







写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。


上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
List:是存储单列数据的集合,存储有顺序,允许重复。继承Collection接口。
Set: 是存储单列数据的集合。继承Collection接口。不允许重复。
Map:存储键和值这样的双列数据的集合,存储数据无顺序,键(key)不能重复,值(value)。可以重复。
🍷hashCode与equals的区别与联系?
一、equals方法的作用
1、默认情况(没有覆盖equals方法)下equals方法都是调用Object类的equals方法,而Object的equals方法主要用于判断对象的内存地址引用是不是同一个地址(是不是同一个对象)。
2 、要是类中覆盖了equals方法,那么就要根据具体的代码来确定equals方法的作用了,覆盖后一般都是通过对象的内容是否相等来判断对象是否相等。
二、Hashcode()方法:
1、我们并没有覆盖equals方法只覆盖了hashCode方法,两个对象虽然hashCode一样,但在将stu1和stu2放入set集合时由于equals方法比较的两个对象是false,所以就没有在比较两个对象的hashcode值。
2、覆盖一下equals方法和hashCode方法,stu1和stu2通过equals方法比较相等,而且返回的hashCode值一样,所以放入set集合中时只放入了一个对象。
3、我们让两个对象equals方法比较相等,但hashCode值不相等试试,虽然stu1和stu2通过equals方法比较相等,但两个对象的hashcode的值并不相等,所以在将stu1和stu2放入set集合中时认为是两个不同的对象。
总结:
1、equals方法用于比较对象的内容是否相等(覆盖以后)
2、hashcode方法只有在集合中用到
3、当覆盖了equals方法时,比较对象是否相等将通过覆盖后的equals方法进行比较(判断对象的内容是否相等)。
4、将对象放入到集合中时,首先判断要放入对象的hashcode值与集合中的任意一个元素的hashcode值是否相等,如果不相等直接将该对象放入集合中。如果hashcode值相等,然后再通过equals方法判断要放入对象与集合中的任意一个对象是否相等,如果equals判断不相等,直接将该元素放入到集合中,否则不放入。
🧉模式
1、单例模式
分类:懒汉式、饿汉式
1、构造方法私有化
2、在本类中创建本类对象
3、保证对象的唯一性final
4、给外界提供得到对象的方法 static
5、在多线程中,饿汉式安全,懒汉式不安全
2、简单工厂模式
批量创建对象
1 创建工厂类 : 创建对象的方法
2 果汁类 是所有种类果汁的父类
3 在工厂类的方法中返回果汁类
4 根据测试类中传递的字符串判断到底返回哪种果汁
5 测试类通过工厂类返回果汁对象
3、建造者模式
内部类使用场景
目的:静态内部类创建外部类对象
1、 创建外部类,在其中创建一个静态内部类
2、静态内部类中写属性,构造方法和set get方法
3、静态内部类中写一个方法,必须返回外部类对象
4、 给外部类创建对象,传递参数。
4、装饰者模式
1、在处理流中使用
2、子类重写父类的方法,提高父类方法的功能及效率
3、为了尽可能减少重复代码,在重写的方法中用父类的对象调用父类原来的方法
4、得到父类对象可以通过将父类对象作为子类属性,通过子类构造方法传递父类对象
🥯Java常用类
1.装箱拆箱
1、装箱:把基本数据类型转成包装类类型
2、拆箱:把包装类类型转成基本数据类型
3、为什么要包装类
八种基本数据类型不满足面向对象的思想,不包括属性和方法。如果给基本数据类型添加功能,只能创建其包装类,将方法和属性封装进去(jdk5.0以后出现了自动拆箱,装箱)
4、Integer支持字符串,但字符串必须是数字。Integer integer3=new Integer("2");
compareTo(); 比较大小,大返回整数,小于返回负数,相等返回0
toBinaryString(); 将十进制数转成二进制,返回String字符串的表现形式
toHexString(); 将十进制转成十六进制
toOctalString(); 将十进制转成八进制
toString(); 将int类型数据转成String字符串
Integer.valueOf(); 将int转成integer类型对象
new Integer(); 将int转成integer类型对象
parseInt(); 将Integer转成int
2.String字符串
== 比较地址
.equals() 比较内容
.equalsIgnoreCase() 忽略大小写比较是否相同
.charAt(); 字符串截取出指定的下标开始
.compareTo() 比较大小
.compareToIgnore() 忽略大小比较
.concat() 将参数字符串连接到指定字符串后面
.contains() 是否包含参数字符串
.startsWith() 以指定前缀开头
.endsWith() 以指定后缀结尾
.indexOf("/") 第一次出现
.indexOf("/", 3) 指定位置开始索引
.lastIndexOf("/") 最后一次出现
.substring(string11.lastIndexOf("/")+1);截取指定位置
.substring(string11.lastIndexOf("/")+1, string11.lastIndexOf("."));//截取字符串,指定开始位置和结束位置
.replace('a', 'b') 替换指定字符串,替换所有的
.toUpperCase() 全部转为大写
.toLowerCase() 全部转成小写
.trim() 去掉字符串前后的空格,中间的去不掉
3.Boolean
Boolean boolean=new Boolean("false");
System.out.println(boolean);
4.正则表达式
字符类
[abc] a、b、c其中任意一个
[^abc] 除了a、b、c中的任意一个
[a-zA-Z] a-z或A-Z范围中的任意一个
[a-zA-Z0-9] a-z A-Z 0-9 其中任意一个
[……] 可以自己定义范围
预定字符类
\d 数字0-9
\D 非数字0-9
\s 空白字符:[ \t\n\x0B\f\r]
\S 非空白字符:\s
\w 单词字符:[a-zA-Z_0-9]
\W 非单词字符\w
数量词
? 一次或者一次也没有
\* 0次到多次
+ 一次或者多次
{n} 恰好n次
{n,} 至少n次
{n,m} 至少n次但不超过m次
.matches(); 匹配是否适合
.spil(); 拆分
5.时间相关类
1、Date类
.getTime();计算毫秒
2、SimpleDateFormat类 格式化时间
.format();返回的是String字符串
3、Calendar接口 日历字段之间的转换提供了一些方法
.get(Calendar.YEAR);
.get(Calendar.MONTH);// 默认是当前月份减一 从0开始的
.get(Calendar.DAY_OF_MONTH);
.get(Calendar.DAY_OF_WEEK);
Calendar calendar = Calendar.getInstance();
Date date = calendar.getTime();
4、Runtime运行时时间
.freeMemory(); 当前的系统剩余空间
5、System.exit(0);退出程序,参数是0 是正常退出
System.gc();调用垃圾回收器 ,不一定能够起来 ,只是起到一个促进的作用
🎄Java集合框架
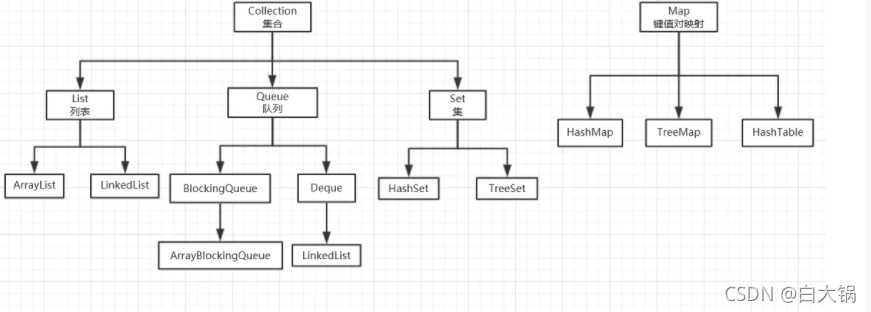
🚀常用的三种集合接口:
1.List:继承自Collection。可以存在相同的对象,有序的。具体实现类有ArrayList,LinkedList,Vector等(已经被抛弃,很少使用)
2.Set:继承自Collection。不能存在相同的对象,无序的,就是数学意义上的集合。具体实现类有HashSet,LinkedHashSet,TreeSet等。
3.Map:以键值对的形式存放对象。key-value。一般是key为String类型,value为Object的类型。具体实现类有HashMap,LinkedHashMap,TreeMap等。
🎉List(有序,可以重复的集合)
public interface List<E> extends Collection<E> {}
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
代码示例:
//产生一个 List 集合,典型实现为 ArrayList
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
//System.out.println(obj);
}
//在指定地方添加元素
list.add(2, 0);
//在指定地方替换元素
list.set(2, 1);
//获得指定对象的索引
int i=list.indexOf(1);
System.out.println("索引为:"+i);
//遍历:普通for循环
for(int j=0;j<list.size();j++){
System.out.println(list.get(j));
}
🎋Set(典型实现 HashSet()是一个无序,不可重复的集合)
HashSet 基于 HashMap 实现,使用了 HashMap 的 K 作为元素存储,V 为 new Object() ,在 add() 方法中如果两个元素的 Hash 值相同,则通过 equals 方法比较是否相等。
LinkedHashSet LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。
TreeSet 红黑树实现有序唯一。
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
③、对于 HashSet: 如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
1、当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
1.1、如果 hashCode 值不同,直接把该元素存储到hashCode()指定的位置
1.2、如果 hashCode 值相同,那么会继续判断该元素和集合对象的 equals() 作比较
1.2.1、hashCode相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
1.2.2、hashCode相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该约束这种情况,即保证:如果两个对象通过equals()方法返回 true,这两个对象的 hashCode 值也应该相同。
注意:每一个存储到 哈希 表中的对象,都得提供hashCode()和equals()方法的实现,用来判断是否是同一个对象
对于HashSet集合,我们要保证如果两个对象通过equals()方法返回 true,这两个对象的 hashCode 值也应该相同。
常见的 hashCode()算法:

2、Set linkedHashSet = new LinkedHashSet();
不可以重复,有序,因为底层采用 链表 和 哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性
3、Set treeSet = new TreeSet();
TreeSet:有序;不可重复,底层使用 红黑树算法,擅长于范围查询。
如果使用TreeSet()无参数的构造器创建一个TreeSet对象, 则要求放入其中的元素的类必须实现Comparable接口所以, 在其中不能放入null元素
必须放入同样类的对象(默认会进行排序) 否则可能会发生类型转换异常.我们可以使用泛型来进行限制
🎡Map(key-value 的键值对,key 不允许重复,value可以)
1、严格来说
Map并不是一个集合,而是两个集合之间 的映射关系。
2、这两个集合没每一条数据通过映射关系,我们可以看成是一条数据。即Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3、因为 Map 集合即没有实现于Collection接口,也没有实现Iterable接口,所以不能对Map集合进行for-each遍历。
代码示例:
Map<String,Object> hashMap = new HashMap<>();
//添加元素到 Map 中
hashMap.put("key1", "value1");
hashMap.put("key2", "value2");
hashMap.put("key3", "value3");
hashMap.put("key4", "value4");
hashMap.put("key5", "value5");
//删除 Map 中的元素,通过 key 的值
hashMap.remove("key1");
//通过 get(key) 得到 Map 中的value
Object str1 = hashMap.get("key1");
//可以通过 添加 方法来修改 Map 中的元素
hashMap.put("key2", "修改 key2 的 Value");
//通过 map.values() 方法得到 Map 中的 value 集合
Collection<Object> value = hashMap.values();
for(Object obj : value){
//System.out.println(obj);
}
//通过 map.keySet() 得到 Map 的key 的集合,然后 通过 get(key) 得到 Value
Set<String> set = hashMap.keySet();
for(String str : set){
Object obj = hashMap.get(str);
//System.out.println(str+"="+obj);
}
//通过 Map.entrySet() 得到 Map 的 Entry集合,然后遍历
Set<Map.Entry<String, Object>> entrys = hashMap.entrySet();
for(Map.Entry<String, Object> entry: entrys){
String key = entry.getKey();
Object value2 = entry.getValue();
System.out.println(key+"="+value2);
}
System.out.println(hashMap);
🎄Map常用方法及实现类
1.添加:
map.put(key,value) //在key位置上存储value值,key存在则覆盖原有值;
map.putAll(Map m);//将Map集合m放在map中
2.删除:
map.clear(); //清空map中的数据
map.remvoe(key); //删除key及其位置上的元素,返回其值。
3.判断:
map.containsValue(value); //判断集合是否包含value值
map.containsKey(key); //判断集合是否包含key键
4.获取:
map.get(key); //获取key键上的value值
map.size(); //获取map集合的大小
Collection c = map.values();
// 返回map集合中的value值 的Collection集合;
Set< K > set = keySet(); //取出key的所有值的Set集合
Set< Map.Entry< K , V > >set =entrySet();
实现类:
1.
Hashtable: 底层用哈希表实现,不允许存在null键和值,集合线程安全(线程同步) jdk1.0以前常用
2.HashMap: 底层用哈希表实现,运行存在null的键和值,集合线程不同步,用法与Hastable相同
3.TreeMap: 底层用二叉树实现,用于需要排序的Map集合中
4.Properties:继承Hastbale,主要用于流中文件固化
5.ConcurrentHashMap:线程安全的 HashMap。
1.7 采用分段锁的形式加锁;1.8 使用 Synchronized 和 CAS 实现同步,若数组的 Node 为空,则通过 CAS 的方式设置值,不为空则加在链表的第一个节点。获取第一个元素是否为空使用 Unsafe 类提供的 getObjectVolatile 保证可见性。
对于读操作,数组由 volatile 修饰,同时数组的元素为 Node,Node 的 K 使用 final 修饰,V 使用 volatile 修饰,下一个节点也用 volatile 修饰,保证多线程的可见性。
6.LinkedHashMap:继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。
🧨Map与Set关系
1、都有几个类型的集合。HashMap 和 HashSet ,都采 哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
2、分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成
🎄Java多线程
🎗创建线程和启动
(1)继承
Thread类创建线程类
通过继承Thread类创建线程类的具体步骤和具体代码如下:
• 定义一个继承Thread类的子类,并重写该类的run()方法;
• 创建Thread子类的实例,即创建了线程对象;
• 调用该线程对象的start()方法启动线程。
class SomeThead extends Thraad {
public void run() {
//do something here
}
}
public static void main(String[] args){
SomeThread oneThread = new SomeThread();
步骤3:启动线程:
oneThread.start();
}
(2)实现
Runnable接口创建线程类
通过实现Runnable接口创建线程类的具体步骤和具体代码如下:
• 定义Runnable接口的实现类,并重写该接口的run()方法;
• 创建Runnable实现类的实例,并以此实例作为Thread的target对象,即该Thread对象才是真正的线程对象。
class SomeRunnable implements Runnable { `在这里插入代码片`
public void run() {
//do something here
}
}
Runnable oneRunnable = new SomeRunnable();
Thread oneThread = new Thread(oneRunnable);
oneThread.start();
(3)通过
Callable和Future创建线程
通过Callable和Future创建线程的具体步骤和具体代码如下:
• 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
• 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
• 使用FutureTask对象作为Thread对象的target创建并启动新线程。
• 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值其中,Callable接口(也只有一个方法)定义如下:
public interface Callable {
V call() throws Exception;
}
步骤1:创建实现Callable接口的类SomeCallable(略);
步骤2:创建一个类对象:
Callable oneCallable = new SomeCallable();
步骤3:由Callable创建一个FutureTask对象:
FutureTask oneTask = new FutureTask(oneCallable);
注释: FutureTask是一个包装器,它通过接受Callable来创建,它同时实现了 Future和Runnable接口。
步骤4:由FutureTask创建一个Thread对象:
Thread oneThread = new Thread(oneTask);
步骤5:启动线程:
oneThread.start();
🎀线程生命周期

1、新建状态
用new关键字和Thread类或其子类建立一个线程对象后,该线程对象就处于新生状态。处于新生状态的线程有自己的内存空间,通过调用start方法进入就绪状态(runnable)。
注意:不能对已经启动的线程再次调用start()方法,否则会出现Java.lang.IllegalThreadStateException异常。
2、就绪状态
处于就绪状态的线程已经具备了运行条件,但还没有分配到CPU,处于线程就绪队列(尽管是采用队列形式,事实上,把它称为可运行池而不是可运行队列。因为cpu的调度不一定是按照先进先出的顺序来调度的),等待系统为其分配CPU。等待状态并不是执行状态,当系统选定一个等待执行的Thread对象后,它就会从等待执行状态进入执行状态,系统挑选的动作称之为“cpu调度”。一旦获得CPU,线程就进入运行状态并自动调用自己的run方法。
提示:如果希望子线程调用start()方法后立即执行,可以使用Thread.sleep()方式使主线程睡眠一伙儿,转去执行子线程。
3、运行状态
处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
处于就绪状态的线程,如果获得了cpu的调度,就会从就绪状态变为运行状态,执行run()方法中的任务。如果该线程失去了cpu资源,就会又从运行状态变为就绪状态。重新等待系统分配资源。也可以对在运行状态的线程调用yield()方法,它就会让出cpu资源,再次变为就绪状态。
注: 当发生如下情况是,线程会从运行状态变为阻塞状态:
①、线程调用sleep方法主动放弃所占用的系统资源
②、线程调用一个阻塞式IO方法,在该方法返回之前,该线程被阻塞
③、线程试图获得一个同步监视器,但更改同步监视器正被其他线程所持有
④、线程在等待某个通知(notify)
⑤、程序调用了线程的suspend方法将线程挂起。不过该方法容易导致死锁,所以程序应该尽量避免使用该方法。
当线程的run()方法执行完,或者被强制性地终止,例如出现异常,或者调用了stop()、desyory()方法等等,就会从运行状态转变为死亡状态。
4、阻塞状态
处于运行状态的线程在某些情况下,如执行了sleep(睡眠)方法,或等待I/O设备等资源,将让出CPU并暂时停止自己的运行,进入阻塞状态。
在阻塞状态的线程不能进入就绪队列。只有当引起阻塞的原因消除时,如睡眠时间已到,或等待的I/O设备空闲下来,线程便转入就绪状态,重新到就绪队列中排队等待,被系统选中后从原来停止的位置开始继续运行。
5、死亡状态
当线程的run()方法执行完,或者被强制性地终止,就认为它死去。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。 如果在一个死去的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
🎭线程管理
🎗线程睡眠——sleep
Java提供了一些便捷的方法用于会线程状态的控制。具体如下:
1、线程睡眠——sleep
如果我们需要让当前正在执行的线程暂停一段时间,并进入阻塞状态,则可以通过调用Thread的sleep方法。
注:
(1)sleep是静态方法,最好不要用Thread的实例对象调用它,因为它睡眠的始终是当前正在运行的线程,而不是调用它的线程对象,它只对正在运行状态的线程对象有效。如下面的例子:
public class Test1 {
public static void main(String[] args) throws InterruptedException {
System.out.println(Thread.currentThread().getName());
MyThread myThread=new MyThread();
myThread.start();
myThread.sleep(1000);//这里sleep的就是main线程,而非myThread线程
Thread.sleep(10);
for(int i=0;i<100;i++){
System.out.println("main"+i);
}
}
}
(2)Java线程调度是Java多线程的核心,只有良好的调度,才能充分发挥系统的性能,提高程序的执行效率。但是不管程序员怎么编写调度,只能最大限度的影响线程执行的次序,而不能做到精准控制。因为使用sleep方法之后,线程是进入阻塞状态的,只有当睡眠的时间结束,才会重新进入到就绪状态,而就绪状态进入到运行状态,是由系统控制的,我们不可能精准的去干涉它,所以如果调用Thread.sleep(1000)使得线程睡眠1秒,可能结果会大于1秒。
🎗线程让步——yield
yield()方法和sleep()方法有点相似,它也是Thread类提供的一个静态的方法,它也可以让当前正在执行的线程暂停,让出cpu资源给其他的线程。但是和sleep()方法不同的是,它不会进入到阻塞状态,而是进入到就绪状态。yield()方法只是让当前线程暂停一下,重新进入就绪的线程池中,让系统的线程调度器重新调度器重新调度一次,完全可能出现这样的情况:当某个线程调用yield()方法之后,线程调度器又将其调度出来重新进入到运行状态执行。
实际上,当某个线程调用了yield()方法暂停之后,优先级与当前线程相同,或者优先级比当前线程更高的就绪状态的线程更有可能获得执行的机会,当然,只是有可能,因为我们不可能精确的干涉cpu调度线程。用法如下:
public class Test1 {
public static void main(String[] args) throws InterruptedException {
new MyThread("低级", 1).start();
new MyThread("中级", 5).start();
new MyThread("高级", 10).start();
}
}
class MyThread extends Thread {
public MyThread(String name, int pro) {
super(name);// 设置线程的名称
this.setPriority(pro);// 设置优先级
}
@Override
public void run() {
for (int i = 0; i < 30; i++) {
System.out.println(this.getName() + "线程第" + i + "次执行!");
if (i % 5 == 0)
Thread.yield();
}
}
}
注:关于sleep()方法和yield()方的区别如下:
①、sleep方法暂停当前线程后,会进入阻塞状态,只有当睡眠时间到了,才会转入就绪状态。而yield方法调用后 ,是直接进入就绪状态,所以有可能刚进入就绪状态,又被调度到运行状态。
②、sleep方法声明抛出了InterruptedException,所以调用sleep方法的时候要捕获该异常,或者显示声明抛出该异常。而yield方法则没有声明抛出任务异常。
③、sleep方法比yield方法有更好的可移植性,通常不要依靠yield方法来控制并发线程的执行。
🎗设置线程的优先级
每个线程执行时都有一个优先级的属性,优先级高的线程可以获得较多的执行机会,而优先级低的线程则获得较少的执行机会。与线程休眠类似,线程的优先级仍然无法保障线程的执行次序。只不过,优先级高的线程获取CPU资源的概率较大,优先级低的也并非没机会执行。
每个线程默认的优先级都与创建它的父线程具有相同的优先级,在默认情况下,main线程具有普通优先级。
注:Thread类提供了setPriority(int newPriority)和getPriority()方法来设置和返回一个指定线程的优先级,其中setPriority方法的参数是一个整数,范围是1~·0之间,也可以使用Thread类提供的三个静态常量:
MAX_PRIORITY =10
MIN_PRIORITY =1
NORM_PRIORITY =5
public class Test1 {
public static void main(String[] args) throws InterruptedException {
new MyThread("高级", 10).start();
new MyThread("低级", 1).start();
}
}
class MyThread extends Thread {
public MyThread(String name,int pro) {
super(name);//设置线程的名称
setPriority(pro);//设置线程的优先级
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(this.getName() + "线程第" + i + "次执行!");
}
}
}
注:虽然Java提供了10个优先级别,但这些优先级别需要操作系统的支持。不同的操作系统的优先级并不相同,而且也不能很好的和Java的10个优先级别对应。所以我们应该使用MAX_PRIORITY、MIN_PRIORITY和NORM_PRIORITY三个静态常量来设定优先级,这样才能保证程序最好的可移植性。
🎗后台(守护)线程
守护线程使用的情况较少,但并非无用,举例来说,JVM的垃圾回收、内存管理等线程都是守护线程。还有就是在做数据库应用时候,使用的数据库连接池,连接池本身也包含着很多后台线程,监控连接个数、超时时间、状态等等。调用线程对象的方法setDaemon(true),则可以将其设置为守护线程。守护线程的用途为:
• 守护线程通常用于执行一些后台作业,例如在你的应用程序运行时播放背景音乐,在文字编辑器里做自动语法检查、自动保存等功能。
• Java的垃圾回收也是一个守护线程。守护线的好处就是你不需要关心它的结束问题。例如你在你的应用程序运行的时候希望播放背景音乐,如果将这个播放背景音乐的线程设定为非守护线程,那么在用户请求退出的时候,不仅要退出主线程,还要通知播放背景音乐的线程退出;如果设定为守护线程则不需要了。
setDaemon方法的详细说明:
public final void setDaemon(boolean on) 将该线程标记为守护线程或用户线程。当正在运行的线程都是守护线程时,Java 虚拟机退出。
该方法必须在启动线程前调用。 该方法首先调用该线程的 checkAccess 方法,且不带任何参数。这可能抛出 SecurityException(在当前线程中)。
参数:
on - 如果为 true,则将该线程标记为守护线程。
抛出:
IllegalThreadStateException - 如果该线程处于活动状态。
SecurityException - 如果当前线程无法修改该线程。
注:JRE判断程序是否执行结束的标准是所有的前台执线程行完毕了,而不管后台线程的状态,因此,在使用后台县城时候一定要注意这个问题。
🎗正确结束线程
Thread.stop()、Thread.suspend、Thread.resume、Runtime.runFinalizersOnExit这些终止线程运行的方法已经被废弃了,使用它们是极端不安全的!想要安全有效的结束一个线程,可以使用下面的方法:
• 正常执行完run方法,然后结束掉;
• 控制循环条件和判断条件的标识符来结束掉线程。
class MyThread extends Thread {
int i=0;
boolean next=true;
@Override
public void run() {
while (next) {
if(i==10)
next=false;
i++;
System.out.println(i);
}
}
}
🎁线程同步
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
🎗同步方法
即有synchronized关键字修饰的方法。由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
public synchronized void save(){}
注:
synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
🎗同步代码块
即有
synchronized关键字修饰的语句块。被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
public class Bank {
private int count =0;//账户余额
//存钱
public void addMoney(int money){
synchronized (this) {
count +=money;
}
System.out.println(System.currentTimeMillis()+"存进:"+money);
}
//取钱
public void subMoney(int money){
synchronized (this) {
if(count-money < 0){
System.out.println("余额不足");
return;
}
count -=money;
}
System.out.println(+System.currentTimeMillis()+"取出:"+money);
}
//查询
public void lookMoney(){
System.out.println("账户余额:"+count);
}
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
🎗使用特殊域变量(volatile)实现线程同步
• volatile关键字为域变量的访问提供了一种免锁机制;
• 使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新;
• 因此每次使用该域就要重新计算,而不是使用寄存器中的值;
• volatile不会提供任何原子操作,它也不能用来修饰final类型的变量。
public class SynchronizedThread {
class Bank {
private volatile int account = 100;
public int getAccount() {
return account;
}
/\*\*
\* 用同步方法实现
\*
\* @param money
\*/
public synchronized void save(int money) {
account += money;
}
/\*\*
\* 用同步代码块实现
\*
\* @param money
\*/
public void save1(int money) {
synchronized (this) {
account += money;
}
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
// bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" +bank.getAccount());
}
}
}
/\*\*
\* 建立线程,调用内部类
\*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedThread st = new SynchronizedThread();
st.useThread();
}
注:多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。用final域,有锁保护的域和volatile域可以避免非同步的问题。
🎗使用重入锁(Lock)实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例
lock() : 获得锁
unlock() : 释放锁
注:
ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
//只给出要修改的代码,其余代码与上同
class Bank {
private int account = 100;
//需要声明这个锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
lock.lock();
try{
account += money;
}finally{
lock.unlock();
}
}
}
🧶线程通信
🎗借助于Object类的wait()、notify()和notifyAll()实现通信
线程执行wait()后,就放弃了运行资格,处于冻结状态;
线程运行时,内存中会建立一个线程池,冻结状态的线程都存在于线程池中,notify()执行时唤醒的也是线程池中的线程,线程池中有多个线程时唤醒第一个被冻结的线程。
notifyall(), 唤醒线程池中所有线程。
注:
(1)
wait(), notify(),notifyall()都用在同步里面,因为这3个函数是对持有锁的线程进行操作,而只有同步才有锁,所以要使用在同步中;
(2)wait(),notify(),notifyall(), 在使用时必须标识它们所操作的线程持有的锁,因为等待和唤醒必须是同一锁下的线程;而锁可以是任意对象,所以这3个方法都是Object类中的方法。
单个消费者生产者例子如下:
class Resource{ //生产者和消费者都要操作的资源
private String name;
private int count=1;
private boolean flag=false;
public synchronized void set(String name){
if(flag)
try{wait();}catch(Exception e){}
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
this.notify();
}
public synchronized void out(){
if(!flag)
try{wait();}catch(Exception e){}
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
this.notify();
}
}
class Producer implements Runnable{
private Resource res;
Producer(Resource res){
this.res=res;
}
public void run(){
while(true){
res.set("商品");
}
}
}
class Consumer implements Runnable{
private Resource res;
Consumer(Resource res){
this.res=res;
}
public void run(){
while(true){
res.out();
}
}
}
public class ProducerConsumerDemo{
public static void main(String[] args){
Resource r=new Resource();
Producer pro=new Producer(r);
Consumer con=new Consumer(r);
Thread t1=new Thread(pro);
Thread t2=new Thread(con);
t1.start();
t2.start();
}
}//运行结果正常,生产者生产一个商品,紧接着消费者消费一个商品。
多个消费者生产者例子如下:
class Resource{
private String name;
private int count=1;
private boolean flag=false;
public synchronized void set(String name){
while(flag) /\*原先是if,现在改成while,这样生产者线程从冻结状态醒来时,还会再判断flag.\*/
try{wait();}catch(Exception e){}
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
this.notifyAll();/\*原先是notity(), 现在改成notifyAll(),这样生产者线程生产完一个商品后可以将等待中的消费者线程唤醒,否则只将上面改成while后,可能出现所有生产者和消费者都在wait()的情况。\*/
}
public synchronized void out(){
while(!flag) /\*原先是if,现在改成while,这样消费者线程从冻结状态醒来时,还会再判断flag.\*/
try{wait();}catch(Exception e){}
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
this.notifyAll(); /\*原先是notity(), 现在改成notifyAll(),这样消费者线程消费完一个商品后可以将等待中的生产者线程唤醒,否则只将上面改成while后,可能出现所有生产者和消费者都在wait()的情况。\*/
}
}
public class ProducerConsumerDemo{
public static void main(String[] args){
Resource r=new Resource();
Producer pro=new Producer(r);
Consumer con=new Consumer(r);
Thread t1=new Thread(pro);
Thread t2=new Thread(con);
Thread t3=new Thread(pro);
Thread t4=new Thread(con);
t1.start();
t2.start();
t3.start();
t4.start();
}
}
🎗使用Condition控制线程通信
jdk1.5中,提供了多线程的升级解决方案为:
(1)将同步synchronized替换为显式的Lock操作;
(2)将Object类中的wait(), notify(),notifyAll()替换成了Condition对象,该对象可以通过Lock锁对象获取;
(3)一个Lock对象上可以绑定多个Condition对象,这样实现了本方线程只唤醒对方线程,而jdk1.5之前,一个同步只能有一个锁,不同的同步只能用锁来区分,且锁嵌套时容易死锁。
class Resource{
private String name;
private int count=1;
private boolean flag=false;
private Lock lock = new ReentrantLock();/\*Lock是一个接口,ReentrantLock是该接口的一个直接子类。\*/
private Condition condition_pro=lock.newCondition(); /\*创建代表生产者方面的Condition对象\*/
private Condition condition_con=lock.newCondition(); /\*使用同一个锁,创建代表消费者方面的Condition对象\*/
public void set(String name){
lock.lock();//锁住此语句与lock.unlock()之间的代码
try{
while(flag)
condition_pro.await(); //生产者线程在conndition\_pro对象上等待
this.name=name+"---"+count++;
System.out.println(Thread.currentThread().getName()+"...生产者..."+this.name);
flag=true;
condition_con.signalAll();
}
finally{
lock.unlock(); //unlock()要放在finally块中。
}
}
public void out(){
lock.lock(); //锁住此语句与lock.unlock()之间的代码
try{
while(!flag)
condition_con.await(); //消费者线程在conndition\_con对象上等待
System.out.println(Thread.currentThread().getName()+"...消费者..."+this.name);
flag=false;
condition_pro.signqlAll(); /\*唤醒所有在condition\_pro对象下等待的线程,也就是唤醒所有生产者线程\*/
}
finally{
lock.unlock();
}
}
}
👕线程池
优点:
(1). 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
(2). 提供响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
(3).提供线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是要做到合理地利用线程,必须对其原理了如指掌。
(4).防止服务器过载,形成内存溢出,或者CPU耗尽。
创建线程池常见的三种方法:
1、newSingleThreadExecutor:创建一个单线程的线程池。
2、newFixedThreadPool:创建固定大小的线程池。
3、newCachedThreadPool:创建一个可缓存的线程池。
🎗newSingleThreadExecutor()
创建一个单线程的线程池。这个线程只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常而结束,那么会有一个新的线程来代替它。此线程保证所有的任务的执行顺序按照任务的提交顺序执行。
public class SingleThreadExecutorDemo {
public static void main(String[] args) {
ExecutorService executorService=Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int no=i;
Runnable task=new Runnable() {
@Override
public void run() {
try{
System.out.println("into "+no);
Thread.sleep(1000L);
System.out.println("end "+no);
}catch(InterruptedException e){
e.printStackTrace();
}
}
};
//交由线程池处理任务
executorService.execute(task);
}
executorService.shutdown();
System.out.println("main thread have terminate");
}
}
🎗newCachedThreadPool的使用
创建一个缓冲池大小可根据需要伸缩的线程池,但是在以前构造的线程可用时将重用它们。对于执行很多短期异步任务而言,这些线程池通常可提供程序性能。调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有60s未被使用的线程。因此,长时间保持空闲的线程池不会使用任何资源。
public class CachedThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService=Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
final int no=i;
Runnable task=new Runnable() {
@Override
public void run() {
try{
System.out.println("into "+no);
Thread.sleep(10001L);
System.out.println("end "+no);
}catch(InterruptedException e){
e.printStackTrace();
}
}
};
executorService.execute(task);
}
System.out.println("main thread have terminate");
executorService.shutdown();
}
}
🎗newFixedThreadPool的使用
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大多数nThreads线程会处于处理任务的活动状态。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新的线程将代替它执行后续任务(如果需要)。在某个线程被显示关闭之前,池中的线程将一直存在。
public class newFixedThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService=Executors.newFixedThreadPool(5);
for (int i = 0; i < 20; i++) {
final int no=i;
Runnable task=new Runnable() {
@Override
public void run() {
try{
System.out.println("into "+no);
Thread.sleep(1000L);
System.out.println("end "+no);
}catch(InterruptedException e){
e.printStackTrace();
}
}
};
executorService.execute(task);
}
System.out.println("main thread have terminate");
executorService.shutdown();
}
}
🧵线程五种状态
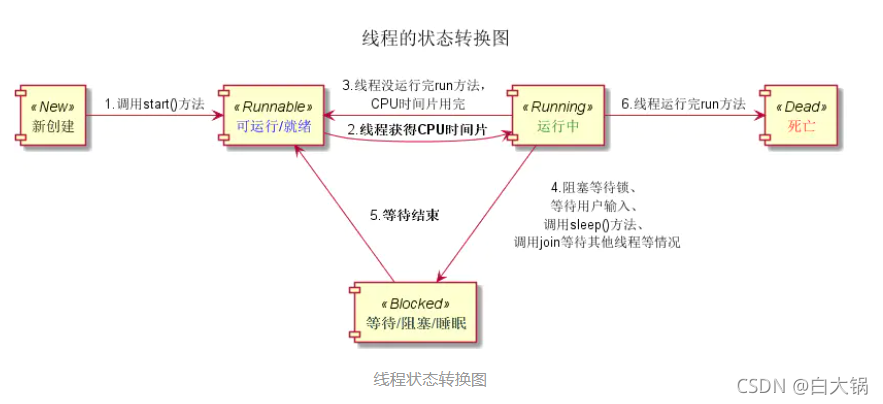
1.New (新创建)
当用new操作符创建一个线程时,如new Thread®,该线程还没有开始运行。这意外这它的状态是new。此时程序还没有开始运行线程中的代码,在线程运行之前还有一些基础工作要做。
2.Runnable (可运行/就绪)
一旦处于新状态的线程调用start方法(如图中的1所示),线程就处于Runnbale状态。
处于Runnable状态的线程还未运行run()方法的代码,只有在获得CPU时间片才开始运行。
3.Running (运行中)
当线程获得CPU时间片,线程就进入Running状态(如图中的2所示)。
处于Running状态的线程有可能在运行中CPU时间片用完,而run方法没运行完,线程就又进入Runnable状态。
通常情况下,运行中的线程一直处于Running与Runnable交替转换的过程中。
4.Blocked (等待/阻塞/睡眠)
当线程在Running状态中,遇到阻塞等待锁、等待用户输入、调用sleep()方法、调用join等待其他线程情况,会导致线程进入阻塞状态(Blocked)。
处于阻塞状态的线程,在阻塞等待结束之后,会进入Runnable状态,等等获得CPU时间片继续运行程序。
5.Dead (死亡)
当线程运行完run方法,直接进入死亡状态Dead 。
🎄Java虚拟机
Jvm相关资料:
链接:Jvm面试资料
提取码:u5i9
废话不说 直接看大佬操作:jvm
🎄MySQL
MySQL相关资料:
链接:MySQL
提取码:1jbm
详情见博主之前文章:MySQL入门到毕业
🎄Spring相关知识点
🎨Bean生命周期
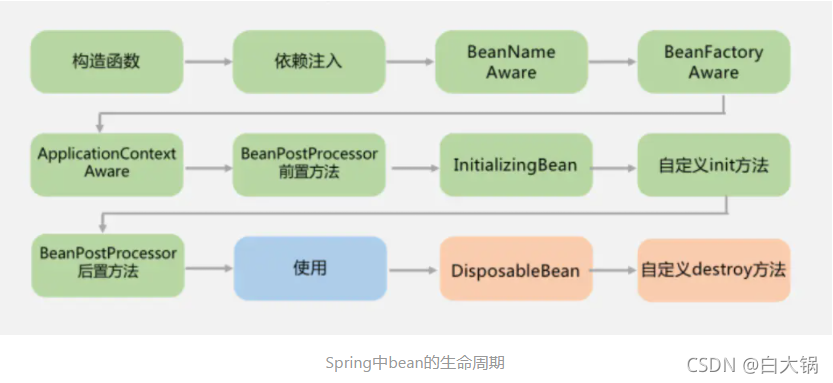
面试中经常问到的bean的生命周期,先看绿色的部分,bean的创建过程:
第1步:调用bean的构造方法创建bean;
第2步:通过反射调用setter方法进行属性的依赖注入;
第3步:如果实现BeanNameAware接口的话,会设置bean的name;
第4步:如果实现了BeanFactoryAware,会把bean factory设置给bean;
第5步:如果实现了ApplicationContextAware,会给bean设置ApplictionContext;
第6步:如果实现了BeanPostProcessor接口,则执行前置处理方法;
第7步:实现了InitializingBean接口的话,执行afterPropertiesSet方法;
第8步:执行自定义的init方法;
第9步:执行BeanPostProcessor接口的后置处理方法。
这时,就完成了bean的创建过程。
在使用完bean需要销毁时,会先执行DisposableBean接口的destroy方法,然后在执行自定义的destroy方法。
🎪Spring应用
🎗常用注解
a.类型类注释:
类型类注释包括
controller、service等,需要重点了解
其中component和bean注解的区别如下:
@Component注解在类上使用表明这个类是个组件类,需要Spring为这个类创建bean。
@Bean注解使用在方法上,告诉Spring这个方法将会返回一个Bean对象,需要把返回的对象注册到Spring的应用上下文中。
b.设置类注解
重点了解
@Autowire和@Qualifier以及bytype、byname等不同的自动装配机制。
c.web类注解
主要以了解为主,关注
@RequestMapping、@GetMapping、@PostMapping等路径匹配注解,以及@PathVariable、@RequestParam等参数获取注解。
d.功能类注解
包括
@ImportResource引用配置、@ComponentScan注解自动扫描、@Transactional事务注解等等,这里不一一介绍了。
🎠Spring优点
(1)spring属于低侵入式设计,代码的污染极低;
(2)spring的DI机制将对象之间的依赖关系交由框架处理,减低组件的耦合性;
(3)Spring提供了AOP技术,支持将一些通用任务,如安全、事务、日志、权限等进行集中式管理,从而提供更好的复用。
(4)spring对于主流的应用框架提供了集成支持。
🎀Spring中IOC理解
(1)IOC就是控制反转,指创建对象的控制权转移给Spring框架进行管理,并由Spring根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间松散耦合,也利于功能的复用。DI依赖注入,和控制反转是同一个概念的不同角度的描述,即 应用程序在运行时依赖IoC容器来动态注入对象需要的外部依赖。
(2)最直观的表达就是,以前创建对象的主动权和时机都是由自己把控的,IOC让对象的创建不用去new了,可以由spring自动生产,使用java的反射机制,根据配置文件在运行时动态的去创建对象以及管理对象,并调用对象的方法的。
(3)Spring的IOC有三种注入方式 :构造器注入、setter方法注入、根据注解注入。
🎇Spring中AOP理解
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,提高系统的可维护性。可用于权限认证、日志、事务处理。
AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理,也称为编译时增强,AOP框架会在编译阶段生成AOP代理类,并将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
① JDK动态代理只提供接口的代理,不支持类的代理,要求被代理类实现接口。JDK动态代理的核心是InvocationHandler接口和Proxy类,在获取代理对象时,使用Proxy类来动态创建目标类的代理类(即最终真正的代理类,这个类继承自Proxy并实现了我们定义的接口),当代理对象调用真实对象的方法时, InvocationHandler 通过
invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;
InvocationHandler 的 invoke(Object proxy,Method method,Object[] args):proxy是最终生成的代理对象; method 是被代理目标实例的某个具体方法; args 是被代理目标实例某个方法的具体入参, 在方法反射调用时使用。
② 如果被代理类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
(3)静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
🎭Spring配置方式
基于XML的配置:基于注解的配置: Spring在2.5版本以后开始支持用注解的方式来配置依赖注入。可以用注解的方式来替代XML方式的bean描述,可以将bean描述转移到组件类的内部,只需要在相关类上、方法上或者字段声明上使用注解即可。注解注入将会被容器在XML注入之前被处理,所以后者会覆盖掉前者对于同一个属性的处理结果
基于Java的配置: Spring对Java配置的支持是由
@Configuration注解和@Bean注解来实现的。由@Bean注解的方法将会实例化、配置和初始化一个新对象,这个对象将由Spring的IoC容器来管理。@Bean声明所起到的作用与元素类似。被@Configuration所注解的类则表示这个类的主要目的是作为bean定义的资源。被@Configuration声明的类可以通过在同一个类的内部调用@bean方法来设置嵌入bean的依赖关系。
🎢Spring中的设计模式
1.代理模式—在AOP和remoting中被用的比较多。
2.单例模式—在spring配置文件中定义的bean默认为单例模式。
模板方法—用来解决代码重复的问题 比如. RestTemplate, JmsTemplate, JpaTemplate。 前端控制器—Srping提供了DispatcherServlet来对请求进行分发。 视图帮助(View Helper )—Spring提供了一系列的JSP标签,高效宏来辅助将分散的代码整合在视图里。 依赖注入—贯穿于BeanFactory / ApplicationContext接口的核心理念。
3.工厂模式—BeanFactory用来创建对象的实例。
4.Builder模式- 自定义配置文件的解析bean是时采用builder模式,一步一步地构建一个beanDefinition
5.策略模式:Spring 中策略模式使用有多个地方,如 Bean 定义对象的创建以及代理对象的创建等。这里主要看一下代理对象创建的策略模式的实现。 前面已经了解 Spring 的代理方式有两个 Jdk 动态代理和 CGLIB 代理。这两个代理方式的使用正是使用了策略模式。
🧨SpringMVC执行流程
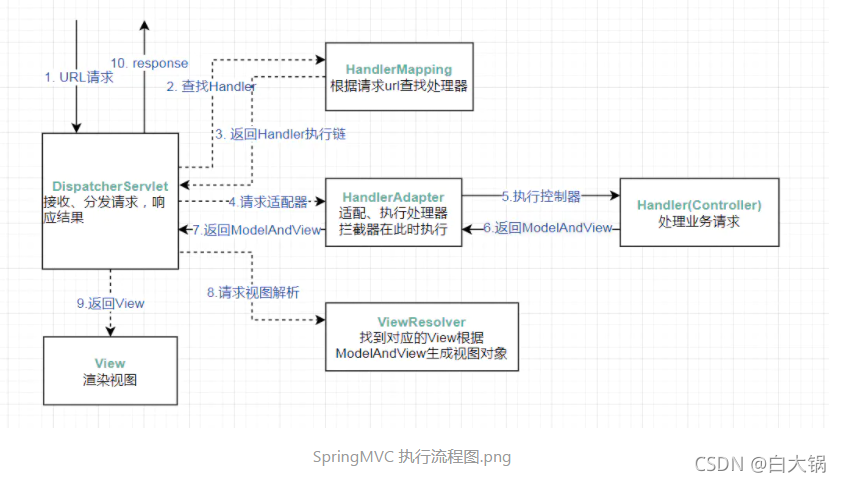
1.DispatcherServlet接收到一个URL请求
2.根据URL到HandlerMapping中查找处理器
3.返回给DispatcherServlet一个Handler执行链
4.DispatcherServlet请求HandlerAdapter适配器,找到对应的Handler
5.执行Handler即Controller的相关业务逻辑
6.Handler返回ModelAndView到HandlerAdapter
7.HandlerAdapter返回ModelAndView到DispatcherServlet
8.DispatcherServlet请求ViewRessolver视图解析器,找到对应的View根据ModelAndView生成视图对象
9.DispatcherServlet返回View
深入学习可查看此文:Spring常见面试题总结(超详细回答)
🎄计算机网络
计算机网络相关资料:
链接:计算机网络
提取码:1wq1
🎍OSI,TCP/IP,五层协议的体系结构,以及各层协议
OSI分层 (7层):物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、 网际层、运输层、 应用层。
五层协议 (5层):物理层、数据链路层、网络层、运输层、 应用层。
每一层的协议如下:
物理层:RJ45、CLOCK、IEEE802.3 (中继器,集线器,网关)
数据链路:PPP、FR、HDLC、VLAN、MAC (网桥,交换机)
网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP、 (路由器)
传输层:TCP、UDP、SPX
会话层:NFS、SQL、NETBIOS、RPC
表示层:JPEG、MPEG、ASII
应用层:FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS
每层作用:
物理层:通过媒介传输比特,确定机械及电气规范(比特Bit)
数据链路层:将比特组装成帧和点到点的传递(帧Frame)
网络层:负责数据包从源到宿的传递和网际互连(包PackeT)
传输层:提供端到端的可靠报文传递和错误恢复(段Segment)
会话层:建立、管理和终止会话(会话协议数据单元SPDU)
表示层:对数据进行翻译、加密和压缩(表示协议数据单元PPDU)
应用层:允许访问OSI环境的手段(应用协议数据单元APDU)
🥽IP地址的分类
A类地址:以0开头, 第一个字节范围:0~127(1.0.0.0 - 126.255.255.255);
B类地址:以10开头, 第一个字节范围:128~191(128.0.0.0 - 191.255.255.255);
C类地址:以110开头, 第一个字节范围:192~223(192.0.0.0 - 223.255.255.255);
10.0.0.0—10.255.255.255, 172.16.0.0—172.31.255.255, 192.168.0.0—192.168.255.255。(Internet上保留地址用于内部)
🥼各种协议
ICMP协议:因特网控制报文协议。它是TCP/IP协议族的一个子协议,用于在IP主机、路由器之间传递控制消息。
TFTP协议:是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。
HTTP协议:超文本传输协议,是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
DHCP协议:动态主机配置协议,是一种让系统得以连接到网络上,并获取所需要的配置参数手段。
NAT协议:网络地址转换属接入广域网(WAN)技术,是一种将私有(保留)地址转化为合法IP地址的转换技术,
DHCP协议:一个局域网的网络协议,使用UDP协议工作,用途:给内部网络或网络服务供应商自动分配IP地址,给用户或者内部网络管理员作为对所有计算机作中央管理的手段。
RARP协议 :RARP是逆地址解析协议,作用是完成硬件地址到IP地址的映射,主要用于无盘工作站,因为给无盘工作站配置的IP地址不能保存。工作流程:在网络中配置一台RARP服务器,里面保存着IP地址和MAC地址的映射关系,当无盘工作站启动后,就封装一个RARP数据包,里面有其MAC地址,然后广播到网络上去,当服务器收到请求包后,就查找对应的MAC地址的IP地址装入响应报文中发回给请求者。因为需要广播请求报文,因此RARP只能用于具有广播能力的网络。
👓TCP三次握手和四次挥手的全过程
三次握手:
第一次握手:客户端发送syn包(syn=x)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
四次挥手:
与建立连接的“三次握手”类似,断开一个TCP连接则需要“四次挥手”。
第一次挥手:主动关闭方发送一个FIN,用来关闭主动方到被动关闭方的数据传送,也就是主动关闭方告诉被动关闭方:我已经不 会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,主动关闭方依然会重发这些数据),但是,此时主动关闭方还可 以接受数据。
第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)。
第三次挥手:被动关闭方发送一个FIN,用来关闭被动关闭方到主动关闭方的数据传送,也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了。
第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,至此,完成四次挥手。
🎄MQ消息队列
博主用的较多的是RabbitMq 可见此文:消息队列—RabbitMQ深入研究(含Springboot+RabbitMQ整合)
🧵MQ应用(异步解耦削峰)
感受:
其实我投简历的时候,都不太敢投递阿里。因为在阿里一面前已经过了字节的三次面试,投阿里的简历一直没被捞,所以以为简历就挂了。
特别感谢一面的面试官捞了我,给了我机会,同时也认可我的努力和态度。对比我的面经和其他大佬的面经,自己真的是运气好。别人8成实力,我可能8成运气。所以对我而言,我要继续加倍努力,弥补自己技术上的不足,以及与科班大佬们基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档

的网络协议,使用UDP协议工作,用途:给内部网络或网络服务供应商自动分配IP地址,给用户或者内部网络管理员作为对所有计算机作中央管理的手段。
RARP协议 :RARP是逆地址解析协议,作用是完成硬件地址到IP地址的映射,主要用于无盘工作站,因为给无盘工作站配置的IP地址不能保存。工作流程:在网络中配置一台RARP服务器,里面保存着IP地址和MAC地址的映射关系,当无盘工作站启动后,就封装一个RARP数据包,里面有其MAC地址,然后广播到网络上去,当服务器收到请求包后,就查找对应的MAC地址的IP地址装入响应报文中发回给请求者。因为需要广播请求报文,因此RARP只能用于具有广播能力的网络。
👓TCP三次握手和四次挥手的全过程
三次握手:
第一次握手:客户端发送syn包(syn=x)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
四次挥手:
与建立连接的“三次握手”类似,断开一个TCP连接则需要“四次挥手”。
第一次挥手:主动关闭方发送一个FIN,用来关闭主动方到被动关闭方的数据传送,也就是主动关闭方告诉被动关闭方:我已经不 会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,主动关闭方依然会重发这些数据),但是,此时主动关闭方还可 以接受数据。
第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)。
第三次挥手:被动关闭方发送一个FIN,用来关闭被动关闭方到主动关闭方的数据传送,也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了。
第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,至此,完成四次挥手。
🎄MQ消息队列
博主用的较多的是RabbitMq 可见此文:消息队列—RabbitMQ深入研究(含Springboot+RabbitMQ整合)
🧵MQ应用(异步解耦削峰)
感受:
其实我投简历的时候,都不太敢投递阿里。因为在阿里一面前已经过了字节的三次面试,投阿里的简历一直没被捞,所以以为简历就挂了。
特别感谢一面的面试官捞了我,给了我机会,同时也认可我的努力和态度。对比我的面经和其他大佬的面经,自己真的是运气好。别人8成实力,我可能8成运气。所以对我而言,我要继续加倍努力,弥补自己技术上的不足,以及与科班大佬们基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档
[外链图片转存中…(img-M4CKxiS2-1715492217979)]















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









