







Spark MLlib 特征工程(上)
前面我们一起构建了一个简单的线性回归模型,来预测美国爱荷华州的房价。从模型效果来看,模型的预测能力非常差。不过,事出有因,一方面线性回归的拟合能力有限,再者,我们使用的特征也是少的可怜。
要想提升模型效果,具体到我们“房价预测”的案例里就是把房价预测得更准,我们需要从特征和模型两个方面着手,逐步对模型进行优化。
在机器学习领域,有一条尽人皆知的“潜规则”:Garbage in,garbage out。它的意思是说,当我们喂给模型的数据是“垃圾”的时候,模型“吐出”的预测结果也是“垃圾”。垃圾是一句玩笑话,实际上,它指的是不完善的特征工程。
特征工程不完善的成因有很多,比如数据质量参差不齐、特征字段区分度不高,还有特征选择不到位、不合理,等等,我们必须要牢记一点:特征工程制约着模型效果,它决定了模型效果的上限,也就是“天花板”。而模型调优,仅仅是在不停地逼近这个“天花板”而已。因此,提升模型效果的第一步,就是要做好特征工程。
打开Spark MLlib 特征工程页面,你会发现这里罗列着数不清的特征处理函数,让人眼花缭乱。作为初学者,看到这么长的列表,更是会感到无所适从。

结合过往的应用经验,我会从特征工程的视角出发,把它们进行归类。
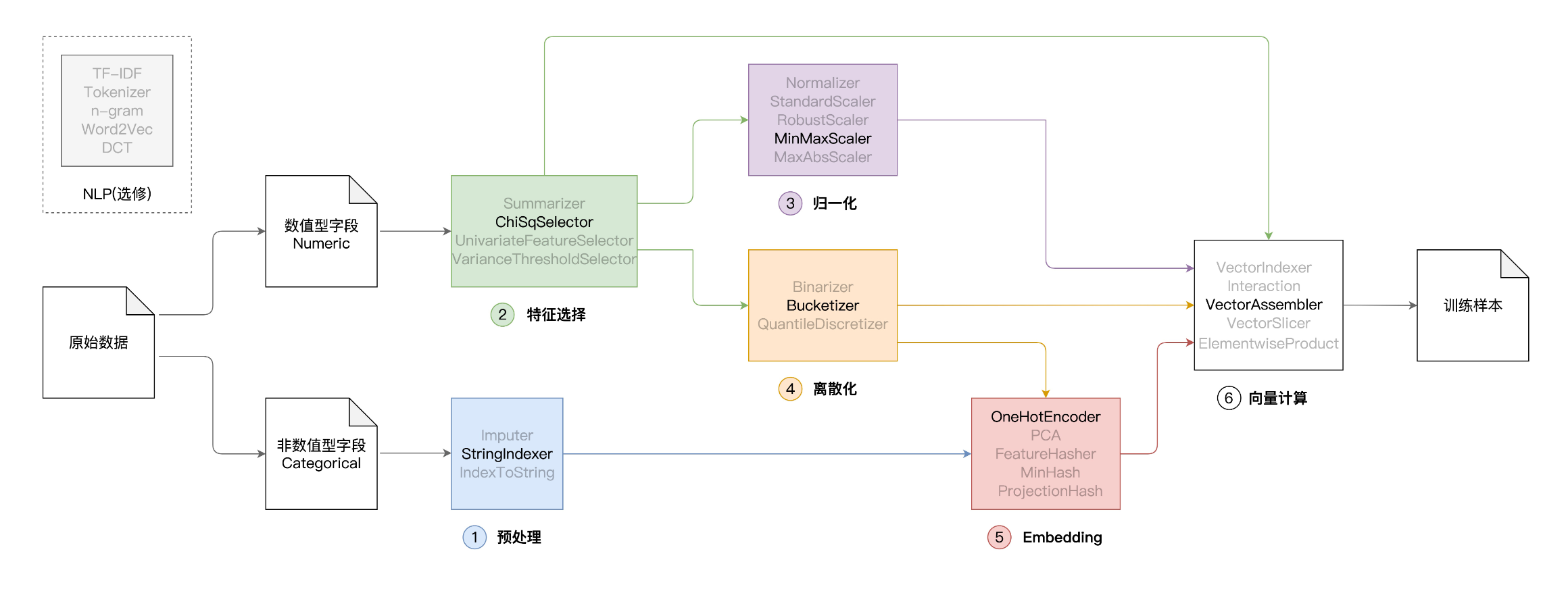
如图所示,从原始数据生成可用于模型训练的训练样本,这个过程又叫“特征工程”,我们有很长的路要走。通常来说,对于原始数据中的字段,我们会把它们分为数值型(Numeric)和非数值型(Categorical)。之所以要这样区分,原因在于字段类型不同,处理方法也不同。
在上图中,从左到右,Spark MLlib 特征处理函数可以被分为如下几类,依次是:
- 预处理
- 特征选择
- 归一化
- 离散化
- Embedding
- 向量计算
除此之外,Spark MLlib 还提供了一些用于自然语言处理(NLP,Natural Language Processing)的初级函数,如图中左上角的虚线框所示。
特征工程
在上一讲,我们的模型只用到了 4 个特征,分别是"LotArea",“GrLivArea”,“TotalBsmtSF"和"GarageArea”。选定这 4 个特征去建模,意味着我们做了一个很强的先验假设:房屋价格仅与这 4 个房屋属性有关。显然,这样的假设并不合理。作为消费者,在决定要不要买房的时候,绝不会仅仅参考这 4 个房屋属性。
爱荷华州房价数据提供了多达 79 个房屋属性,其中一部分是数值型字段,如记录各种尺寸、面积、大小、数量的房屋属性,另一部分是非数值型字段,比如房屋类型、街道类型、建筑日期、地基类型,等等。
显然,房价是由这 79 个属性当中的多个属性共同决定的。机器学习的任务,就是先找出这些“决定性”因素(房屋属性),然后再用一个权重向量(模型参数)来量化不同因素对于房价的影响。
预处理 Encoding:StringIndexer
由于绝大多数模型(包括线性回归模型)都不能直接“消费”非数值型数据,因此,咱们的第一步,就是把房屋属性中的非数值字段,转换为数值字段。在特征工程中,对于这类基础的数据转换操作,我们统一把它称为预处理。
其实在机器学习的文章中我们有介绍过,可以使用One Hot Encoding 或者 Label Encoding
我们可以利用 Spark MLlib 提供的 StringIndexer 完成预处理。顾名思义,StringIndexer 的作用是,以数据列为单位,把字段中的字符串转换为数值索引。例如,使用 StringIndexer,我们可以把“车库类型”属性 GarageType 中的字符串转换为数字,如下图所
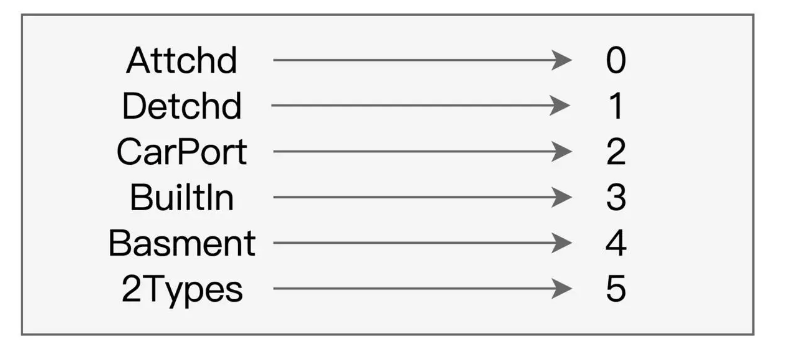
StringIndexer 的用法比较简单,可以分为三个步骤:
- 第一步,实例化 StringIndexer 对象;
- 第二步,通过 setInputCol 和 setOutputCol 来指定输入列和输出列;
- 第三步,调用 fit 和 transform 函数,完成数据转换。
接下来,我们就结合上一讲的“房价预测”项目,使用 StringIndexer 对所有的非数值字段进行转换,从而演示并学习它的用法。首先,我们读取房屋源数据并创建 DataFrame。
import org.apache.spark.sql.DataFrame
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val filePath: String = s"${rootPath}/train.csv"
val sourceDataDF: DataFrame = spark.read.format("csv").option("header", true).load(filePath)

然后,我们挑选出所有的非数值字段,并使用 StringIndexer 对其进行转换。
// 导入StringIndexer
import org.apache.spark.ml.feature.StringIndexer
// 所有非数值型字段,也即StringIndexer所需的“输入列” 这里有52列
val categoricalFields: Array[String] = Array("MSSubClass", "MSZoning", "Street", "Alley", "LotShape", "LandContour", "Utilities", "LotConfig", "LandSlope", "Neighborhood", "Condition1" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









