







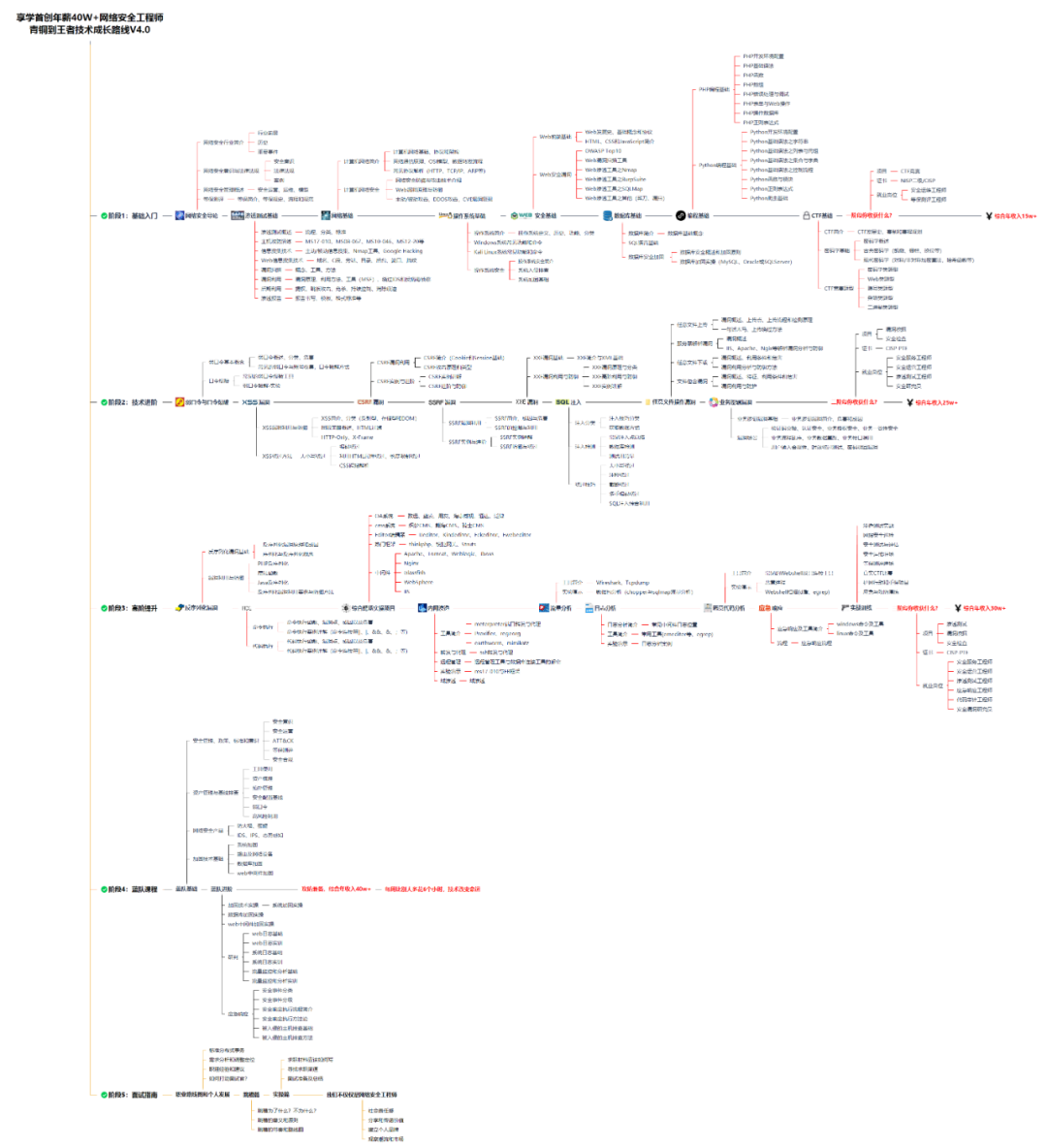
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
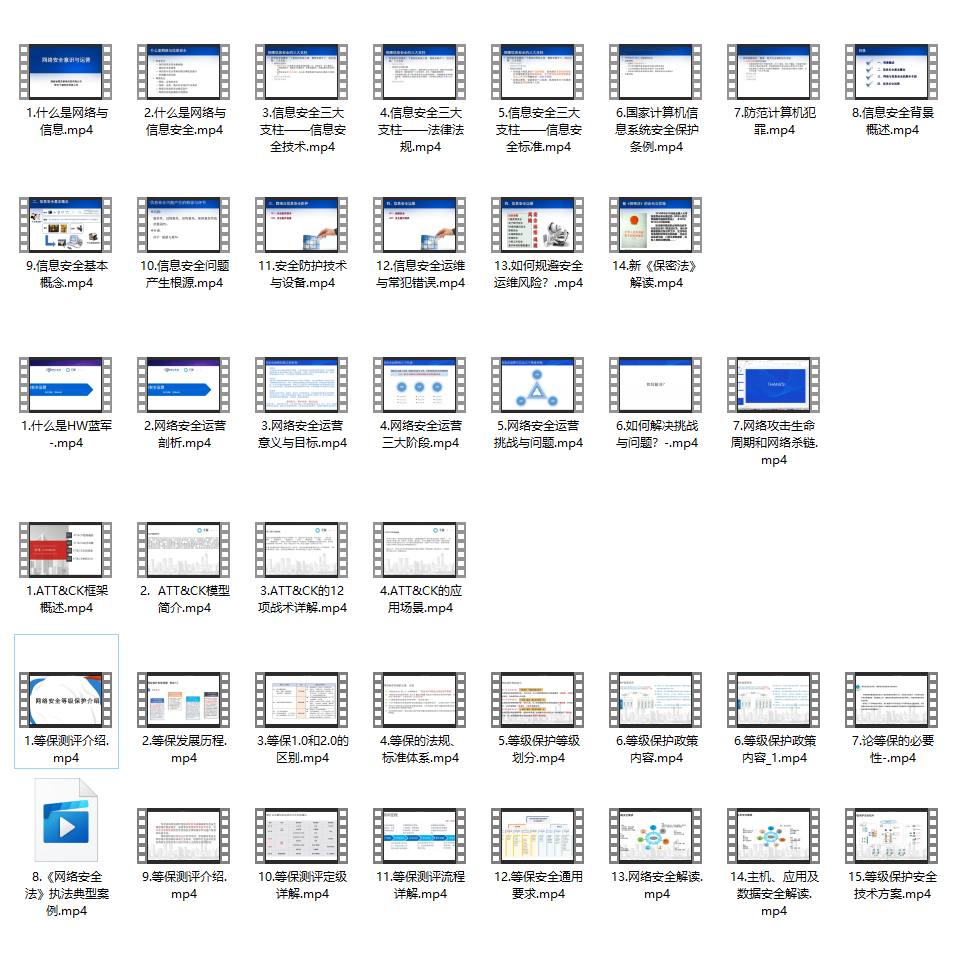
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
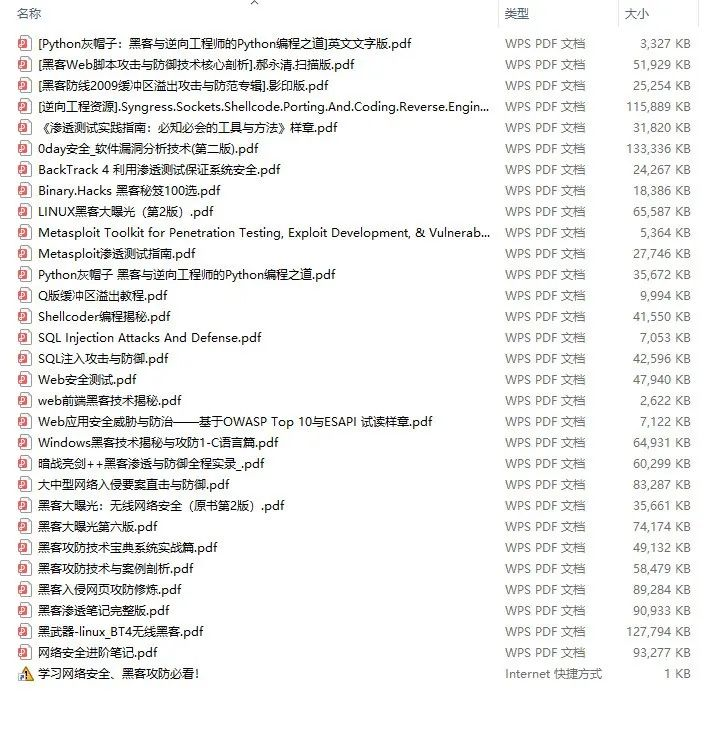
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

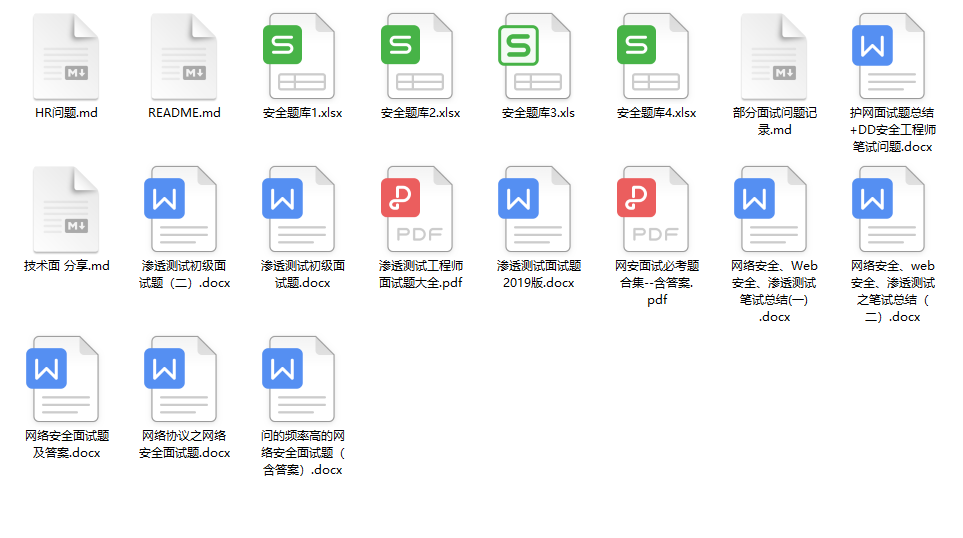
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
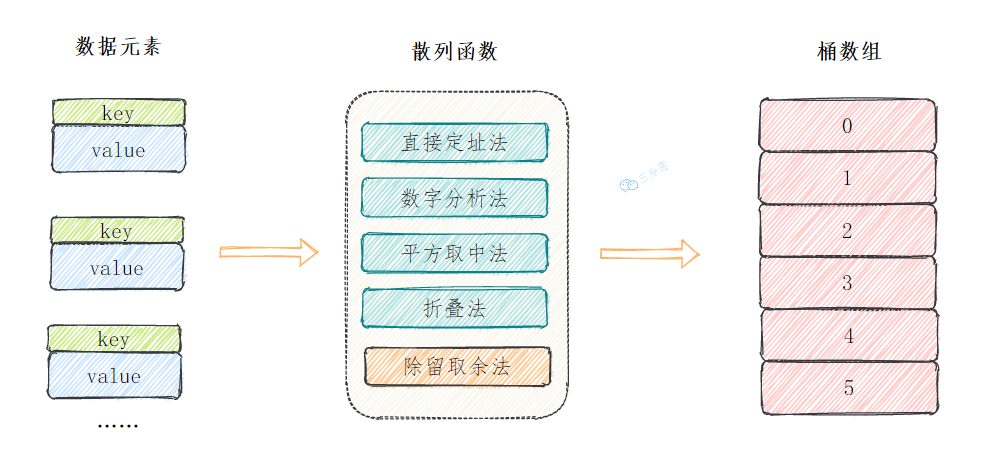
散列函数也叫哈希函数,假如我们数据元素的key是整数或者可以转换为一个整数,可以通过这些常见方法来获取映射地址。
- 直接定址法
直接根据key来映射到对应的数组位置,例如1232放到下标1232的位置。
- 数字分析法
取key的某些数字(例如十位和百位)作为映射的位置
- 平方取中法
取key平方的中间几位作为映射的位置
- 折叠法
将key分割成位数相同的几段,然后把它们的叠加和作为映射的位置
- 除留余数法
H(key)=key%p(p<=N),关键字除以一个不大于哈希表长度的正整数p,所得余数为哈希地址,这是应用最广泛的散列函数构造方法。
在Java里,Object类里提供了一个默认的hashCode()方法,它返回的是一个32位int形整数,其实也就是对象在内存里的存储地址。
但是,这个整数肯定是要经过处理的,上面几种方法里直接定址法可以排除,因为我们不可能建那么大的桶数组。
而且我们最后计算出来的散列地址,尽可能要在桶数组长度范围之内,所以我们选择除留取余法。
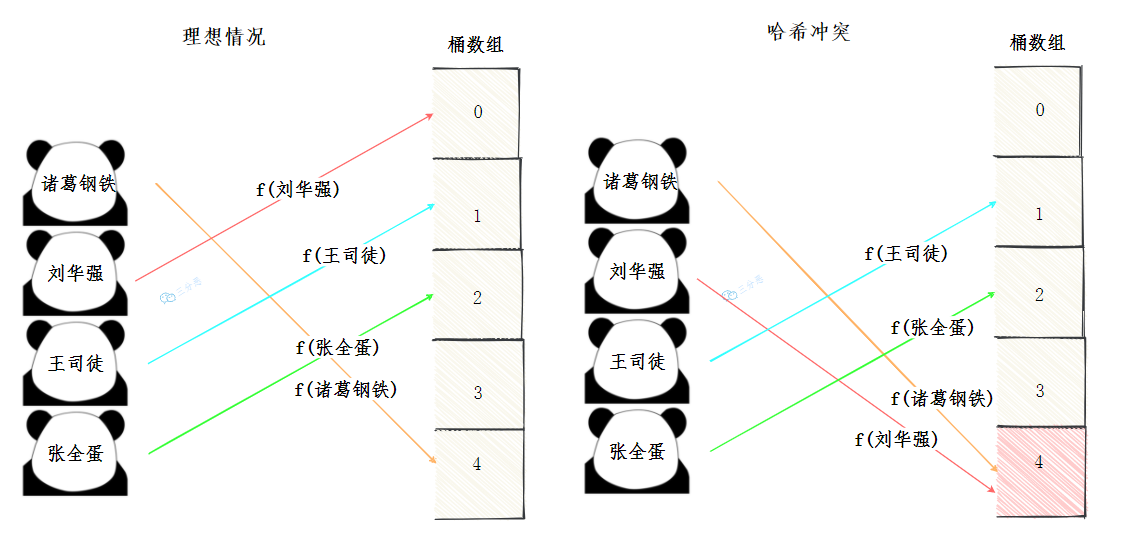
哈希冲突
理想的情况,是每个数据元素经过哈希函数的计算,落在它独属的桶数组的位置。
但是现实通常不如人意,我们的空间是有限的,设计再好的哈希函数也不能完全避免哈希冲突。所谓的哈希冲突,就是不同的key经过哈希函数计算,落到了同一个下标。
既然有了冲突,就得想办法解决冲突,常见的解决哈希冲突的办法有:
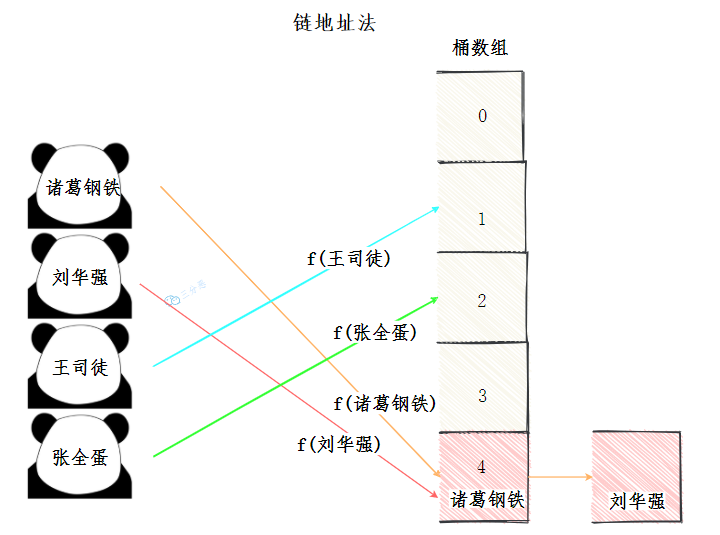
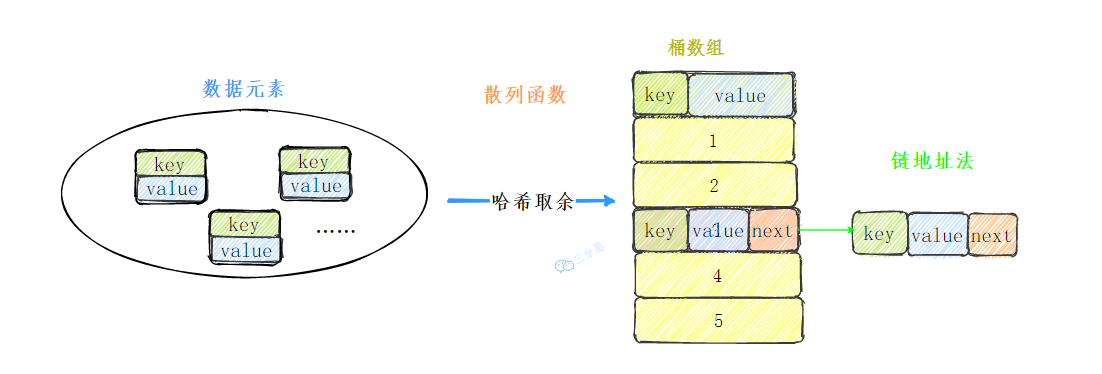
链地址法
也叫拉链法,看起来,像在桶数组上再拉一个链表出来,把发生哈希冲突的元素放到一个链表里,查找的时候,从前往后遍历链表,找到对应的key就行了。
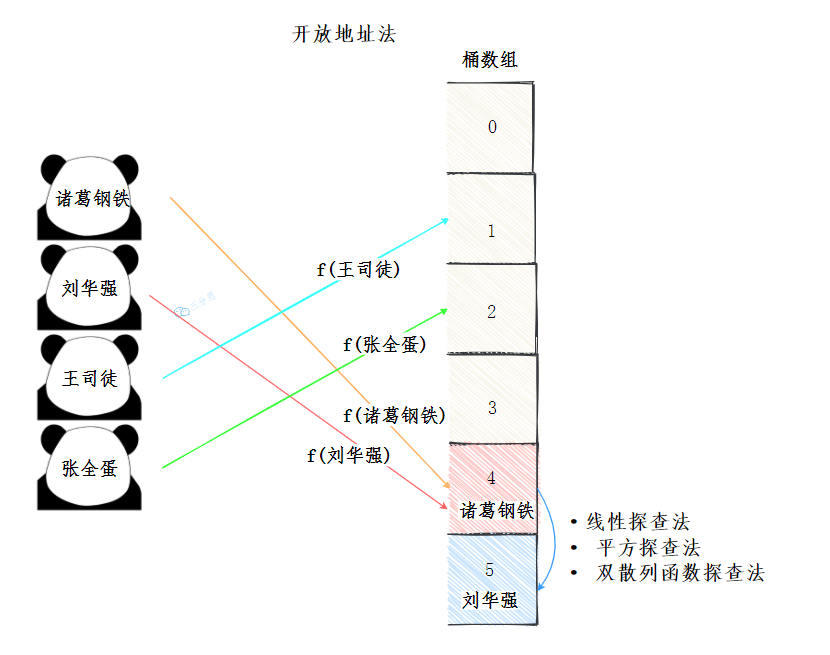
开放地址法
开放地址法,简单来说就是给冲突的元素再在桶数组里找到一个空闲的位置。
找到空闲位置的方法有很多种:
- 线行探查法: 从冲突的位置开始,依次判断下一个位置是否空闲,直至找到空闲位置
- 平方探查法: 从冲突的位置x开始,第一次增加
1^2个位置,第二次增加2^2…,直至找到空闲的位置 - 双散列函数探查法
……
再哈希法
构造多个哈希函数,发生冲突时,更换哈希函数,直至找到空闲位置。
建立公共溢出区
建立公共溢出区,把发生冲突的数据元素存储到公共溢出区。
很明显,接下来我们解决冲突,会使用链地址法。
好了,哈希表的介绍就到这,相信你已经对哈希表的本质有了深刻的理解,接下来,进入coding时间。
HashMap实现
我们实现的简单的HashMap命名为ThirdHashMap,先确定整体的设计:
- 散列函数:hashCode()+除留余数法
- 冲突解决:链地址法
整体结构如下:
内部节点类
我们需要定义一个节点来作为具体数据的载体,它不仅要承载键值对,同样还得作为单链表的节点:
/\*\*
\* 节点类
\*
\* @param <K>
\* @param <V>
\*/
class Node<K, V> {
//键值对
private K key;
private V value;
//链表,后继
private Node<K, V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
成员变量
主要有四个成员变量,其中桶数组作为装载数据元素的结构:
//默认容量
final int DEFAULT_CAPACITY = 16;
//负载因子
final float LOAD_FACTOR = 0.75f;
//HashMap的大小
private int size;
//桶数组
Node<K, V>[] buckets;
构造方法
构造方法有两个,无参构造方法,桶数组默认容量,有参指定桶数组容量。
/\*\*
\* 无参构造器,设置桶数组默认容量
\*/
public ThirdHashMap() {
buckets = new Node[DEFAULT_CAPACITY];
size = 0;
}
/\*\*
\* 有参构造器,指定桶数组容量
\*
\* @param capacity
\*/
public ThirdHashMap(int capacity) {
buckets = new Node[capacity];
size = 0;
}
散列函数
散列函数,就是我们前面说的hashCode()和数组长度取余。
/\*\*
\* 哈希函数,获取地址
\*
\* @param key
\* @return
\*/
private int getIndex(K key, int length) {
//获取hash code
int hashCode = key.hashCode();
//和桶数组长度取余
int index = hashCode % length;
return Math.abs(index);
}
put方法
我用了一个putval方法来完成实际的逻辑,这是因为扩容也会用到这个方法。
大概的逻辑:
- 获取元素插入位置
- 当前位置为空,直接插入
- 位置不为空,发生冲突,遍历链表
- 如果元素key和节点相同,覆盖,否则新建节点插入链表头部
/\*\*
\* put方法
\*
\* @param key
\* @param value
\* @return
\*/
public void put(K key, V value) {
//判断是否需要进行扩容
if (size >= buckets.length \* LOAD_FACTOR) resize();
putVal(key, value, buckets);
}
/\*\*
\* 将元素存入指定的node数组
\*
\* @param key
\* @param value
\* @param table
\*/
private void putVal(K key, V value, Node<K, V>[] table) {
//获取位置
int index = getIndex(key, table.length);
Node node = table[index];
//插入的位置为空
if (node == null) {
table[index] = new Node<>(key, value);
size++;
return;
}
//插入位置不为空,说明发生冲突,使用链地址法,遍历链表
while (node != null) {
//如果key相同,就覆盖掉
if ((node.key.hashCode() == key.hashCode())
&& (node.key == key || node.key.equals(key))) {
node.value = value;
return;
}
node = node.next;
}
//当前key不在链表中,插入链表头部
Node newNode = new Node(key, value, table[index]);
table[index] = newNode;
size++;
}
扩容方法
扩容的大概过程:
- 创建两倍容量的新数组
- 将当前桶数组的元素重新散列到新的数组
- 新数组置为map的桶数组
/\*\*
\* 扩容
\*/
private void resize() {
//创建一个两倍容量的桶数组
Node<K, V>[] newBuckets = new Node[buckets.length \* 2];
//将当前元素重新散列到新的桶数组
rehash(newBuckets);
buckets = newBuckets;
}
/\*\*
\* 重新散列当前元素
\*
\* @param newBuckets
\*/
private void rehash(Node<K, V>[] newBuckets) {
//map大小重新计算
size = 0;
//将旧的桶数组的元素全部刷到新的桶数组里
for (int i = 0; i < buckets.length; i++) {
//为空,跳过
if (buckets[i] == null) {
continue;
}
Node<K, V> node = buckets[i];
while (node != null) {
//将元素放入新数组
putVal(node.key, node.value, newBuckets);
node = node.next;
}
}
}
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









