







总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
1. 线程池设计和制作
============
第一步:定义一个王者线程池:TheKingThreadPool,它是这次手工制作中名副其实的主角儿。在这个线程池中,包含了任务队列管理、工作线程管理,并提供了可以指定队列类型的构造参数,以及任务提交入口和线程池关闭接口。你看,虽然它看起来似乎很迷你,但是线程池的核心组件都已经具备了,甚至在它的基础上,你完全可以把它扩展成更为成熟的线程池。
/**
- 王者线程池
*/
public class TheKingThreadPool {
private final BlockingQueue taskQueue;
private final List workers = new ArrayList<>();
private ThreadPoolStatus status;
/**
-
初始化构建线程池
-
@param worksNumber 线程池中的工作线程数量
-
@param taskQueue 任务队列
*/
public TheKingThreadPool(int worksNumber, BlockingQueue taskQueue) {
this.taskQueue = taskQueue;
status = ThreadPoolStatus.RUNNING;
for (int i = 0; i < worksNumber; i++) {
workers.add(new Worker(“Worker” + i, taskQueue));
}
for (Worker worker : workers) {
Thread workThread = new Thread(worker);
workThread.setName(worker.getName());
workThread.start();
}
}
/**
-
提交任务
-
@param task 待执行的任务
*/
public synchronized void execute(Task task) {
if (!this.status.isRunning()) {
throw new IllegalStateException(“线程池非运行状态,停止接单啦~”);
}
this.taskQueue.offer(task);
}
/**
- 等待所有任务执行结束
*/
public synchronized void waitUntilAllTasksFinished() {
while (this.taskQueue.size() > 0) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
- 关闭线程池
*/
public synchronized void shutdown() {
this.status = ThreadPoolStatus.SHUTDOWN;
}
/**
- 停止线程池
*/
public synchronized void stop() {
this.status = ThreadPoolStatus.SHUTDOWN;
for (Worker worker : workers) {
worker.doStop();
}
}
}
第二步:设计并制作工作线程。工作线程是干活的线程,将负责处理提交到线程池中的任务,我们把它叫做Worker。其实,这里的Worker的定义和Java线程池中的Worker已经很像了,它继承了Runnable接口并封装了Thread. 在构造Worker时,可以设定它的名字,并传入任务队列。当Worker启动后,它将会从任务队列中获取任务并执行。此外,它还提供了Stop方法,用以响应线程池的状态变化。
/**
- 线程池中用于执行任务的线程
*/
public class Worker implements Runnable {
private final String name;
private Thread thread = null;
private final BlockingQueue taskQueue;
private boolean isStopped = false;
private AtomicInteger counter = new AtomicInteger();
public Worker(String name, BlockingQueue queue) {
this.name = name;
taskQueue = queue;
}
public void run() {
this.thread = Thread.currentThread();
while (!isStopped()) {
try {
Task task = taskQueue.poll(5L, TimeUnit.SECONDS);
if (task != null) {
note(this.thread.getName(), “:获取到新的任务->”, task.getTaskDesc());
task.run();
counter.getAndIncrement();
}
} catch (Exception ignored) {
}
}
note(this.thread.getName(), “:已结束工作,执行任务数量:” + counter.get());
}
public synchronized void doStop() {
isStopped = true;
if (thread != null) {
this.thread.interrupt();
}
}
public synchronized boolean isStopped() {
return isStopped;
}
public String getName() {
return name;
}
}
第三步:设计并制作任务。任务是可以可执行的对象,因此我们直接继承Runnable接口就行。其实,直接使用Runnable接口也是可以的,只不过为了让示例更加清楚,我们给Task加了任务描述的方法。
/**
- 任务
*/
public interface Task extends Runnable {
String getTaskDesc();
}
第四步:设计线程池的状态。线程池作为一个运行框架,它必然会有一系列的状态,比如运行中、停止、关闭等。
public enum ThreadPoolStatus {
RUNNING(),
SHUTDOWN(),
STOP(),
TIDYING(),
TERMINATED();
ThreadPoolStatus() {
}
public boolean isRunning() {
return ThreadPoolStatus.RUNNING.equals(this);
}
}
以上四个步骤完成后,一个简易的线程池就已经制作完毕。你看,如果你从以上几点入手来理解线程池的源码的话,是不是要简单多了?Java中的线程池的核心组成也是如此,只不过在细节处理等方面更多全面且丰富。
2. 运行线程池
=========
现在,我们的王者线程池已经制作好。接下来,我们通过一个场景来运行它,看看它的效果如何。
试验场景:峡谷森林中,铠、兰陵王和典韦等负责打野,而安其拉、貂蝉和大乔等美女负责对狩猎到的野怪进行烧烤,一场欢快的峡谷烧烤节正在进行中。
在这个场景中,铠和兰陵王他们负责提交任务,而貂蝉和大乔她们则负责处理任务。
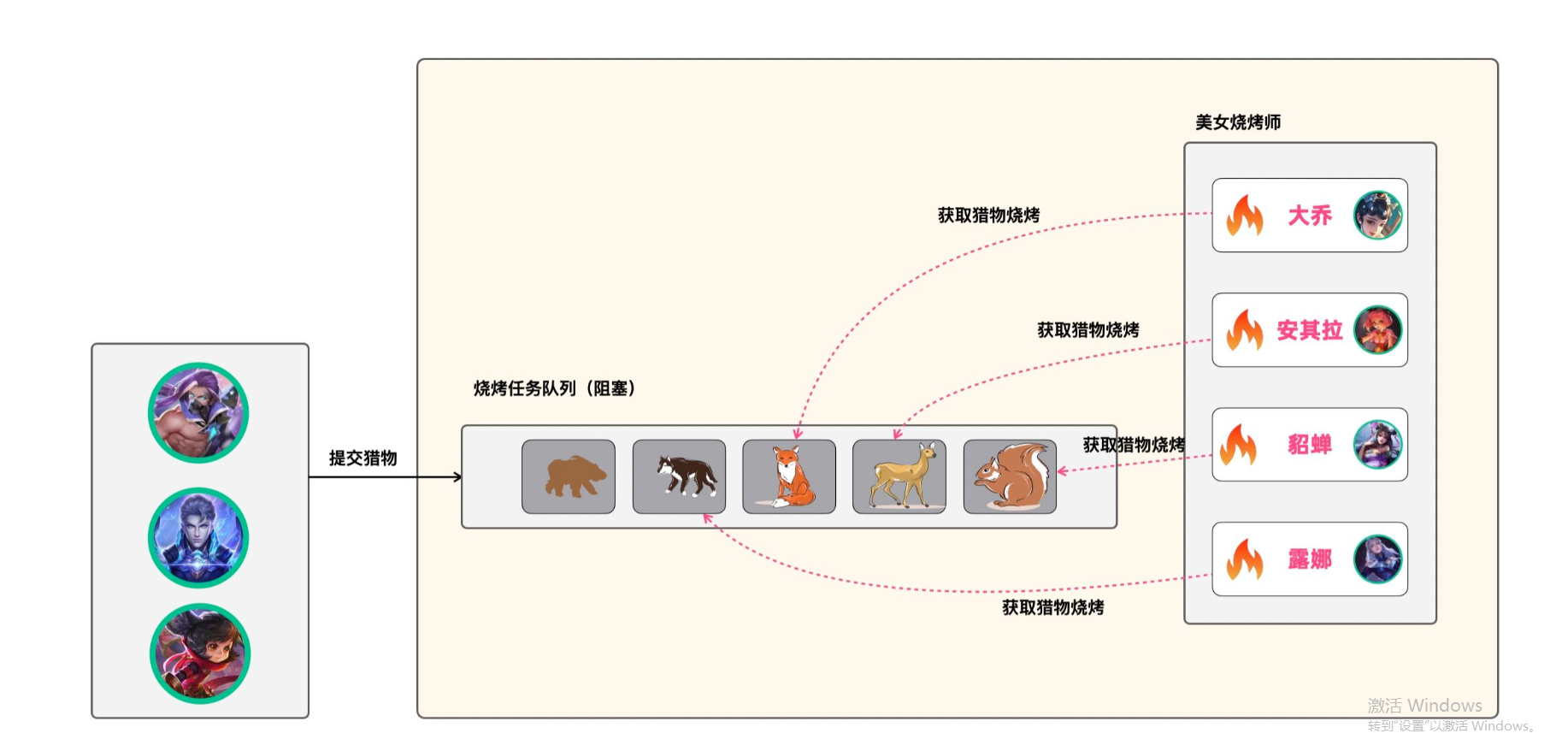
在下面的实现代码中,我们通过上述设计的TheKingThreadPool来定义个线程池,wildMonsters中的野怪表示待提交的任务,并安排3个工作线程来执行任务。在示例代码的末尾,当所有任务执行结束后,关闭线程池。
public static void main(String[] args) {
TheKingThreadPool theKingThreadPool = new TheKingThreadPool(3, new ArrayBlockingQueue<>(10));
String[] wildMonsters = {“棕熊”, “野鸡”, “灰狼”, “野兔”, “狐狸”, “小鹿”, “小花豹”, “野猪”};
for (String wildMonsterName : wildMonsters) {
theKingThreadPool.execute(new Task() {
public String getTaskDesc() {
return wildMonsterName;
}
public void run() {
System.out.println(Thread.currentThread().getName() + “:” + wildMonsterName + “已经烤好”);
}
});
}
theKingThreadPool.waitUntilAllTasksFinished();
theKingThreadPool.stop();
}
王者线程池运行结果如下:
Worker0:获取到新的任务->灰狼
Worker1:获取到新的任务->野鸡
Worker1:野鸡已经烤好
Worker2:获取到新的任务->棕熊
Worker2:棕熊已经烤好
Worker1:获取到新的任务->野兔
Worker1:野兔已经烤好
Worker0:灰狼已经烤好
Worker1:获取到新的任务->小鹿
Worker1:小鹿已经烤好
Worker2:获取到新的任务->狐狸
Worker2:狐狸已经烤好
Worker1:获取到新的任务->野猪
Worker1:野猪已经烤好
Worker0:获取到新的任务->小花豹
Worker0:小花豹已经烤好
Worker0:已结束工作,执行任务数量:2
Worker2:已结束工作,执行任务数量:2
Worker1:已结束工作,执行任务数量:4
Process finished with exit code 0
从结果中可以看到,效果完全符合预期。所有的任务都已经提交完毕,并且都被正确执行。此外,通过线程池的任务统计,可以看到任务并不是均匀分配,Worker1执行了4个任务,而Worker0和Worker2均只执行了2个任务,这也是线程池中的正常现象。
三、透彻理解Java中的线程池
===============
在手工制作线程线程池之后,再来理解Java中的线程池就相对要容易很多。当然,相比于王者线程池,Java中的线程池(ThreadPoolExecutor)的实现要复杂很多。所以,理解时应当遵循一定的结构和脉络,把握住线程池的核心要点,眉毛胡子一把抓、理不清层次会导致你无法有效理解它的设计内涵,进而导致你无法正确掌握它。
总体来说,Java中的线程池的设计核心都是围绕“任务”进行,可以通过一个框架、两大核心、三大过程概括。理解了这三个重要概念,基本上你已经能从相对抽象的层面理解了线程池。
-
一个框架:即线程池的整体设计存在一个框架,而不是杂乱无章的组成。所以,在学习线程池时,首先要能从立体上感知到这个框架的存在,而不要陷于凌乱的细节中;
-
两大核心:在线程池的整个框架中,围绕任务执行这件事,存在两大核心:任务的管理和任务的执行,对应的也就是任务队列和用于执行任务的工作线程。任务队列和工作线程是框架得以有效运转的关键部件;
-
三大过程:前面说过,线程池的整体设计都是围绕任务展开,所以框架内可以分为任务提交、任务管理和任务执行三大过程。
从类比的角度讲,你可以把框架看作是一个生产车间。在这个车间里,有一条流水线,任务队列和工作线程是这条流水线的两大关键组成。而在流水线运作的过程中,就会涉及任务提交、任务管理和任务执行等不同的过程。
下面这幅图,将帮助你立体地感知线程池的整体设计,建议你收藏。在这幅图中,清楚地展示了线程池整个框架的工作流程和核心部件,接下来的文章也将围绕这幅图展开。
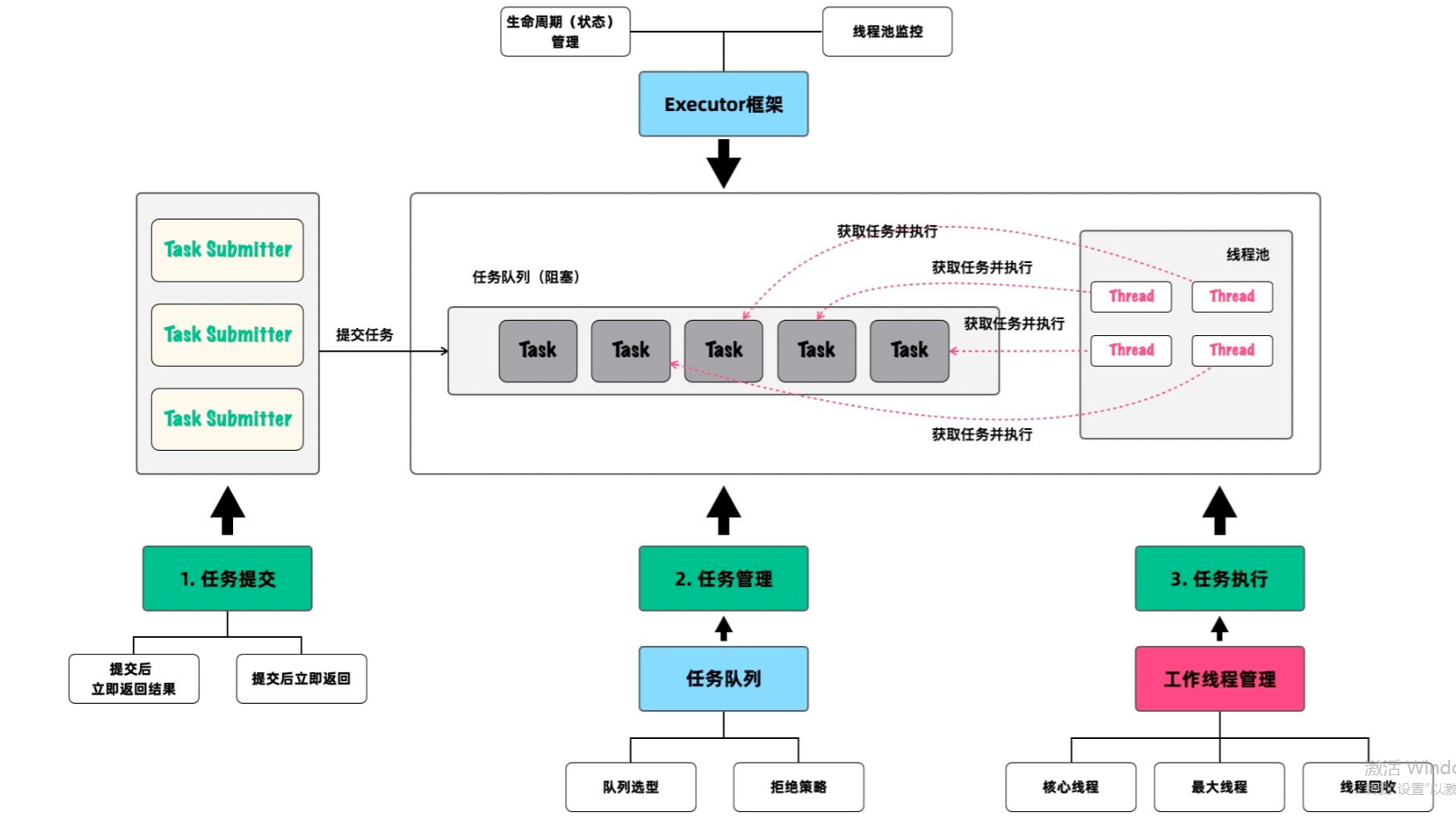
1. 线程池框架设计概览
=============
从源码层面看,理解Java中的线程池,要从下面这四兄弟的概念和关系入手,这四个概念务必了然于心。

-
Executor:作为线程池的最顶层接口,Executor的接口在设计上,实现了任务提交与任务执行之间的解耦,这是它存在的意义。在Executor中,只定义了一个方法void execute(Runnable command),用于执行提交的可运行的任务。注意,你看它这个方法的参数干脆就叫command,也就是“命令”,意在表明所提交的不是一个静止的对象,而是可运行的命令。并且,这个命令将在未来的某一时刻执行,具体由哪个线程来执行也是不确定的;
-
ExecutorService:继承了Executor的接口,并在此基础上提供可以管理服务和执行结果(Futrue) 的能力。ExecutorService所提供的submit方法可以返回任务的执行结果,而shutdown方法则可以用于关闭服务。相比起来,Executor只具备单一的执行能力,而ExecutorService则不仅具有执行能力,还提供了简单的服务管理能力;
-
AbstractExecutorService:作为ExecutorService的简单实现,该类通过RunnableFuture和newTaskFor实现了submit、invokeAny和invokeAll等方法;
-
ThreadPoolExecutor:该类是线程池的最终实现类,实现了Executor和ExecutorService中定义的能力,并丰富了AbstractExecutorService中的实现。在ThreadPoolExecutor中,定义了任务管理策略和线程池管理能力,相关能力的实现细节将是我们下文所要讲解的核心所在。
如果你觉得还是不太能直观地感受四兄弟的差异,那么你可以放大查看下面这幅高清图示。看的时候,要格外注意它们各自方法的不同,方法的不同意味着它们的能力不同。
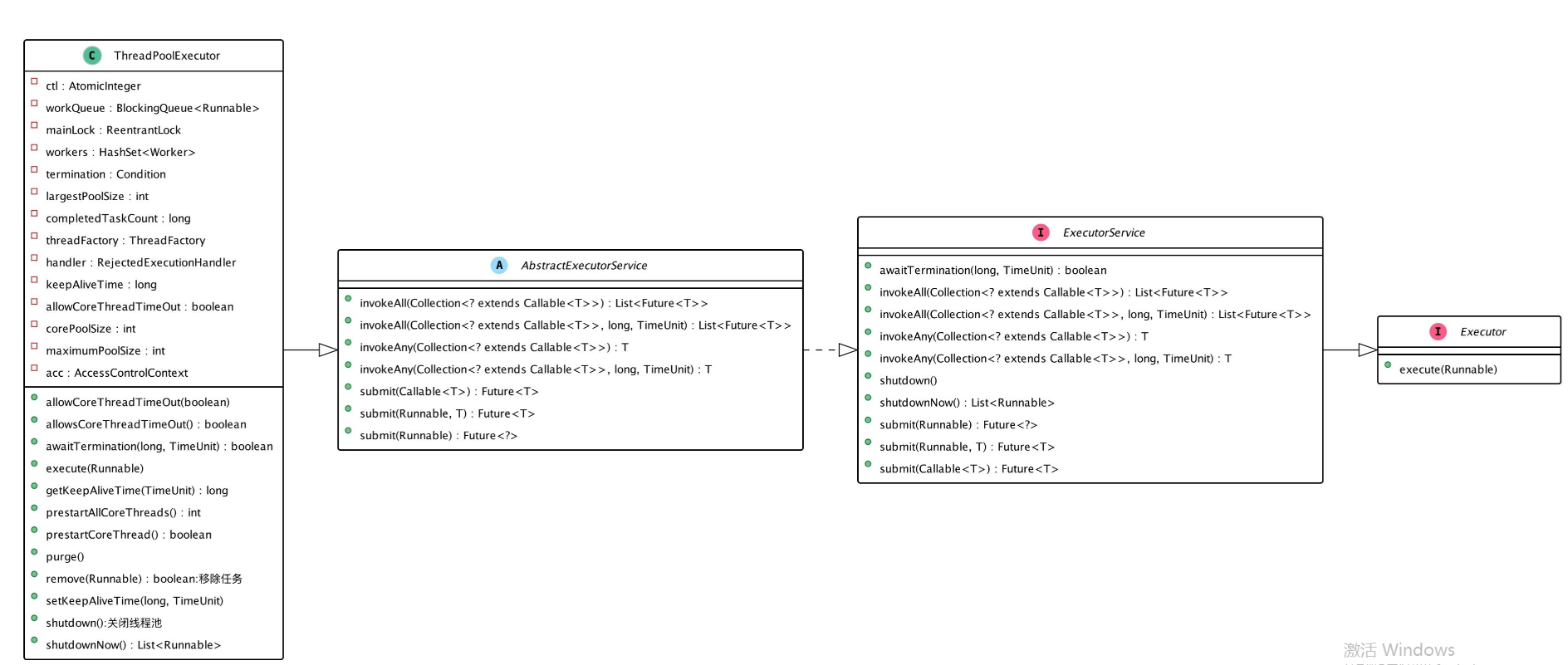
而对于线程池总体的执行过程,下面这幅图也建议你收藏。这幅图虽然简明,但完整展示了从任务提交到任务执行的整个过程。这个执行过程往往也是面试中的高频面试题,务必掌握。

(1)线程池的核心属性
===========
线程池中的一些核心属性选取如下,对于其中个别属性会做特别说明。
// 线程池控制相关的主要变量
// 这个变量很神奇,下文后专门陈述,请特别留意
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 待处理的任务队列
private final BlockingQueue < Runnable > workQueue;
// 工作线程集合
private final HashSet < Worker > workers = new HashSet < Worker > ();
// 创建线程所用到的线程工厂
private volatile ThreadFactory threadFactory;
// 拒绝策略
private volatile RejectedExecutionHandler handler;
// 核心线程数
private volatile int corePoolSize;
// 最大线程数
private volatile int maximumPoolSize;
// 空闲线程的保活时长
private volatile long keepAliveTime;
// 线程池变更的主要控制锁,在工作线程数、变更线程池状态等场景下都会用到
private final ReentrantLock mainLock = new ReentrantLock();
关于ctl字段的特别说明
在ThreadPoolExecutor的多个核心字段中,其他字段可能都比较好理解,但是ctl要单独拎出来做些解释。
顾名思义,ctl这个字段用于对线程池的控制。它的设计比较有趣,用一个字段却表示了两层含义,也就是这个字段实际是两个字段的合体:
-
runState:线程池的运行状态(高3位);
-
workerCount:工作线程数量(第29位)。
这两个字段的值相互独立,互不影响。那为何要用这种设计呢?这是因为,在线程池中这两个字段几乎总是如影相随,如果不用一个字段来表示的话,那么就需要通过锁的机制来控制两个字段的一致性。不得不说,这个字段设计上还是比较巧妙的。
在线程池中,也提供了一些方法可以方便地获取线程池的状态和工作线程数量,它们都是通过对ctl进行位运算得来。
/**
计算当前线程池的状态
*/
private static int runStateOf(int c) {
return c & ~CAPACITY;
}
/**
计算当前工作线程数
*/
private static int workerCountOf(int c) {
return c & CAPACITY;
}
/**
初始化ctl变量
*/
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
关于位运算,这里补充一点说明,如果你对位运算有点迷糊的话可以看看,如果你对它比较熟悉则可以直接跳过。
假设A=15,二进制是1111;B=6,二进制是110.
运算符名称描述示例&按位与如果相对应位都是1,则结果为1,否则为0(A&B),得到6,即110~按位非按位取反运算符翻转操作数的每一位,即0变成1,1变成0。(〜A)得到-16,即
11111111111111111111111111110000|按位或如果相对应位都是 0,则结果为 0,否则为 1(A | B)得到15,即 1111
(2)线程池的核心构造器
============
ThreadPoolExecutor有四个构造器,其中一个是核心构造器。你可以根据需要,按需使用这些构造器。
- 核心构造器之一:相对较为常用的一个构造器,你可以指定核心线程数、最大线程数、线程保活时间和任务队列类型。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
- 核心构造器之二:相比于第一个构造器,你可以在这个构造器中指定ThreadFactory. 通过ThreadFactory,你可以指定线程名称、分组等个性化信息。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
- 核心构造器之三:这个构造器的要点在于,你可以指定拒绝策略。关于任务队列的拒绝策略,下文有详细介绍。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
- 核心构造器之四:这个构造器是ThreadPoolExecutor的核心构造器,提供了较为全面的参数设置,上述的三个构造器都是基于它实现。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
(3)线程池中的核心方法
============
/**
- 提交Runnable类型的任务并执行,但不返回结果
*/
public void execute(Runnable command){…}
/**
- 提交Runnable类型的任务,并返回结果
*/
public Future<?> submit(Runnable task){…}
/**
- 提交Runnable类型的任务,并返回结果,支持指定默认结果
*/
public Future submit(Runnable task, T result){…}
/**
- 提交Callable类型的任务并执行
*/
public Future submit(Callable task) {…}
/**
- 关闭线程池,继续执行队列中未完成的任务,但不会接收新的任务
*/
public void shutdown() {…}
/**
- 立即关闭线程池,同时放弃未执行的任务,并不再接收新的任务
*/
public List shutdownNow(){…}
(4)线程池的状态与生命周期管理
================
前文说过,线程池恰似一个生产车间,而从生产车间的角度看,生产车间有运行、停产等不同状态,所以线程池也是有一定的状态和使用周期的。
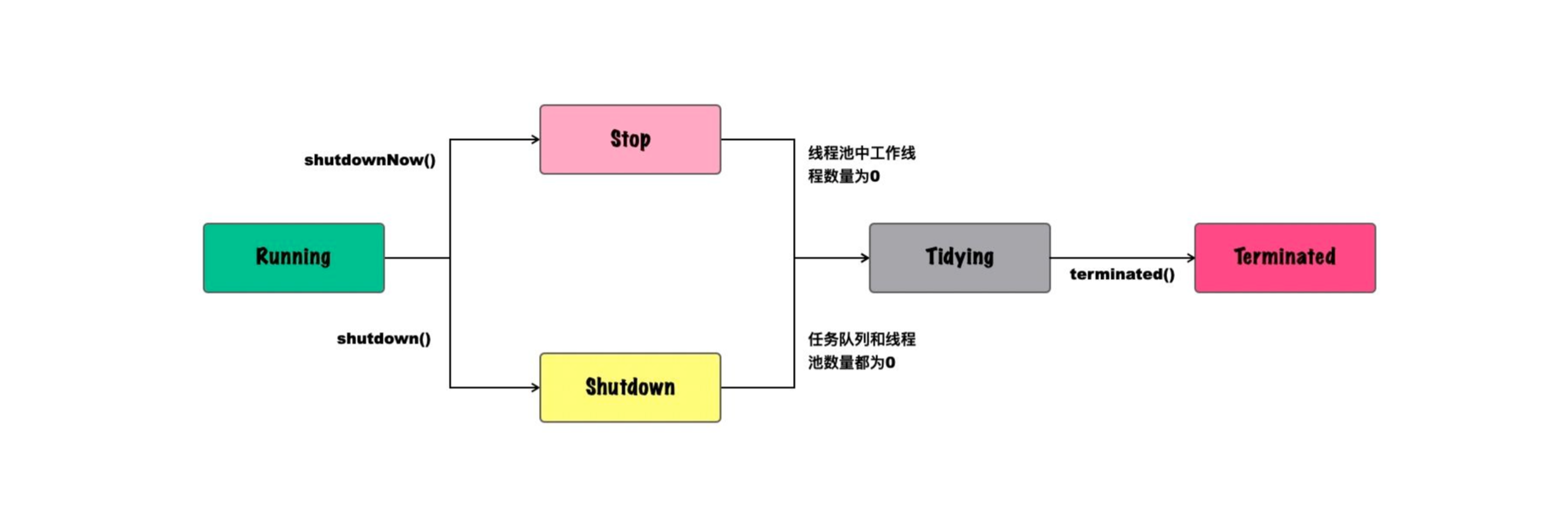
-
Running:运行中,该状态下可以继续向线程池中增加任务,并正常处理队列中的任务;
-
Shutdown:关闭中,该状态下线程池不会立即停止,但不能继续向线程池中增加任务,直到任务执行结束;
-
Stop:停止,该状态下将不再接收新的任务,同时不再处理队列中的任务,并中断工作中的线程;
-
Tidying:相对短暂的中间状态,所有任务都已经结束,并且所有的工作线程都不再存在(workerCount==0),并运行terminated()钩子方法;
-
Terminated:terminated()运行结束。
2. 如何向线程池中提交任务
===============
向线程池提交任务有两种比较常见的方式,一种是需要返回执行结果的,一种则是不需要返回结果的。
(1)不关注任务执行结果:execute
====================
通过execute()提交任务到线程池后,任务将在未来某个时刻执行,执行的任务的线程可能是当前线程池中的线程,也可能是新创建的线程。当然,如果此时线程池应关闭,或者任务队列已满,那么该任务将交由RejectedExecutionHandler处理。
(2)关注任务执行结果:submit
==================
通过submit()提交任务到线程池后,运行机制和execute类似,其核心不同在于,由submit()提交任务时将等待任务执行结束并返回结果。
3. 如何管理提交的任务
=============
(1)任务队列选型策略
===========
-
SynchronousQueue:无缝传递(Direct handoffs)。当新的任务到达时,将直接交由线程处理,而不是放入缓存队列。因此,如果任务达到时却没有可用线程,那么将会创建新的线程。所以,为了避免任务丢失,在使用SynchronousQueue时,将会需要创建无数的线程,在使用时需要谨慎评估。
-
LinkedBlockingQueue:无界队列,新提交的任务都会缓存到该队列中。使用无界队列时,只有corePoolSize中的线程来处理队列中的任务,这时候和maximumPoolSize是没有关系的,它不会创建新的线程。当然,你需要注意的是,如果任务的处理速度远低于任务的产生速度,那么LinkedBlockingQueue的无限增长可能会导致内存容量等问题。
-
ArrayBlockingQueue:有界队列,可能会触发创建新的工作线程,maximumPoolSize参数设置在有界队列中将发挥作用。在使用有界队列时,要特别注意任务队列大小和工作线程数量之间的权衡。如果任务队列大但是线程数量少,那么结果会是系统资源(主要是CPU)占用率较低,但同时系统的吞吐量也会降低。反之,如果缩小任务队列并扩大工作线程数量,那么结果则是系统吞吐量增大,但同时系统资源占用也会增加。所以,使用有界队列时,要考虑到平衡的艺术,并配置相应的拒绝策略。
(2)如何选择合适的拒绝策略
==============
在使用线程池时,拒绝策略是必须要确认的地方,因为它可能会造成任务丢失。
当线程池已经关闭或任务队列已满且无法再创建新的工作线程时,那么新提交的任务将会被拒绝,拒绝时将调用RejectedExecutionHandler中的rejectedExecution(Runnable r, ThreadPoolExecutor executor)来执行具体的拒绝动作。
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
以execute方法为例,当线程池状态异常或无法新增工作线程时,将会执行任务拒绝策略。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf© < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning© && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
ThreadPoolExecutor的默认拒绝策略是AbortPolicy,这一点在属性定义中已经确定。在大部分场景中,直接拒绝任务都是不合适的。
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
-
AbortPolicy:默认策略,直接抛出RejectedExecutionException异常;
-
CallerRunsPolicy:交由当前线程自己来执行。这种策略这提供了一个简单的反馈控制机制,可以减慢提交新任务的速度;
-
DiscardPolicy:直接丢弃任务,不会抛出异常;
-
DiscardOldestPolicy:如果此时线程池没有关闭,将从队列的头部取出第一个任务并丢弃,并再次尝试执行。如果执行失败,那么将重复这个过程。
如果上述四种策略均不满足,你也可以通过RejectedExecutionHandler接口定制个性化的拒绝策略。事实上,为了兼顾任务不丢失和系统负载,建议你自己实现拒绝策略。
(3)队列维护
=======
本次面试答案,以及收集到的大厂必问面试题分享:

();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
ThreadPoolExecutor的默认拒绝策略是AbortPolicy,这一点在属性定义中已经确定。在大部分场景中,直接拒绝任务都是不合适的。
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
-
AbortPolicy:默认策略,直接抛出RejectedExecutionException异常;
-
CallerRunsPolicy:交由当前线程自己来执行。这种策略这提供了一个简单的反馈控制机制,可以减慢提交新任务的速度;
-
DiscardPolicy:直接丢弃任务,不会抛出异常;
-
DiscardOldestPolicy:如果此时线程池没有关闭,将从队列的头部取出第一个任务并丢弃,并再次尝试执行。如果执行失败,那么将重复这个过程。
如果上述四种策略均不满足,你也可以通过RejectedExecutionHandler接口定制个性化的拒绝策略。事实上,为了兼顾任务不丢失和系统负载,建议你自己实现拒绝策略。
(3)队列维护
=======
本次面试答案,以及收集到的大厂必问面试题分享:
[外链图片转存中…(img-CNxWM56l-1714990513534)]














 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









