






RDD2022(文献[1])数据集包含了六个国家的道路缺陷数据,分别是中国、日本、捷克、挪威、美国、印度,如图1所示。

图1 提供数据的国家列表
数据集下载地址:地址,如图2所示。
图2 RDD2022下载地址
该数据集总共包含了47420张图片以及每张图片对应的xml标签,为研究团队进行目标分类、目标检测、语义分割等工作提供了方便。
由于计算资源有限,同时中国部分包含了4878张图片足够支持本课题进行目标检测方向的深入研究,因此本文选择中国的数据支撑验证实验。
中国数据分为两部分:China_M和China_D。China_M由摩托车上装置智能手机拍摄得到,China_D中的图片由无人机搭载摄像头拍摄得到。每部分又分为训练图片、测试图片、训练标签,具体描述如图3所示。


图3 China_M和China_D具体描述
数据集中有五种标签,分别是D00(纵向裂缝)、D10(横向裂缝)、D20(网状裂缝)、D40(坑洞)、Repair(修复)。标签及示例图片如图4所示。(来自文献[2],该文献用的是China_D数据集)。

图4 标签及示例图片
在China_M和China_D中每种标签对应的样本数量如图5所示。
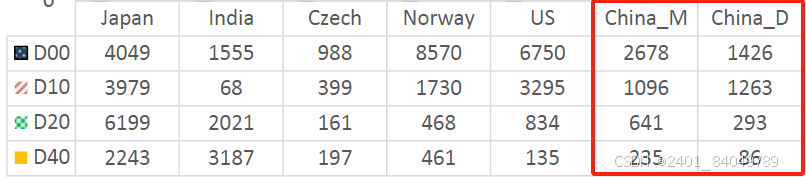
图5 样本数量
统计如下:D00合计4104个;D10合计2359个。D20合计934个。D40合计321个。该图没有统计Repair类型,通过代码统计Repair合计1046个,如表1所示。
| 类型 | 合计 |
| D00 | 4104 |
| D10 | 2359 |
| D20 | 934 |
| D40 | 321 |
| Repair | 1046 |
表1 样本统计
数据集中有五张背景图片(没有进行标注),分别是China_Drone_000170、China_Drone_000218、
China_Drone_000256、China_Drone_001134、China_Drone_001391(这五张看起来也是有缺陷的,不知道是漏了,还是说当背景?有知道的朋友可以在评论区说明,感谢)
(2025-5-21 答辩通过,准备毕业了。祝还在读研的同学学业顺利,天天开心。)
参考文献:
[1] Arya, D., Maeda, H., Ghosh, S. K., Toshniwal, D., & Sekimoto, Y. (2022, January 1). RDD2022: A multi-national image dataset for automatic Road Damage Detection [Online post]. arXiv.Org. https://doi.org/10.48550/arxiv.2209.08538
[2] 张艳君, 沈平, 郭安辉, & 高博. (2023). 融合 CBAM-YOLOv7 模型的路面缺陷智能检测方法研究. 重庆理工大学学报(自然科学), 38(05), 321.

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









