



👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python 全国5A级景区数据采集与pyecharts可视化(源码+数据+论文)【独一无二】
一、设计要求
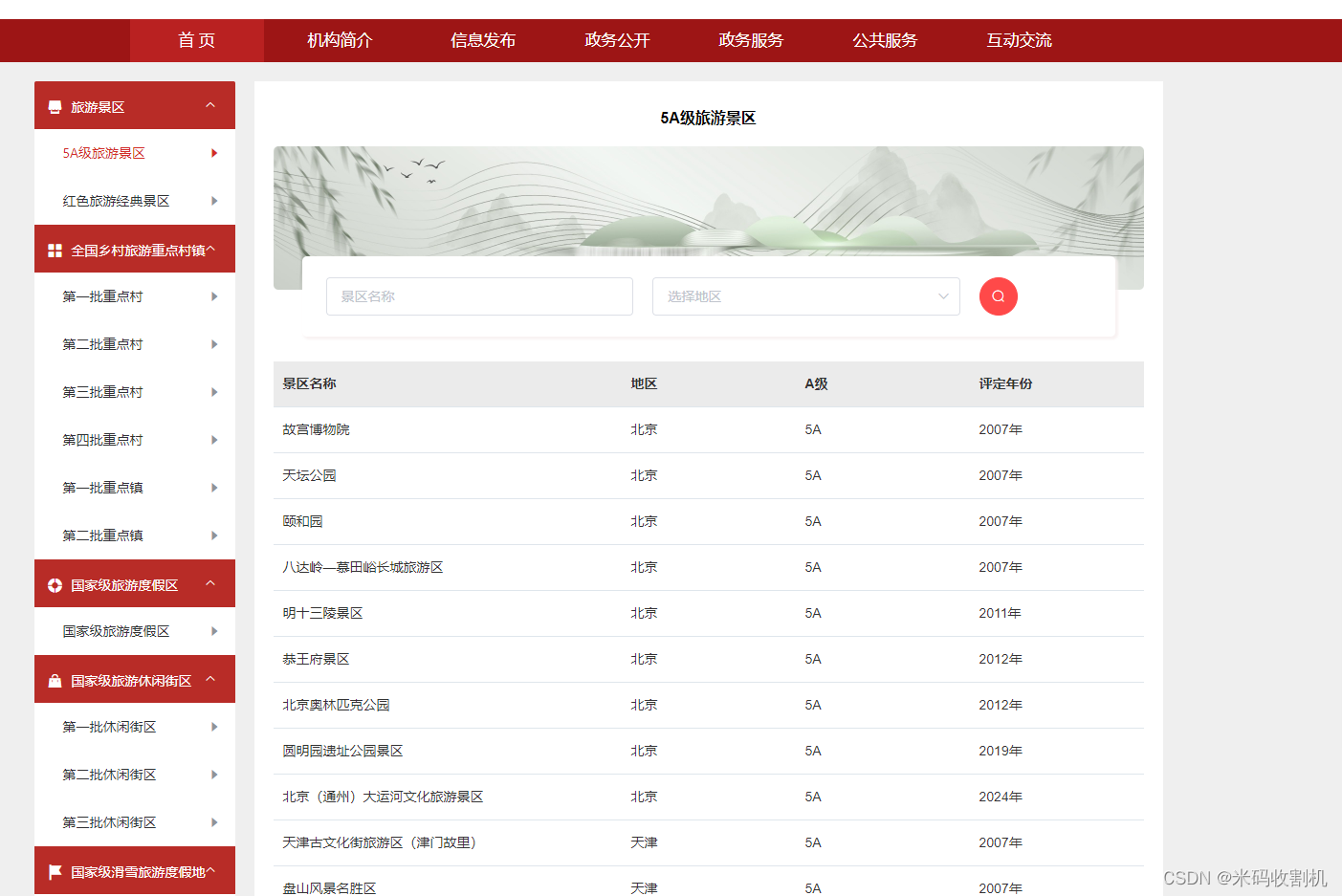
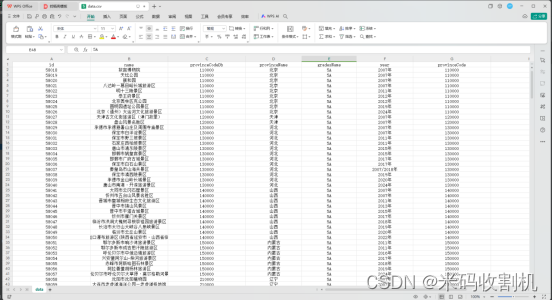
- 使用python采集从文旅部网站上采集全国5A级景区的数据,包括景区级别、景区名称和省份,并将其存储到本地文件中;
- 对采集到的数据进行清洗和预处理,处理缺失值、异常值等;
- 使用数据可视化工具Pyecharts对预处理的数据进行可视化分析,包括但不限于景区分布图、门票价格分布图、评分分布图等;
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
- 根据分析结果,撰写实验报告,总结景区分布情况。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
二、采集及数据分析可视化
2.1.数据采集
导入所需的Python库,分别用于处理JSON数据、进行HTTP请求、处理数据以及读写CSV文件。
import json
import requests
import pandas as pd
import csv:
这是定义了一个函数 write_csv,它接受一个参数 csv_file_path,用于指定CSV文件的路径。
def write_csv(csv_file_path)
打开一个CSV文件,如果文件不存在则创建,‘a+’ 模式表示以追加的方式打开文件。
with open('data.csv', 'a+', newline='', encoding='utf-8') as csvfile
csv_writer = csv.writer(csvfile)
csv_writer.writerow(csv_file_path)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
data = {…}: 准备要发送的POST请求的数据,包括目录ID、页码、每页大小和搜索列表。在这里,目录ID被硬编码为 “4”,页码由循环提供,每页大小是 20。发送POST请求,获取数据。
res = requests.post(url=url, json=data, headers=headers)
if res.status_code == 200:
text = res.text.replace('null', '0').replace('false', 'False').replace('true', 'True')
for msg in eval(text)["data"]["contentList"]["content"]
write_csv([...])
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
2.2 数据分析可视化
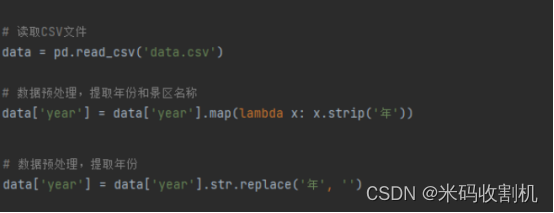
2.数据预处理
3.数据建模与分析
# 统计每年的景区数量
year_counts = data['year'].value_counts().sort_index()
# 创建柱状图
bar = Bar()
bar.add_xaxis(year_counts.index.tolist())
bar.add_yaxis("景区数量", year_counts.values.tolist())
# 设置全局配置
bar.set_global_opts(title_opts=opts.TitleOpts(title="每年景区数量统计"),
xaxis_opts=opts.AxisOpts(name="年份"),
yaxis_opts=opts.AxisOpts(name="景区数量"))
# 设置全局配置
map_chart.set_global_opts(
title_opts=opts.TitleOpts(title="各省份景区数量"),
visualmap_opts=opts.VisualMapOpts(max_=province_counts['count'].max(), is_piecewise=True, pieces=[
{"min": 1, "max": 2, "label": "1-2", "color": "#FFE4E1"},
# 略.....
# 略.....> 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
# 略.....
])
)
其余代码略.....
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈
4.数据可视化结果
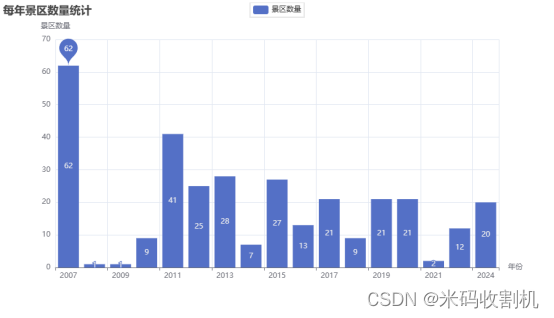
统计每年的景区数量,并以柱状图的形式展示。
使用 pyecharts 库创建 Bar 图表,设置年份为 X 轴,景区数量为 Y 轴,以展示每年景区数量的变化趋势。
设置全局配置和系列配置,如图表标题、轴名称、数据标签等。
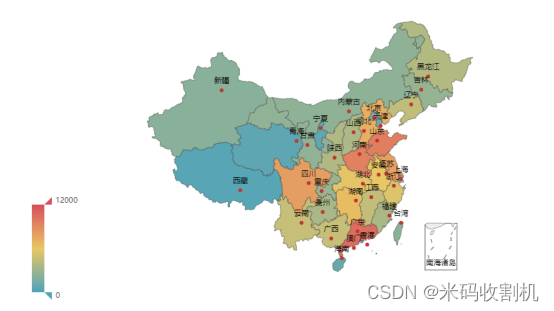
统计各省份的景区数量,并以地图的形式展示。
使用 pyecharts 库创建 Map 图表,根据省份的景区数量绘制地图,颜色深浅表示景区数量的多少。
设置全局配置,包括标题等,以及视觉映射配置,根据景区数量设置不同的颜色范围。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈

统计各省份的景区数量,并以地图的形式展示。
使用 pyecharts 库创建 Map 图表,根据省份的景区数量绘制地图,颜色深浅表示景区数量的多少。
设置全局配置,包括标题等,以及视觉映射配置,根据景区数量设置不同的颜色范围。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “景区可视化” 获取。👈👈👈



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











