







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
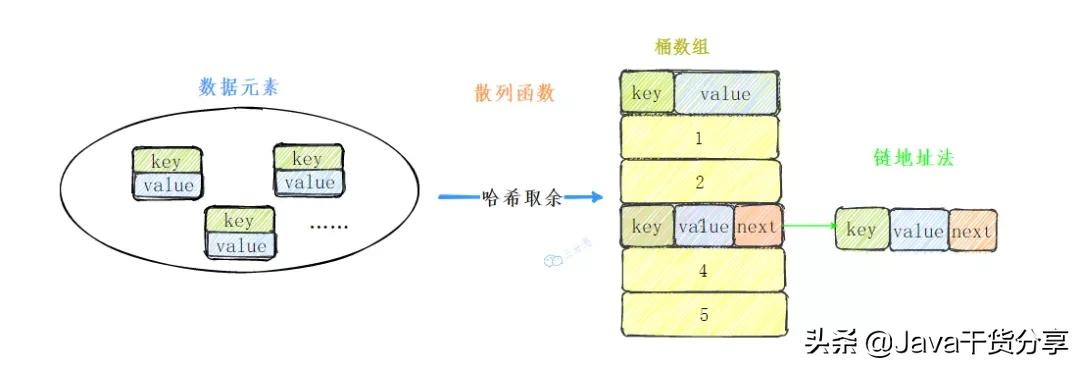
自定义HashMap整体结构
内部节点类
=====
我们需要定义一个节点来作为具体数据的载体,它不仅要承载键值对,同样还得作为单链表的节点:
/**
-
节点类
-
@param
-
@param
*/
class Node<K, V> {
//键值对
private K key;
private V value;
//链表,后继
private Node<K, V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
成员变量
====
主要有四个成员变量,其中桶数组作为装载数据元素的结构:
//默认容量
final int DEFAULT_CAPACITY = 16;
//负载因子
final float LOAD_FACTOR = 0.75f;
//HashMap的大小
private int size;
//桶数组
Node<K, V>[] buckets;
构造方法
====
构造方法有两个,无参构造方法,桶数组默认容量,有参指定桶数组容量。
/**
- 无参构造器,设置桶数组默认容量
*/
public ThirdHashMap() {
buckets = new Node[DEFAULT_CAPACITY];
size = 0;
}
/**
-
有参构造器,指定桶数组容量
-
@param capacity
*/
public ThirdHashMap(int capacity) {
buckets = new Node[capacity];
size = 0;
}
散列函数
====
散列函数,就是我们前面说的hashCode()和数组长度取余。
/**
-
哈希函数,获取地址
-
@param key
-
@return
*/
private int getIndex(K key, int length) {
//获取hash code
int hashCode = key.hashCode();
//和桶数组长度取余
int index = hashCode % length;
return Math.abs(index);
}
put方法
=====
我用了一个putval方法来完成实际的逻辑,这是因为扩容也会用到这个方法。
大概的逻辑:
-
获取元素插入位置
-
当前位置为空,直接插入
-
位置不为空,发生冲突,遍历链表
-
如果元素key和节点相同,覆盖,否则新建节点插入链表头部
/**
-
put方法
-
@param key
-
@param value
-
@return
*/
public void put(K key, V value) {
//判断是否需要进行扩容
if (size >= buckets.length * LOAD_FACTOR) resize();
putVal(key, value, buckets);
}
/**
-
将元素存入指定的node数组
-
@param key
-
@param value
-
@param table
*/
private void putVal(K key, V value, Node<K, V>[] table) {
//获取位置
int index = getIndex(key, table.length);
Node node = table[index];
//插入的位置为空
if (node == null) {
table[index] = new Node<>(key, value);
size++;
return;
}
//插入位置不为空,说明发生冲突,使用链地址法,遍历链表
while (node != null) {
//如果key相同,就覆盖掉
if ((node.key.hashCode() == key.hashCode())
&& (node.key == key || node.key.equals(key))) {
node.value = value;
return;
}
node = node.next;
}
//当前key不在链表中,插入链表头部
Node newNode = new Node(key, value, table[index]);
table[index] = newNode;
size++;
}
扩容方法
====
扩容的大概过程:
-
创建两倍容量的新数组
-
将当前桶数组的元素重新散列到新的数组
-
新数组置为map的桶数组
/**
- 扩容
*/
private void resize() {
//创建一个两倍容量的桶数组
Node<K, V>[] newBuckets = new Node[buckets.length * 2];
//将当前元素重新散列到新的桶数组
rehash(newBuckets);
buckets = newBuckets;
}
/**
-
重新散列当前元素
-
@param newBuckets
*/
private void rehash(Node<K, V>[] newBuckets) {
//map大小重新计算
size = 0;
//将旧的桶数组的元素全部刷到新的桶数组里
for (int i = 0; i < buckets.length; i++) {
//为空,跳过
if (buckets[i] == null) {
continue;
}
Node<K, V> node = buckets[i];
while (node != null) {
//将元素放入新数组
putVal(node.key, node.value, newBuckets);
node = node.next;
}
}
}
get方法
=====
get方法就比较简单,通过散列函数获取地址,这里我省去了有没有成链表的判断,直接查找链表。
/**
-
获取元素
-
@param key
-
@return
*/
public V get(K key) {
//获取key对应的地址
int index = getIndex(key, buckets.length);
if (buckets[index] == null) return null;
Node<K, V> node = buckets[index];
//查找链表
while (node != null) {
if ((node.key.hashCode() == key.hashCode())
&& (node.key == key || node.key.equals(key))) {
return node.value;
}
node = node.next;
}
return null;
}
完整代码:

完整代码
测试
==
测试代码如下:
@Test
void test0() {
ThirdHashMap map = new ThirdHashMap();
for (int i = 0; i < 100; i++) {
map.put(“刘华强” + i, “你这瓜保熟吗?” + i);
}
System.out.println(map.size());
for (int i = 0; i < 100; i++) {
System.out.println(map.get(“刘华强” + i));
}
}
@Test
void test1() {
ThirdHashMap map = new ThirdHashMap();
map.put(“刘华强1”,“哥们,你这瓜保熟吗?”);
map.put(“刘华强1”,“你这瓜熟我肯定要啊!”);
System.out.println(map.get(“刘华强1”));
}
大家可以自行跑一下看看结果。
总结
==
好了,到这,我们一个简单的HashMap就实现了,这下,面试快手再也不怕手写HashMap了。
快手面试官:真的吗?我不信。我就要你手写个红黑树版的……

当然了,我们也发现,HashMap的O(1)时间复杂度操作是在冲突比较少的情况下,简单的哈希取余肯定不是最优的散列函数;冲突之后,链表拉的太长,同样影响性能;我们的扩容和put其实也存在线程安全的问题……
但是,现实里我们不用考虑那么多,因为李老爷已经帮我们写好了,我们只管调用就完了。手写HashMap?这么狠,面试都卷到这种程度了?
第一次见到这个面试题,是在某个不方便透露姓名的Offer收割机大佬的文章:
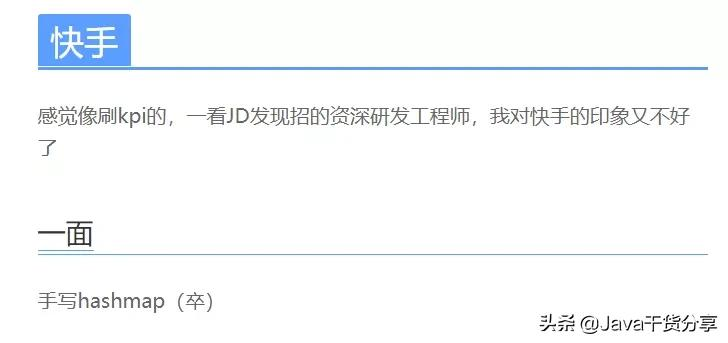
手写HashMap,快手一面卒
这……我当时就麻了,我们都知道HashMap的数据结构是数组+链表+红黑树,这是要手撕红黑树的节奏吗?
后来,整理了一些面经,发现这道题在快手的面试出现还比较频繁,分析这道题应该在快手的面试题库。那既然频繁出,肯定不能是手撕红黑树——我觉得面试官也多半撕不出来,不撕红黑树,那这道题还有点救,慢慢往下看。
认识哈希表
=====
HashMap其实是数据结构中的哈希表在Java里的实现。
哈希表本质
=====
哈希表也叫散列表,我们先来看看哈希表的定义:
哈希表是根据关键码的值而直接进行访问的数据结构。
就像有人到公司找老三,前台小姐姐拿手一指,那个墙角的工位就是。
简单说来说,哈希表由两个要素构成:桶数组和散列函数。
-
桶数组:一排工位
-
散列函数:老三在墙角
桶数组
===
我们可能知道,有一类基础的数据结构线性表,而线性表又分两种,数组和链表。
哈希表数据结构里,存储元素的数据结构就是数组,数组里的每个单元都可以想象成一个桶(Bucket)。
假如给若干个程序员分配工位:蛋蛋、熊大、牛儿、张三,我们观察到,这些名字比较有特色,最后一个字都是数字,我们可以把它提取出来作为关键码,这些一来,就可以把他们分配到对应编号的工位,没分配到的工位就让它先空着。
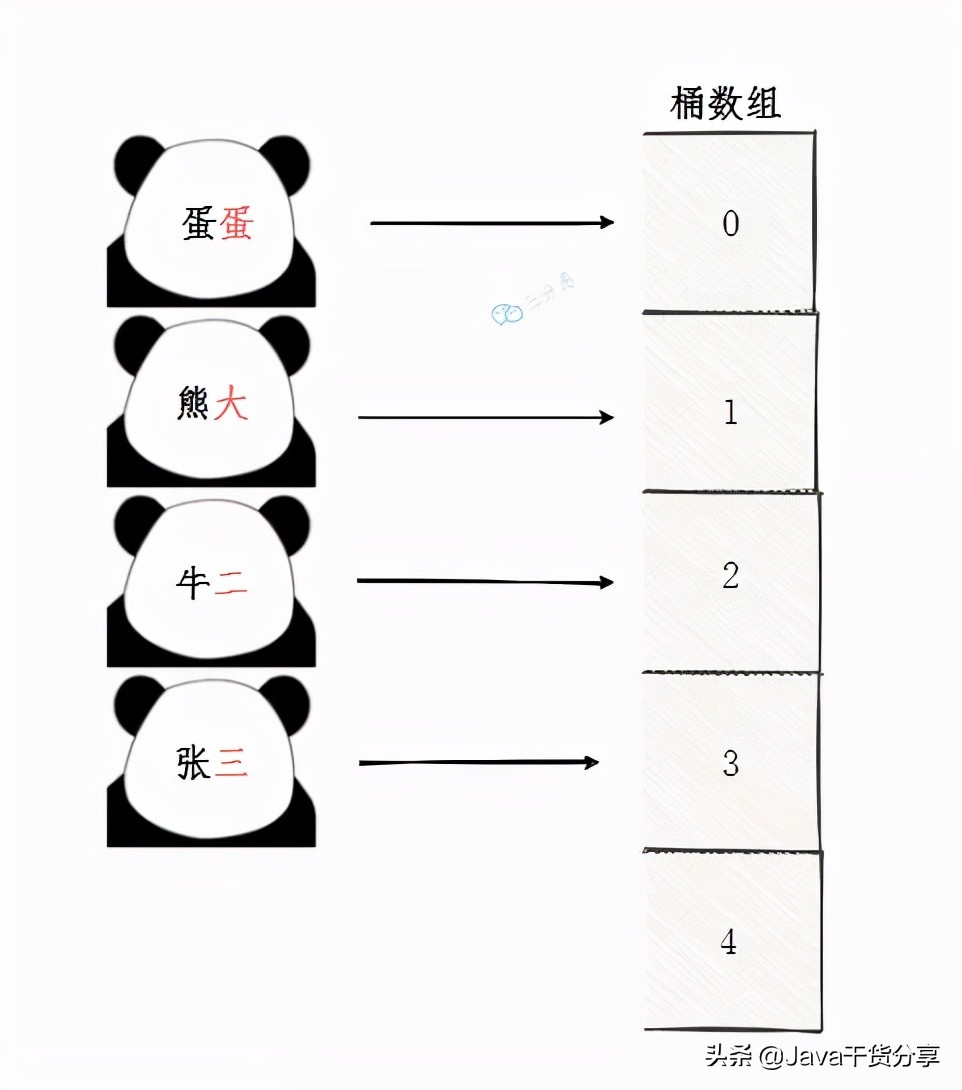
元素映射
那么在这种情况下,我们查找/插入/删除的时间复杂度是多少呢?很明显,都是O(1)。
但咱们也不是葫芦娃,名字不能都叫一二三四五六七之类的,假如来的新人叫南宫大牛,那我们怎么分配他呢?
这就引入了我们的第二个关键要素——散列函数。
散列函数
====
我们需要在元素和桶数组对应位置建立一种映射映射关系,这种映射关系就是散列函数,也可以叫哈希函数。
例如,我们一堆无规律的名字诸葛钢铁、刘华强、王司徒、张全蛋……我们就需要通过散列函数,算出这些名字应该分配到哪一号工位。
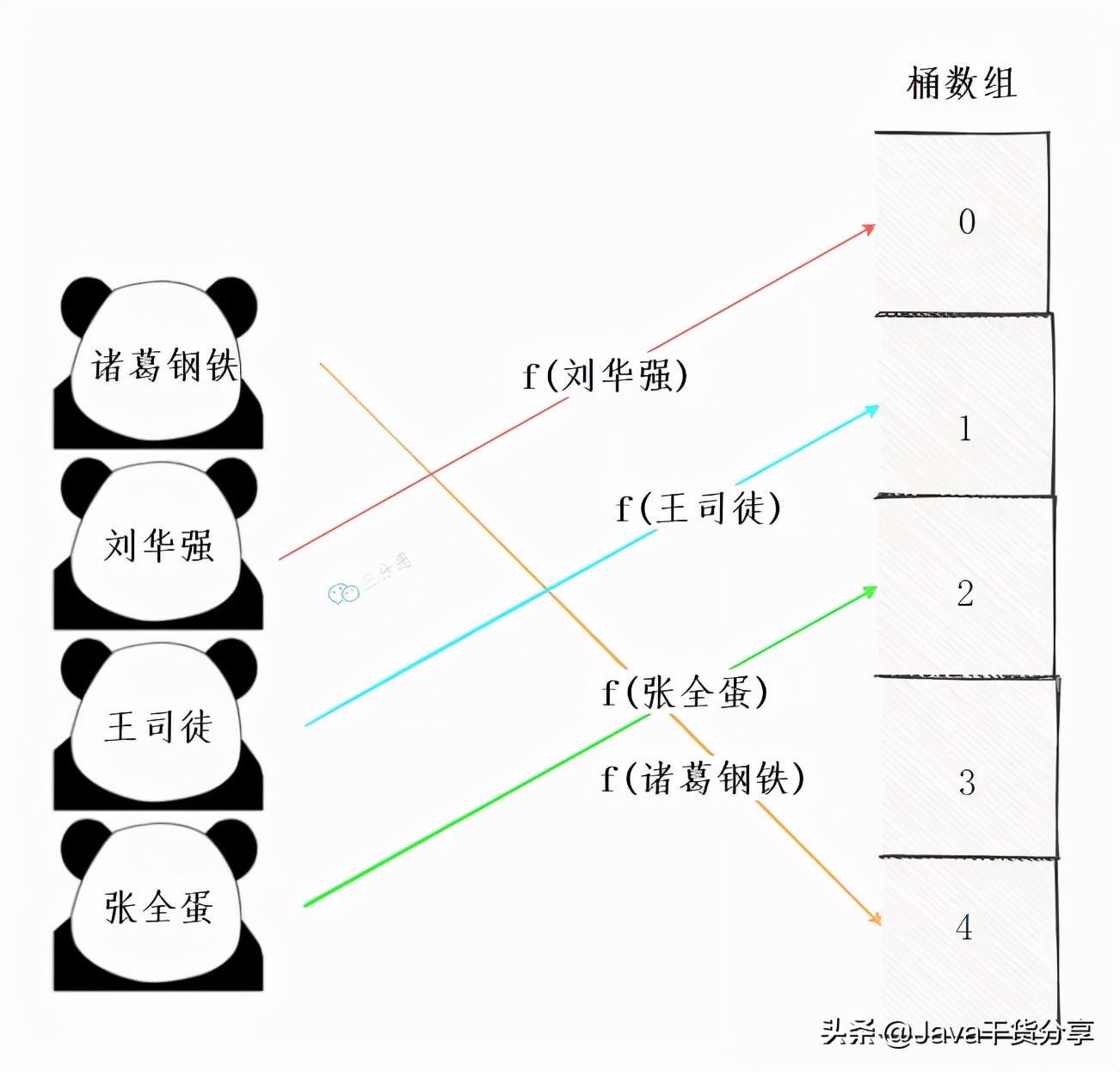
散列函数
散列函数构造
======
散列函数也叫哈希函数,假如我们数据元素的key是整数或者可以转换为一个整数,可以通过这些常见方法来获取映射地址。
-
直接定址法直接根据key来映射到对应的数组位置,例如1232放到下标1232的位置。
-
数字分析法取key的某些数字(例如十位和百位)作为映射的位置
-
平方取中法取key平方的中间几位作为映射的位置
-
折叠法将key分割成位数相同的几段,然后把它们的叠加和作为映射的位置
-
除留余数法H(key)=key%p(p<=N),关键字除以一个不大于哈希表长度的正整数p,所得余数为哈希地址,这是应用最广泛的散列函数构造方法。
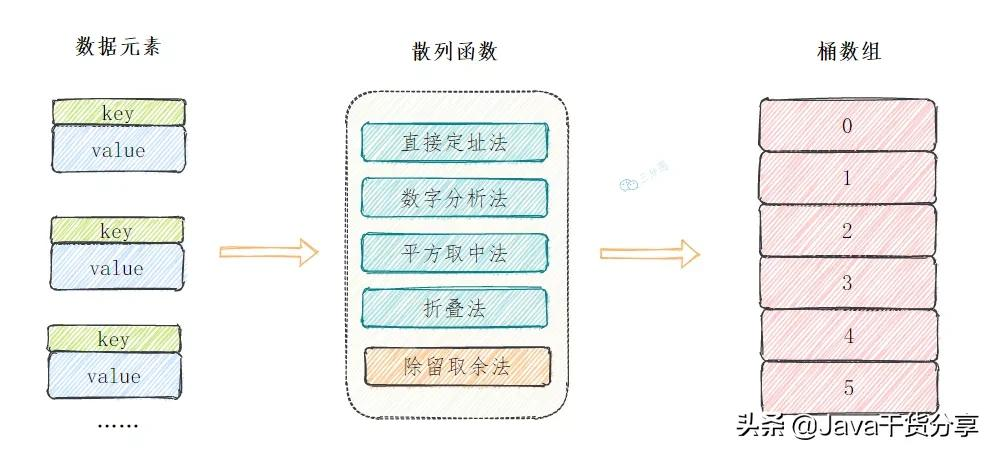
散列函数构造
在Java里,Object类里提供了一个默认的hashCode()方法,它返回的是一个32位int形整数,其实也就是对象在内存里的存储地址。
但是,这个整数肯定是要经过处理的,上面几种方法里直接定址法可以排除,因为我们不可能建那么大的桶数组。
而且我们最后计算出来的散列地址,尽可能要在桶数组长度范围之内,所以我们选择除留取余法。
哈希冲突
====
理想的情况,是每个数据元素经过哈希函数的计算,落在它独属的桶数组的位置。
但是现实通常不如人意,我们的空间是有限的,设计再好的哈希函数也不能完全避免哈希冲突。所谓的哈希冲突,就是不同的key经过哈希函数计算,落到了同一个下标。
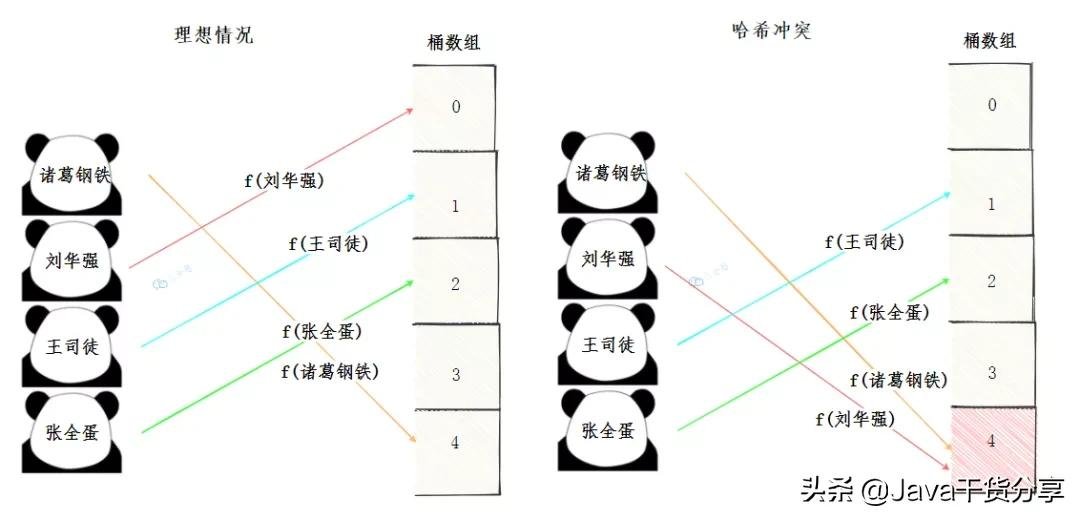
哈希冲突
既然有了冲突,就得想办法解决冲突,常见的解决哈希冲突的办法有:
链地址法
====
也叫拉链法,看起来,像在桶数组上再拉一个链表出来,把发生哈希冲突的元素放到一个链表里,查找的时候,从前往后遍历链表,找到对应的key就行了。
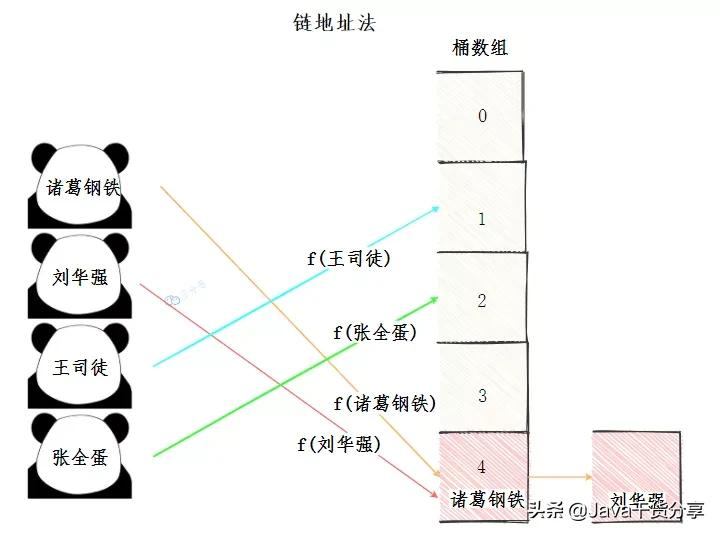
链地址法
开放地址法
=====
开放地址法,简单来说就是给冲突的元素再在桶数组里找到一个空闲的位置。
找到空闲位置的方法有很多种:
-
线行探查法: 从冲突的位置开始,依次判断下一个位置是否空闲,直至找到空闲位置
-
平方探查法: 从冲突的位置x开始,第一次增加12个位置,第二次增加22…,直至找到空闲的位置
-
双散列函数探查法
……
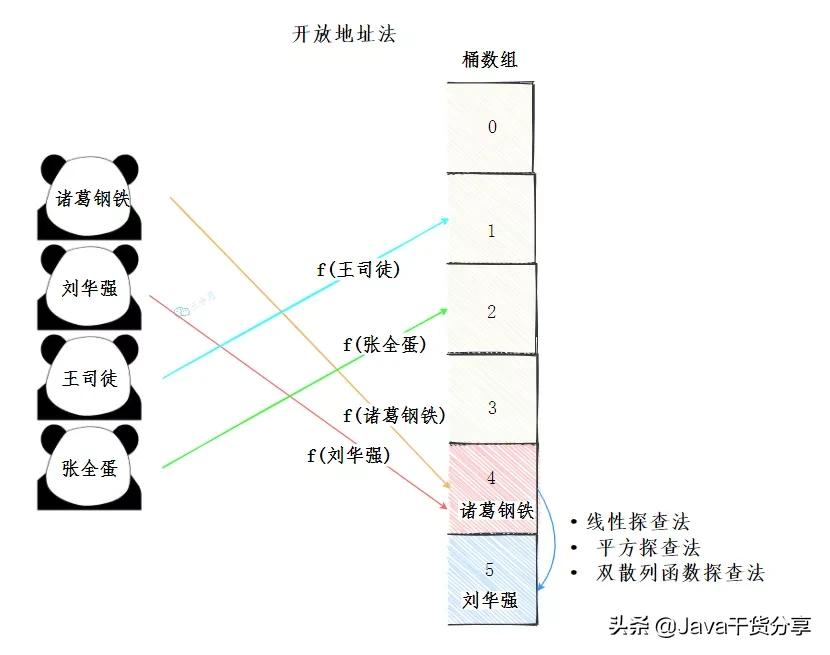
开放地址法
再哈希法
====
构造多个哈希函数,发生冲突时,更换哈希函数,直至找到空闲位置。
建立公共溢出区
=======
建立公共溢出区,把发生冲突的数据元素存储到公共溢出区。
很明显,接下来我们解决冲突,会使用链地址法。
好了,哈希表的介绍就到这,相信你已经对哈希表的本质有了深刻的理解,接下来,进入coding时间。
HashMap实现
=========
我们实现的简单的HashMap命名为ThirdHashMap,先确定整体的设计:
-
散列函数:hashCode()+除留余数法
-
冲突解决:链地址法
整体结构如下:
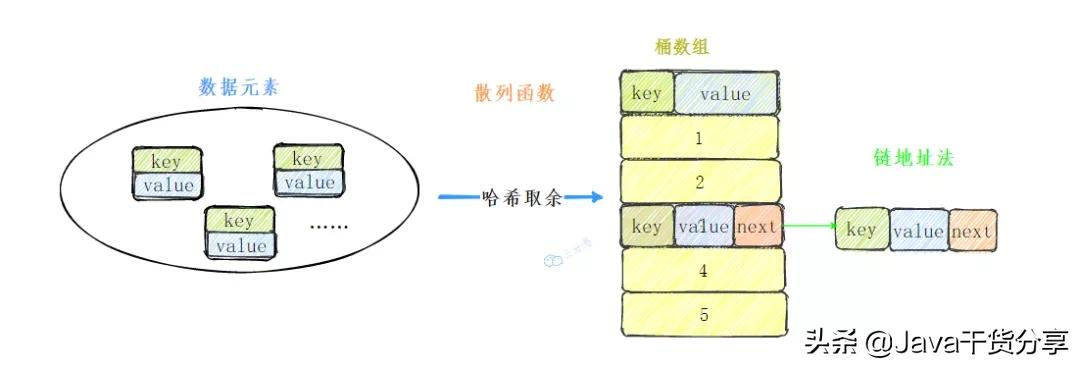
自定义HashMap整体结构
内部节点类
=====
我们需要定义一个节点来作为具体数据的载体,它不仅要承载键值对,同样还得作为单链表的节点:
/**
-
节点类
-
@param
-
@param
*/
class Node<K, V> {
//键值对
private K key;
private V value;
//链表,后继
private Node<K, V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
成员变量
====
主要有四个成员变量,其中桶数组作为装载数据元素的结构:
//默认容量
final int DEFAULT_CAPACITY = 16;
//负载因子
final float LOAD_FACTOR = 0.75f;
//HashMap的大小
private int size;
//桶数组
Node<K, V>[] buckets;
构造方法
====
构造方法有两个,无参构造方法,桶数组默认容量,有参指定桶数组容量。
/**
- 无参构造器,设置桶数组默认容量
*/
public ThirdHashMap() {
buckets = new Node[DEFAULT_CAPACITY];
size = 0;
}
/**
-
有参构造器,指定桶数组容量
-
@param capacity
*/
public ThirdHashMap(int capacity) {
buckets = new Node[capacity];
size = 0;
}
散列函数
====
最后:学习总结——MyBtis知识脑图(纯手绘xmind文档)
学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能迅速过完整个知识,脑补回来。下方即为我手绘的MyBtis知识脑图,由于是xmind文件,不好上传,所以小编将其以图片形式导出来传在此处,细节方面不是特别清晰。但可给感兴趣的朋友提供完整的MyBtis知识脑图原件(包括上方的面试解析xmind文档)

除此之外,前文所提及的Alibaba珍藏版mybatis手写文档以及一本小小的MyBatis源码分析文档——《MyBatis源码分析》等等相关的学习笔记文档,也皆可分享给认可的朋友!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Node<K, V>[] buckets;
构造方法
====
构造方法有两个,无参构造方法,桶数组默认容量,有参指定桶数组容量。
/**
- 无参构造器,设置桶数组默认容量
*/
public ThirdHashMap() {
buckets = new Node[DEFAULT_CAPACITY];
size = 0;
}
/**
-
有参构造器,指定桶数组容量
-
@param capacity
*/
public ThirdHashMap(int capacity) {
buckets = new Node[capacity];
size = 0;
}
散列函数
====
最后:学习总结——MyBtis知识脑图(纯手绘xmind文档)
学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能迅速过完整个知识,脑补回来。下方即为我手绘的MyBtis知识脑图,由于是xmind文件,不好上传,所以小编将其以图片形式导出来传在此处,细节方面不是特别清晰。但可给感兴趣的朋友提供完整的MyBtis知识脑图原件(包括上方的面试解析xmind文档)
[外链图片转存中…(img-VfaS2rqI-1713188364742)]
除此之外,前文所提及的Alibaba珍藏版mybatis手写文档以及一本小小的MyBatis源码分析文档——《MyBatis源码分析》等等相关的学习笔记文档,也皆可分享给认可的朋友!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-PRWYWztN-1713188364742)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









