






本文档面向对自动化网页交互、数据抓取和网络自动化任务感兴趣的Python开发者。无论你是初学者还是有经验的开发者,Webbot库都能为你的自动化项目提供强大的支持。

Webbot库概述
Webbot是一个专为Python设计的库,用于简化网页自动化任务。它基于Selenium WebDriver,提供了一系列高级接口,使自动化任务更加直观和易于管理。Webbot库的设计理念是将复杂的网页交互抽象为简单的API调用,从而减少开发者在编写自动化脚本时的工作量。
Webbot库的核心功能包括自动化表单填写、点击操作、数据抓取等,同时支持处理JavaScript渲染的页面和模拟用户行为。这些功能使得Webbot库成为自动化测试、数据收集和网页监控等领域的理想选择。
主要功能
Webbot库提供了一系列强大的功能,以下是一些关键功能:
自动化表单填写:Webbot库可以自动填写网页表单,支持文本框、下拉菜单、复选框等多种表单元素。
点击操作:通过Webbot库,可以模拟鼠标点击事件,触发网页上的按钮、链接等元素。
数据抓取:Webbot库能够从网页中提取文本、图片、链接等数据,方便进行进一步的分析和处理。
JavaScript处理:Webbot库支持执行JavaScript代码,处理需要JavaScript渲染的动态内容。
用户行为模拟:Webbot库可以模拟键盘输入、页面滚动等用户行为,更真实地模拟用户操作。
使用场景
Webbot库适用于多种自动化任务场景,以下是一些常见的使用场景:
自动化测试:Webbot库可以用于自动化网页功能测试,模拟用户操作,验证网页功能的正确性。
数据收集:通过Webbot库,可以定期从网页抓取数据,进行市场分析、价格监控等。
监控系统:Webbot库可以用于监控网页内容的实时变化,例如监控新闻网站的最新新闻。
安装与配置
要使用Webbot库,首先需要通过pip安装:
pip install webbot
然后,确保已安装对应的WebDriver,如ChromeDriver。WebDriver是Selenium WebDriver的本地实现,用于控制浏览器。以下是安装ChromeDriver的步骤:
下载与你的Chrome浏览器版本兼容的ChromeDriver。
将下载的ChromeDriver可执行文件放置在系统的PATH环境变量中,或者在Webbot脚本中指定其路径。
基本用法
以下是使用Webbot库的基本示例:
from webbot import Webbot
# 创建Webbot实例
bot = Webbot()
# 访问网页
bot.visit('https://example.com')
# 填写表单
bot.fill('username', 'your_username')
bot.fill('password', 'your_password')
# 点击按钮
bot.click('login_button')
# 提取数据
data = bot.extract_text('div.content')
print(data)
在这个示例中,我们首先创建了一个Webbot实例,然后访问了一个网页,填写了用户名和密码,点击了登录按钮,并提取了页面中的一些数据。
高级功能
Webbot库的高级功能包括处理JavaScript渲染的页面。以下是一些高级用法示例:
from webbot import Webbot
bot = Webbot()
# 访问需要JavaScript渲染的网页
bot.visit('https://example.com')
# 等待页面加载完成
bot.wait_for_element('div.content')
# 执行JavaScript代码
bot.execute_script('arguments[0].scrollIntoView()', bot.find_element('div.content'))
# 模拟键盘输入
bot.send_keys('input.search', 'search query')
# 模拟点击操作
bot.click('button.submit')
在这个示例中,我们展示了如何等待页面元素加载、执行JavaScript代码、模拟键盘输入和点击操作。
社区与支持
Webbot库拥有活跃的社区和丰富的资源,以下是一些社区资源链接:
GitHub仓库:https://github.com/webbot/webbot - 这是Webbot库的官方GitHub仓库,你可以在这里找到源代码、文档和问题跟踪。
官方文档:https://webbot.readthedocs.io/ - 官方文档提供了详细的API参考和使用指南。
社区论坛:https://community.webbot.io/ - 社区论坛是讨论Webbot库相关问题和分享经验的好地方。
注意事项
使用Webbot库时,请考虑以下事项:
遵守robots.txt协议:确保你的自动化任务遵守目标网站的robots.txt协议,尊重网站的爬虫政策。
避免频繁请求:频繁的请求可能会使服务器负载过重,甚至导致你的IP被封禁。合理控制请求频率,避免对网站造成不良影响。
异常处理:在自动化脚本中使用异常处理机制,确保在遇到错误时能够优雅地处理,避免脚本意外终止。
Webbot库以其易用性和灵活性,帮助开发者在自动化任务中节省时间,提高效率。通过本文档,我们希望开发者能够快速上手并充分利用Webbot库的强大功能。无论你是进行自动化测试、数据收集还是网页监控,Webbot库都能为你提供强大的支持。

全套Python学习资料分享:
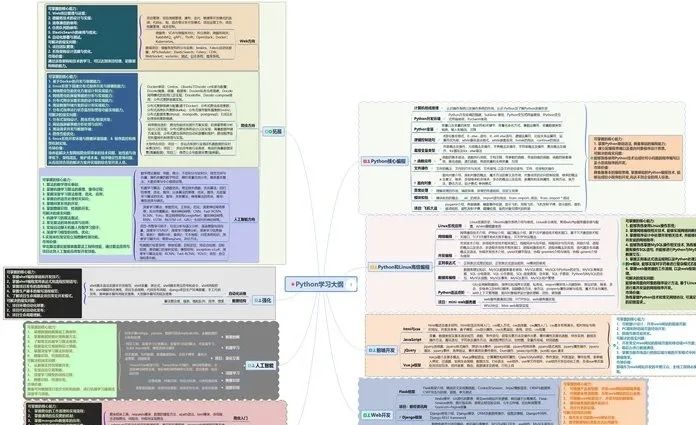
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

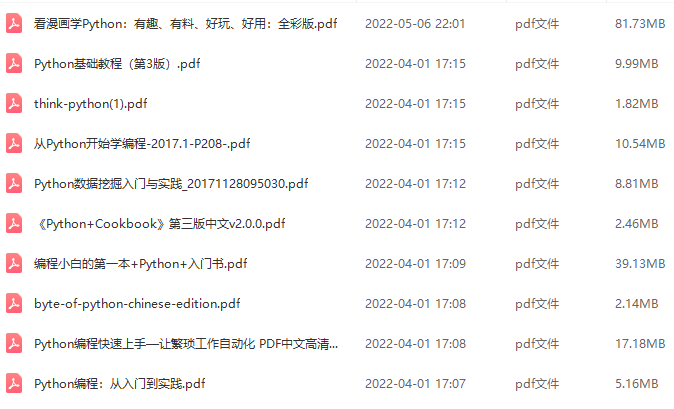
三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
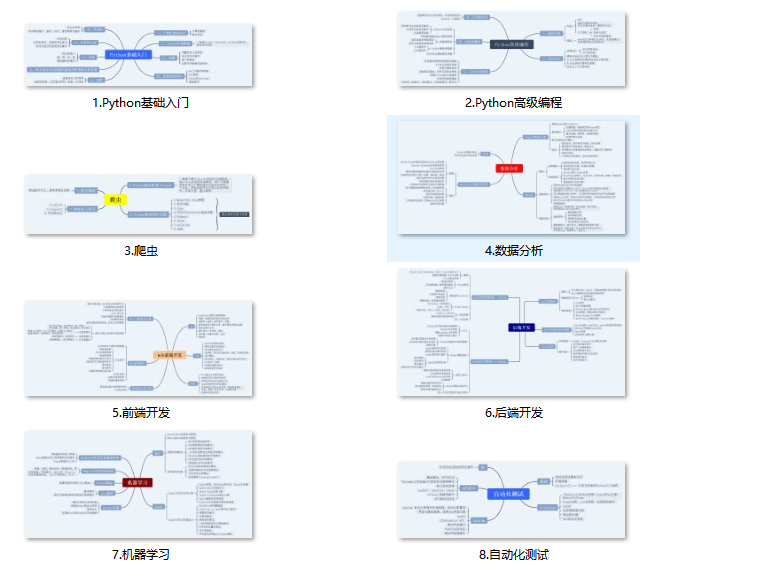
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

如有侵权,请联系删除。















 1290
1290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









