







 本文详细探讨了Apache Calcite中的HepPlanner优化器,包括HepRelVertex和HepInstruction的基本概念,以及HepPlanner的处理流程,如初始化HepProgram、设置根节点和规则优化。通过示例展示了谓词下推、常量折叠和列裁剪等优化策略的作用,解释了这些优化在减少数据传输、提高效率方面的价值。同时,文章介绍了Calcite优化器的实现,特别是HepPlanner和VolcanoPlanner的工作原理。
本文详细探讨了Apache Calcite中的HepPlanner优化器,包括HepRelVertex和HepInstruction的基本概念,以及HepPlanner的处理流程,如初始化HepProgram、设置根节点和规则优化。通过示例展示了谓词下推、常量折叠和列裁剪等优化策略的作用,解释了这些优化在减少数据传输、提高效率方面的价值。同时,文章介绍了Calcite优化器的实现,特别是HepPlanner和VolcanoPlanner的工作原理。
在 Calcite 的代码里,有一个测试类(org.apache.calcite.test.RelOptRulesTest)汇集了对目前内置所有 Rules 的测试 case,这个测试类可以方便我们了解各个 Rule 的作用。在这里有下面一条 SQL,通过这条语句来说明一下上面介绍的这三种规则。
1 |
select 10 + 30, users.name, users.age |
谓词下推(Predicate Pushdown)
关于谓词下推,它主要还是从关系型数据库借鉴而来,关系型数据中将谓词下推到外部数据库用以减少数据传输;属于逻辑优化,优化器将谓词过滤下推到数据源,使物理执行跳过无关数据。最常见的例子就是 join 与 filter 操作一起出现时,提前执行 filter 操作以减少处理的数据量,将 filter 操作下推,以上面例子为例,示意图如下(对应 Calcite 中的 FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN Rule):
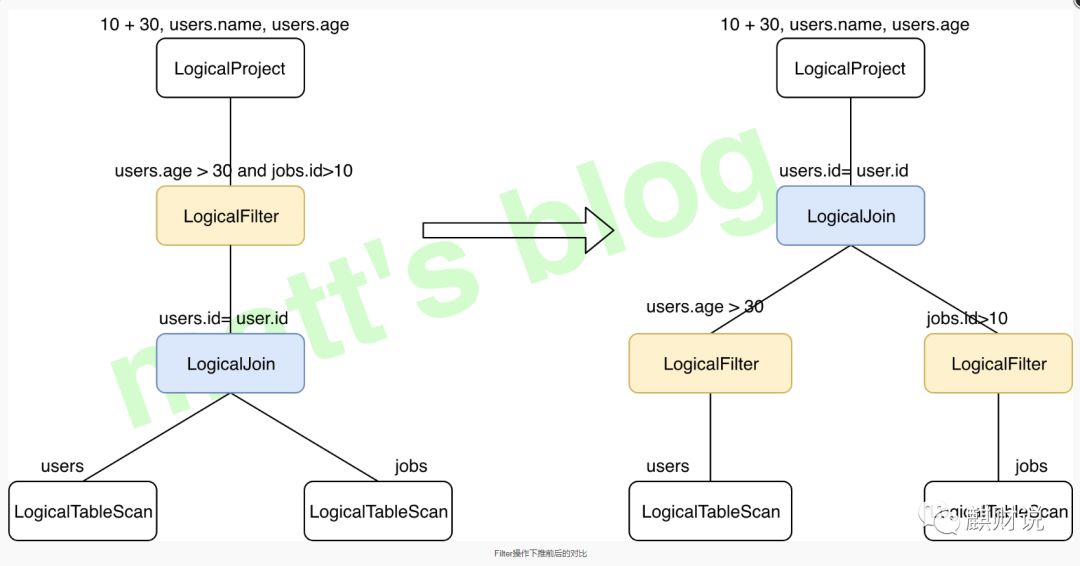
Filter操作下推前后的对比
在进行 join 前进行相应的过滤操作,可以极大地减少参加 join 的数据量。
常量折叠(Constant Folding)
常量折叠也是常见的优化策略,这个比较简单、也很好理解,可以看下 编译器优化 – 常量折叠 这篇文章,基本不用动脑筋就能理解,对于我们这里的示例,有一个常量表达式 10 + 30,如果不进行常量折叠,那么每行数据都需要进行计算,进行常量折叠后的结果如下图所示( 对应 Calcite 中的 ReduceExpressionsRule.PROJECT_INSTANCE Rule):
 常量折叠前后的对比
常量折叠前后的对比
列裁剪(Column Pruning)
列裁剪也是一个经典的优化规则,在本示例中对于jobs 表来说,并不需要扫描它的所有列值,而只需要列值 id,所以在扫描 jobs 之后需要将其他列进行裁剪,只留下列 id。这个优化带来的好处很明显,大幅度减少了网络 IO、内存数据量的消耗。裁剪前后的示意图如下(不过并没有找到 Calcite 对应的 Rule):
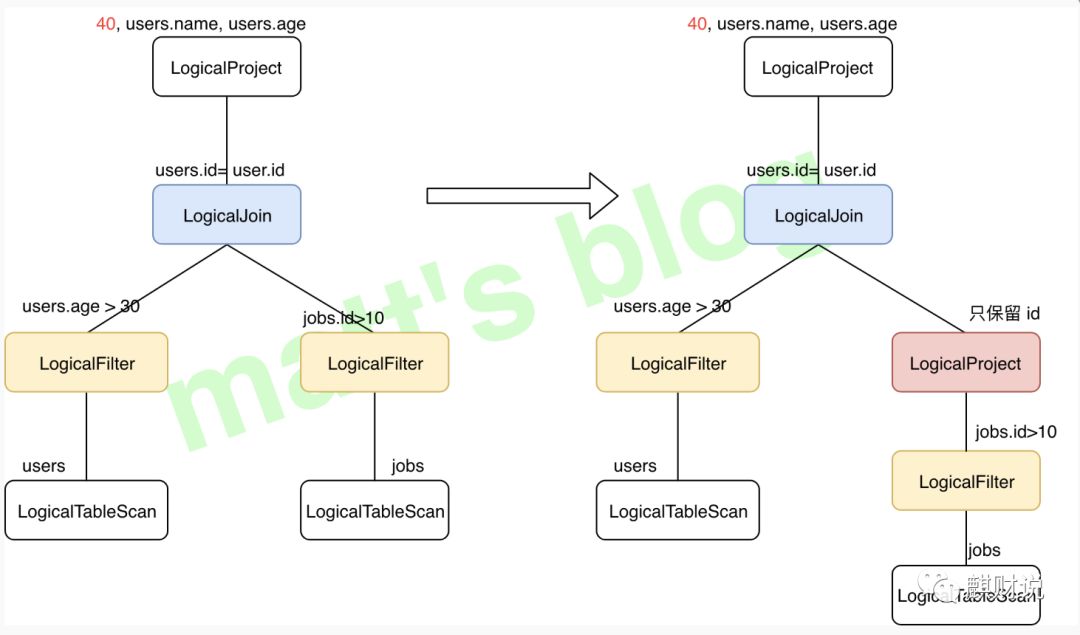
列裁剪前后的对比
Calcite 中的优化器实现
===============
有了前面的基础后,这里来看下 Calcite 中优化器的实现,RelOptPlanner 是 Calcite 中优化器的基类,其子类实现如下图所示:
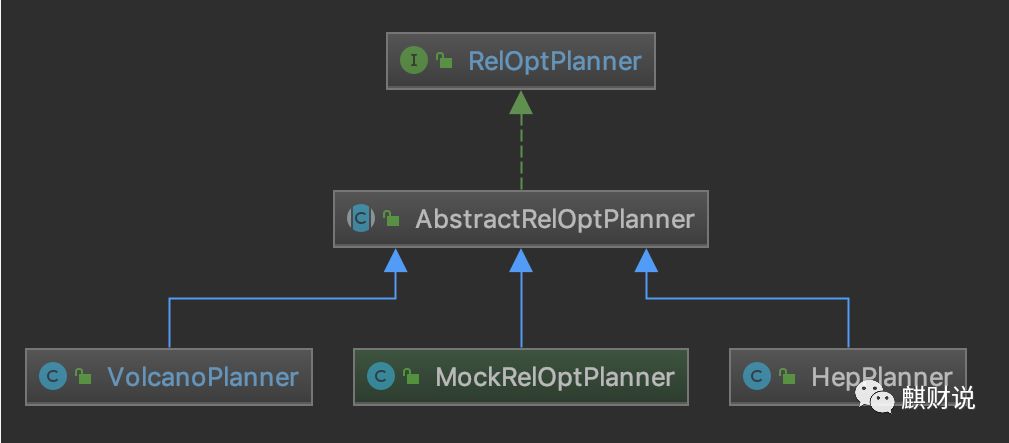
RelOptPlanner
Calcite 中关于优化器提供了两种实现:
-
HepPlanner:就是前面 RBO 的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现 rule match 的情况才算完成;
-
VolcanoPlanner:就是前面 CBO 的实现,它会一直迭代 rules,直到找到 cost 最小的 paln。
前面提到过像calcite这类查询优化器最核心的两个问题之一是怎么把优化规则应用到关系代数相关的RelNode Tree上。所以在阅读calicite的代码时就得带着这个问题去看看它的实现过程,然后才能判断它的代码实现得是否优雅。
calcite的每种规则实现类(RelOptRule的子类)都会声明自己应用在哪种RelNode子类上,每个RelNode子类其实都可以看成是一种operator(中文常翻译成算子)。
VolcanoPlanner就是优化器,用的是动态规划算法,在创建VolcanoPlanner的实例后,通过calcite的标准jdbc接口执行sql时,默认会给这个VolcanoPlanner的实例注册将近90条优化规则(还不算常量折叠这种最常见的优化),所以看代码时,知道什么时候注册可用的优化规则是第一步(调用VolcanoPlanner.addRule实现),这一步比较简单。
接下来就是如何筛选规则了,当把语法树转成RelNode Tree后是没有必要把前面注册的90条优化规则都用上的,所以需要有个筛选的过程,因为每种规则是有应用范围的,按RelNode Tree的不同节点类型就可以筛选出实际需要用到的优化规则了。这一步说起来很简单,但在calcite的代码实现里是相当复杂的,也是非常关键的一步,是从调用VolcanoPlanner.setRoot方法开始间接触发的,如果只是静态的看代码不跑起来跟踪调试多半摸不清它的核心流程的。筛选出来的优化规则会封装成VolcanoRuleMatch,然后扔到RuleQueue里,而这个RuleQueue正是接下来执行动态规划算法要用到的核心类。筛选规则这一步的代码实现很晦涩。
第三步才到VolcanoPlanner.findBestExp,本质上就是一个动态规划算法的实现,但是最值得关注的还是怎么用第二步筛选出来的规则对RelNode Tree进行变换,变换后的形式还是一棵RelNode Tree,最常见的是把LogicalXXX开头的RelNode子类换成了EnumerableXXX或BindableXXX,总而言之,看看具体优化规则的实现就对了,都是繁琐的体力活。
一个优化器,理解了上面所说的三步基本上就抓住重点了。
—— 来自【zhh-4096 】的微博
下面详细讲述一下这两种 planner 在 Calcite 内部的具体实现。
HepPlanner
使用 HepPlanner 实现的完整代码见 SqlHepTest。
HepPlanner 中的基本概念
这里先看下 HepPlanner 的一些基本概念,对于后面的理解很有帮助。
HepRelVertex
HepRelVertex 是对 RelNode 进行了简单封装。HepPlanner 中的所有节点都是 HepRelVertex,每个 HepRelVertex 都指向了一个真正的 RelNode 节点。
1 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









