







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Web前端全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注前端)

正文
V8引擎的工作流程:
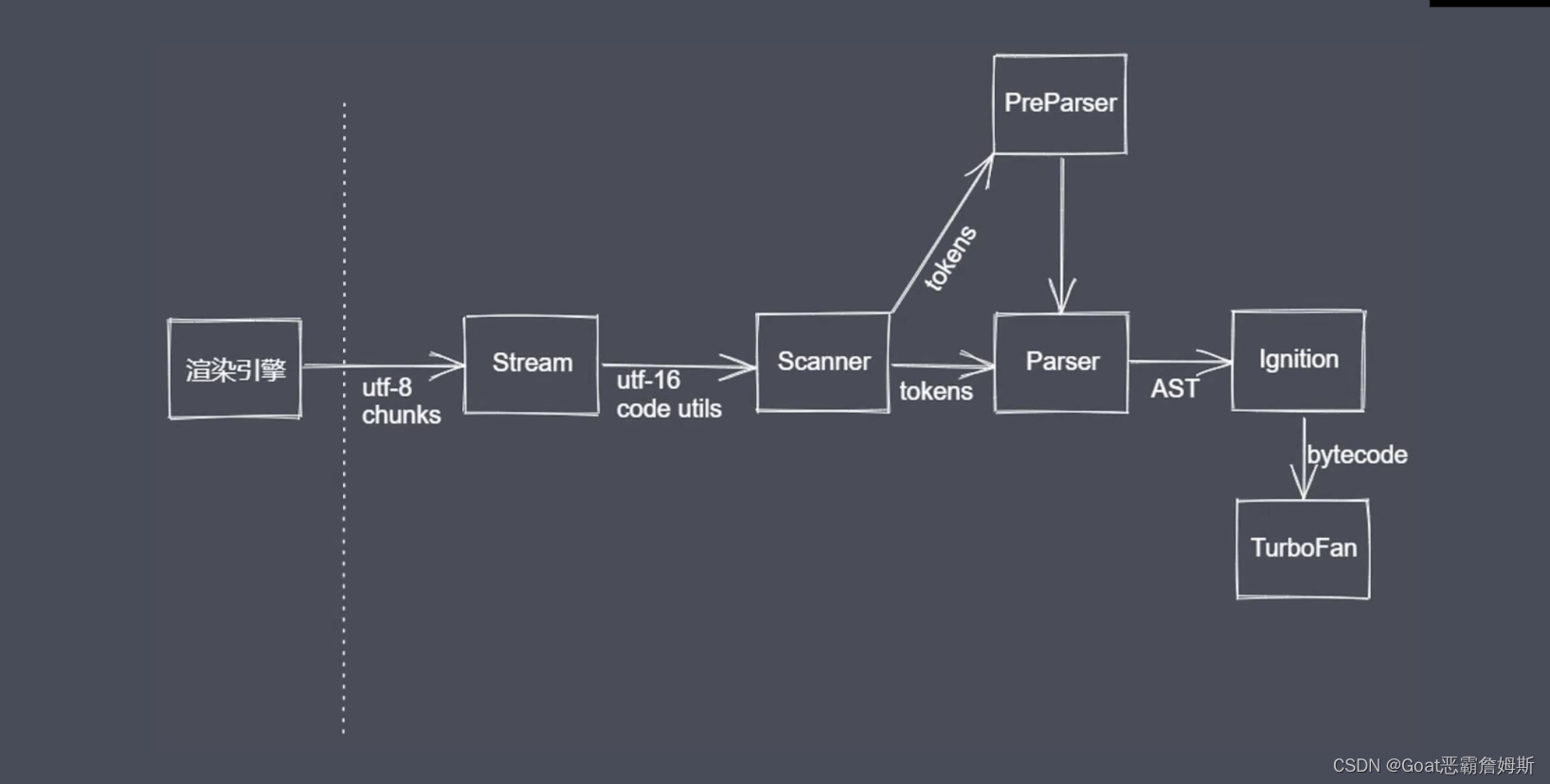
本身是个引用程序,也是js的运行环境,在浏览器中用于解析和编译js代码 ,内部也存在很多的子模块,如图scanner是一个扫描器,对纯文本的js代码进行词法的分析,把代码分子成不同的tokens,会得到一个词语的单元,指在语法上没有办法再分割的最小单位,可能是一个单个字符,也可能是字符串,例如:
const username= "Hello"
扫描后大概是下面的样子,当然只是形象的表示,并不代表就是这样子的:
[
{
"type":"Keyword",
"value":"const"
},
{
"type":"Identifier",
"value":"username"
},
{
"type":"Punctuator",
"value":"="
},
{
"type":"String",
"value":"Hello"
}
]
下面就到了Parser解析器, 把上述词法分析出的tokens转换成抽象的ast语法树,同时也会做语法校验,如果有错就会抛出错误。如下:
{
"type":"Program",
"body":[
{
"type":"VariableDeclaration",
"declarations":[
"type":"VariableDeclarator",
"id":{
"type":"identifier",
"name":"username"
},
"init":{
"type":"Literal",
"value":"Hello",
"raw":"Hello",
},
],
"kind":"const"
}
],
"sourceType":"script"
}
parser的解析有两种情况,预解析preparser和全量解析parser。
preparser:比如在代码中我们声明了很多变量,但并没有每个都使用,此时如果做全量解析,要转为字节码等,但我们最后又不去执行,会有很多无用功,所以有了预解析,会跳过未被使用的代码,不会生成ast,但会产生一些相应的scope信息,这些信息没有变量的引用和声明,因为在这里并不是真正的执行。但是作用域的信息,我们这里是有的,同时也会依据规范来抛出特定的错误,不是全量解析,所以不会全部抛出,解析速度会更快,因为做的事情会少一些。如下:
function fn1(){
console.log('fn1')
}
function fn2(){
console.log('fn2')
}
fn2()
fn1没有被执行,那么fn1就是预解析, 不会生成ast,但仍然会生成作用域的信息。
parser全量解析:会立即解析所有立即执行的代码,会生成相应的ast语法树,同样也会确定更多的信息,其实对应着我们执行上下文的创建,内存中构建具体scopes(作用域),scopes chain信息,变量引用,声明等,这些都是在预解析和解析阶段完成的,但此时代码是并未执行的,会抛出所有的错误。分析一段代码:
// 声明时未被调用,因此会被认为是不会被执行的代码,进行预解析
function foo(){
console.log('foo')
}
// 声明时未调用,因此会被认为是不会被执行的代码,进行预解析
function fn(){
console.log('fn2')
}
//函数立即执行,只进行一次全量解析
(function bar(){
console.log('fn2')
})()
// 执行foo,那么再对foo进行全量解析,此时foo函数被解析了两次
foo()
如果我们在foo函数中再声明一个函数,那么还是一样会执行预解析,然后调用时全量解析,解析了两次,所以嵌套层级太深也会导致多次的解析操作,因此书写代码也要减少不必要的函数嵌套。
ignition :是V8提供的一个解释器
把之前生成的抽象的ast语法树把它转变为字节码bytesCode,同时收集在下个编译阶段需要的一些信息,可以把这个过程看作是预编译的过程,不过基于性能考虑,其实不会把编译和预编译区分特别明显,因为有些代码在预编译就可以直接执行。
TurboFan :是V8提供的编译器模块,利用上个阶段收集到的信息,把这些字节码来转化为我们具体的汇编代码,之后可以开始代码执行,也就是后续需要理解和分析的堆栈执行过程。
堆栈操作
分析堆栈方面的处理操作的主要目的是可以本质上分析一段代码的执行过过程,另一方面后续如果想要分析一段代码执行时所涉及到性能问题,可以从堆栈层面上考虑一下执行流程,可以看看性能消耗。
js代码在执行时一定需要一个环境,浏览器下面会有它自己的js执行引擎比如说V8,代码最终会被转为可以被识别的机器码,那这些字符串类型的机器码具体是在哪里执行呢?这块会用到环境执行栈(ECStack,execution context stack),浏览器在渲染界面的时候,会去在计算机的内存当中开辟一个内存空间,专门来用于执行js代码,而这个栈内存就是我们所说的执行环境栈,但是不同的区域又要保持互相的独立,不能相互影响,全局执行上下文管理全局的代码执行,某一个私有的执行上下文管理它自己的局部代码,这样就可以区分不同的区域代码执行了。
以全局执行上下文为例:
在全局执行上下文当中,可能会同时存在很多个变量声明,这些内容又存在哪里呢?底层给出了一个VO(G)的全局变量对象,它肯定占据了一片空间,我们就认为所有的变量的声明都被放在这个对象中所占据的空间里,有了这些之后全局里的代码就可以进栈执行了。例如我们连续调用多个函数,但是无论怎么操作,全局的执行上下文都是存在的,因此在这个栈底永远都有一个ECG——全局执行上下文。
而代码的执行步骤,针对全局来说,肯定要做编译,包含之前所提到的词法分析,语法分析,预解析的过程等,接下就是代码执行了,如图:
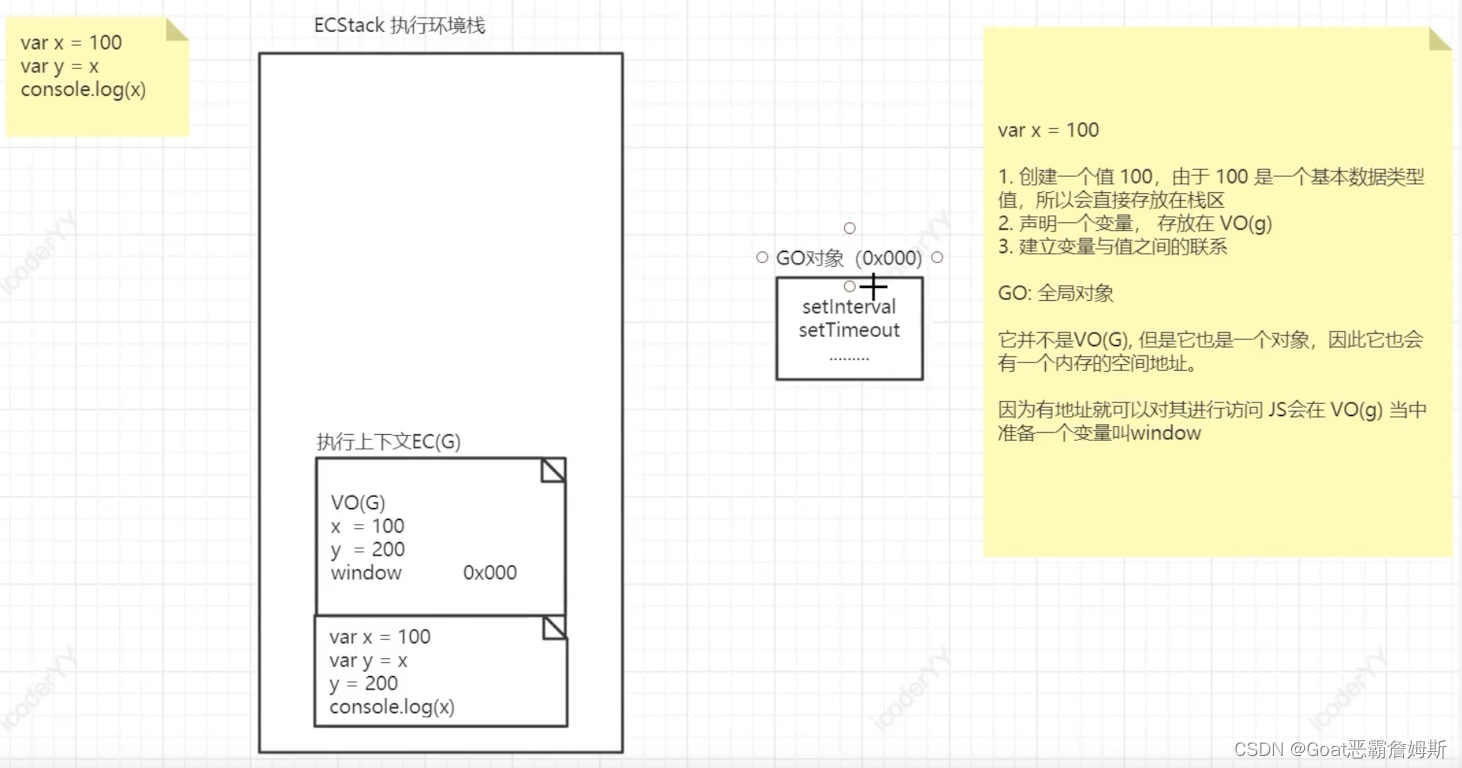
ECStack全局执行栈就是在浏览器申请开辟的内存空间,代码编译前会有个进入执行环境站栈的操作,x,y是属于全局执行上下文中,被存放在全局变量对象VO(G)中,先创建一个值,比如创建100,100是基本数据类型,会放在栈区,然后再声明一个变量x,存放在VO(G),最后建立值与变量的联系,同理在VO(G)里面会再创建y,也同样与100建立联系。
在执行完毕后出站,然后创建的值和声明的变量都会被释放掉,但是变量有可能引用了另外的对象地址,那么被引用的对象不一定会被释放掉。
总结:
基本数据类型都是按值操作
基本数据类型值存放在栈内存
栈内存和堆内存(引用数据用的)都属于计算机内存,如果用的太多对我们的使用会有性能的影响。
GO:全局对象,它并不是VO(G),但也是个对象,因此也会有一个内存的空间地址。
js会在VO(G)中准备一个变量叫window,可以直接通过window访问GO的全局对象,对应的栈区里存的只是一个地址,指向GO全局对象。
引用类型堆栈操作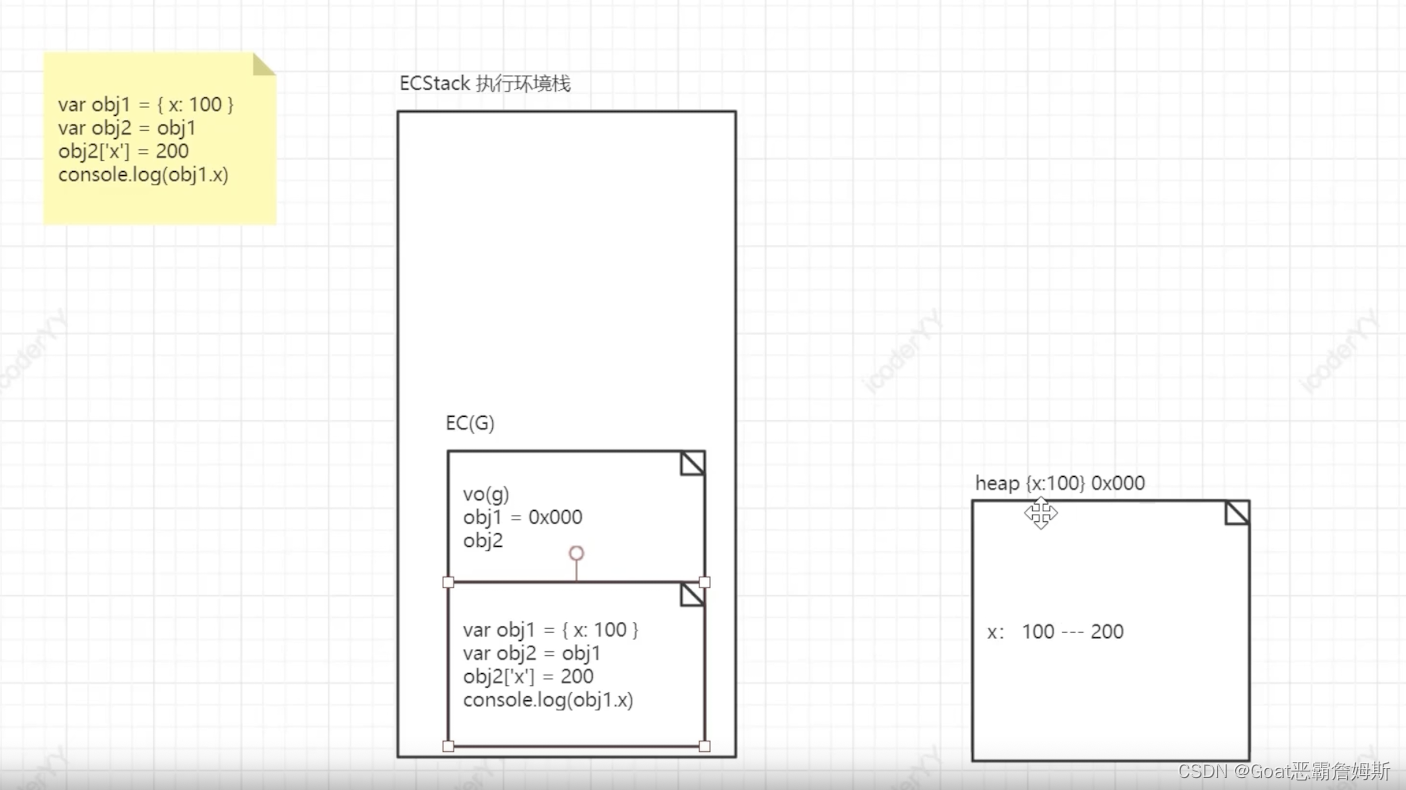 在全局执行上下文执行时还是一样,会先在全局变量VO(G)中创建变量,然后在堆内存中创建对象数据,地址以十六进制表示,在全局变量对象中建立数据联系,obj1所指向的是其实就是数据所在堆内存中的地址。obj2也是指向相同的地址,obj2修改x的值,因为是个地址引用,所以会在对应的堆内存中找到x并且改值,在这里obj1的x属性也会改变。
在全局执行上下文执行时还是一样,会先在全局变量VO(G)中创建变量,然后在堆内存中创建对象数据,地址以十六进制表示,在全局变量对象中建立数据联系,obj1所指向的是其实就是数据所在堆内存中的地址。obj2也是指向相同的地址,obj2修改x的值,因为是个地址引用,所以会在对应的堆内存中找到x并且改值,在这里obj1的x属性也会改变。
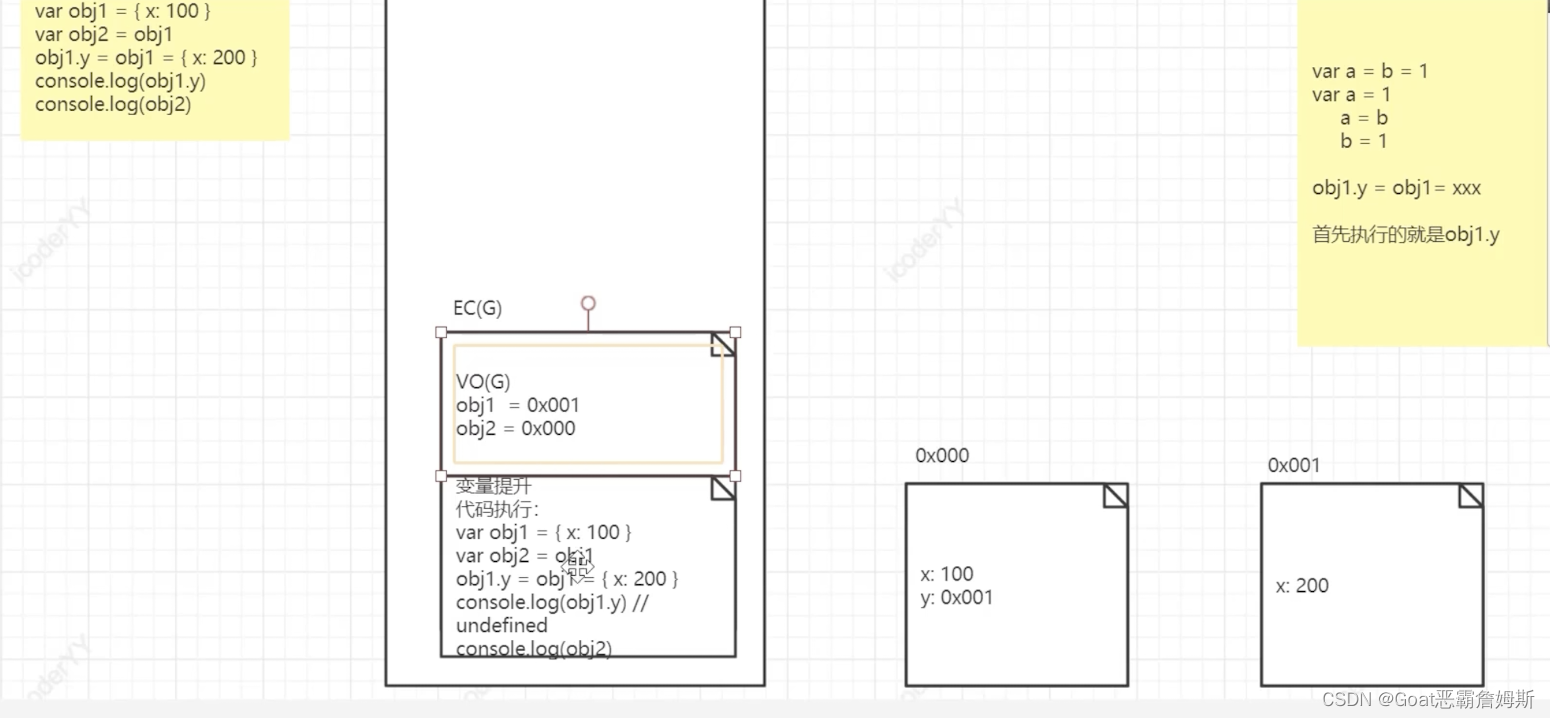
重复的就不再赘述,在这里比较难理解的是obj1.y先执行,创建新内存指向0x001,obj1指向为0x000,再执行obj1={x:200},此时obj的指向1已经改变了为0x001,那么此时0x001并不存在y属性,所以打印为undefined,obj2的引用地址为0x000那么此时,obj2是含有y属性的。
函数堆栈处理
对于函数的处理会有稍微的不同,在全局创建一个函数,那么在全局变量对象中会声明变量,同时在堆内存创建空间存储函数,也是以十六进制地址的形式来表示,内容是以字符串的形式存储,但是函数的地址会被保存在栈内存中,调用时直接通过地址访问函数,创建函数时就已经确定了它的作用域,也就是创建函数时所在的执行上下文,全局创建作用域就是全局执行上下文。
函数执行,就是将堆内存中的字符串形式的代码执行,执行过程中会生成一个新执行上下文来管理函数体当中的代码,私有执行上下文EC,其中就包括当前上下文中的变量区域AO,具体包括:
1.确定作用域链,包括当前执行上下文,上级执行上下文。
2.确定this的指向,全局指向window。
3.初始化argumens对象。
4.形参赋值,也就是变量声明,会存储在AO中,变量的储存的方式与上述全局的一致。
5.变量提升,有使用var的话。
6.执行代码。
执行结束后,出栈释放,在局部作用域内的变量会被释放,但是堆内存的地址还是存在的,只是断了与局部变量之间的引用关系,其他的地方还是会正常引用。
闭包堆栈处理
函数的处理基本不变,但是出现了父子函数,父子函数的处理也都是相同的,在代码执行完毕之后,正常情况下是要出栈的,如果把父函数释放了,那么子函数也被释放了,但是子函数被外部的变量引用着,那么就会存在变量找不到值的问题,所以当前的父函数是不能释放的,创建的执行上下文不能被释放,这就是闭包的现象。执行完毕后,子函数的变量以及作用域会得到释放。
闭包是一种机制,通过私有上下文来保护当中变量的机制。我们也可以认为当我们创建的某一个执行上下文不被释放的时候就形成了闭包,可以起到保护,保存数据。
闭包垃圾回收
浏览器都自有垃圾回收(内存管理,V8为例)
释放对空间和栈空间,栈空间的数据如果外部没有引用,就会被释放掉,当前堆内存如果被引用,就不能被释放,如果后续不再使用内存里的数据,也可以自己主动释放置空,浏览器就会对其回收。
当前上下文中是否有内容,被其他上下文的变量所占用,如果有则无法释放(闭包),我们置空即可(置为null)
注:对于同种元素的方法添加最好使用事件委托,避免生成多的空间占用内存。
JSBench的使用
可以测试代码的性能,JSBench.me
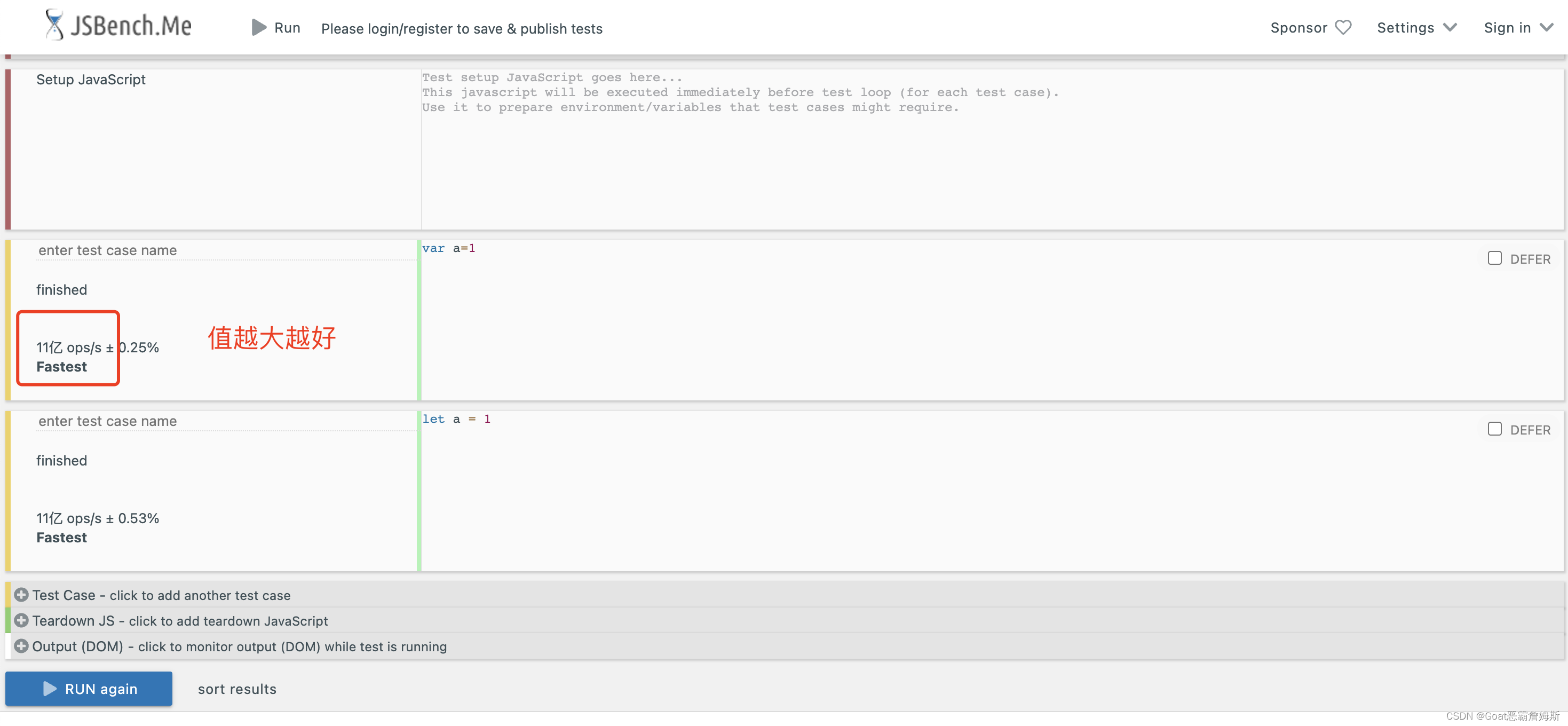
使用过程中最好只开一个页面,多个页面多线程影响速度,执行测试时不要做其他的事情,会影响效率,还有最好多执行几次,来取几率最高的结果,对于结果我们不应该纠结于代码的执行时间,对于性能测试i来说,我们关注的并不是只有时间,这只是众多性能指标中的一个,一段代码执行速度快不一定就很健壮,而对于我们的代码在执行过程中所涉及到的性能更多的是两个方面,要么拿空间换时间,要么牺牲时间获得更多的空间。
变量局部化
将变量尽量声明在局部作用域当中,这样可以提高执行代码的效率,减少了数据访问时查找的路径。
缓存数据
对于需要多次使用的数据进行提前保存,后续可以重复使用
减少访问层级
尽量将要访问的对象或属性放在可以最近访问到的位置,可以提高代码的效率。
防抖和节流
在一些高频率时间触发的场景下,我们不希望对应的事件处理函数多次执行。比如,滚动事件,输入的模糊匹配,轮播图切换,点击操作等。
浏览器默认情况下都会有自己的监听事件间隔,如果监听到多次事件的监听执行,那么就会造成不必要的资源浪费。
防抖:对于高频率的操作,避免事件的重复触发,n 秒后在执行该事件
节流:对于高频操作,每隔一段时间执行,n秒内只执行一次。
减少if判断层级,减少循环体活动(包括循环体内部的代码,经常使用但不变的部分,可以放在循环体外面)。
字面量与构造式
使用new的方式会比字面量的声明变量的方式花费的时间更多,因为调用了函数,会多做很多其他的事情。
刷面试题
刷题的重要性,不用多说。对于应届生或工作年限不长的人来说,刷面试题一方面能够尽可能地快速自己对某个技术点的理解,另一方面在面试时,有一定几率被问到相同或相似题,另外或多或少也能够为自己面试增加一些自信心,可见适当的刷题是很有必要的。
-
前端字节跳动真题解析

-
【269页】前端大厂面试题宝典

最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
g)
最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)
[外链图片转存中…(img-bzwwpM7C-1713476855823)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









