







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
★
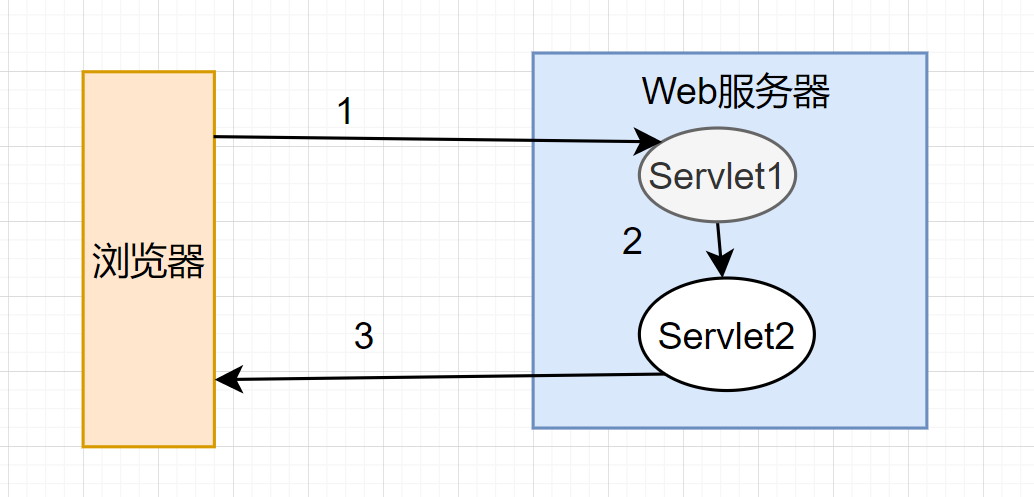
- 直接转发方式(Forward) ,客户端和浏览器只发出一次请求,Servlet、HTML、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于每个信息资源是共享的。
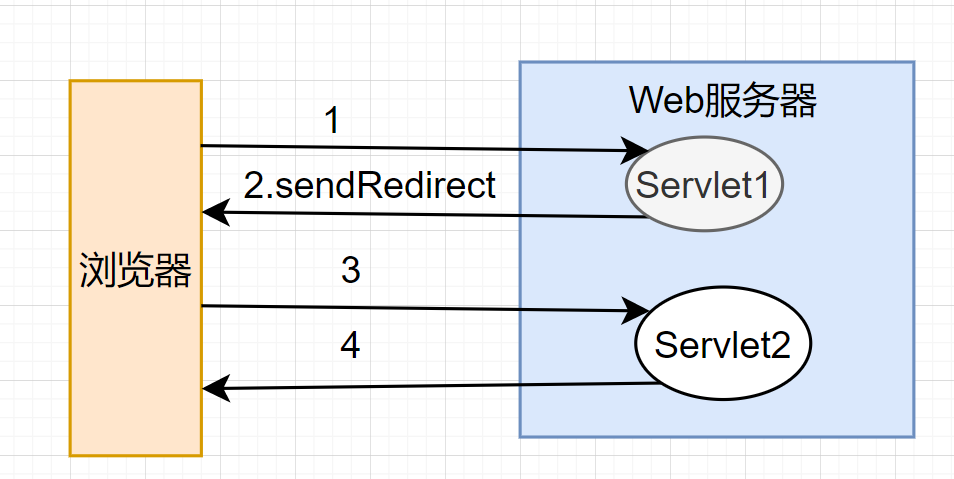
- 间接转发方式(Redirect) 实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
”
举个通俗的例子:
★
- 直接转发就相当于:“A找B借钱,B说没有,B去找C借,借到借不到都会把消息传递给A”;
- 间接转发就相当于:“A找B借钱,B说没有,让A去找C借”。**
”
看下这两个图,可以更容易理解一些:
- Redirect 的工作原理:
- forward 的工作原理
24. 聊聊SQL注入?
思路: SQL注入是最经典的安全问题。无论你是前端开发还是后端开发,都必须掌握的。
★
SQL注入是一种代码注入技术,一般被应用于攻击web应用程序。它通过在web应用接口传入一些特殊参数字符,来欺骗应用服务器,执行恶意的SQL命令,以达到非法获取系统信息的目的。它目前是黑客对数据库进行攻击的最常用手段之一。
”
24.1 SQL注入是如何攻击的?
举个常见的业务场景:在web表单搜索框输入员工名字,然后后台查询出对应名字的员工。
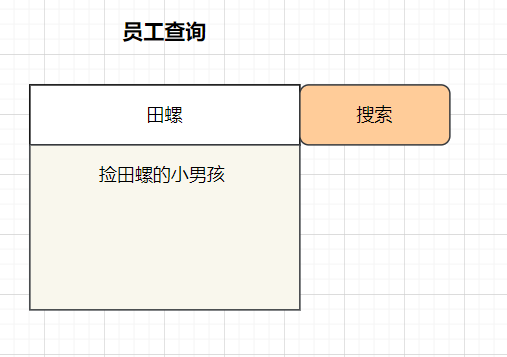
这种场景下,一般都是前端页面,把一个名字参数name传到后台,然后后台通过SQL把结果查询出来
name = “田螺”; //前端传过来的
SQL= “select * from staff where name=” + name; //根据前端传过来的name参数,查询数据库员工表staff
因为SQL是直接拼接的,如果我们完全信任前端传的参数的话。假如前端传这么一个参数时'' or '1'='1',SQL就变成酱紫的啦。
select * from staff where name=‘’ or ‘1’=‘1’;
这个SQL会把所有的员工信息全都查出来了,酱紫就请求用户已经越权啦。请求者可以获取所有员工的信息,信息已经暴露了啦。
24.2 如何预防SQL注入问题
1). 使用#{}而不是 ${}
在MyBatis中,使用#{}而不是${},可以很大程度防止sql注入。
-
因为
#{}是一个参数占位符,对于字符串类型,会自动加上"",其他类型不加。由于Mybatis采用预编译,其后的参数不会再进行SQL编译,所以一定程度上防止SQL注入。 -
${}是一个简单的字符串替换,字符串是什么,就会解析成什么,存在SQL注入风险
2). 不要暴露一些不必要的日志或者安全信息,比如避免直接响应一些sql异常信息。
如果SQL发生异常了,不要把这些信息暴露响应给用户,可以自定义异常进行响应
3). 不相信任何外部输入参数,过滤参数中含有的一些数据库关键词关键词
可以加个参数校验过滤的方法,过滤union,or等数据库关键词
4). 适当的权限控制
在你查询信息时,先校验下当前用户是否有这个权限。比如说,实现代码的时候,可以让用户多传一个企业Id什么的,或者获取当前用户的session信息等,在查询前,先校验一下当前用户是否是这个企业下的等等,是的话才有这个查询员工的权限。
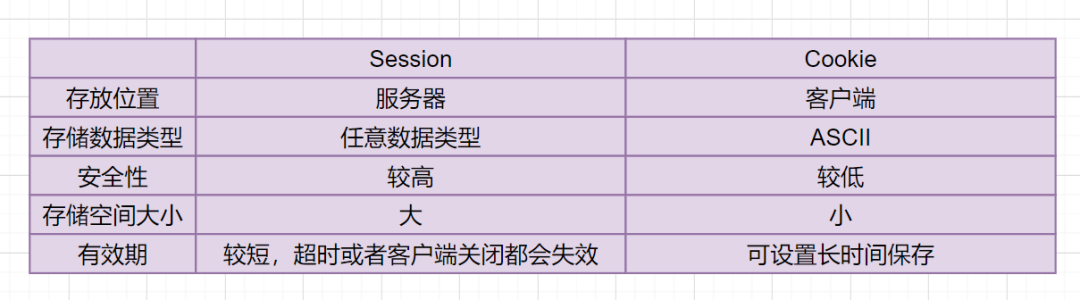
25. Session和Cookie的区别。
我们先来看Session和Cookie的概念吧:
-
Cookie是保存在客户端的一小块文本串的数据。客户端向服务器发起请求时,服务端会向客户端发送一个Cookie,客户端就把Cookie保存起来。在客户端下次向同一服务器再发起请求时,Cookie被携带发送到服务器。服务器就是根据这个Cookie来确认身份的。
-
session指的就是服务器和客户端一次会话的过程。Session利用Cookie进行信息处理的,当用户首先进行了请求后,服务端就在用户浏览器上创建了一个Cookie,当这个Session结束时,其实就是意味着这个Cookie就过期了。Session对象存储着特定用户会话所需的属性及配置信息。
Session 和Cookie的区别主要有这些:
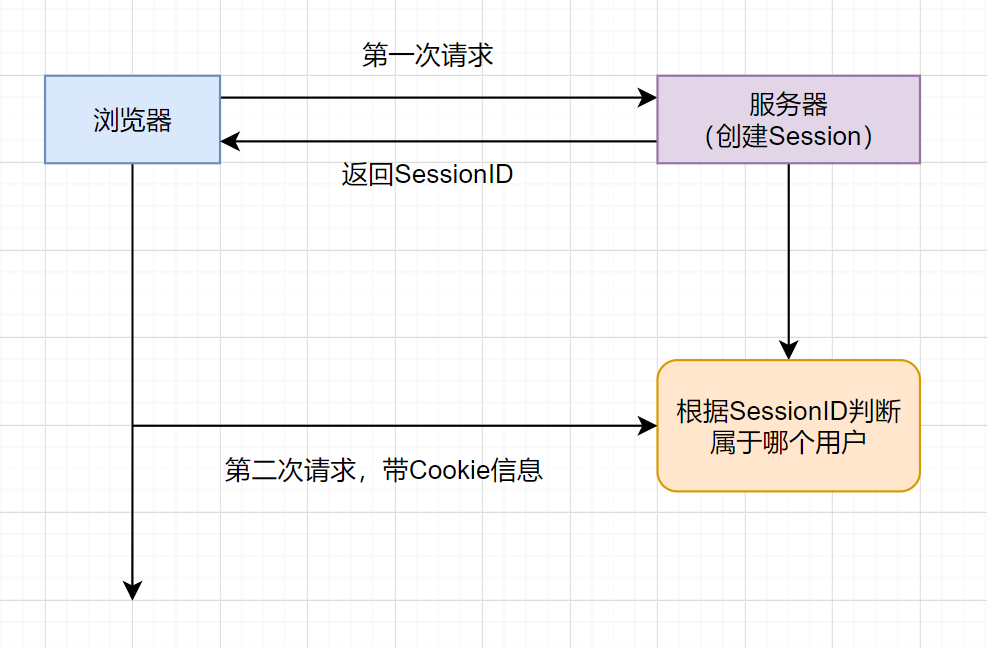
来看个图吧:
★
- 用户第一次请求服务器时,服务器根据用户提交的信息,创建对应的Session,请求返回时将此Session的唯一标识信息SessionID返回给浏览器,浏览器接收到服务器返回的SessionID信息后,会将此信息存入Cookie中,同时Cookie记录此SessionID是属于哪个域名。
- 当用户第二次访问服务器时,请求会自动判断此域名下是否存在Cookie信息,如果存在,则自动将Cookie信息也发送给服务端,服务端会从Cookie中获取SessionID,再根据 SessionID查找对应的 Session信息,如果没有找到,说明用户没有登录或者登录失效,如果找到Session证明用户已经登录可执行后面操作。
”
26. IP地址有哪些分类?
一般可以这么认为,IP地址=网络号+主机号。
-
网络号:它标志主机所连接的网络地址表示属于互联网的哪一个网络。
-
主机号:它标志主机地址表示其属于该网络中的哪一台主机。
IP地址分为A,B,C,D,E五大类:
-
A类地址(1~126):以0开头,网络号占前8位,主机号占后面24位。
-
B类地址(128~191):以10开头,网络号占前16位,主机号占后面16位。
-
C类地址(192~223):以110开头,网络号占前24位,主机号占后面8位。
-
D类地址(224~239):以1110开头,保留位多播地址。
-
E类地址(240~255):以11110开头,保留位为将来使用

IP地址分类
27. 说下ARP 协议的工作过程?
ARP 协议协议,Address Resolution Protocol,地址解析协议,它是用于实现IP地址到MAC地址的映射。
★
- 首先,每台主机都会在自己的ARP缓冲区中建立一个ARP列表,以表示IP地址和MAC地址的对应关系。
- 当源主机需要将一个数据包要发送到目的主机时,会首先检查自己的ARP列表,是否存在该IP地址对应的MAC地址;如果有﹐就直接将数据包发送到这个MAC地址;如果没有,就向本地网段发起一个ARP请求的广播包,查询此目的主机对应的MAC地址。此ARP请求的数据包里,包括源主机的IP地址、硬件地址、以及目的主机的IP地址。
- 网络中所有的主机收到这个ARP请求后,会检查数据包中的目的IP是否和自己的IP地址一致。如果不相同,就会忽略此数据包;如果相同,该主机首先将发送端的MAC地址和IP地址添加到自己的ARP列表中,如果ARP表中已经存在该IP的信息,则将其覆盖,然后给源主机发送一个 ARP响应数据包,告诉对方自己是它需要查找的MAC地址。
- 源主机收到这个ARP响应数据包后,将得到的目的主机的IP地址和MAC地址添加到自己的ARP列表中,并利用此信息开始数据的传输。如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3649
3649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









