







Spark MLlib Pipeline
前面我们一起学习了如何在 Spark MLlib 框架下做特征工程与模型训练。不论是特征工程,还是模型训练,针对同一个机器学习问题,我们往往需要尝试不同的特征处理方法或是模型算法。结合之前的大量实例,细心的你想必早已发现,针对同一问题,不同的算法选型在开发的过程中,存在着大量的重复性代码。
以 GBDT 和随机森林为例,它们处理数据的过程是相似的,原始数据都是经过 StringIndexer、VectorAssembler 和 VectorIndexer 这三个环节转化为训练样本,只不过 GBDT 最后用 GBTRegressor 来做回归,而随机森林用 RandomForestClassifier 来做分类。
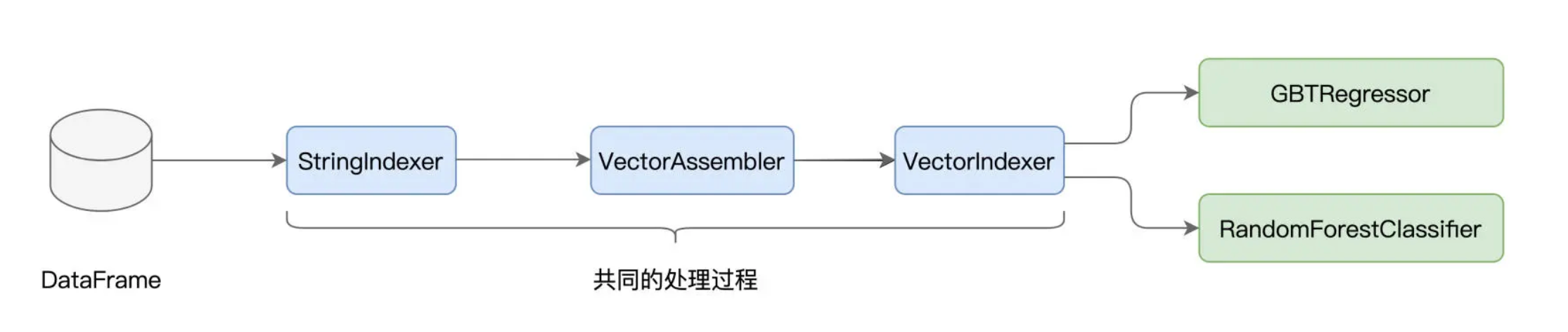
不仅如此,在之前验证模型效果的时候我们也没有闭环,仅仅检查了训练集上的拟合效果,并没有在测试集上进行推理并验证。如果我们尝试去加载新的测试数据集,那么所有的特征处理过程,都需要在测试集上重演一遍。无疑,这同样会引入大量冗余的重复代码。
那么,有没有什么办法,能够避免上述的重复开发,让 Spark MLlib 框架下的机器学习开发更加高效呢?答案是肯定的,今天这一讲,我们就来说说 Spark MLlib Pipeline,看看它如何帮助开发者大幅提升机器学习应用的开发效率。
什么是MLlib Pipeline
简单地说,Pipeline 是一套基于 DataFrame 的高阶开发 API,它让开发者以一种高效的方式,来打造端到端的机器学习流水线。这么说可能比较抽象,我们不妨先来看看,Pipeline 都有哪些核心组件,它们又提供了哪些功能。
Pipeline 的核心组件有两类,一类是 Transformer,我们不妨把它称作“转换器”,另一类是 Estimator,我把它叫作“模型生成器”。我们之前接触的各类特征处理函数,实际上都属于转换器,比如 StringIndexer、MinMaxScaler、Bucketizer、VectorAssembler,等等。而前面 3 讲提到的模型算法,全部都是 Estimator。

Transformer
我们先来说说 Transformer,数据转换器。在形式上,Transformer 的输入是 DataFrame,输出也是 DataFrame。结合特定的数据处理逻辑,Transformer 基于原有的 DataFrame 数据列,去创建新的数据列,而新的数据列中,往往包含着不同形式的特征。
以 StringIndexer 为例,它的转换逻辑很简单,就是把字符串转换为数值。在创建 StringIndexer 实例的时候,我们需要使用 setInputCol(s) 和 setOutputCol(s) 方法,来指定原始数据列和期待输出的数据列,而输出数据列中的内容就是我们需要的特征,如下图所示。
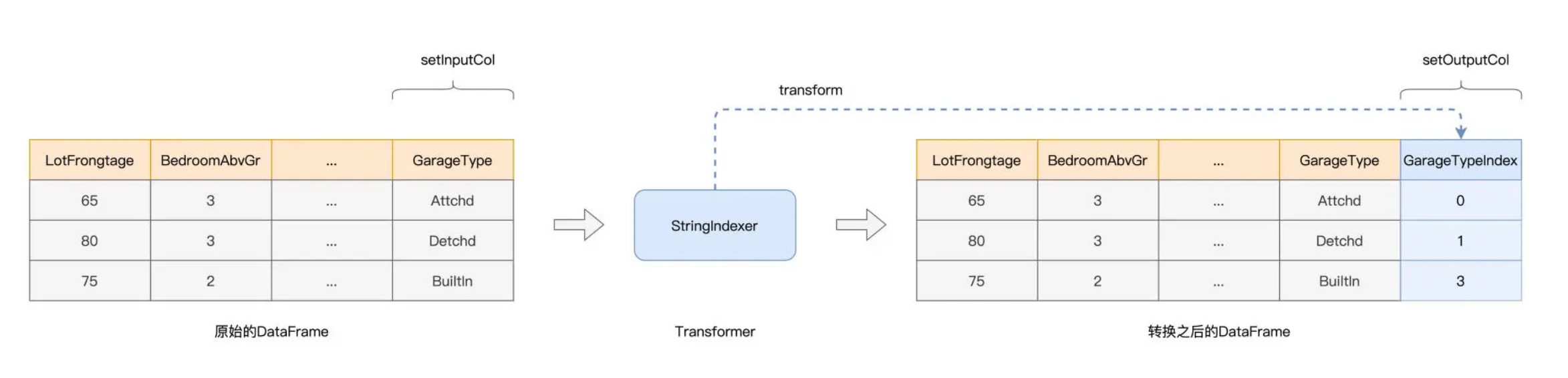
结合图示可以看到,Transformer 消费原有 DataFrame 的数据列,然后把生成的数据列再追加到该 DataFrame,就会生成新的 DataFrame。换句话说,Transformer 并不是“就地”(Inline)修改原有的 DataFrame,而是基于它去创建新的 DataFrame。
实际上,每个 Transformer 都实现了 setInputCol(s) 和 setOutputCol(s) 这两个(接口)方法。除此之外,Transformer 还提供了 transform 接口,用于封装具体的转换逻辑。正是基于这些核心接口,Pipeline 才能把各式各样的 Transformer 拼接在一起,打造出了特征工程流水线。
一般来说,在一个机器学习应用中,我们往往需要多个 Transformer 来对数据做各式各样的转换,才能生成所需的训练样本。在逻辑上,多个基于同一份原始数据生成的、不同“版本”数据的 DataFrame,它们会同时存在于系统中。
不过,受益于 Spark 的惰性求值(Lazy Evaluation)设计,应用在运行时并不会出现多份冗余数据重复占用内存的情况。
不过,为了开发上的遍历,我们还是会使用 var 而不是用 val 来命名原始的 DataFrame。原因很简单,如果用 val 的话,我们需要反复使用新的变量名,来命名新生成的 DataFrame。
Estimator
接下来,我们来说说 Estimator。相比 Transformer,Estimator 要简单得多,它实际上就是各类模型算法,如 GBDT、随机森林、线性回归,等等。Estimator 的核心接口,只有一个,那就是 fit,中文可以翻译成“拟合”。
Estimator 的作用,就是定义模型算法,然后通过拟合 DataFrame 所囊括的训练样本,来生产模型(Models)。这也是为什么我把 Estimator 称作是“模型生成器”。
不过,有意思的是,虽然模型算法是 Estimator,但是 Estimator 生产的模型,却是不折不扣的 Transformer。
要搞清楚为什么模型是 Transformer,我们得先弄明白模型到底是什么。所谓机器学习模型,它本质上就是一个参数(Parameter
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









