







Object singletonObject = singletonObjects.get(className);
if (singletonObject == null) {
//再从半成品缓存中查找
singletonObject = earlySingletonObjects.get(className);
}
return singletonObject;
}
@SuppressWarnings(“unchecked”)
private static T getBean(Class clazz) throws IllegalAccessException, InstantiationException {
//先从缓存中获取
String className = clazz.getSimpleName();
Object singleton = getSingleton(className);
if (singleton != null) {
return (T) singleton;
}
synchronized (singletonObjects) {
singleton = singletonObjects.get(className);
//这里需要再进行一次检查
if (singleton != null) {
return (T) singleton;
}
//实例化对象
T instance = clazz.newInstance();
//实例化完成后,就将这个半成品放入到缓存中
earlySingletonObjects.put(className, instance);
//获取当前类中的所有字段
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
//允许访问私有变量
field.setAccessible(true);
//判断字段是否被@Load注解修饰
boolean isUseLoad = field.isAnnotationPresent(Load.class);
if (!isUseLoad) {
continue;
}
//获取需要被注入的字段的class
Class<?> fieldType = field.getType();
//递归获取字段的实例对象
Object fieldBean = getBean(fieldType);
//将实例对象注入到该字段中
field.set(instance, fieldBean);
}
//完成属性注入后,从半成品缓存中移除,加入到成品缓存中
earlySingletonObjects.remove(className);
singletonObjects.put(className, instance);
return instance;
}
}
public static void main(String[] args) {
new Thread(() -> {
try {
A a1 = getBean(A.class);
System.out.println(“t1.a:” + a1.hashCode());
System.out.println(“t1.b:” + a1.getB().hashCode());
} catch (IllegalAccessException | InstantiationException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
A a1 = getBean(A.class);
System.out.println(“t2.a:” + a1.hashCode());
System.out.println(“t2.b:” + a1.getB().hashCode());
} catch (IllegalAccessException | InstantiationException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
B b = getBean(B.class);
System.out.println(“t3.b:” + b.hashCode());
System.out.println(“t3.a:” + b.getA().hashCode());
} catch (IllegalAccessException | InstantiationException e) {
e.printStackTrace();
}
}).start();
}
输出结果:

多次实验,从输出结果说明:在多线程的场景下,使用两级缓存能够有效避免出现空指针的问题,在一定程度上也能比整个方法加锁的效率更高。

五、什么样的循环依赖都能解决吗?
================
从第二节可以看出,多例模式下就不可以解决循环依赖。
我们在以上小节中写的代码,是默认全部使用反射set注入的。
而对于单例模式,在经过对依赖项自然排序后,构造器注入是不可以优先于任何一个set注入的。

第一种场景:b依赖a,需要使用构造器注入a;a依赖b,需要使用set注入b
经过Spring对Bean的自然排序后,会先去创建a,再去创建b。
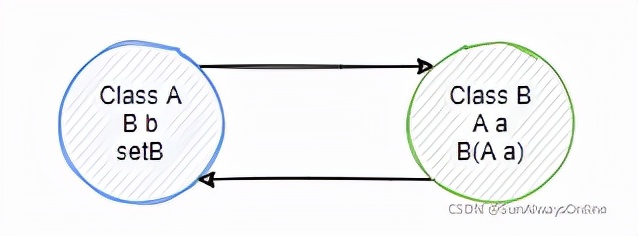
这种场景,是可以解决循环依赖的。在实例化B时,已经存在半成品a。
结论:最后再使用构造器注入时,可以解决循环依赖。
第二种场景:a依赖b,需要使用构造器注入b;b依赖a,需要使用set注入a
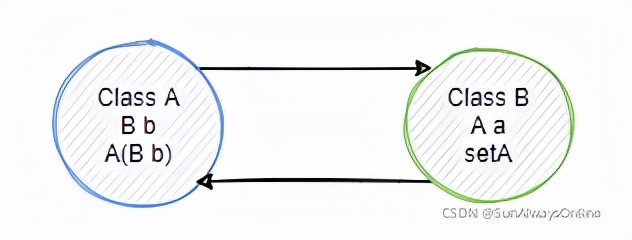
这种场景,在实例化a时,就需要调用构造方法,因此去实例b,而b在缓存中找不到a,造成注入失败。
结论:一开始就使用构造器注入,则不能解决循环依赖。
那么都使用构造器注入时,那肯定也不能解决循环依赖的。
因此,Spring解决循环依赖有两个小前提:
-
循环依赖中的Bean都是单例
-
在经过自然排序后,构造器注入不能优先于循环依赖中的任何一个set注入
六、Spring中解决循环依赖的原理
==================
在Spring中,我们使用getBean方法从容器获取一个Bean,那么就从getBean方法入手
AbstractApplicationContext类中的getBean
public Object getBean(String name) throws BeansException {
assertBeanFactoryActive();
return getBeanFactory().getBean(name);
}
接着进入AbstractBeanFactory类中的getBean
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
再进入到doGetBean方法中,该方法比较长,截取其中比较核心的点来说
先说getSingleton方法
//从缓存中获取指定的bean
Object sharedInstance = getSingleton(beanName);
进入到
DefaultSingletonBeanRegistry的getSingleton方法中
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//先从一级缓存中查找
Object singletonObject = this.singletonObjects.get(beanName);
//如果一级缓存中没有,且当前bean正处于创建的过程中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存中查找
singletonObject = this.earlySingletonObjects.get(beanName);
//如果二级缓存中也没有,且允许暴露早期引用时
if (singletonObject == null && allowEarlyReference) {
//从三级缓存中查找到bean的工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//调用getObject方法生成bean
singletonObject = singletonFactory.getObject();
//放入到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
看到这里,似乎和之前我们写的代码很像啊。
Spring在解决循环依赖时,其实也用到了缓存,缓存声明及定义如下:
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
singletonObjects,一级缓存,存放的是最终的成品,即完成实例化(仅调用构造方法)、属性注入、初始化后的bean
earlySingletonObjects,二级缓存,存放的是半成品,或叫早期曝光对象,即只完成实例化,未完成属性注入及初始化的bean
singletonFactories,三级缓存,存放的是能获取到半成品的工厂
前几节我们自己解决了循环依赖,一级缓存的存在是为了在单线程的情况下解决循环依赖,而二级缓存的存在是为了兼容多线程,提升获取bean的效率。那三级缓存存在的意义又是什么呢?

解决循环依赖,其中的一个核心前提是bean必须是单例的,因此我们接着看doGetBean方法中第二处核心的代码,即处理单例bean的代码
/处理单例bean
if (mbd.isSingleton()) {
//sharedInstance就是从缓存中获取的bean,一般来说,这里是null的
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
其中getSingleton方法中的第二个参数是一个函数式接口类型的ObjectFactory,因此这里可以直接使用lambda表达式来传入一个默认的实现,即createBean方法。
进入到getSingleton(beanName,objectFactory)方法中,精简后的代码如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
//如果不在缓存中,就会利用getObject方法去创建
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//标志当前bean正在创建中,如果被多次创建,这里也会抛出异常
beforeSingletonCreation(beanName);
boolean newSingleton = false;
//执行getObject,即执行外部传入的createBean方法
singletonObject = singletonFactory.getObject();
newSingleton = true;
//省略异常处理,出现异常时,newSingleton=false
//取消bean正在创建的标志
afterSingletonCreation(beanName);
if (newSingleton) {
//管理缓存,移除三级缓存与二级缓存,加入到一级缓存中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
当走到getObject方法时,就会进入到
AbstractAutowireCapableBeanFactorycreateBean方法中核心的方法是这一句话
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
接着进入到同类中的doCreateBean方法中,精简之后的代码:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 实例化bean
BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
//加入到三级缓存中,getEarlyBeanReference会返回单例工厂
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
//属性注入
populateBean(beanName, mbd, instanceWrapper);
//初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
if (earlySingletonExposure) {
//从二级缓存中查找
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
//返回二级缓存中的bean,这里就有可能是代理后的对象
exposedObject = earlySingletonReference;
}
}
return exposedObject;
}
看看getEarlyBeanReference到底返回了什么样的一个单例工厂(但其实说是工厂,不如说是获取早期曝光对象的一个逻辑)
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
//从容器中寻找实现InstantiationAwareBeanPostProcessor接口的后置处理器
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//遍历找到的所有符合要求的后置处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
//如果后置处理器实现了SmartInstantiationAwareBeanPostProcessor接口
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
在getEarlyBeanReference方法中,最终会返回一个经过AOP拦截后生成的代理对象。
如果当前没有任何实现
InstantiationAwareBeanPostProcessor接口的后置处理器,即当前bean没有被任何AOP拦截后,那直接返回传进来的bean。
到这里,源码已经分析得差不多了。以A与B的循环依赖,画一下整个过程
以A没被代理为例:

A被代理为例:
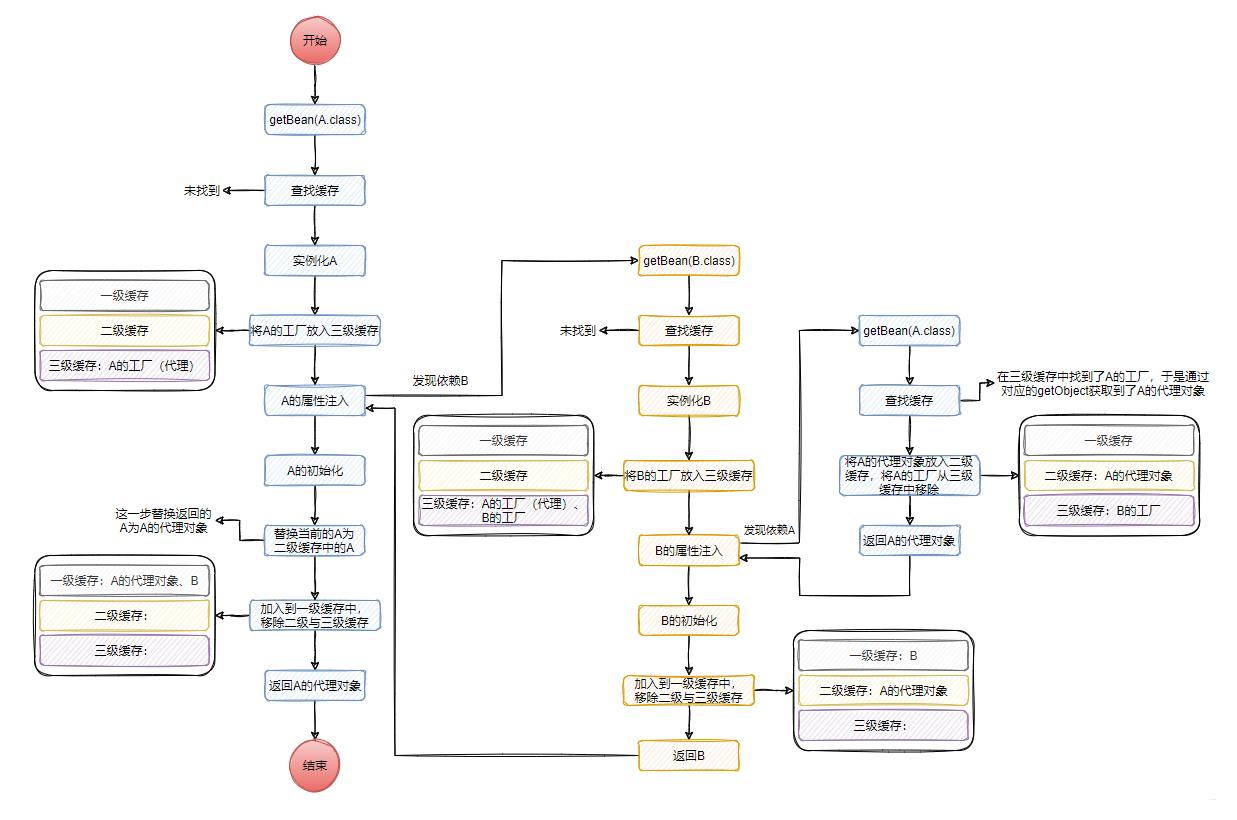
从上面的分析可以看出,解决循环依赖的本质是借助于缓存。
多例下的循环依赖,每次注入的都是一个新的对象,完全用不到缓存,所以无法解决多例下的循环依赖。
在经过自然排序后,如果一开始就是构造器注入,也无法利用到缓存。set注入之所以能利用到缓存,是因为能够将实例化与属性赋值分离,给缓存利用留下余地。
对三级缓存的理解
========
在单线程的情况,也就是getBean仅支持串行操作的话,那么一级缓存其实已经够用了。
二级缓存将半成品与成品对象分离,使得多线程的情况下,不会拿到不完整的对象实例。而且支持多线程同时查询缓存,在一定程度上提升了性能。
三级缓存存放的是单例对象工厂,准确的说,是函数式接口实现,是生成对象的一段逻辑。如果该对象被代理,则工厂的getObject返回代理之后的对象,否则返回原对象。
这里可能有人有疑问,为什么需要三级缓存呢?在实例化阶段之后,直接将原对象或代理对象放入二级缓存不也行吗?
理论是可以的。
一般来说,在Bean的生命周期中,创建代理是在初始化完成后再做的。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构

- 第二个就是数据库的高频知识点与性能优化

- 第三个则是并发编程(72个知识点学习)

- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料

还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!
系化!**
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构
[外链图片转存中…(img-WUPR7DAU-1712443010885)]
- 第二个就是数据库的高频知识点与性能优化
[外链图片转存中…(img-AG6Qujnv-1712443010885)]
- 第三个则是并发编程(72个知识点学习)
[外链图片转存中…(img-3m7Z0NNG-1712443010885)]
- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料
[外链图片转存中…(img-nAuNO4eE-1712443010886)]
还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门即可获取!















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









