







收集整理了一份《2024年最新Python全套学习资料》免费送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

正文
我们就不提 Python 安装调试中文版之类的麻烦事了,这些也不爽,但不辞辛苦倒还能对付。这里只说它的语言语法,这可不是多费力气就能解决的事了。
日常职场业务主要是处理表格类数据(用专业的说法是结构化数据),比如这样的:
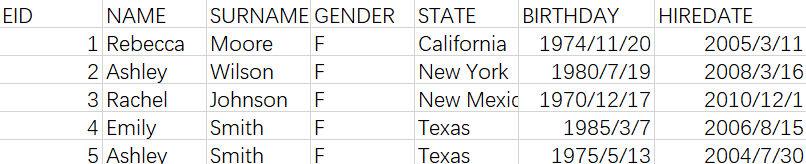
表里除第一行外的每行数据称为一条记录,对应了一件事、一个人、一张订单……,第一行是标题,说明记录由哪些属性构成,这些记录都有相同的属性,整个表就是这样一些记录的集合。
Python 主要是用一个叫 DataFrame 的东西来处理这类表格数据,我们来看看DataFrame是怎么做的。
比如上面的表格,读入 DataFrame 后是这样的:
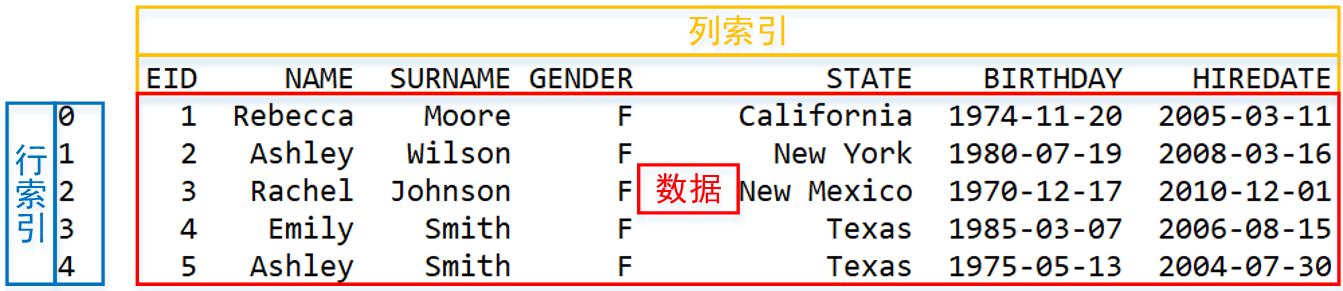
看起来和 Excel 差不多,只是行号是从 0 开始的。
但是,DataFrame 的本质是一个矩阵(大学时代的线性代数还想得起来吗?),Python也没有记录这样的概念,它的运算都要绕到矩阵可以执行的方法上才行。
我们来看一些简单运算。
过滤是个简单常见的运算,就是把满足某一条件的子集取出来,比如还是上面的表格:

问题一:取出 R&D 部门的员工。
Python 代码是这样的:
import pandas as pd # 导入 Pandas
data = pd.read_csv(‘Employees.csv’) # 读取数据
rd = data.loc[data[‘DEPT’]==‘R&D’] # 过滤 R&D 部门
print(rd) # 查看 rd 数据
运行结果:

代码很简单,结果也没问题。但是:
1.用到的函数叫 loc,是 location(定位)的缩写,完全没有过滤的意思。事实上,这里的过滤也是通过定位(location)满足条件的行的索引来实现的,函数里面的data['DEPT]=='R&D'会算出一个布尔值构成的 Series:

和 data 的索引相同,满足条件的行为 True 否则为 False
然后 loc 就是根据取值为 True 的行对应的索引再取出 data 中相应的行再得到一个新的 DataFrame,本质上是从矩阵中抽取指定行的运算,用来对付过滤就有点绕。
2.过滤 DataFrame 并不只可以使用 loc 函数过滤,还可以用 query(…) 等方法,但结果都是定位到矩阵的行列索引,然后按行列索引取数据,大体上是这样的 matrix.loc[row,col]
无论如何,基本的过滤还算简单吧,讲明白了也能理解。下面我们再尝试对过滤后的子集做两个算不上复杂的运算看看。
修改子集中的数据
问题二:将 R&D 部门员工的工资上调 5%
自然的想法,只要过滤出 R&D 部门员工,然后对这些员工的工资进行修改就可以了。
按照这种逻辑写出代码:
import pandas as pd #导入 Pandas
data = pd.read_csv(‘Employees.csv’) #读取数据
rd = data.loc[data[‘DEPT’]==‘R&D’] #过滤 R&D 部门
rd[‘SALARY’]=rd[‘SALARY’]*1.05 #修改 SALARY
print(data)
运行结果:
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation:
http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
rd[‘SALARY’]=rd[‘SALARY’]*1.05

可以看到,不仅触发了警告,修改值也没有成功。
这是因为rd = data.loc[data['DEPT']=='R&D']是一个过滤后的矩阵,再使用rd['SALARY']=rd['SALARY']*1.05这个语句修改SALARY值的时候,rd['SALARY']
又是一个新的矩阵了,因此修改它其实是修改的rd这个子矩阵,并没有修改data这个最初的矩阵。
这话说着很绕,听着也绕。
正确的代码怎么写呢?
import pandas as pd
data = pd.read_csv(‘Employees.csv’)
rd_salary = data.loc[data[‘DEPT’]==‘R&D’,‘SALARY’]
#找到 R&D 部门的员工工资
data.loc[data[‘DEPT’]==‘R&D’,‘SALARY’] = rd_salary*1.05
#截取 R&D 部门的员工工资并修改
print(data)
运行结果:

这次对了。不可以先取出子集再修改,要对着原矩阵,找到要修改的成员的定位再来修改,即loc[row=data['DEPT']=='R&D',column='SALARY'],按照行列索引取到要修改的数据,对着这个矩阵赋值。想要上调5%还要在此之前先拿到这份数据(rd_salary=…这句)。这种写法要进行重复的过滤,效率低也就罢了,但实在是太绕了。
子集求交
问题三:找出既是纽约州又是 R&D 部门的员工
这个问题更简单,只要算出两个子集做个交集运算就完了。我们看看Python是如何处理的:
import pandas as pd
data = pd.read_csv(‘Employees.csv’)
rd = data[data[‘DEPT’]==‘R&D’] #R&D部门员工
ny = data[data[‘STATE’]==‘New York’] #纽约州员工
isect_idx = rd.index.intersection(ny.index) #索引求交集
rd_isect_ny = data.loc[isect_idx] #按索引交集截取数据
print(rd_isect_ny)
运行结果:

集合求交是非常基本的运算,很多程序语言都提供了,事实上python也提供了(上面有intersection函数)。然而, DataFrame的本质是矩阵,两个矩阵求交集却没有什么意义,Python 也就没有提供矩阵求交集的运算。想要做到用两个dataframe表示的集合的交集运算,只能绕道去求两个矩阵索引的交集,最后再利用索引的交集从原数据上定位截取,有种舍近求远的感觉,不按“套路”出牌。
工作中最常用的过滤运算都这么令人费解,绕的脑袋晕,可以想象其他更复杂的运算,一股酸爽的感觉“悠然而生”。
下面看下稍微复杂一点的分组运算:
分组运算是日常数据处理中最常用的运算了,Python也提供了丰富的分组运算函数,能够完成大多数的分组运算,但在理解和使用上并没有那么容易。
分组理解
分组就是把一个大集合按某种规则分成一些小集合,结果是个由集合构成的集合,然后再对分组后的集合进行运算,如下图:
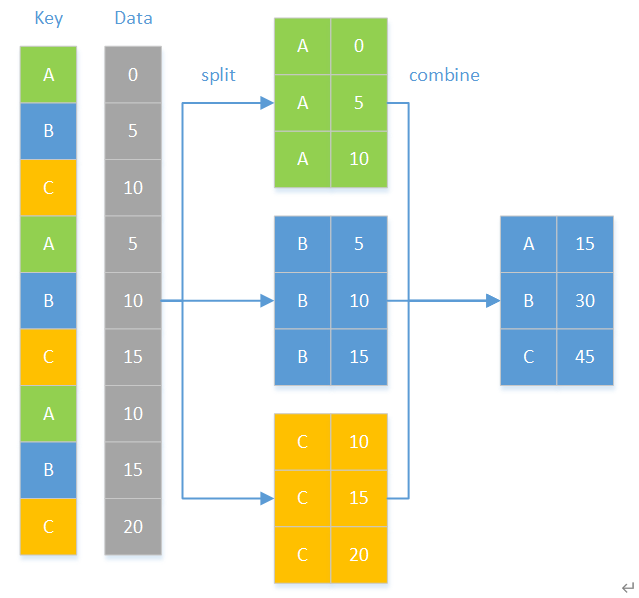
先来看下最常用的分组聚合运算。
问题四:汇总各部门的人数
Python 代码:
import pandas as pd
data = pd.read_csv(‘Employees.csv’)
group = data.groupby(“DEPT”) #按照部门分组
dept_num = group.count() #汇总各部门人数
print(dept_num)
运行结果:
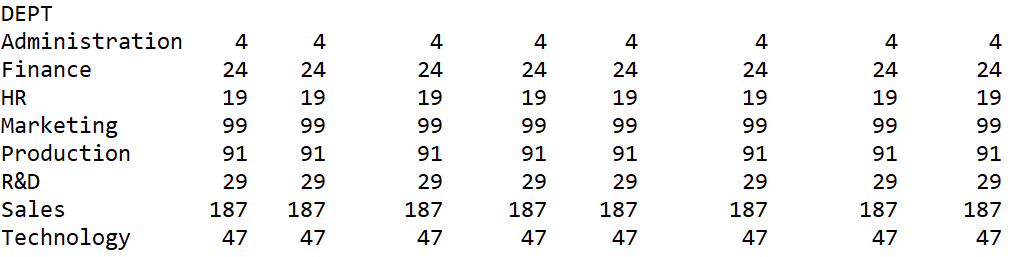
结果好像有点尴尬,本来只需要记录每个分组中的成员数量,只要有一列就行了,为什么出来这么多列,它像是对每一列都重复做了同样的动作,好奇怪。
别急,这个问题 Python 还是可以解决的,只不过不是用 count 函数,而是 size 函数:
import pandas as pd
data = pd.read_csv(‘Employees.csv’)
group = data.groupby(“DEPT”) #按照部门分组
dept_num = group.size() #汇总各部门人数
print(dept_num)
运行结果:
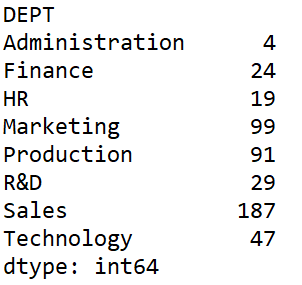
这个结果看起来就正常多了,不过,还是感觉哪里怪怪的。
是滴,这个结果不再是二维的 DataFrame 了,而是个单维的 Seriese。
count 函数计算的结果之所以奇怪,是因为它是对每一列计数,而 size 函数是查看各组的大小,但其实我们自然的逻辑还是用 count 来计数,size 很难用自然的逻辑想到(还要上网搜资料)。
如前所述,分组结果应该是集合的集合,我们看看 Python 中的 DataFrame 分组后是什么样子呢?把上面代码中data.groupby(“DEPT”)的结果打印出来看。
import pandas as pd
data = pd.read_csv(‘Employees.csv’)
group = data.groupby(“DEPT”) #按照部门分组
print(group)
运行结果:
“pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001ADBC9CE0F0”
哇,这是个什么东东?
第一次看到这个东西,直接就蒙圈了,分组的结果不应该是集合的集合吗,为什么会是这样?这对于非专业程序人员来说简直如同梦魇。
不过上网搜搜还是可以看到它是一个所谓的可迭代对象,迭代以后发现它的每一条都是以分组索引+ DataFrame 构成的,可以使用一些方法看到里边的内容,如使用 list(group)就可以看到分组的结果了。如下图:
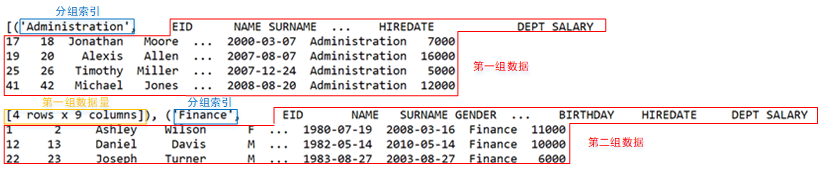
看到上图以后就会明白,被称为“对象”的东西里面原来是这样的。本质上它也确实是个集合的集合(姑且把矩阵理解成集合吧),但它并不能像普通的集合那样直接取某个成员 (如 group[0]),这在使用上迫使用户强行记忆这类“对象”的 N 种运算规则,理解不了就只能死记硬背了。
看到这里,估计已经有很多读者开始晕菜了,彻底不明白上面这段话是在胡说八道些什么。嗯,这就对了,因为这才是职场人员的正常状态。
分组中简单的聚合运算都如此难以理解,我们再烧烧脑,看下稍微复杂一点的分组后子集合的运算。
分组子集处理
虽然分组后经常用于聚合运算,但有时我们并不关心聚合结果,而是关心分组后的集合本身。比如分组后的集合按某一列排序。
问题五:将各部门员工按照入职时间从早到晚进行排序 。
问题分析:分组后对子集按照入职时间排序即可。
Python 代码
import pandas as pd
employee = pd.read_csv(“Employees.csv”)
employee[‘HIREDATE’]=pd.to_datetime(employee[‘HIREDATE’])
#修改入职时间格式
employee_new = employee.groupby(‘DEPT’,as_index=False).apply(lambda x:x.sort_values(‘HIREDATE’)).reset_index(drop=True)
#按 DEPT 分组,并对各组按照 HIREDATE 排序,最后重置索引
print(employee_new)
运行结果:
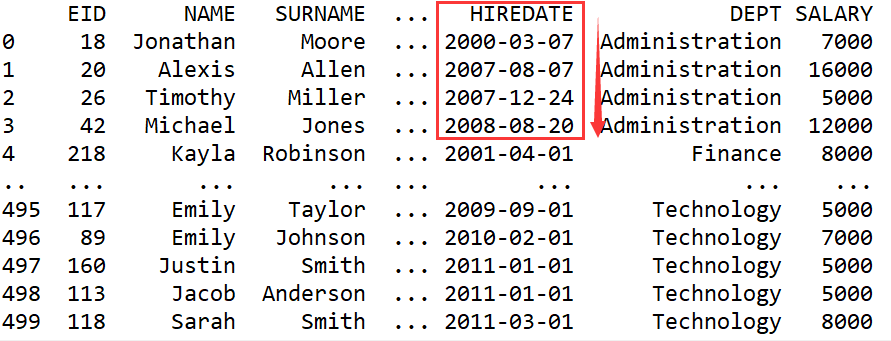
结果没问题,各个部门员工都按照入职时间从早到晚排序了。但我们观察下代码中最核心的一句employee.groupby('DEPT',as_index=False).apply(lambda x:x.sort_values('HIREDATE')),把这句代码抽象一下就是这样:
df.groupby©.apply(lambda x:f(x))
df:数据框 DataFrame
groupby:分组函数
c:分组依据的列
以上三个还是比较好理解的,可是 apply 配合 lambda 就十分晦涩难懂了,超出了大多数非专业程序人员理解的范畴,这需要明白所谓“函数语言”的原理才能搞懂(自己去搜索,俺懒得解释了)。
如果不使用这“二位”(apply+lambda)呢?也能做,就是会很麻烦。得用 for 循环,对每个分组子集分别排序,最后还得把结果合并起来。
import pandas as pd
employee = pd.read_csv(“Employees.csv”)
employee[‘HIREDATE’]=pd.to_datetime(employee[‘HIREDATE’]) #修改入职时间格式
dept_g = employee.groupby(‘DEPT’,as_index=False) #按 DEPT 分组
dept_list = [] #初始化列表
for index,group in dept_g: #for循环
group = group.sort_values(‘HIREDATE’) #每个分组排序
dept_list.append(group) #排序结果放入列表
employee_new = pd.concat(dept_list,ignore_index=True) #合并各组结果
print(employee_new)
运行结果相同,但代码复杂了很多,而且运行效率也变低了。你愿意用哪一种呢?
Python 对于类似但不完全一样的数据设计了不同的数据类型,也对应有不同的操作方式,并不能简单地把对某种数据的知识复制到另一个类似数据上,搞得人晕死。
说了这么多,总结下来就是一句话:Python 真的挺难懂的,它就不是一个面向非专业选手的东西。具体来说大概就是三点:
1.DataFrame 本质是矩阵
所有的运算都要想办法按矩阵的方法来计算,经常会很绕。
2.数据类型多而且运算规则差别很大
Python 中设计了 Series,DataFrame,分组对象等等不同的数据类型,而且不同的数据类型,计算方法也不完全相同,如DataFrame可以使用query函数过滤,而 Series 不可以,分组对象的本质完全不同于 Series 和 DataFrame,计算方法更是难以捉摸。
3.知其然而不知其所以然
数据类型过多,计算方法差别又大,无形之中增加了用户的记忆量,死记硬背的成分更多,想要灵活运用太难了,这就造成了一种奇怪的现象:一个简单的运算,上网搜索 Python 代码的时间可能比用 excel 计算还要长。
Python 代码看起来简单,但你上了培训班也大概率学不会,结果只会抄例子。
那么,是不是就没有适合职场人员进行日常数据处理的工具了吗?
还是有的。
集算器 SPL 也是一种程序设计语言,专注于结构化数据计算。SPL 中提供了丰富的基础计算方法,其概念逻辑也是符合我们的思维习惯的。
1.序表是记录的集合
SPL 使用序表承载结构化数据,接近于日常处理的 excel 表。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)
[外链图片转存中…(img-cbIlZEdi-1713790627885)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









