







它们的特点和适用场景:
| 工具 | 特点 | 适用场景 |
|---|---|---|
Lock | 最基本的互斥锁,一次只允许一个线程访问共享资源不可重入,即同一线程再次获取会导致死锁 | 简单的线程同步需求 需要确保一段代码同一时间只能被一个线程执行 |
RLock | 可重入锁,同一线程可以多次获取锁并释放允许同一线程多次调用 acquire() | 复杂的递归线程同步需求某些情况下需要允许同一线程多次获取和释放锁 |
Semaphore | 允许一定数量的线程同时访问共享资源控制并发数量 | 有限资源的并发控制控制同时运行的线程数量,比如限流 |
Event | 可以通过 set() 和 clear() 设置和清除事件状态 线程可以等待事件的发生 | 线程间通信和同步一个线程等待某个事件的发生,另一个线程触发事件 |
Condition | 提供了更高级的线程同步机制,结合了锁和事件 | 复杂的线程协调和通信需求- 允许线程等待某个条件,其他线程在满足条件时通知等待的线程继续执行 |
3.21 Lock(锁)
threading.Lock类提供了最基本的线程同步机制,它可以确保一次只有一个线程可以访问共享资源。acquire()方法用于获取锁,release()方法用于释放锁。- 示例:
import threading
import time
# 创建一个锁对象
lock = threading.Lock()
def worker():
# 获取锁
lock.acquire()
try:
# 执行需要同步的操作
print("Thread {} is working...".format(threading.Thread.getName(t)))
# 模拟耗时操作
time.sleep(1)
finally:
# 释放锁
lock.release()
# 创建多个线程并启动它们
threads = []
for i in range(5):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print("All threads finished.")
3.22 RLock(递归锁)
threading.RLock是一个可重入锁,允许同一线程多次获得锁。acquire()和release()方法的使用方式与Lock类似,但允许同一线程多次调用acquire()。- 示例:
import threading
import time
class Counter:
def \_\_init\_\_(self):
self.value = 0
self.lock = threading.RLock()
def increment(self):
with self.lock:
self.value += 1
print(f"Incremented to {self.value} by {threading.currentThread().getName()}")
time.sleep(0.1) # 模拟一些计算或I/O操作
def decrement(self):
with self.lock:
self.value -= 1
print(f"Decremented to {self.value} by {threading.currentThread().getName()}")
time.sleep(0.1) # 模拟一些计算或I/O操作
def worker(counter):
for _ in range(3):
counter.increment()
counter.decrement()
# 创建 Counter 实例
counter = Counter()
# 创建多个线程
threads = []
for i in range(3):
thread = threading.Thread(target=worker, args=(counter,))
threads.append(thread)
thread.start()
# 等待线程执行完成
for thread in threads:
thread.join()
print("Final counter value:", counter.value)
3.23 Condition(条件变量)
threading.Condition是一个高级的线程同步工具,同时提供了锁和条件等待/通知机制。acquire()和release()方法用于加锁和解锁,wait()方法用于等待条件的通知,notify()和notify_all()方法用于发送通知。- 示例:
import threading
shared_resource = []
condition = threading.Condition()
def consumer():
with condition:
print("Consumer waiting...")
condition.wait()
print("Consumer consumed the resource:", shared_resource.pop(0))
def producer():
with condition:
print("Producer producing resource...")
shared_resource.append("New Resource")
condition.notify()
print("Producer notified the consumer.")
# 创建线程
consumer_thread = threading.Thread(target=consumer)
producer_thread = threading.Thread(target=producer)
# 启动线程
consumer_thread.start()
producer_thread.start()
# 等待线程执行完成
consumer_thread.join()
producer_thread.join()
print("Main thread ends.")
3.24 Semaphore(信号量)
threading.Semaphore是一种控制并发访问的计数器,它允许多个线程同时访问共享资源,但可以限制同时访问的线程数量。acquire()和release()方法用于获取和释放信号量。- 示例:
import threading
semaphore = threading.Semaphore(value=2) # 允许同时两个线程访问
def access\_resource():
with semaphore:
print(threading.currentThread().getName(), "is accessing the resource.")
# 假设这里是对共享资源的访问
# 创建多个线程
threads = []
for i in range(5):
thread = threading.Thread(target=access_resource)
threads.append(thread)
thread.start()
# 等待线程执行完成
for thread in threads:
thread.join()
print("Main thread ends.")
这些是 Python 中常用的线程同步方法。选择合适的方法取决于你的应用场景,例如是否需要多次获取锁、是否需要等待条件、是否需要限制并发数量等。这些同步工具能够有效地管理多线程程序中的竞态条件,确保线程安全地访问共享资源。
四、GIL
4.1 简述
Python的全局解释器锁(Global Interpreter Lock,简称GIL)是CPython解释器中的一种线程同步机制。具体如下:
- 原理与作用:GIL是一种互斥锁,它确保在任何时刻只有一个线程执行Python字节码。这意味着即使在多核CPU上,使用多线程的Python程序也无法实现真正的并行执行。
- 优缺点:GIL的存在简化了内存管理和解释器的实现,因为不需要担心多个线程同时修改内存中的数据结构。然而,这也限制了多线程在计算密集型任务中的应用,因为GIL会阻止多个线程同时利用多核处理器的优势。
- 性能瓶颈:对于I/O密集型任务,GIL的影响相对较小,因为线程大部分时间都在等待I/O操作,而不是执行计算。但是,对于计算密集型任务,GIL可能导致性能瓶颈,因为它限制了多线程的并行能力。
- 解决方案:为了克服GIL的限制,可以使用多进程代替多线程(多进程未必使程序更快),因为每个进程都有自己的Python解释器和GIL,从而可以在多核CPU上并行运行。此外,还可以使用Jython或IronPython这样的替代Python解释器,它们没有GIL的限制。
- 未来展望:Python社区正在努力解决GIL的问题。例如,Python 3.12引入了GIL可选项,允许在编译时关闭GIL,以提高CPU密集型场景的性能。
在cpython的PR中可以看到前几天的一条PR,即添加GIL的开关。
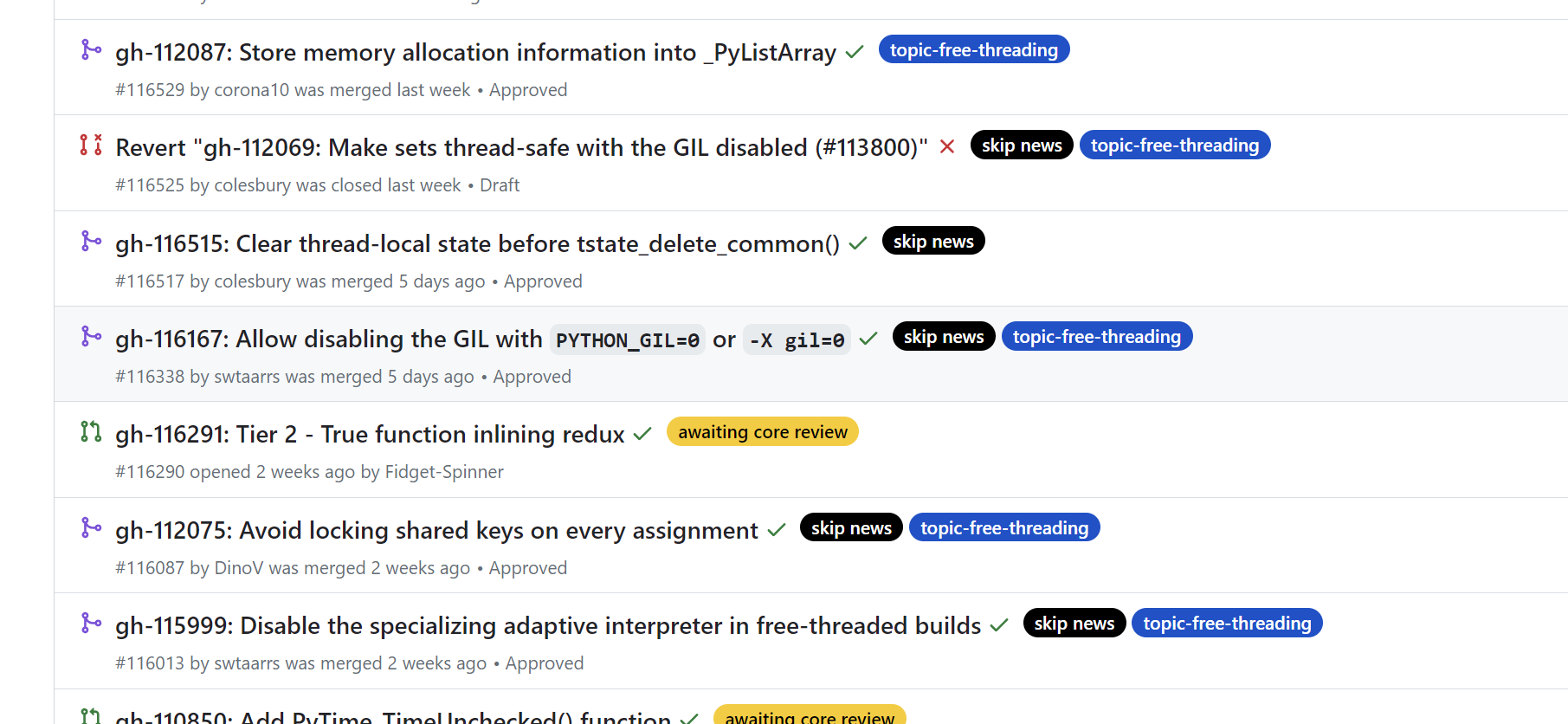
当然不是release版,能用到可能还需要很久。
有时候,限制程序性能的可能不是GIL,而是程序的生产者。🤣
4.2 详细
看的高天视频。
在讲解GIL之前,首先需要澄清一个概念:什么是线程?
- 线程是操作系统进行计算和调度的最小单位。我们可以简单地理解为,程序运行在线程中。每个线程有自己的上下文。
- 而进程是比线程更大的单位,每个进程有自己的内存等。一个进程可以包含多个线程,这些线程共享进程的内存,也就是说这些线程可以读写相同的变量。
当一个进程有不止一个线程时,就会出现一种情况,称为"racing"或"竞争冒险"。因为一个进程中的多个线程,既可能同时运行,也可能交替运行。无论是同时运行还是交替运行,你都无法控制它们之间的相对顺序。
举例:
a = 1
if a > 0:
a -= 1
- 假设两个线程都在运行这个函数。
- 我们有"线程一"和"线程二"。假设它们两个都成功地将 A 初始化为 1。注意,他们两个共享变量 A。
- 假设 “多线程一” 先来判断 if A 大于零,他发现是 true,然后进入了 if 语句。
- 这时候 “多线程二” 开始判断,同时也发现 A 大于零,然后也进入了 if 语句。
- 由于他们两个线程都进了 if 语句,所以 A 被减了两次。然而,左边这个程序的目的显然是将 A 减到零。
- 在更多情况下,可能是线程一运行,然后 if A 大于零,A 减一,然后 A 变成零了。这时候线程二再来判断 if A 大于零,他就发现 A 不大于零了,然后他就跳过了 if 语句。
- 这种情况,由于线程之间的相对运行顺序不同,导致了结果不同,我们称之为"竞争冒险"。
如果你学过 C 和 C++ 的话,你会知道在这些语言里,你需要显式地分配(如malloc)和释放(free)内存。如果你只分配不释放,随着程序的运行,你占用的内存会越来越多,最终导致内存泄漏。但是在 Python 中,你不需要显式地去分配和释放内存。所有的 Python 对象,包括列表和字典等,你拿来就可以直接使用,不用担心这些繁琐的事情,因为 Python 的解释器会帮你管理内存。
那么 Python 是如何实现自动分配和释放内存的呢?内存分配相对容易,我需要内存时我就拿就行了,关键是什么时候可以释放它。Python 使用的机制叫做"引用计数"。引用计数的原理并不复杂,每一个 Python 对象都数着有多少个地方在使用它。当没有新的地方在使用它时,对象的引用计数加一;当这个对象不再被使用时,引用计数减一。这样一来,只要你数数是对的,Python 就可以知道什么时候这个对象的引用计数变为零,这时候就没有人需要它了,于是自动帮你释放掉这块内存。
这个过程本身并不难理解,就是数数嘛。
然而,结合刚才我们提到的"竞争冒险",我们可以想象,如果一个进程中有多个线程在运行的话,这里就会存在一个"竞争冒险"的问题。因为这个减少引用计数的操作并不是"原子性(atomic)"的。"原子性"的意思是在运行的时候不会被其他线程打断。这个减少引用计数虽然在 C 语言中看起来像一个操作符,但它实际上也要先读取这个引用计数的信息,然后减一再存回去。在这三个步骤中间,就有可能有其他的线程过来,在你存回去之前也进行这个操作。这种情况的发生就可能导致你数数数错了,多数了一个,或者少数了一个。一旦你数数数不清楚了,你就无法保证每一个 Python 对象都能被正确释放,那就会出现严重的内存泄漏问题。
在多线程中一般来说,我们会使用"加锁"来解决这个问题。加锁的意思是,我要保证这一段程序只有一个线程在运行,其他线程不能进入这段程序。
伪代码:
# 在这个if之前,先锁住
lock.acquire()
if a > 0:
a -= 1
# 在这个if之后,释放锁
lock.release()
通过这种方式,在运行 if a > 0: 语句块时,其他线程无法进入这段代码。他们需要等待当前线程释放锁之后,才能再次运行这段程序。
回到 Python。你可能会认为在这个例子中,只需在 if 外面加一个锁就可以解决问题。但是在 Python 中,并不仅仅是引用计数存在这个问题,所有与 Python 对象相关的代码都有可能存在竞争冒险的问题,都有可能有多个线程同时尝试读取或写入 Python 对象的数据。因此,当 Python 设计者决定给 Python 设计一个全局锁,也就是我们所说的 GIL ,这是一个比较简单的解决方案。
GIL,全局解释器锁,位于我们之前提到的 CPython 的主循环中。它的作用是确保在它运行完之前,当前线程持有 GIL 锁。通过这种机制,Python 可以确保每一个字节码在运行时都拿到线程锁。换言之,没有线程能够在运行期间打断执行任何字节码。因此,在每一个字节码中运行的 C 程序都是线程安全的。你可以在里面放心地增加引用计数、减少引用计数,而不必担心锁的问题,因为你知道锁已经被拿住了。
全局锁带来的好处是非常多的:
- 首先,这是一个非常简单的设计。在编写较大项目时,你会发现简单真的很重要。程序越简单,你维护所需要的努力就越少。相比于为每个对象实现自己的锁,全局锁要简单得多。
- 其次,由于只有一个线程锁,它避免了死锁问题。死锁是指一个线程拥有两个以上的锁时可能发生的情况。
- 第三,对于单线程程序或者不能并行的多线程程序来说,全局锁的性能是非常优秀的。因为全局锁保证了每次运行一个字节码时最多只需要一次锁。但是如果每个对象都有自己的锁,你可能需要多次锁。
- 最后,它让编写 C 扩展变得更容易。因为你可以确定每个字节码运行时都没有竞争冒险的问题。这样在你的 C 代码中修改 Python 对象时,你就不必担心锁的问题了,这让第三方开发者编写扩展变得更容易。
正因为这些优点,GIL 至今仍然存在于 Python 中。当然,也有人尝试过从 Python 中移除 GIL,但没有一次尝试能够保证 Python 在单线程下的运行速度不受影响。另外,还有一个非常严重的问题,即所谓的向后兼容性。也就是说,之前写的 C 扩展都默认现在有线程锁。如果你现在把这个东西拿掉了,那之前写的扩展很可能就无法使用了。
上面谈到了 GIL 的一些优势,但是它也受到很多人的批评,因为它限制了 Python 在多核 CPU 下的表现。然而,在 Python 中,有其他的方法来避免这个问题。
- 最简单也是最 Python 的方法就是**使用多进程。**虽然一个进程不能利用多个 CPU 核心,但我可以有很多个进程,通过多进程可以避开 GIL 的问题,并利用多核 CPU 来加速程序。
- 第二种方法是编写 C 扩展,然后在 C 中实现多线程,让多线程运行的是 C 代码而不是 Python 代码。当然,这样一来,你需要自己解决竞争冒险的问题。
- 最后,你还可以尝试使用一些没有 GIL 的 Python 解释器,像 Jython 和 IronPython。不过,它们也有自己的问题。
4.3 有GIL多线程仍要加锁
尽管Python的全局解释器锁(GIL)确保了同一时刻只有一个线程执行Python字节码,这防止了多个线程同时修改Python对象,从而避免了一些竞态条件问题。然而,这并不意味着你可以完全不需要锁。
简单例程:
import threading
counter = 0
def f():
global counter
for _ in range(1000000):
counter += 1
t1 = threading.Thread(target=f)
t2 = threading.Thread(target=f)
t1.start()
t2.start()
t1.join()
t2.join()
print(counter)
分别用 python3.12 和 python3.8 来运行:
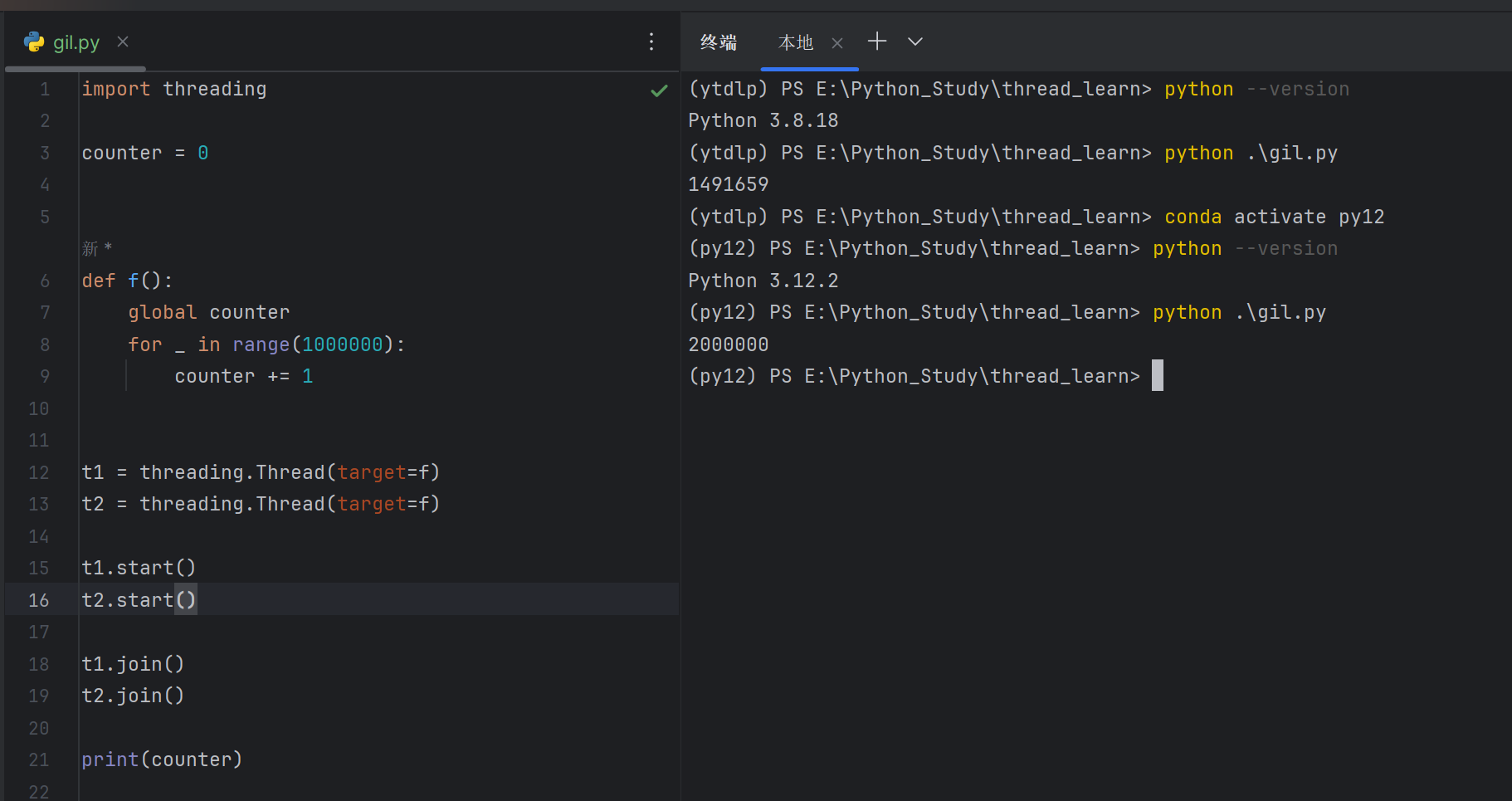
结果是不一样的。Why ???
python虚拟机的核心在_PyEval_EvalFrameDefault函数里面,先看一下3.8版本的,主要是main loop:,它负责一个一个运行字节码,循环开始时,对eval_breaker的值进行了检查,它保存的信息是是否需要交出GIL。
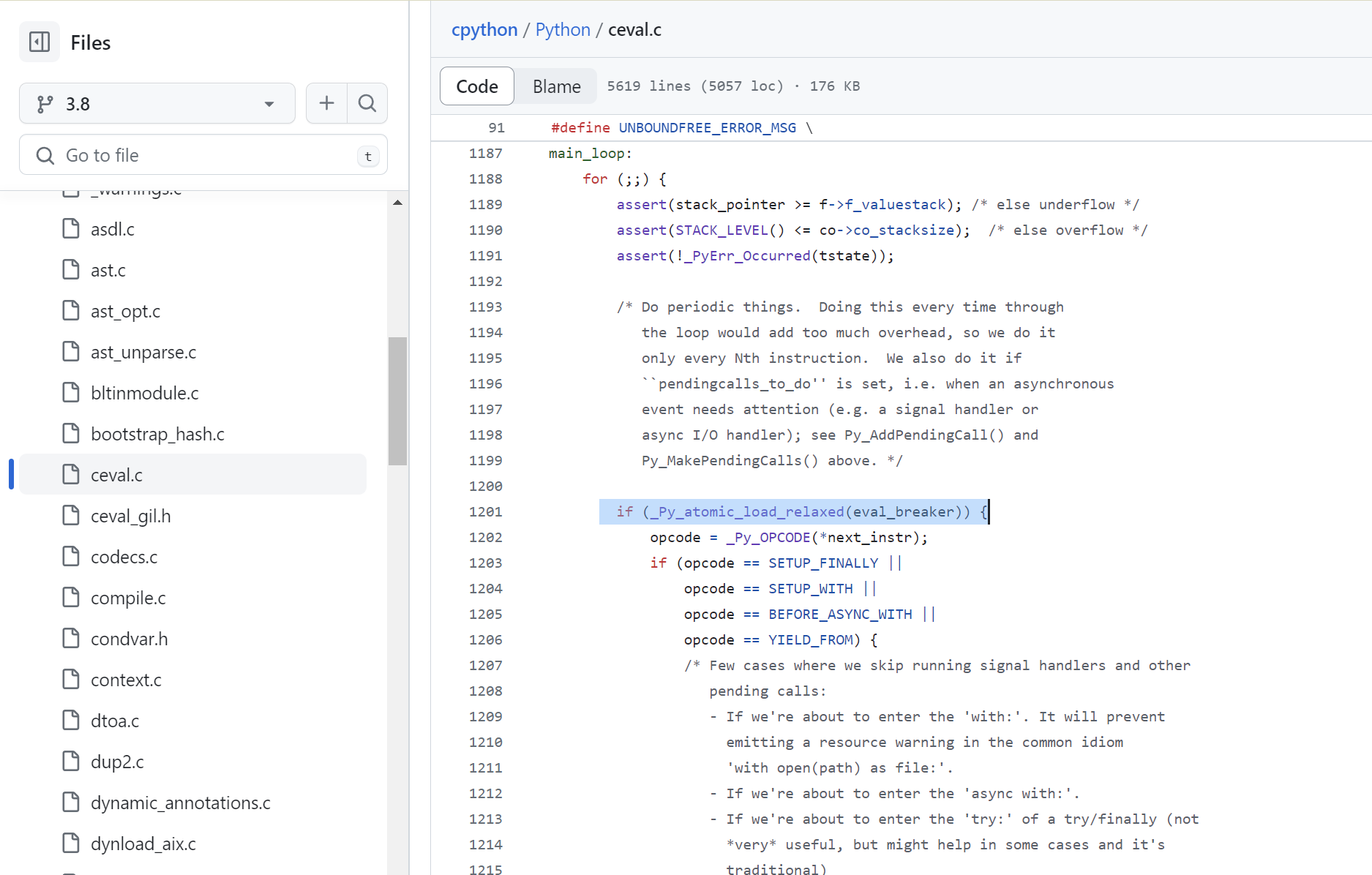
每一次循环,即一个字节码的运行时,都会检查是否需要交出GIL(给其他线程)。但这样开销较大。可以看到不同字节码可能对应 FAST_DISPATCH和 DISPATCH,前者不会触发GIL检查,后者会。python3.8 里面使用
DISPATCH的占大多数。即大部分字节码运行后有可能交出GIL,给其它线程使用。

查看前面程序的字节码:python -m dis .\gil.py
9 12 LOAD_GLOBAL 1 (counter)
14 LOAD_CONST 2 (1)
16 INPLACE_ADD
而INPLACE_ADD对应的是DISPATCH,即第一个线程运行+1后还没将结果保存到counter就可能会交出GIL,然后线程2在那里自加,之后又将运行权交给线程1,线程1将很久之前的值拿来加,导致结果错误。
在python3.8中
#define FAST\_DISPATCH() goto fast\_next\_opcode
#define DISPATCH() continue
而3.10中:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









