







- 同一月,GitHub上Star突破15k+,截止发文时点,已经16K+!
然后就在这个月,PaddleOCR的项目团队宣布,根据之前项目中碰到的问题以及解决经验,经过整组团队人员的共同努力,构建并发布新一代的OCR系统PP-OCRv2。
PP-OCRv2CPU推理速度相比于PP-OCR server提升220%;效果相比于PP-OCR mobile 提升7%
简单的说,就是更高更快更强!

同时在功能加强的基础上,大小仅13M(检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M),可以轻松部署服务器端和移动端。
光说不练假把式,说了那么多我们先来一起看下PP-OCRv2的实际识别效果究竟如何:
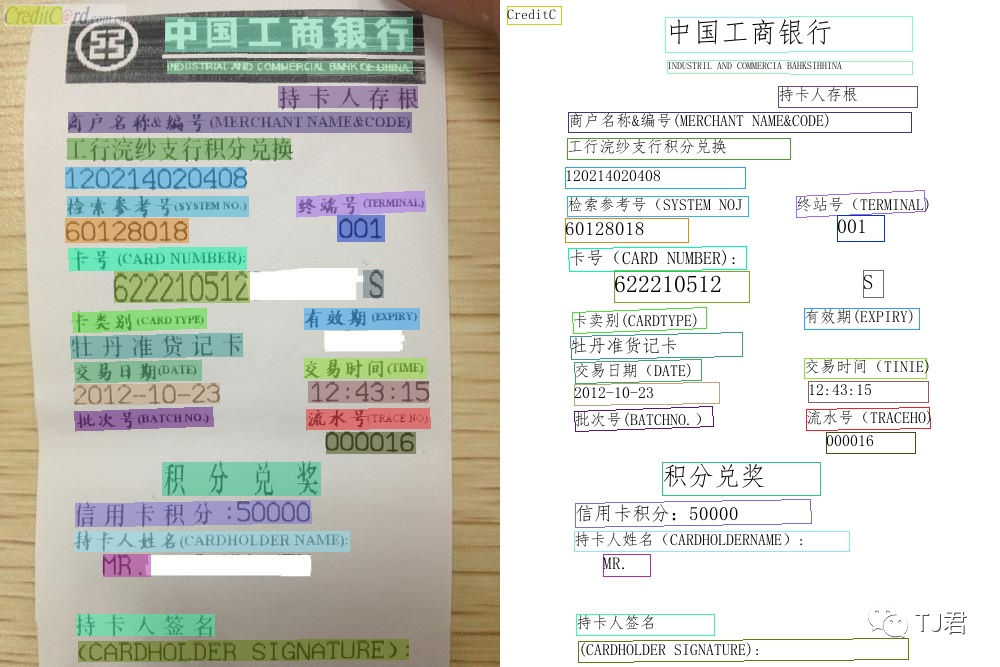
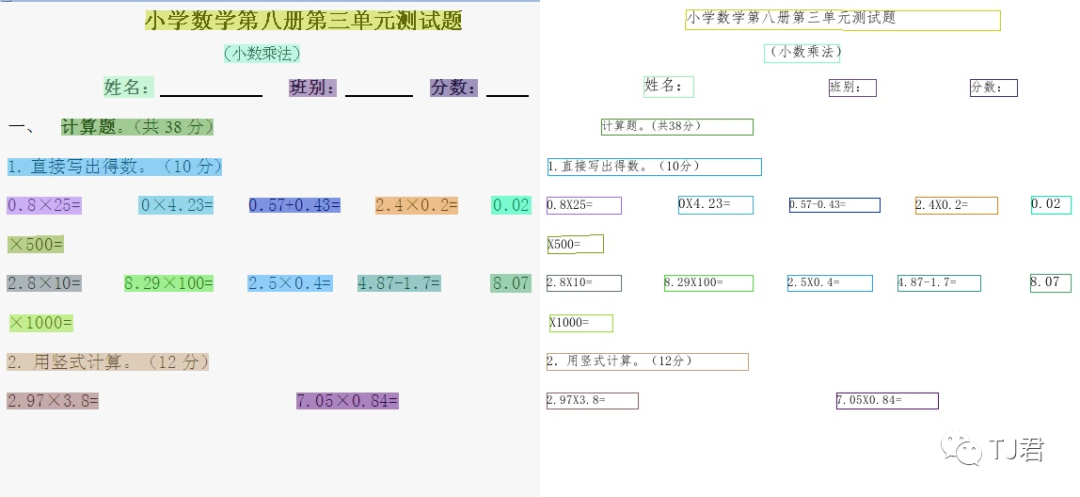

看着的确不错,别急,还有各种其他不同的场景,例如:
中文识别模型


英文识别模型

多语言识别模型


光看效果是不错,但是如果程序猿小伙伴遇到问题不会用怎么办?
项目组考虑到这点,特地为众多好学的程序猿小伙伴准备了丰富详尽的教程文档。



从项目环境的准备,到项目的运行,快速开始,各种模型的设计训练,各种实际的部署以及常见的问题,光看看这个教程,就感觉受益匪浅了~
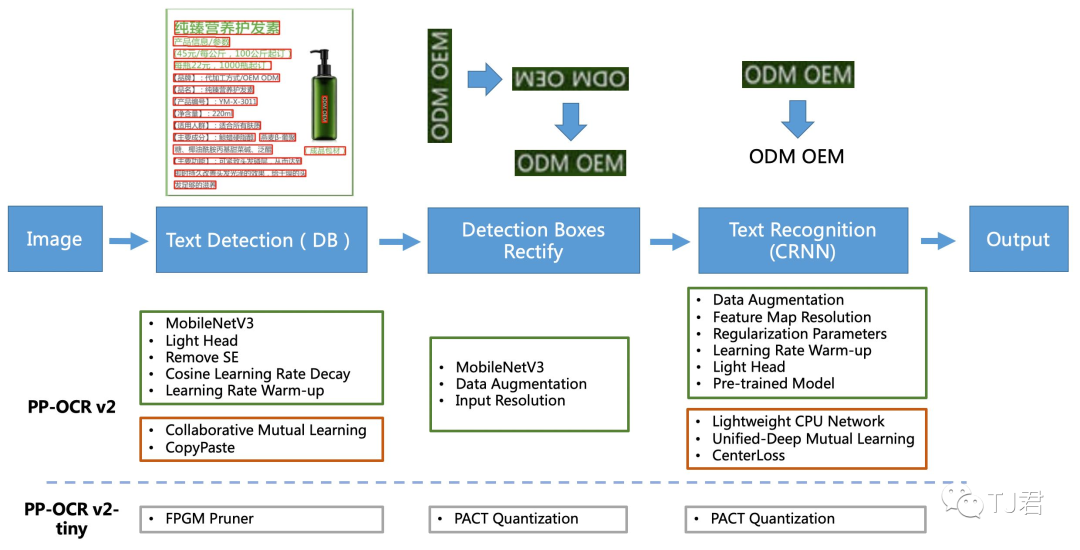
总的来说, PP-OCRv2是在PP-OCR的基础上,在5个方面重点优化:
-
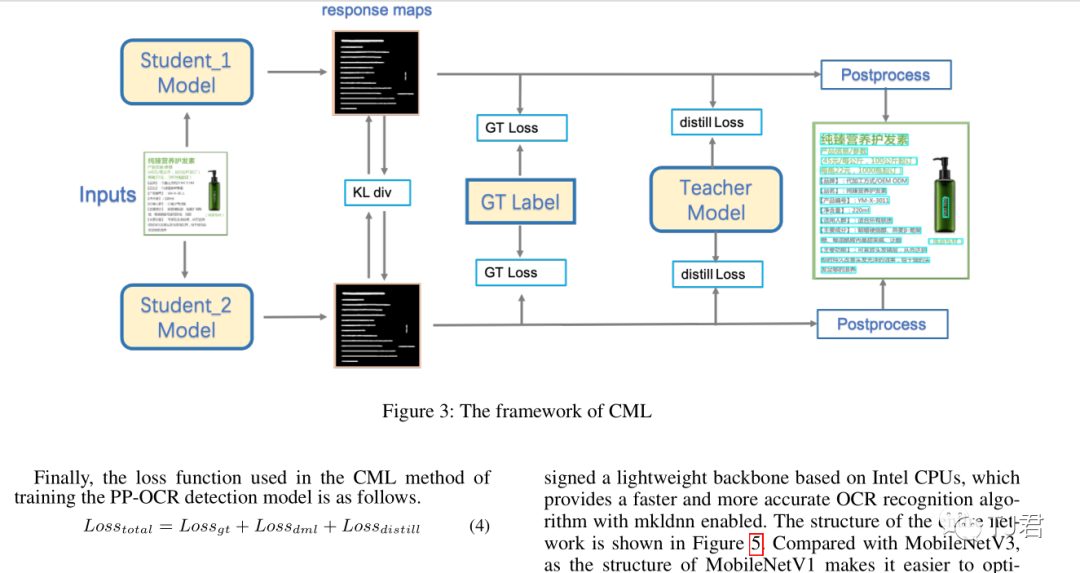
检测模型采用CML协同互学习知识蒸馏策略
-
CopyPaste数据增广策略
-
识别模型采用LCNet轻量级骨干网络
-
UDML 改进知识蒸馏策略
-
Enhanced CTC loss损失函数改进
(如下图红框所示)进一步在推理速度和预测效果上取得明显提升。
对于上述更新内容有兴趣想深度钻研的小伙伴,这里还有一份长达8页的文档,可供研究学习(下载地址同项目地址一并关注公众号回复关键字后提供)

最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
有帮助,需要这份全套学习资料的朋友可以戳我获取!!**](https://bbs.csdn.net/topics/618164986)
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









