







现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
分析完请求以及返回的数据之后就可以开始怕取数据了,请求代码展示如下,返回数据正常。
-- coding: utf-8 --
@Time : 2021/9/18 16:03
@Author : KK
@File : 40_原神官网.py
@Software: PyCharm
import requests
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36’}
def get_data(url):
try:
response = requests.get(url=url, headers=headers)
print(response.json())
except:
pass
if name == ‘main’:
url = ‘https://ys.mihoyo.com/content/ysCn/getContentList?pageSize=20&pageNum=1&order=asc&channelId=150’
get_data(url)
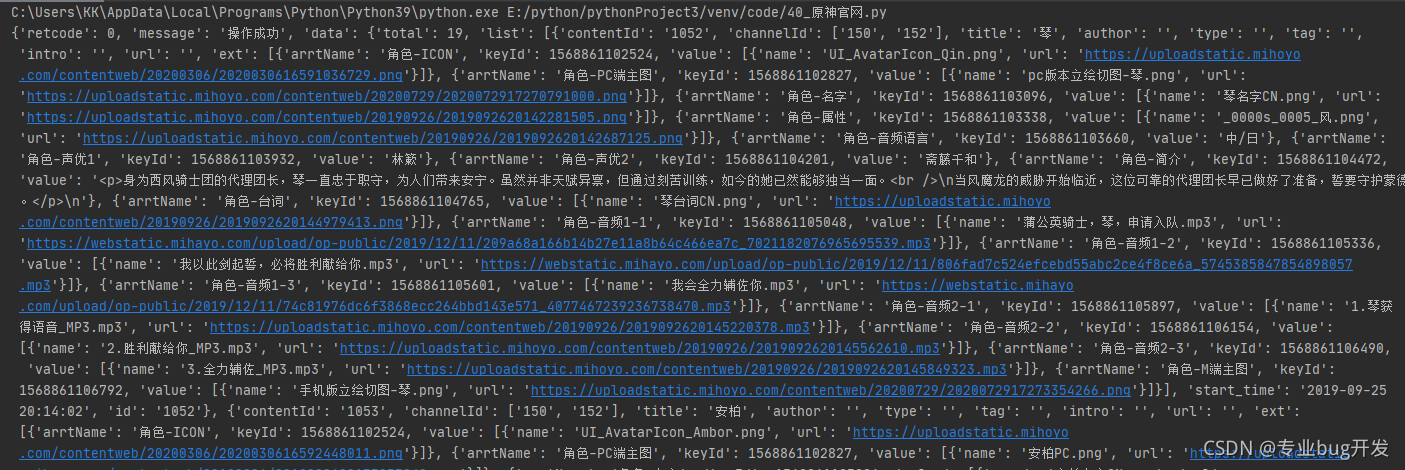
4.清洗数据
对于返回的JSON格式的数据我们不需要任何选择器就可以直接获取,注意看清数据的层次结构,这样我们就可以一层层获取我们需要的数据了,获取的时候参照格式化后的代码即可。
格式化后的数据如下,显然我们需要的数据在list这个列表里面,所以我们先拿到这个list,然后去遍历list进一步取出里面的数据。
def get_data(url):
try:
yinpin = []
tu_url = None
jianjie = None
response = requests.get(url=url, headers=headers)
print(response.json())
res = response.json()
data_list = res[‘data’][‘list’] # 获取到list数据
print(data_list)
i = 1
for each in data_list:
print(‘正在爬取第{}个角色…’.format(i))
i = i + 1
id = each[‘id’] # 角色id
title = each[‘title’] # 角色名字
start_time = each[‘start_time’] # 角色上线时间
ext_list = each[‘ext’]
for item in ext_list:
if item[‘arrtName’] == ‘角色-PC端主图’: # 角色主图
tu_url = item[‘value’][0][‘url’]
elif item[‘arrtName’] == ‘角色-简介’: # 角色简介
jianjie = processing(item[‘value’])
elif item[‘arrtName’] == ‘角色-音频1-2’: # 可以使用正则匹配所有的
yinpin = item[‘value’][0][‘name’] + ‘||’ + item[‘value’][0][‘url’] # 一条配音链接
data = {
“角色ID”: id,
“角色名称”: title,
“上线时间”: start_time,
“高清图片”: tu_url,
“角色简介”: jianjie,
“角色配音”: yinpin,
}
print(data)
dict_infor.append(data)
print(dict_infor)
except ZeroDivisionError as e:
print(“except:”, e)
finally:
pass
5.完整代码以及效果截图
-- coding: utf-8 --
@Time : 2021/9/18 16:03
@Author : KK
@File : 40_原神官网.py
@Software: PyCharm
import requests
import re
import csv
import time
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36’}
dict_infor = []
处理字符串中的空白符,并拼接字符串
def processing(strs):
n = strs.replace(‘
’, ‘’).replace(‘
\n’, ‘’).replace(‘
return n # 返回拼接后的字符串
def get_data(url):
try:
yinpin = []
tu_url = None
jianjie = None
response = requests.get(url=url, headers=headers)
print(response.json())
res = response.json()
data_list = res[‘data’][‘list’] # 获取到list数据
print(data_list)
i = 1
for each in data_list:
print(‘正在爬取第{}个角色…’.format(i))
i = i + 1
id = each[‘id’] # 角色id
title = each[‘title’] # 角色名字
start_time = each[‘start_time’] # 角色上线时间
ext_list = each[‘ext’]
for item in ext_list:
if item[‘arrtName’] == ‘角色-PC端主图’: # 角色主图
tu_url = item[‘value’][0][‘url’]
elif item[‘arrtName’] == ‘角色-简介’: # 角色简介
jianjie = processing(item[‘value’])
elif item[‘arrtName’] == ‘角色-音频1-2’: # 可以使用正则匹配所有的
yinpin = item[‘value’][0][‘name’] + ‘||’ + item[‘value’][0][‘url’] # 一条配音链接
data = {
“角色ID”: id,
“角色名称”: title,
“上线时间”: start_time,
“高清图片”: tu_url,
“角色简介”: jianjie,
“角色配音”: yinpin,
}
print(data)
dict_infor.append(data)
print(dict_infor)
except ZeroDivisionError as e:
print(“except:”, e)
finally:
pass
def get_url():
page_list = [150, 151, 324]
for i in page_list:
url = ‘https://ys.mihoyo.com/content/ysCn/getContentList?pageSize=20&pageNum=1&order=asc&channelId={}’.format(i)
get_data(url)
if name == ‘main’:
get_url()
保存到csv
with open(r’E:\python\pythonProject3\venv\Include\原神.csv’, ‘a’, encoding=‘utf-8’, newline=‘’) as cf:
writer = csv.DictWriter(cf, fieldnames=[‘角色ID’, ‘角色名称’, ‘上线时间’, ‘高清图片’, ‘角色简介’, ‘角色配音’])
writer.writeheader()
writer.writerows(dict_infor)
time.sleep(1)
print(‘爬取并保存完毕’)
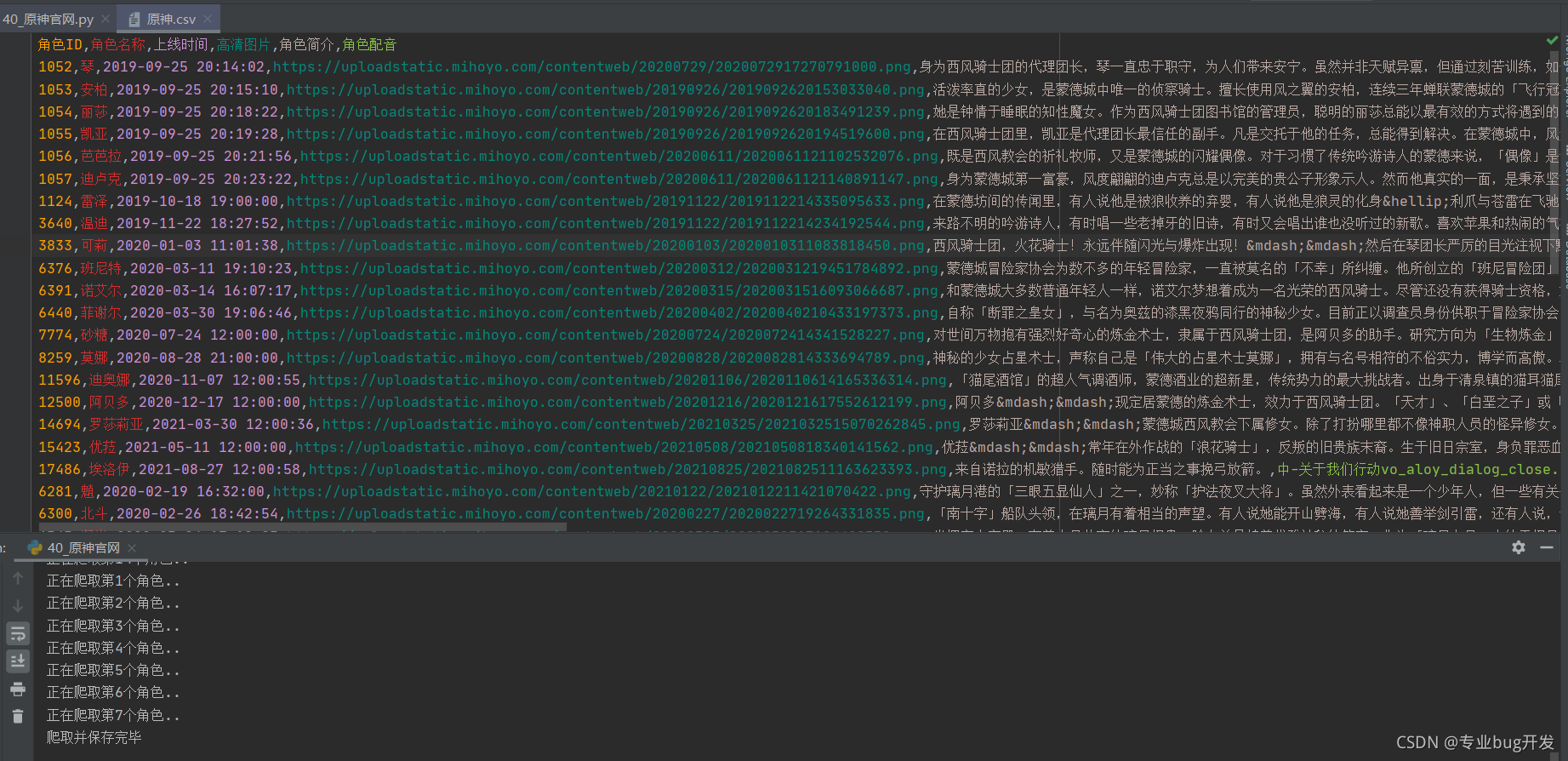
6.分析总结
通过上面的代码可以发现,对于这类数据的爬取其实和requests请求方式差不多,主要区别在于我们获取到的数据不同,对于JSON数据我们同样进行适当的处理,获取我们想要的数据。
============================================================================
Selenium是浏览器自动化测试框架,是一个用于web测试的工具,可以直接在浏览器中运行,并可驱动浏览器执行一定的操作,例如点击、下拉等,还可以获取浏览器当前页面的源代码。
1.安装Selenium以及浏览器驱动
在pycharm搜索安装selenium模块或者直接控制台pip install selenium命令行安装。
由于该框架需要浏览器驱动,我们根据自己所使用的浏览器下载对应版本即可。
2.Selenium使用准备
下载完成后将名称chromedriver.exe的文件提取出来放在与自己的python.exe文件同级的路径中。

3.Selenium模块常用方法
a.定位元素
| 模块名称 | 使用 |
| — | — |
| find_element_by_id() | |
| find_element_by_name() | |
| find_element_by_xpath() | |
| find_element_by_link_text() | |
| find_element_by_partial_link_text() | 查询返回单个元素 |
| find_element_by_tag_name | |
| find_element_by_class_name | |
| find_element_by_css_selector | |
| 模块名称 | 使用 |
| — | — |
| find_elements_by_name() | |
| find_elements_by_xpath() | |
| find_elements_by_link_text() | |
| find_elements_by_partial_link_text() | 查询返回多个元素 |
| find_elements_by_tag_name | |
| find_elements_by_class_name | |
| find_elements_by_css_selector | |
b.鼠标操作
| 模块问题 | |
| — | — |
| click() | 点击元素 |
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 4778
4778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









