







doInstallation(context, new File(applicationInfo.sourceDir), new File(applicationInfo.dataDir), “secondary-dexes”, “”, true);
…
Log.i(“MultiDex”, “install done”);
}
}
从入口的判断来看,如果虚拟机本身就支持加载多个dex文件,那就啥都不用做;如果是不支持加载多个dex(5.0以下是不支持的),则走到 doInstallation 方法。
private static void doInstallation(Context mainContext, File sourceApk, File dataDir, String secondaryFolderName, String prefsKeyPrefix, boolean reinstallOnPatchRecoverableException) throws IOException, IllegalArgumentException, IllegalAccessException, NoSuchFieldException, InvocationTargetException, NoSuchMethodException, SecurityException, ClassNotFoundException, InstantiationException {
…
//获取非主dex文件
File dexDir = getDexDir(mainContext, dataDir, secondaryFolderName);
MultiDexExtractor extractor = new MultiDexExtractor(sourceApk, dexDir);
IOException closeException = null;
try {
// 1. 这个load方法,第一次没有缓存,会非常耗时
List files = extractor.load(mainContext, prefsKeyPrefix, false);
try {
//2. 安装dex
installSecondaryDexes(loader, dexDir, files);
}
…
}
}
}
}
先看注释1,MultiDexExtractor#load
List<? extends File> load(Context context, String prefsKeyPrefix, boolean forceReload) throws IOException {
if (!this.cacheLock.isValid()) {
throw new IllegalStateException(“MultiDexExtractor was closed”);
} else {
List files;
if (!forceReload && !isModified(context, this.sourceApk, this.sourceCrc, prefsKeyPrefix)) {
try {
//读缓存的dex
files = this.loadExistingExtractions(context, prefsKeyPrefix);
} catch (IOException var6) {
Log.w(“MultiDex”, “Failed to reload existing extracted secondary dex files, falling back to fresh extraction”, var6);
//读取缓存的dex失败,可能是损坏了,那就重新去解压apk读取,跟else代码块一样
files = this.performExtractions();
//保存标志位到sp,下次进来就走if了,不走else
putStoredApkInfo(context, prefsKeyPrefix, getTimeStamp(this.sourceApk), this.sourceCrc, files);
}
} else {
//没有缓存,解压apk读取
files = this.performExtractions();
//保存dex信息到sp,下次进来就走if了,不走else
putStoredApkInfo(context, prefsKeyPrefix, getTimeStamp(this.sourceApk), this.sourceCrc, files);
}
Log.i(“MultiDex”, “load found " + files.size() + " secondary dex files”);
return files;
}
}
查找dex文件,有两个逻辑,有缓存就调用loadExistingExtractions方法,没有缓存或者缓存读取失败就调用performExtractions方法,然后再缓存起来。使用到缓存,那么performExtractions 方法想必应该是很耗时的,分析一下代码:
private List<MultiDexExtractor.ExtractedDex> performExtractions() throws IOException {
//先确定命名格式
String extractedFilePrefix = this.sourceApk.getName() + “.classes”;
this.clearDexDir();
List<MultiDexExtractor.ExtractedDex> files = new ArrayList();
ZipFile apk = new ZipFile(this.sourceApk); // apk转为zip格式
try {
int secondaryNumber = 2;
//apk已经是改为zip格式了,解压遍历zip文件,里面是dex文件,
//名字有规律,如classes1.dex,class2.dex
for(ZipEntry dexFile = apk.getEntry(“classes” + secondaryNumber + “.dex”); dexFile != null; dexFile = apk.getEntry(“classes” + secondaryNumber + “.dex”)) {
//文件名:xxx.classes1.zip
String fileName = extractedFilePrefix + secondaryNumber + “.zip”;
//创建这个classes1.zip文件
MultiDexExtractor.ExtractedDex extractedFile = new MultiDexExtractor.ExtractedDex(this.dexDir, fileName);
//classes1.zip文件添加到list
files.add(extractedFile);
Log.i(“MultiDex”, "Extraction is needed for file " + extractedFile);
int numAttempts = 0;
boolean isExtractionSuccessful = false;
while(numAttempts < 3 && !isExtractionSuccessful) {
++numAttempts;
//这个方法是将classes1.dex文件写到压缩文件classes1.zip里去,最多重试三次
extract(apk, dexFile, extractedFile, extractedFilePrefix);
…
}
//返回dex的压缩文件列表
return files;
}
这里的逻辑就是解压apk,遍历出里面的dex文件,例如class1.dex,class2.dex,然后又压缩成class1.zip,class2.zip…,然后返回zip文件列表。
思考为什么这里要压缩呢? 后面涉及到ClassLoader加载类原理的时候会分析ClassLoader支持的文件格式。
第一次加载才会执行解压和压缩过程,第二次进来读取sp中保存的dex信息,直接返回file list,所以第一次启动的时候比较耗时。
dex文件列表找到了,回到上面MultiDex#doInstallation方法的注释2,找到的dex文件列表,然后调用installSecondaryDexes方法进行安装,怎么安装呢?方法点进去看SDK 19 以上的实现
private static final class V19 {
private V19() {
}
static void install(ClassLoader loader, List<? extends File> additionalClassPathEntries, File optimizedDirectory) throws IllegalArgumentException, IllegalAccessException, NoSuchFieldException, InvocationTargetException, NoSuchMethodException, IOException {
Field pathListField = MultiDex.findField(loader, “pathList”);//1 反射ClassLoader 的 pathList 字段
Object dexPathList = pathListField.get(loader);
ArrayList suppressedExceptions = new ArrayList();
// 2 扩展数组
MultiDex.expandFieldArray(dexPathList, “dexElements”, makeDexElements(dexPathList, new ArrayList(additionalClassPathEntries), optimizedDirectory, suppressedExceptions));
…
}
private static Object[] makeDexElements(Object dexPathList, ArrayList files, File optimizedDirectory, ArrayList suppressedExceptions) throws IllegalAccessException, InvocationTargetException, NoSuchMethodException {
Method makeDexElements = MultiDex.findMethod(dexPathList, “makeDexElements”, ArrayList.class, File.class, ArrayList.class);
return (Object[])((Object[])makeDexElements.invoke(dexPathList, files, optimizedDirectory, suppressedExceptions));
}
}
-
反射ClassLoader 的 pathList 字段
-
找到pathList 字段对应的类的
makeDexElements方法 -
通过
MultiDex.expandFieldArray这个方法扩展dexElements数组,怎么扩展?看下代码:
private static void expandFieldArray(Object instance, String fieldName, Object[] extraElements) throws NoSuchFieldException, IllegalArgumentException, IllegalAccessException {
Field jlrField = findField(instance, fieldName);
Object[] original = (Object[])((Object[])jlrField.get(instance)); //取出原来的dexElements 数组
Object[] combined = (Object[])((Object[])Array.newInstance(original.getClass().getComponentType(), original.length + extraElements.length)); //新的数组
System.arraycopy(original, 0, combined, 0, original.length); //原来数组内容拷贝到新的数组
System.arraycopy(extraElements, 0, combined, original.length, extraElements.length); //dex2、dex3…拷贝到新的数组
jlrField.set(instance, combined); //将dexElements 重新赋值为新的数组
}
就是创建一个新的数组,把原来数组内容(主dex)和要增加的内容(dex2、dex3…)拷贝进去,反射替换原来的dexElements为新的数组,如下图
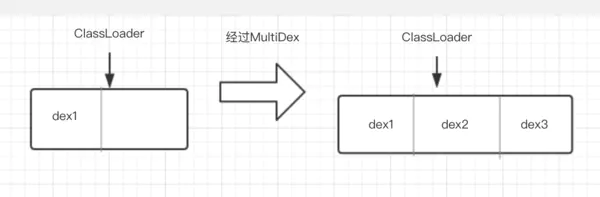
看起来有点眼熟,Tinker热修复的原理也是通过反射将修复后的dex添加到这个dex数组去,不同的是热修复是添加到数组最前面,而MultiDex是添加到数组后面。这样讲可能还不是很好理解?来看看ClassLoader怎么加载一个类的就明白了~
2.2.4 ClassLoader 加载类原理
不管是 PathClassLoader还是DexClassLoader,都继承自BaseDexClassLoader,加载类的代码在 BaseDexClassLoader中
4.4 源码
/dalvik/src/main/java/dalvik/system/BaseDexClassLoader.java
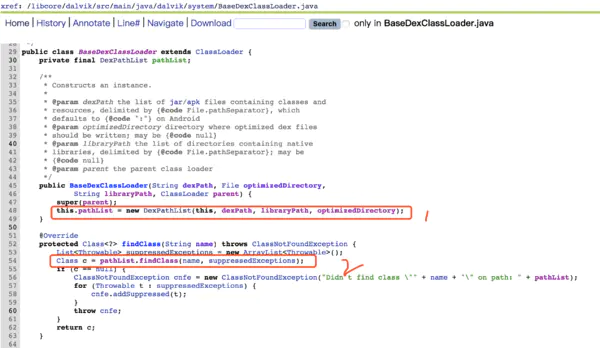
-
构造方法通过传入dex路径,创建了
DexPathList。 -
ClassLoader的findClass方法最终是调用DexPathList 的findClass方法
接着看DexPathList源码 /dalvik/src/main/java/dalvik/system/DexPathList.java

DexPathList里面定义了一个dexElements 数组,findClass方法中用到,看下
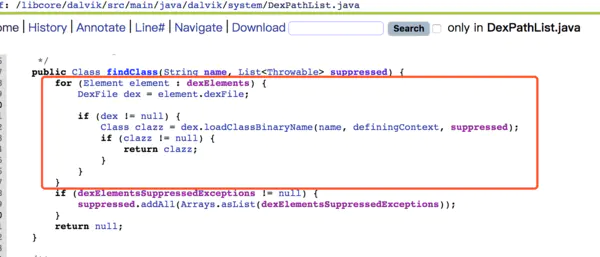
findClass方法逻辑很简单,就是遍历dexElements 数组,拿到里面的DexFile对象,通过DexFile的loadClassBinaryName方法加载一个类。
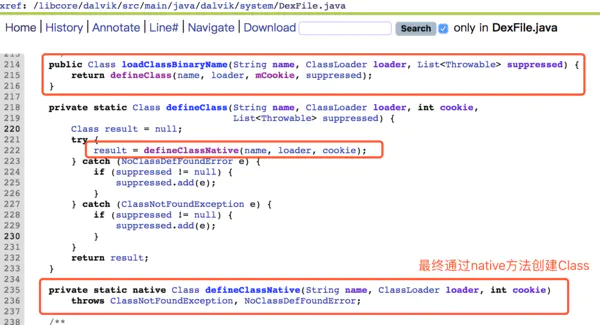
最终创建Class是通过native方法,就不追下去了,大家有兴趣可以看下native层是怎么创建Class对象的。DexFile.cpp
那么问题来了,5.0以下这个dexElements 里面只有主dex(可以认为是一个bug),没有dex2、dex3…,MultiDex是怎么把dex2添加进去呢? 答案就是反射DexPathList的dexElements字段,然后把我们的dex2添加进去,当然,dexElements里面放的是Element对象,我们只有dex2的路径,必须转换成Element格式才行,所以反射DexPathList里面的makeDexElements 方法,将dex文件转换成Element对象即可。

dex2、dex3…通过makeDexElements方法转换成要新增的Element数组,最后一步就是反射DexPathList的dexElements字段,将原来的Element数组和新增的Element数组合并,然后反射赋值给dexElements变量,最后DexPathList的dexElements变量就包含我们新加的dex在里面了。
makeDexElements方法会判断file类型,上面讲dex提取的时候解压apk得到dex,然后又将dex压缩成zip,压缩成zip,就会走到第二个判断里去。仔细想想,其实dex不压缩成zip,走第一个判断也没啥问题吧,那谷歌的MultiDex为什么要将dex压缩成zip呢?在Android开发高手课中看到张绍文也提到这一点

然后我在反编译头条App的时候,发现头条参考谷歌的MultiDex,自己写了一套,猜想可能是优化这个多余的压缩过程,头条的方案下面会介绍。
2.2.5 原理小结
ClassLoader 加载类原理:
ClassLoader.loadClass -> DexPathList.loadClass -> 遍历dexElements数组 ->DexFile.loadClassBinaryName
通俗点说就是:ClassLoader加载类的时候是通过遍历dex数组,从dex文件里面去加载一个类,加载成功就返回,加载失败则抛出Class Not Found 异常。
MultiDex原理:
在明白ClassLoader加载类原理之后,我们可以通过反射dexElements数组,将新增的dex添加到数组后面,这样就保证ClassLoader加载类的时候可以从新增的dex中加载到目标类,经过分析后最终MultipDex原理图如下:
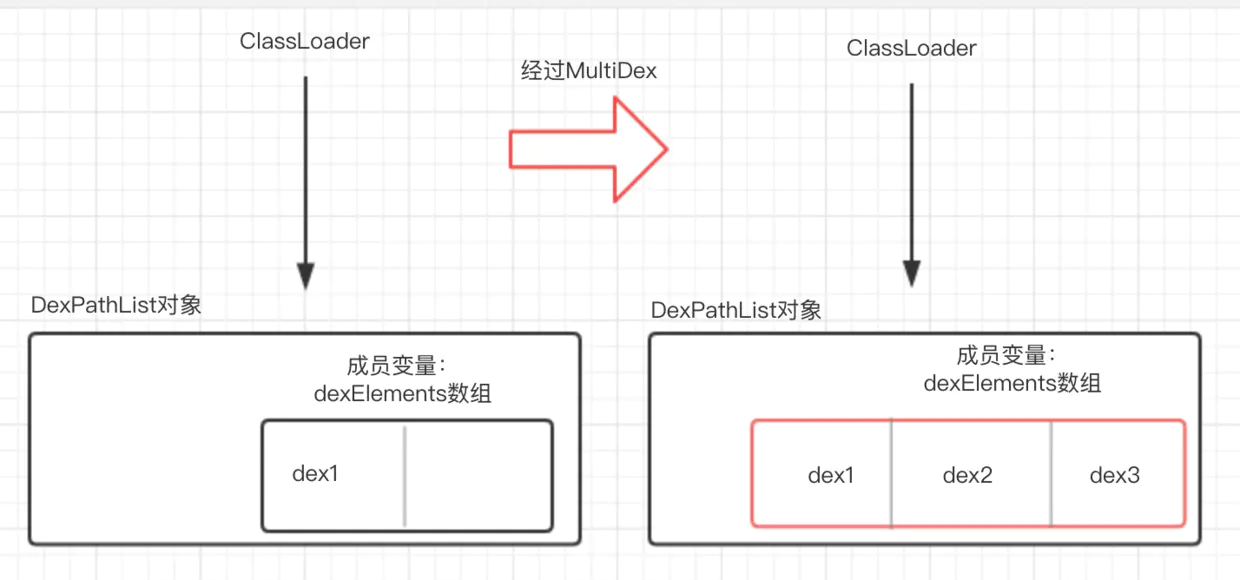
2.2.6 MultiDex 优化(两种方案)
知道了MultiDex原理之后,可以理解install过程为什么耗时,因为涉及到解压apk取出dex、压缩dex、将dex文件通过反射转换成DexFile对象、反射替换数组。
那么MultiDex到底应该怎么优化呢,放子线程可行吗?
方案1:子线程install(不推荐)
这个方法大家很容易就能想到,在闪屏页开一个子线程去执行MultiDex.install,然后加载完才跳转到主页。需要注意的是闪屏页的Activity,包括闪屏页中引用到的其它类必须在主dex中,不然在MultiDex.install之前加载这些不在主dex中的类会报错Class Not Found。这个可以通过gradle配置,如下:
defaultConfig {
//分包,指定某个类在main dex
multiDexEnabled true
multiDexKeepProguard file(‘multiDexKeep.pro’) // 打包到main dex的这些类的混淆规制,没特殊需求就给个空文件
multiDexKeepFile file(‘maindexlist.txt’) // 指定哪些类要放到main dex
}
maindexlist.txt 文件指定哪些类要打包到主dex中,内容格式如下
com/lanshifu/launchtest/SplashActivity.class
在已有项目中用这种方式,一顿操作猛如虎之后,编译运行在4.4的机器上,启动闪屏页,加载完准备进入主页直接崩掉了。

报错NoClassDefFoundError,一般都是该类没有在主dex中,要在maindexlist.txt 将配置指定在主dex。 **第三方库中的ContentProvider必须指定在主dex中,否则也会找不到,为什么?**文章开头说过应用的启动流程,ContentProvider 初始化时机如下图:
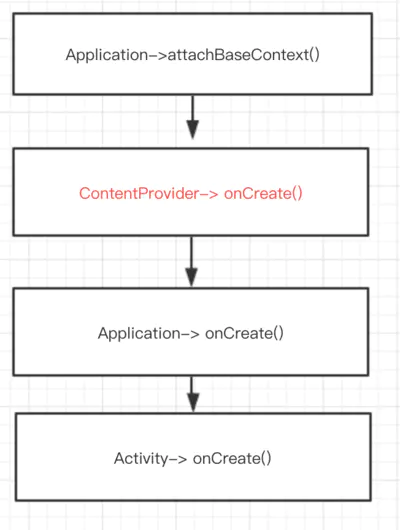
ContentProvider初始化太早了,如果不在主dex中,还没启动闪屏页就已经crash了。
所以这种方案的缺点很明显:
- MultiDex加载逻辑放在闪屏页的话,闪屏页中引用到的类都要配置在主dex。
- ContentProvider必须在主dex,一些第三方库自带ContentProvider,维护比较麻烦,要一个一个配置。
这时候就思考一下,有没有其它更好的方案呢?大厂是怎么做的?今日头条肯定要对MultiDex进行优化吧,反编译瞧瞧?

点了一根烟之后,开始偷代码…
MultiDex优化方案2:今日头条方案
今日头条没有加固,反编译后很容易通过关键字搜索找到MultidexApplication这个类,
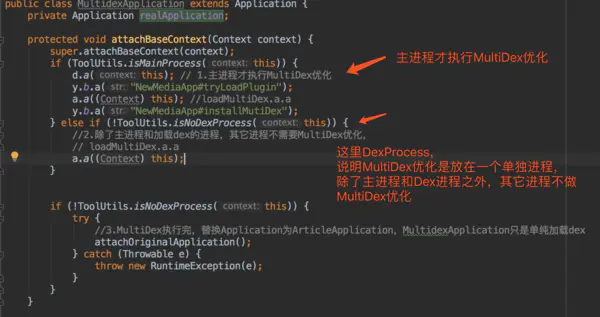
看注释1的d.a(this);这个方法,代码虽然混淆了,但是方法内部的代码还是可以看出是干嘛的,继续跟这个方法,为了不影响阅读,我对混淆做了一些处理,改成正常的方法名。
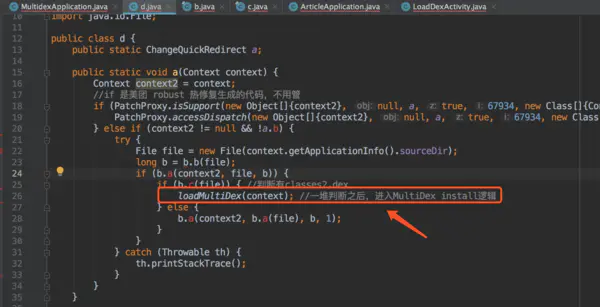
每个方法开头都有PatchProxy.isSupport这个if判断,这个是美团Robust热修复生成的代码,今日头条没有自己的热修复框架,没有用Tinker,而是用美团的,想了解关于Robust细节可以参考文末链接。Robust直接跳过,看else代码块即可。
继续看loadMultiDex方法
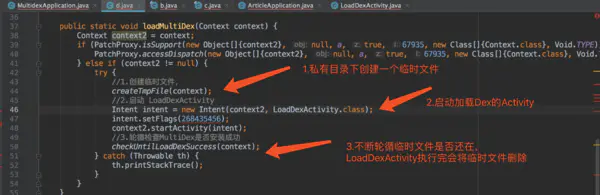
逻辑如下:
1. 创建临时文件,作为判断MultiDex是否加载完的条件
2. 启动LoadDexActivity去加载MultiDex(LoadDexActivity在单独进程),加载完会删除临时文件
3. 开启while循环,直到临时文件不存在才跳出循环,进入Application的onCreate
创建临时文件代码
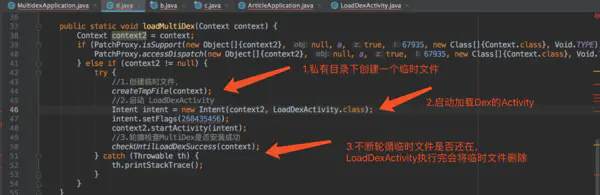
while循环代码
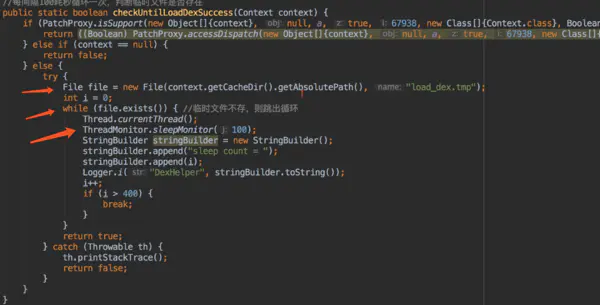
LoadDexActivity 只有一个加载框,加载完再跳转到闪屏页
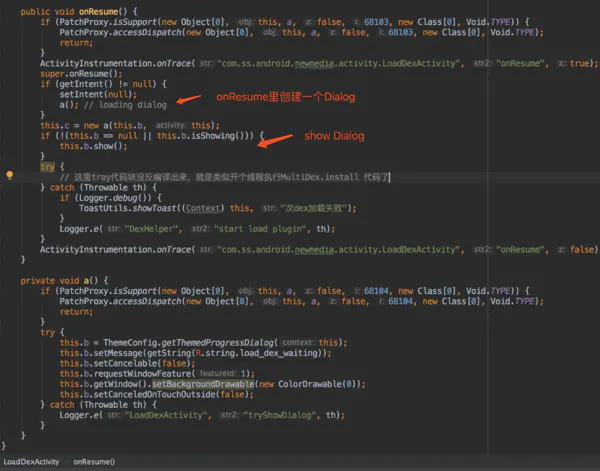
dex加载完应该要finish掉当前Activity
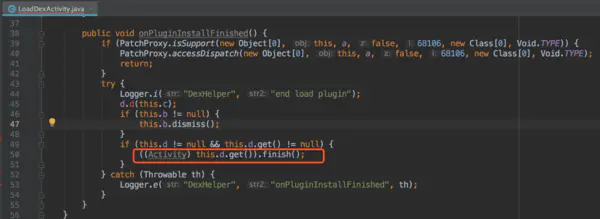
按照上面代码分析,今日头条在5.0以下手机首次启动应该是这样:
-
打开桌面图标
-
显示默认背景
-
跳转到加载dex的界面,展示一个loading的加载框几秒钟
-
跳转到闪屏页
实际上是不是这样呢,用4.4机器试下?
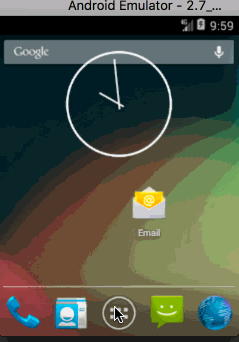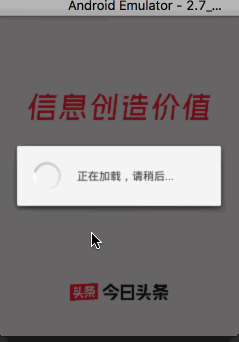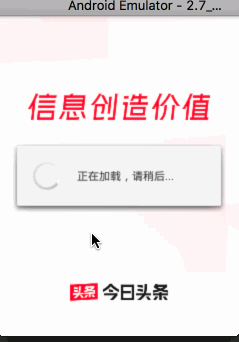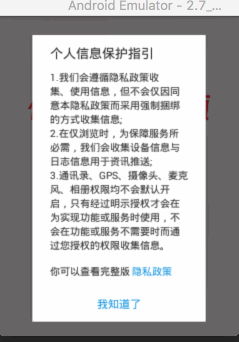
看起来完全跟猜想的一致,撸几行代码验证应该不难吧?

点了一根烟之后,开始撸代码,最终实现效果如下

效果跟今日头条是一致的,不再重复分析代码了,源码上传到github,感兴趣的同学可以参考参考,头条的方案,值得尝试~ github.com/lanshifu/Mu…
再次梳理一下这种方式:
-
在主进程Application 的 attachBaseContext 方法中判断如果需要使用MultiDex,则创建一个临时文件,然后开一个进程(LoadDexActivity),显示Loading,异步执行MultiDex.install 逻辑,执行完就删除临时文件并finish自己。
-
主进程Application 的 attachBaseContext 进入while代码块,定时轮循临时文件是否被删除,如果被删除,说明MultiDex已经执行完,则跳出循环,继续正常的应用启动流程。
-
注意LoadDexActivity 必须要配置在main dex中。
有些同学可能会问,启动还是很久啊,冷启动时间有变化吗? 冷启动时间是指点击桌面图标到第一个Activity显示这段时间。
MultiDex优化总结
方案1:直接在闪屏页开个子线程去执行MultiDex逻辑,MultiDex不影响冷启动速度,但是难维护。
方案2:今日头条的MultiDex优化方案:
-
在Application 的attachBaseContext 方法里,启动另一个进程的LoadDexActivity去异步执行MultiDex逻辑,显示Loading。
-
然后主进程Application进入while循环,不断检测MultiDex操作是否完成
-
MultiDex执行完之后主进程Application继续走,ContentProvider初始化和Application onCreate方法,也就是执行主进程正常的逻辑。
其实应该还有方案3,因为我发现头条并没有直接使用Google的MultiDex,而是参考谷歌的MultiDex,自己写了一套,耗时应该会少一些,大家有兴趣可以去研究一下。
2.3 预创建Activity
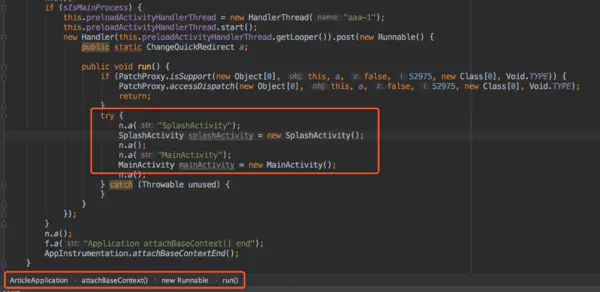
这段代码是今日头条里面的,Activity对象预先new出来,
对象第一次创建的时候,java虚拟机首先检查类对应的Class 对象是否已经加载。如果没有加载,jvm会根据类名查找.class文件,将其Class对象载入。同一个类第二次new的时候就不需要加载类对象,而是直接实例化,创建时间就缩短了。
头条真是把启动优化做到极致。
2.4 第三方库懒加载
很多第三方开源库都说在Application中进行初始化,十几个开源库都放在Application中,肯定对冷启动会有影响,所以可以考虑按需初始化,例如Glide,可以放在自己封装的图片加载类中,调用到再初始化,其它库也是同理,让Application变得更轻。
2.5 WebView启动优化。
WebView启动优化文章也比较多,这里只说一下大概优化思路。
-
WebView第一次创建比较耗时,可以预先创建WebView,提前将其内核初始化。
-
使用WebView缓存池,用到WebView的地方都从缓存池取,缓存池中没有缓存再创建,注意内存泄漏问题。
-
本地预置html和css,WebView创建的时候先预加载本地html,之后通过js脚本填充内容部分。
这一部分可以参考: mp.weixin.qq.com/s/KwvWURD5W…
2.6 数据预加载
这种方式一般是在主页空闲的时候,将其它页面的数据加载好,保存到内存或数据库,等到打开该页面的时候,判断已经预加载过,直接从内存或数据库读取数据并显示。
2.7 线程优化
线程是程序运行的基本单位,线程的频繁创建是耗性能的,所以大家应该都会用线程池。单个cpu情况下,即使是开多个线程,同时也只有一个线程可以工作,所以线程池的大小要根据cpu个数来确定。
启动优化方式就先介绍到这里,常见的就是这些,其它的可以作为补充。
TraceView性能损耗太大,得到的结果不真实。 Systrace 可以方便追踪关键系统调用的耗时情况,如 Choreographer,但是不支持应用程序代码的耗时分析。
3.1 Systrace + 函数插桩
结合Systrace 和 函数插桩,就是将如下代码插入到每个方法的入口和出口
class Trace{
public static void i(String tag){
android.os.Trace.beginSection(tag);
}
public static void o(){
android.os.Trace.endSection();
}
}
插桩后的代码如下
void test(){
Trace.i(“test”);
System.out.println(“doSomething”);
Trace.o();
}
插桩工具参考: github.com/AndroidAdva…
mac下systrace路径在
/Users/{xxx}/Library/Android/sdk/platform-tools/systrace/
编译运行app,执行命令
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)

最后
答应大伙的备战金三银四,大厂面试真题来啦!
这份资料我从春招开始,就会将各博客、论坛。网站上等优质的Android开发中高级面试题收集起来,然后全网寻找最优的解答方案。每一道面试题都是百分百的大厂面经真题+最优解答。包知识脉络 + 诸多细节。
节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
《960全网最全Android开发笔记》

《379页Android开发面试宝典》
包含了腾讯、百度、小米、阿里、乐视、美团、58、猎豹、360、新浪、搜狐等一线互联网公司面试被问到的题目。熟悉本文中列出的知识点会大大增加通过前两轮技术面试的几率。
如何使用它?
1.可以通过目录索引直接翻看需要的知识点,查漏补缺。
2.五角星数表示面试问到的频率,代表重要推荐指数

《507页Android开发相关源码解析》
只要是程序员,不管是Java还是Android,如果不去阅读源码,只看API文档,那就只是停留于皮毛,这对我们知识体系的建立和完备以及实战技术的提升都是不利的。
真正最能锻炼能力的便是直接去阅读源码,不仅限于阅读各大系统源码,还包括各种优秀的开源库。

腾讯、字节跳动、阿里、百度等BAT大厂 2020-2021面试真题解析

资料收集不易,如果大家喜欢这篇文章,或者对你有帮助不妨多多点赞转发关注哦。文章会持续更新的。绝对干货!!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
经真题+最优解答。包知识脉络 + 诸多细节。
节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
《960全网最全Android开发笔记》
[外链图片转存中…(img-AM3csLyj-1713581097389)]
《379页Android开发面试宝典》
包含了腾讯、百度、小米、阿里、乐视、美团、58、猎豹、360、新浪、搜狐等一线互联网公司面试被问到的题目。熟悉本文中列出的知识点会大大增加通过前两轮技术面试的几率。
如何使用它?
1.可以通过目录索引直接翻看需要的知识点,查漏补缺。
2.五角星数表示面试问到的频率,代表重要推荐指数
[外链图片转存中…(img-enkovRab-1713581097389)]
《507页Android开发相关源码解析》
只要是程序员,不管是Java还是Android,如果不去阅读源码,只看API文档,那就只是停留于皮毛,这对我们知识体系的建立和完备以及实战技术的提升都是不利的。
真正最能锻炼能力的便是直接去阅读源码,不仅限于阅读各大系统源码,还包括各种优秀的开源库。
[外链图片转存中…(img-zWJRkCzd-1713581097390)]
腾讯、字节跳动、阿里、百度等BAT大厂 2020-2021面试真题解析
[外链图片转存中…(img-clb8tMoj-1713581097391)]
资料收集不易,如果大家喜欢这篇文章,或者对你有帮助不妨多多点赞转发关注哦。文章会持续更新的。绝对干货!!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!














 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









