







如下有向图,
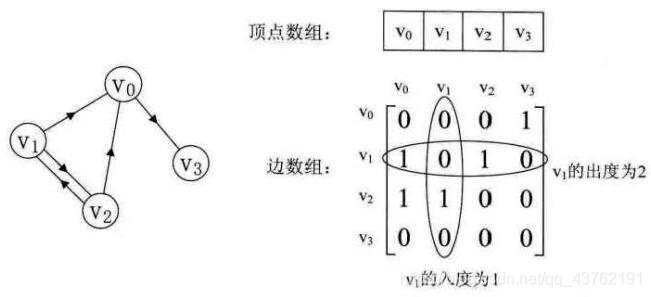
如下网图:

邻接矩阵结构:
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXVEX 100 /* 最大顶点数,应由用户定义 */
#define INFINITY 65535
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef char VertexType; /* 顶点类型应由用户定义 */
typedef int EdgeType; /* 边上的权值类型应由用户定义 */
typedef struct
{
VertexType vexs[MAXVEX]; /* 顶点表 */
EdgeType arc[MAXVEX][MAXVEX];/* 邻接矩阵,可看作边表 */
int numNodes, numEdges; /* 图中当前的顶点数和边数 */
}MGraph;
有了这个结构定义,我们构造一个图,其实就是给顶点表和边表输入数据的过程。我们来看看无向网图的创建代码。
/* 建立无向网图的邻接矩阵表示 */
void CreateMGraph(MGraph *G)
{
int i,j,k,w;
printf(“输入顶点数和边数:\n”);
scanf(“%d,%d”,&G->numNodes,&G->numEdges); /* 输入顶点数和边数 */
for(i = 0;i numNodes;i++) /* 读入顶点信息,建立顶点表 */
scanf(&G->vexs[i]);
for(i = 0;i numNodes;i++)
for(j = 0;j numNodes;j++)
G->arc[i][j]=INFINITY; /* 邻接矩阵初始化 */
for(k = 0;k numEdges;k++) /* 读入numEdges条边,建立邻接矩阵 */
{
printf(“输入边(vi,vj)上的下标i,下标j和权w:\n”);
scanf(“%d,%d,%d”,&i,&j,&w); /* 输入边(vi,vj)上的权w */
G->arc[i][j]=w;
G->arc[j][i]= G->arc[i][j]; /* 因为是无向图,矩阵对称 */
}
}
从代码中也可以得到,n 个顶点和e 条边的无向网图的创建,时间复杂度O(n^2)。
DFS:深度优先
如果使用邻接矩阵,代码如下:
Boolean visited[MAXVEX]; /* 访问标志的数组 */
/* 邻接矩阵的深度优先递归算法 */
void DFS(MGraph G, int i)
{
int j;
visited[i] = TRUE;
printf("%c ", G.vexs[i]);/* 打印顶点,也可以其它操作 */
for(j = 0; j < G.numVertexes; j++)
if(G.arc[i][j] == 1 && !visited[j])
DFS(G, j);/* 对为访问的邻接顶点递归调用 */
}
/* 邻接矩阵的深度遍历操作 */
void DFSTraverse(MGraph G)
{
int i;
for(i = 0; i < G.numVertexes; i++)
visited[i] = FALSE; /* 初始所有顶点状态都是未访问过状态 */
for(i = 0; i < G.numVertexes; i++)
if(!visited[i]) /* 对未访问过的顶点调用DFS,若是连通图,只会执行一次 */
DFS(G, i);
}
如果使用邻接表结构,代码如下:
Boolean visited[MAXSIZE]; /* 访问标志的数组 */
/* 邻接表的深度优先递归算法 */
void DFS(GraphAdjList GL, int i)
{
EdgeNode *p;
visited[i] = TRUE;
printf("%c ",GL->adjList[i].data);/* 打印顶点,也可以其它操作 */
p = GL->adjList[i].firstedge;
while§
{
if(!visited[p->adjvex])
DFS(GL, p->adjvex);/* 对为访问的邻接顶点递归调用 */
p = p->next;
}
}
/* 邻接表的深度遍历操作 */
void DFSTraverse(GraphAdjList GL)
{
int i;
for(i = 0; i < GL->numVertexes; i++)
visited[i] = FALSE; /* 初始所有顶点状态都是未访问过状态 */
for(i = 0; i < GL->numVertexes; i++)
if(!visited[i]) /* 对未访问过的顶点调用DFS,若是连通图,只会执行一次 */
DFS(GL, i);
}
BFS:广度优先
如果说图的深度优先遍历类似树的前序遍历, 那么图的广度优先遍历就类似于树的层序遍历了。
以下是邻接矩阵结构的广度优先遍历算法:
/* 邻接矩阵的广度遍历算法 */
void BFSTraverse(MGraph G)
{
int i, j;
Queue Q;
for(i = 0; i < G.numVertexes; i++)
visited[i] = FALSE;
InitQueue(&Q); /* 初始化一辅助用的队列 */
for(i = 0; i < G.numVertexes; i++) /* 对每一个顶点做循环 */
{
if (!visited[i]) /* 若是未访问过就处理 */
{
visited[i]=TRUE; /* 设置当前顶点访问过 */
printf("%c ", G.vexs[i]);/* 打印顶点,也可以其它操作 */
EnQueue(&Q,i); /* 将此顶点入队列 */
while(!QueueEmpty(Q)) /* 若当前队列不为空 */
{
DeQueue(&Q,&i); /* 将队对元素出队列,赋值给i */
for(j=0;j<G.numVertexes;j++)
{
/* 判断其它顶点若与当前顶点存在边且未访问过 */
if(G.arc[i][j] == 1 && !visited[j])
{
visited[j]=TRUE; /* 将找到的此顶点标记为已访问 */
printf("%c ", G.vexs[j]); /* 打印顶点 */
EnQueue(&Q,j); /* 将找到的此顶点入队列 */
}
}
}
}
}
}
对于邻接表的广度优先遍历,代码与邻接矩阵差异不大,代码如下:
/* 邻接表的广度遍历算法 */
void BFSTraverse(GraphAdjList GL)
{
int i;
EdgeNode *p;
Queue Q;
for(i = 0; i < GL->numVertexes; i++)
visited[i] = FALSE;
InitQueue(&Q);
for(i = 0; i < GL->numVertexes; i++)
{
if (!visited[i])
{
visited[i]=TRUE;
printf("%c ",GL->adjList[i].data);/* 打印顶点,也可以其它操作 */
EnQueue(&Q,i);
while(!QueueEmpty(Q))
{
DeQueue(&Q,&i);
p = GL->adjList[i].firstedge; /* 找到当前顶点的边表链表头指针 */
while§
{
if(!visited[p->adjvex]) /* 若此顶点未被访问 */
{
visited[p->adjvex]=TRUE;
printf("%c ",GL->adjList[p->adjvex].data);
EnQueue(&Q,p->adjvex); /* 将此顶点入队列 */
}
p = p->next; /* 指针指向下一个邻接点 */
}
}
}
}
}
这俩算法倒是在运筹学里学过。
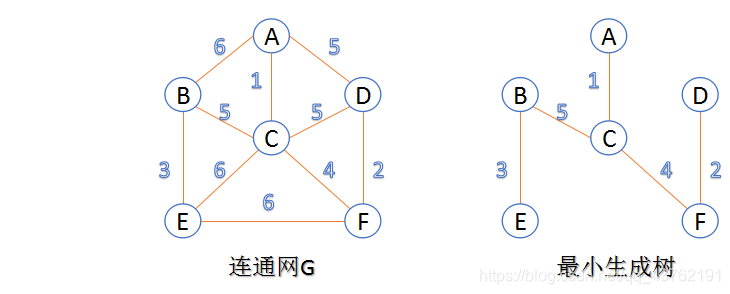
Prim算法
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
1、图的所有顶点集合为V;初始令集合u={s},v=V−u;
2、在两个集合u,v能够组成的边中,选择一条代价最小的边(u0,v0),加入到最小生成树中,并把v0并入到集合u中。
3、重复上述步骤,直到最小生成树有n-1条边或者n个顶点为止。
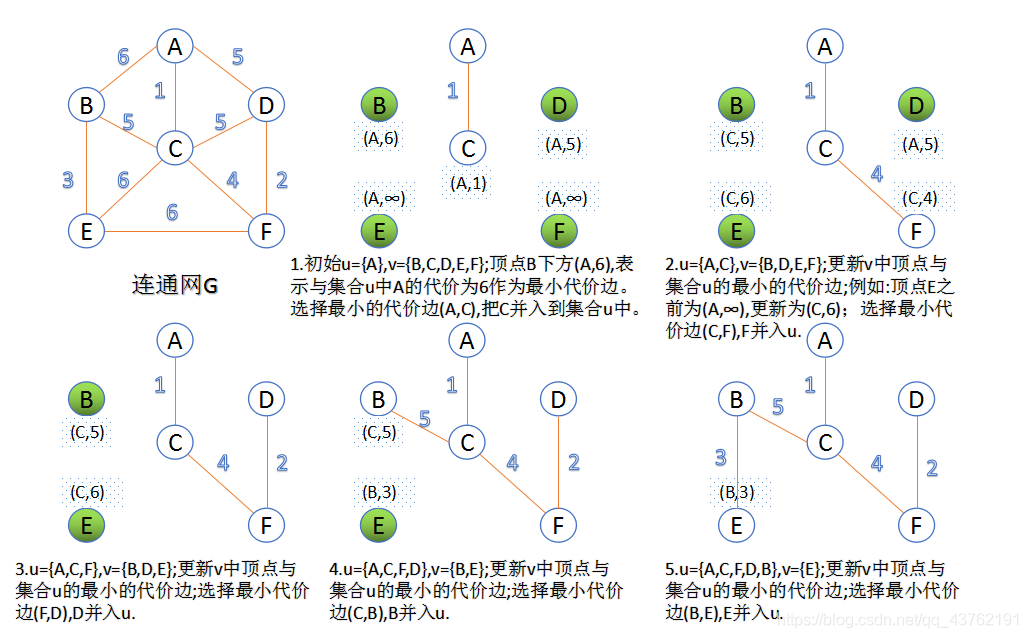
(先将图构造成一个邻接矩阵G)
/* Prim算法生成最小生成树 */
void MiniSpanTree_Prim(MGraph G)
{
int min, i, j, k;
int adjvex[MAXVEX]; /* 保存相关顶点下标 */
int lowcost[MAXVEX]; /* 保存相关顶点间边的权值 */
lowcost[0] = 0;/* 初始化第一个权值为0,即v0加入生成树 */
/* lowcost的值为0,在这里就是此下标的顶点已经加入生成树 */
adjvex[0] = 0; /* 初始化第一个顶点下标为0 */
for(i = 1; i < G.numVertexes; i++) /* 循环除下标为0外的全部顶点 */
{
lowcost[i] = G.arc[0][i]; /* 将v0顶点与之有边的权值存入数组 */
adjvex[i] = 0; /* 初始化都为v0的下标 */
}
for(i = 1; i < G.numVertexes; i++)
{
min = INFINITY; /* 初始化最小权值为∞, */
/* 通常设置为不可能的大数字如32767、65535等 */
j = 1;k = 0;
while(j < G.numVertexes) /* 循环全部顶点 */
{
if(lowcost[j]!=0 && lowcost[j] < min)/* 如果权值不为0且权值小于min */
{
min = lowcost[j]; /* 则让当前权值成为最小值 */
k = j; /* 将当前最小值的下标存入k */
}
j++;
}
printf(“(%d, %d)\n”, adjvex[k], k);/* 打印当前顶点边中权值最小的边 */
lowcost[k] = 0;/* 将当前顶点的权值设置为0,表示此顶点已经完成任务 */
for(j = 1; j < G.numVertexes; j++) /* 循环所有顶点 */
{
if(lowcost[j]!=0 && G.arc[k][j] < lowcost[j])
{/* 如果下标为k顶点各边权值小于此前这些顶点未被加入生成树权值 */
lowcost[j] = G.arc[k][j];/* 将较小的权值存入lowcost相应位置 */
adjvex[j] = k; /* 将下标为k的顶点存入adjvex */
}
}
}
}
Kruskal算法
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
- 把图中的所有边按代价从小到大排序;
- 把图中的n个顶点看成独立的n棵树组成的森林;
- 按权值从小到大选择边,所选的边连接的两个顶点ui,vi,应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
- 重复(3),直到所有顶点都在一颗树内或者有n-1条边为止。

typedef struct
{
int begin;
int end;
int weight;
}Edge; /* 对边集数组Edge结构的定义 */
/* 生成最小生成树 */
void MiniSpanTree_Kruskal(MGraph G)
{
int i, j, n, m;
int k = 0;
int parent[MAXVEX];/* 定义一数组用来判断边与边是否形成环路 */
Edge edges[MAXEDGE];/* 定义边集数组,edge的结构为begin,end,weight,均为整型 */
/* 用来构建边集数组并排序********************* */
for ( i = 0; i < G.numVertexes-1; i++)
{
for (j = i + 1; j < G.numVertexes; j++)
{
if (G.arc[i][j]<INFINITY)
{
edges[k].begin = i;
edges[k].end = j;
edges[k].weight = G.arc[i][j];
k++;
}
}
}
sort(edges, &G);
/* ******************************************* */
for (i = 0; i < G.numVertexes; i++)
parent[i] = 0; /* 初始化数组值为0 */
printf(“打印最小生成树:\n”);
for (i = 0; i < G.numEdges; i++) /* 循环每一条边 */
{
n = Find(parent,edges[i].begin);
m = Find(parent,edges[i].end);
if (n != m) /* 假如n与m不等,说明此边没有与现有的生成树形成环路 */
{
parent[n] = m; /* 将此边的结尾顶点放入下标为起点的parent中。 */
/* 表示此顶点已经在生成树集合中 */
printf(“(%d, %d) %d\n”, edges[i].begin, edges[i].end, edges[i].weight);
}
}
}
克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势; 而普里姆算法对于稠密图,即边数非常多的情况会更好一些。
对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点。关于最短路径主要有两种算法,迪杰斯特拉(Dijkstra) 算法和弗洛伊德(Floyd) 算法。
这俩算法在运筹学中也学了。
Dijkstra 算法
文字解释枯燥无味,我选择看图:(求解节点“1”到其他所有节点的最短路径)
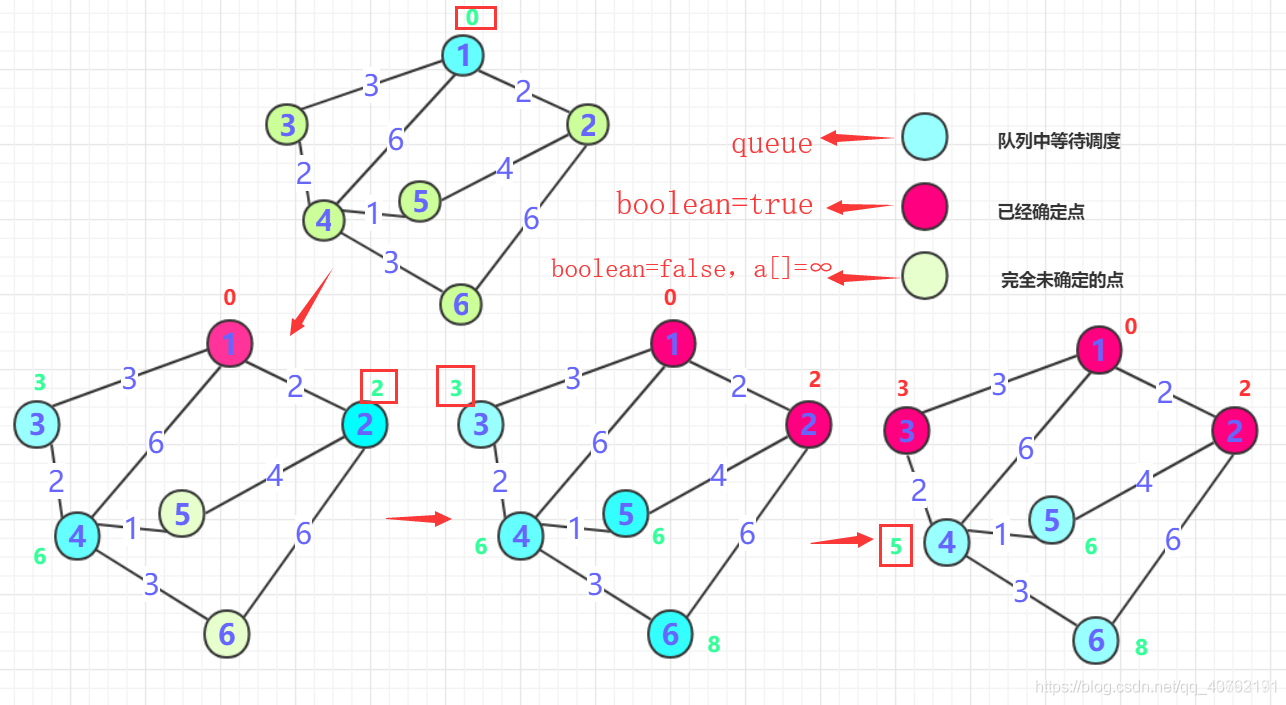
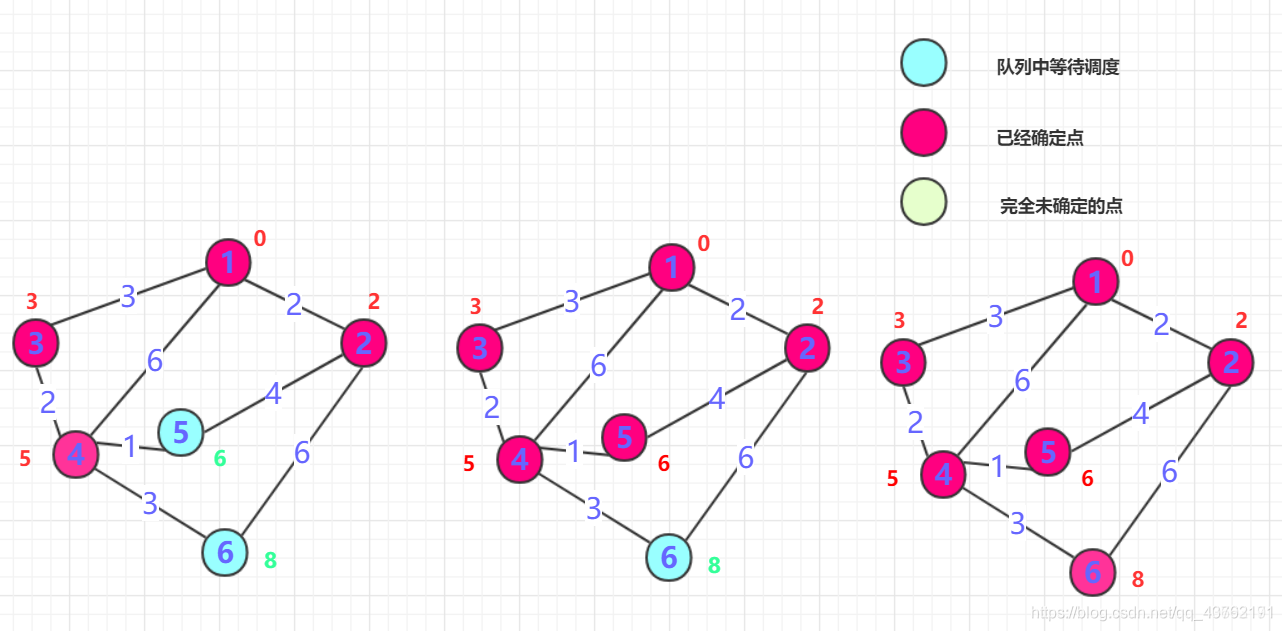
这是我能找到的最容易理解的图了,其他图文讲的讳莫如深,我不喜欢。
上面这两张理解完,再重新看一套,上面这两张是用来了解一下啥是迪杰斯特拉算法,接下来这套是用来写代码的:
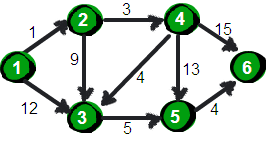


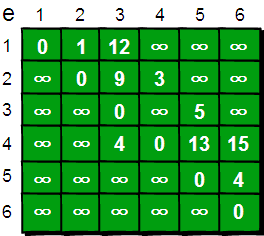



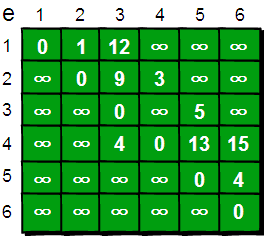
下面我们来模拟一下:
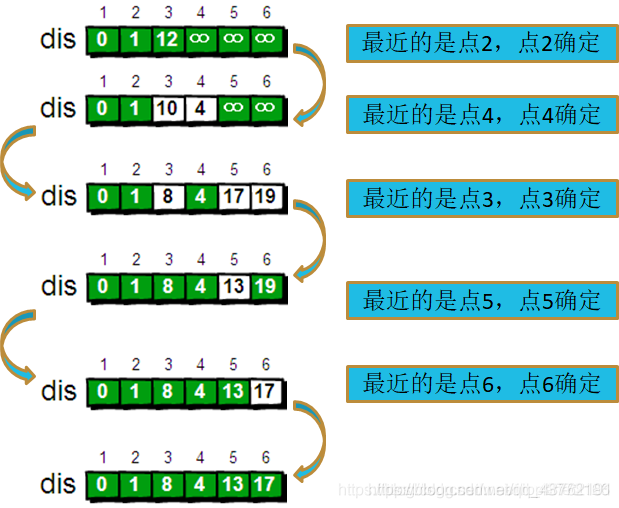
直接看这套的时候,会有点晕,不过有前面那套的铺垫,就好多了。
#include
#include
using namespace std;
const int INF = 0x3f3f3f3f, N = 205;
int ma[N][N];
int dis[N];
bool vis[N];
int n, m, st, ed;
void init()
{
// 初始化ma数组
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ma[i][j] = (i == j ? 0 : INF);
}
void Dijk()
{
for (int i = 0; i < n - 1; i++){
int minv = INF, k; // k用来存储最小的且没被松弛过的城市
for (int j = 0; j < n; j++){
if (minv > dis[j] && !vis[j]){
minv = dis[j];
k = j;
}
}
vis[k] = 1;
for (int h = 0; h < n; h++)
dis[h] = min(dis[h], dis[k] + ma[k][h]);
}
}
int main(void)
{
int a, b, c;
while (cin >> n >> m){
// 初始化ma数组
init();
for (int i = 0; i < m; i++){
cin >> a >> b >> c;
if (ma[a][b] > c)
ma[a][b] = ma[b][a] = c;
}
// 输入起点和终点
cin >> st >> ed;
// 初始化dis数组
for (int i = 0; i < n; i++)
dis[i] = ma[st][i];
// 初始化vis数组
memset(vis, 0, sizeof vis);
vis[st] = 1;
Dijk();
cout << (dis[ed] == INF ? -1 : dis[ed]) << endl;
}
return 0;
}
Floyd 算法
Floyd-Warshall算法,简称Floyd算法,用于求解任意两点间的最短距离,时间复杂度为O(n^3)。
适用范围:无负权回路即可,边权可正可负,运行一次算法即可求得任意两点间最短路。
核心思想:
任意节点i到j的最短路径两种可能:
1、直接从i到j;
2、从i经过若干个节点k到j。
实现步骤:
第1步:初始化map矩阵。
矩阵中map[i][j]的距离为顶点i到顶点j的权值;
如果i和j不相邻,则map[i][j]=∞。
如果i==j,则map[i][j]=0;
第2步:以顶点A(假设是第1个顶点)为中介点,若a[i][j] > a[i][1]+a[1][j],则设置a[i][j]=a[i][1]+a[1][j]。
不好理解,看图吧,虽然图也挺抽象
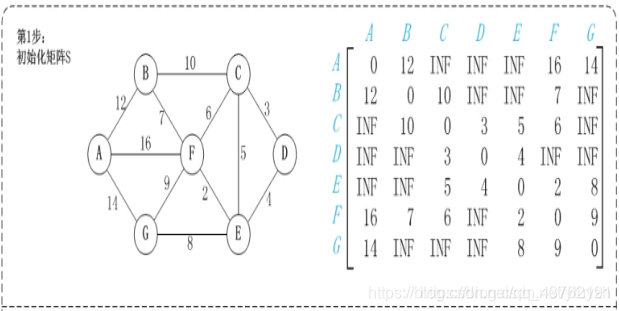
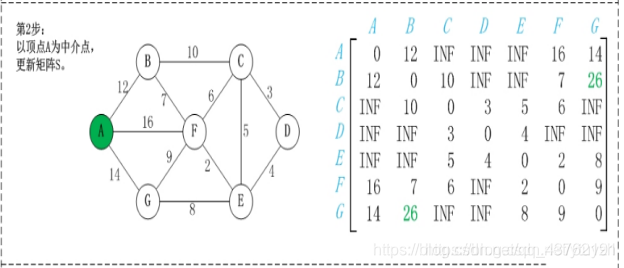
这步可以理解不?理解不了慢慢理解,下面都是这种操作。
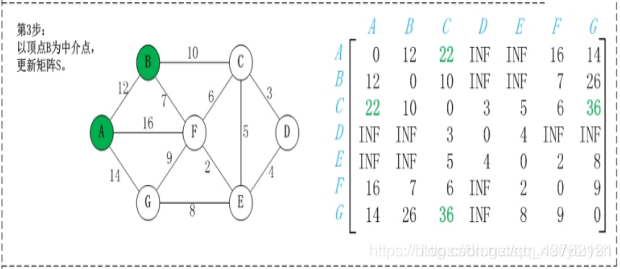

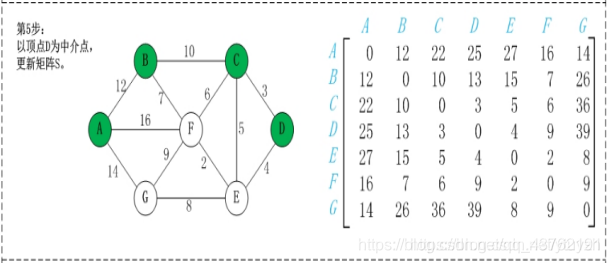
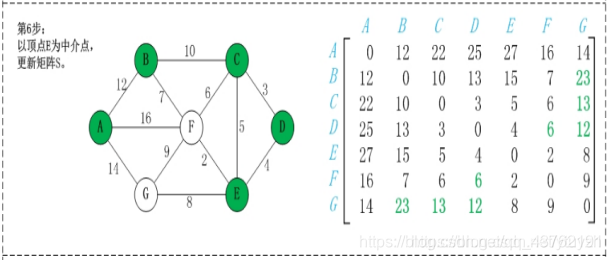
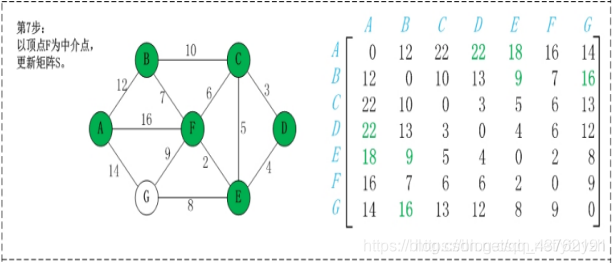
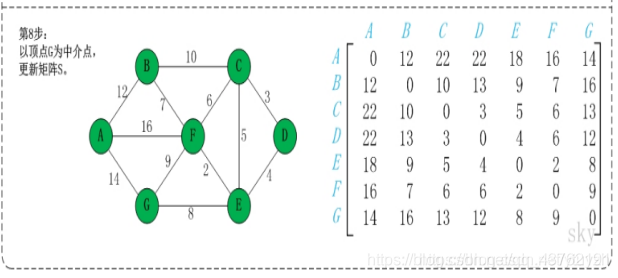
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单
缺点:时间复杂度比较高,不适合计算大量数据。
时间复杂度:O(n^3);空间复杂度:O(n^2);
#define mem(a,b) memset(a,b,sizeof(a))
const int inf=1<<29;
int main()
{
int map[10][10],n,m,t1,t2,t3;
scanf(“%d%d”,&n,&m);//n表示顶点个数,m表示边的条数
//初始化
for(int i=1; i<=n; i++)
for(int j=1; j<=n; j++)
if(i==j)
map[i][j]=0;
else
map[i][j]=inf;
//读入边
for(int i=1; i<=m; i++)
{
scanf(“%d%d%d”,&t1,&t2,&t3);
map[t1][t2]=t3;
}
//弗洛伊德(Floyd)核心语句
for(int k=1; k<=n; k++)
for(int i=1; i<=n; i++)
for(int j=1; j<=n; j++)
if(map[i][k]+map[k][j]<map[i][j])
map[i][j]=map[i][k]+map[k][j];
for(int i=1; i<=n; i++)
{
for(int j=1; j<=n; j++)
printf(“%10d”,map[i][j]);
printf(“\n”);
}
return 0;
}
(系统提醒:看完这篇至少需要半个小时,建议收藏下次再看)
什么是拓扑排序?在离散数学里面有教,我还记得当时的栗子:要学数据科学,必须先学C++、数据结构、数据库、数学分析、线性代数;要学数据结构、数据库,必须先学C/C++,就是一个次序的问题。
抽象到图里面,就是这样的:
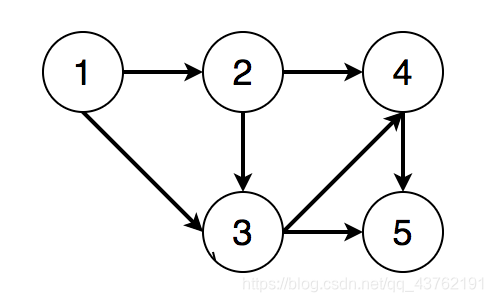
1、结点1必须在结点2、3之前
2、结点2必须在结点3、4之前
3、结点3必须在结点4、5之前
4、结点4必须在结点5之前
则一个满足条件的拓扑排序为[1, 2, 3, 4, 5]。
若我们删去图中4、5结点之前的有向边,上图变为如下所示:
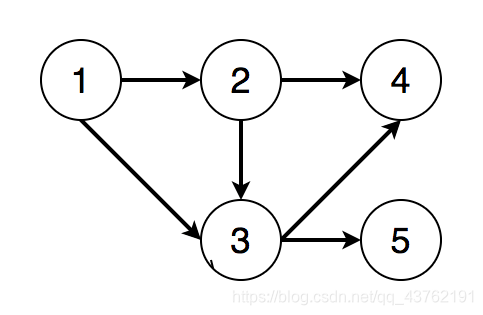
则我们可得到两个不同的拓扑排序结果:[1, 2, 3, 4, 5]和[1, 2, 3, 5, 4]。
要想完成拓扑排序,我们每次都应当从入度为0的结点开始遍历。因为只有入度为0的结点才能够成为拓扑排序的起点。
由此我们可以进一步得出一个改进的深度优先遍历或广度优先遍历算法来完成拓扑排序。以广度优先遍历为例,这一改进后的算法与普通的广度优先遍历唯一的区别在于我们应当保存每一个结点对应的入度,并在遍历的每一层选取入度为0的结点开始遍历(而普通的广度优先遍历则无此限制,可以从该吃呢个任意一个结点开始遍历)。
这个算法描述如下:
1、初始化一个int[] inDegree保存每一个结点的入度。
2、对于图中的每一个结点的子结点,将其子结点的入度加1。
3、选取入度为0的结点开始遍历,并将该节点加入输出。
4、对于遍历过的每个结点,更新其子结点的入度:将子结点的入度减1。
5、重复步骤3,直到遍历完所有的结点。
如果无法遍历完所有的结点,则意味着当前的图不是有向无环图。不存在拓扑排序。
#include
#include
#include
#include
#include
#include
using namespace std;
const int maxn=505;
vector ve[maxn]; //保存出度的节点
int inde[maxn]; //入度的数目
bool vis[maxn]; //是否删除此节点
vector re; //保存结果
int n,m;
//初始化
void init()
{
memset (inde,0,sizeof(inde));
for (int i=0;i<maxn;i++)
{
ve[i].clear();
vis[i]=false;
}
re.clear();
}
//广度优先搜索
void bfs (int x)
{
queue q;
q.push(x);
vis[x]=true;
while (!q.empty())
{
int now=q.front();
q.pop();
//将结果放入容器中
re.push_back(now);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
每年转战互联网行业的人很多,说白了也是冲着高薪去的,不管你是即将步入这个行业还是想转行,学习是必不可少的。作为一个Java开发,学习成了日常生活的一部分,不学习你就会被这个行业淘汰,这也是这个行业残酷的现实。
如果你对Java感兴趣,想要转行改变自己,那就要趁着机遇行动起来。或许,这份限量版的Java零基础宝典能够对你有所帮助。

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
ear();
vis[i]=false;
}
re.clear();
}
//广度优先搜索
void bfs (int x)
{
queue q;
q.push(x);
vis[x]=true;
while (!q.empty())
{
int now=q.front();
q.pop();
//将结果放入容器中
re.push_back(now);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-2Pp1RFUU-1713462219294)]
[外链图片转存中…(img-OpXVqRNN-1713462219295)]
[外链图片转存中…(img-QTS4fNNP-1713462219295)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
最后
每年转战互联网行业的人很多,说白了也是冲着高薪去的,不管你是即将步入这个行业还是想转行,学习是必不可少的。作为一个Java开发,学习成了日常生活的一部分,不学习你就会被这个行业淘汰,这也是这个行业残酷的现实。
如果你对Java感兴趣,想要转行改变自己,那就要趁着机遇行动起来。或许,这份限量版的Java零基础宝典能够对你有所帮助。
[外链图片转存中…(img-bBvfNJz7-1713462219295)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 2849
2849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









