proxy_no_cache string;
上下文:http、server、location
示例:proxy_no_cache h t t p p r a g m a http_pragma httppragma http_authorization;
proxy_cache_bypass
定义条件,在该条件下将不会从缓存中获取响应。
语法:proxy_cache_bypass string;
上下文:http、server、location
示例:proxy_cache_bypass h t t p p r a g m a http_pragma httppragma http_authorization;
upstream_cache_status 变量
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-NQxdJcUD-1713800607034)]
[外链图片转存中…(img-DBKV2RQO-1713800607035)]
[外链图片转存中…(img-P9c5Dzf1-1713800607035)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Java)
[外链图片转存中…(img-HidZRtrx-1713800607035)]
总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。
[外链图片转存中…(img-wXUO958s-1713800607036)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









