







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
然后程序在该文件夹下生成一个名为"微博名字"的文件夹,明星的所有微博爬取结果都在这里。文件夹里包含一个csv文件、一个txt文件、一个json文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见设置数据库部分。
02
Python爬虫教程
Python爬虫教程系列、从 0 到 1 学习 Python 爬虫,包括浏览器抓包,手机 APP 抓包,如 fiddler、mitmproxy,各种爬虫涉及的模块的使用,如:requests、beautifulSoup、selenium、appium、scrapy 等,以及验证码识别,MySQL,MongoDB 数据库的 Python 使用,多线程多进程爬虫的使用,css 爬虫加密逆向破解,JS爬虫逆向,分布式爬虫,爬虫项目实战实例等。
地址:https://github.com/wistbean/learn_python3_spider

03
爬虫集合
这个开源项目收集了各种爬虫 ,包括 Blibli、博客园、百度百科、北邮人、百度云网盘、Boss、贝壳、豆瓣、CSDN、抖音、GitHub、京东、知乎、拉钩、链家、微信公众号、网易云等等,你能想到的国内外网站爬虫,都可以先来这里看看有没有开源的爬虫。
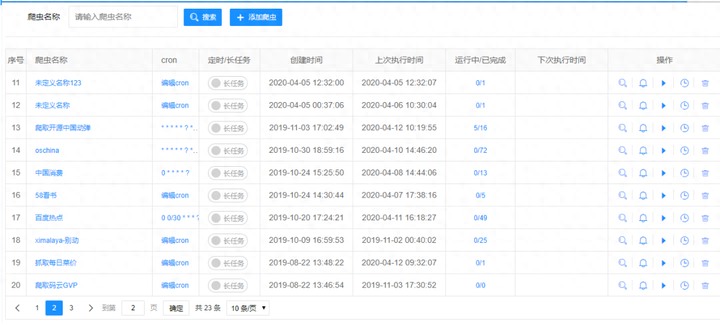
接下来以流程图的方式,开始配置一些变量和参数,点开始就能爬出你想要的数据。
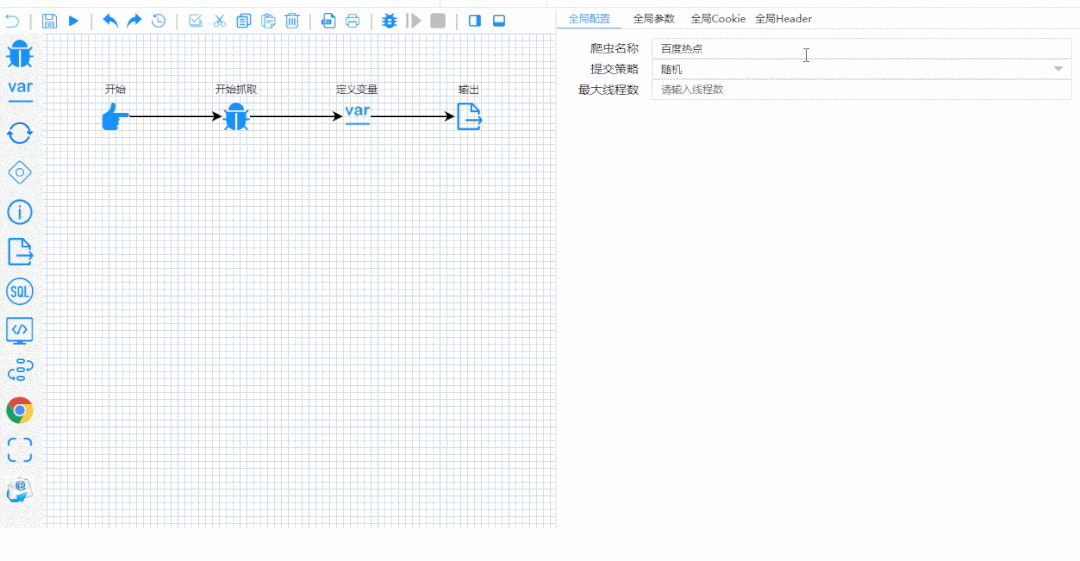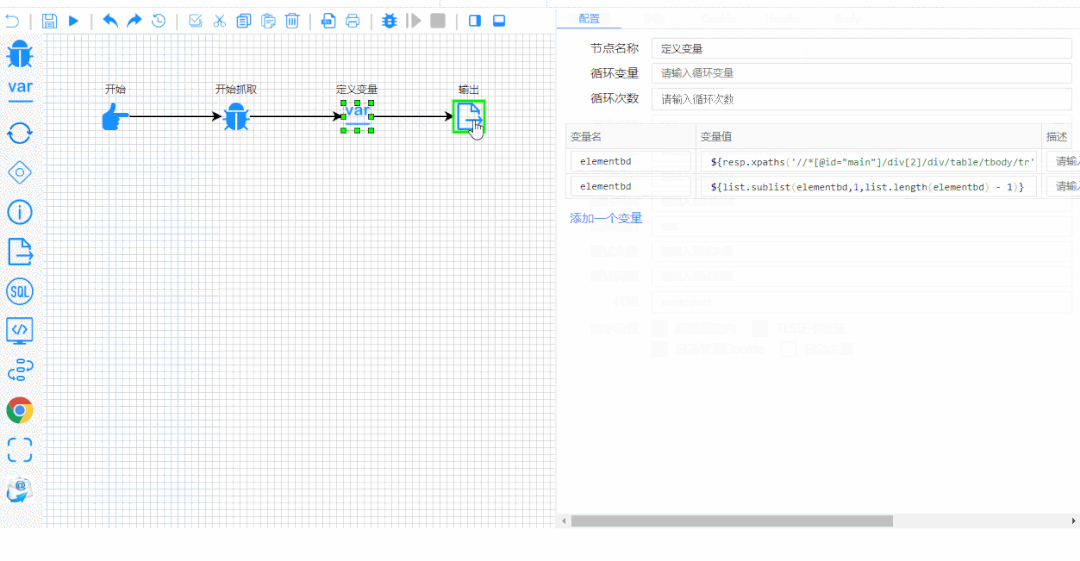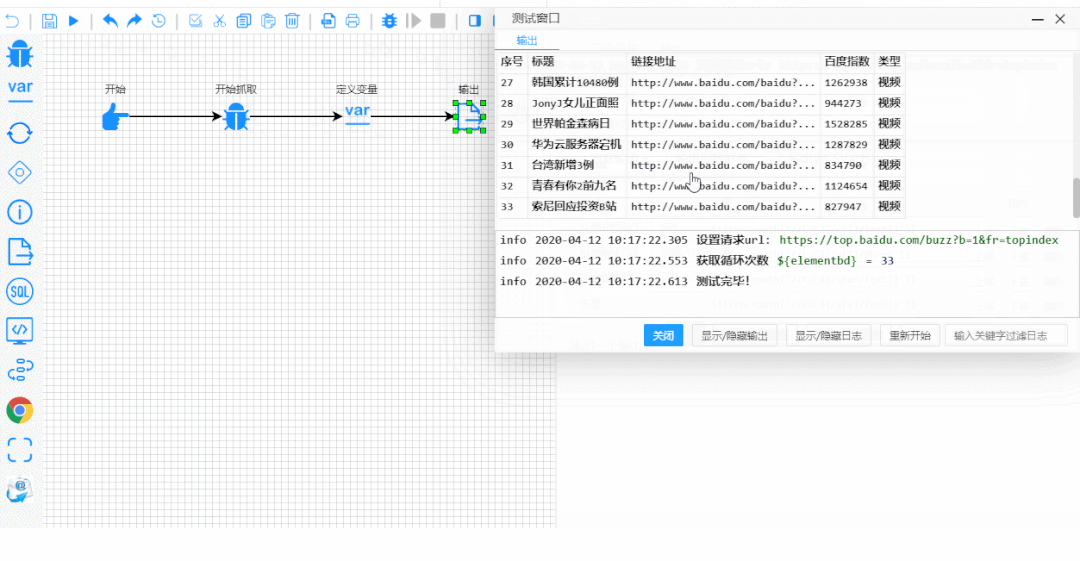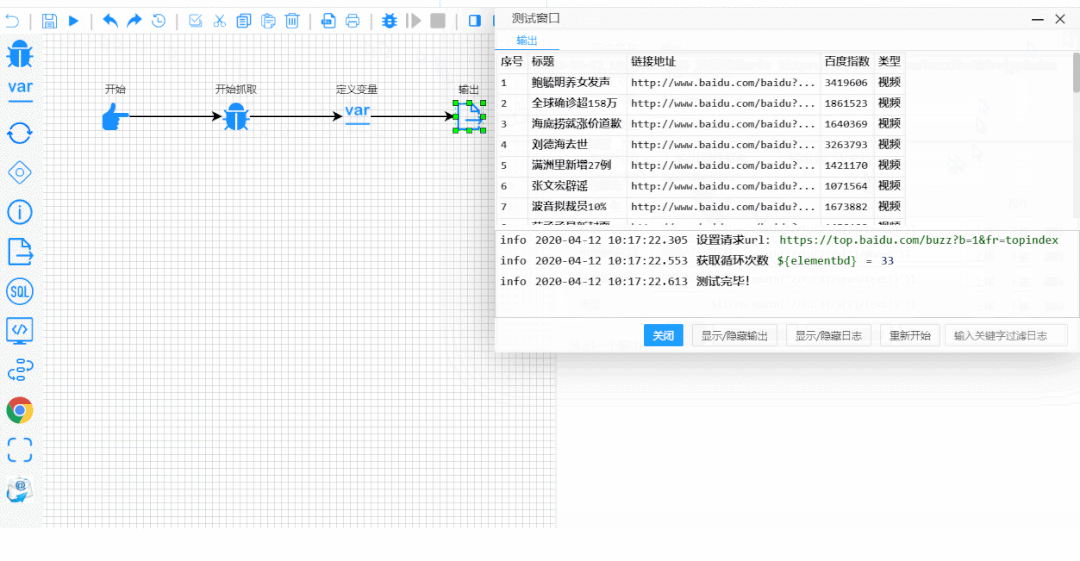
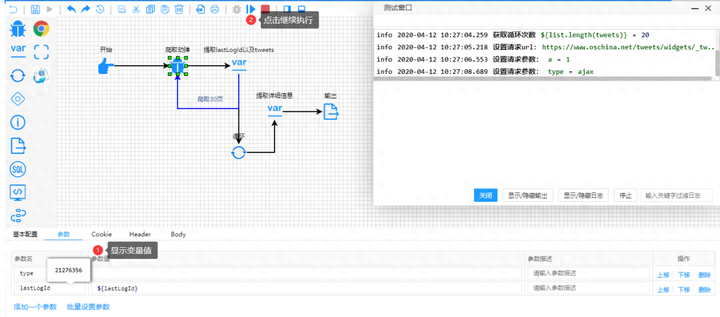
05
Java爬虫
Spiderman 是一个Java开源Web数据抽取工具,它能够收集指定的Web页面并从这些页面中提取有用的数据。
Spiderman主要是运用了像XPath,正则表达式等这些技术来实数据抽取。
地址:https://gitee.com/l-weiwei/spiderman
06
爬虫大全
这个开源项目包含多种网站、电商数据爬虫。包含:淘宝商品、微信公众号、大众点评、招聘网站、闲鱼、阿里任务、scrapy博客园、微博、百度贴吧、豆瓣电影、包图网、全景网、豆瓣音乐、某省药监局、搜狐新闻、机器学习文本采集、fofa资产采集、汽车之家、国家统计局、百度关键词收录数、蜘蛛泛目录、今日头条、豆瓣影评️️️。
地址:https://gitee.com/AJay13/ECommerceCrawlers
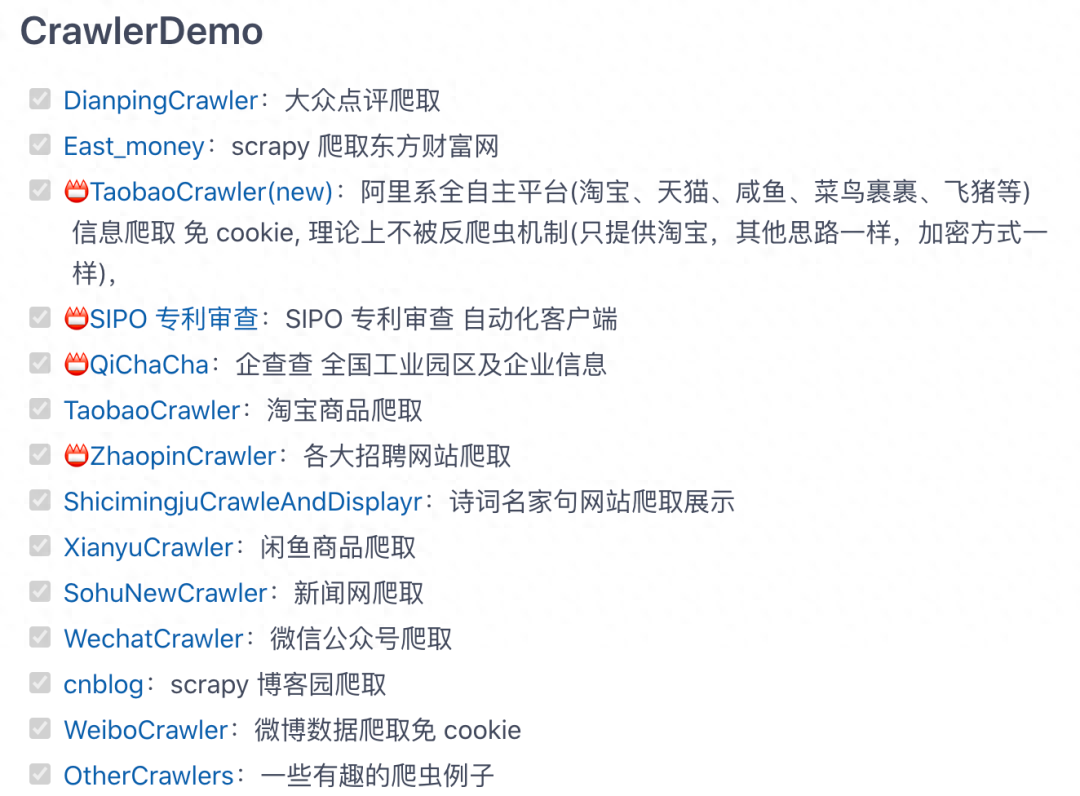
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6641
6641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









